A few weeks ago, I published a series of blog on the Alfresco Clustering, including Solr Sharding. At that time, I planned to first explain what is really the Solr Sharding, what are the different concepts and methods around it. Unfortunately, I didn’t get the time to write this blog so I had to post the one related to Solr even before explaining the basics. Today, I’m here to rights my wrong! Obviously, this blog has a focus on Alfresco related Solr Sharding since that’s what I do.
I. Solr Sharding – Concepts
The Sharding in general is the partitioning of a set of data in a specific way. There are several possibilities to do that, depending on the technology you are working on. In the scope of Solr, the Sharding is therefore the split of the Solr index into several smaller indices. You might be interested in the Solr Sharding because it improves the following points:
- Fault Tolerance: with a single index, if you lose it, then… you lost it. If the index is split into several indices, then even if you are losing one part, you will still have all others that will continue working
- High Availability: it provides more granularity than the single index. You might want for example to have a few small indices without HA and then have some others with HA because you configured them to contain some really important nodes of your repository
- Automatic Failover: Alfresco knows automatically (with Dynamic Registration) which Shards are up-to-date and which ones are lagging behind so it will choose automatically the best Shards to handle the search queries so that you get the best results possible. In combination with the Fault Tolerance above, this gives the best possible HA solution with the less possible resources
- Performance improvements: better performance in indexing since you will have several Shards indexing the same repository so you can have less work done by each Shards for example (depends on Sharding Method). Better performance in searches since the search query will be processes by all Shards in parallel on smaller parts of the index instead of being one single query on the full index
Based on benchmarks, Alfresco considers that a Solr Shard can contain up to 50 to 80 000 000 nodes. This is obviously not a hard limit, you can have a single Shard with 200 000 000 nodes but it is more of a best practice if you want to keep a fast and reliable index. With older versions of Alfresco (before the version 5.1), you couldn’t create Shards because Alfresco didn’t support it. So, at that time, there were no other solutions than having a single big index.
There is one additional thing that must be understood here: the 50 000 000 nodes soft limit is 50M nodes in the index, not in the repository. Let’s assume that you are using a DB_ID_RANGE method (see below for the explanation) with an assumed split of 65% live nodes, 20% archived nodes, 15% others (not indexed: renditions, other stores, …). So, if we are talking about the “workspace://SpacesStore” nodes (live ones), then if we want to fill a Shard with 50M nodes, we will have to use a DB_ID_RANGE of 100*50M/65 = 77M. Basically, the Shard should be more or less “full” once there are 77M IDs in the Database. For the “archive://SpacesStore” nodes (archived ones), it would be 100*50M/20 = 250M.
Alright so what are the main concepts in the Solr Sharding? There are several terms that need to be understood:
- Node: It’s a Solr Server (a Solr installed using the Alfresco Search Services). Below, I will use “Solr Server” instead because I already use “nodes” (lowercase) for the Alfresco Documents so using “Node” (uppercase) for the Solr Server, it might be a little bit confusing…
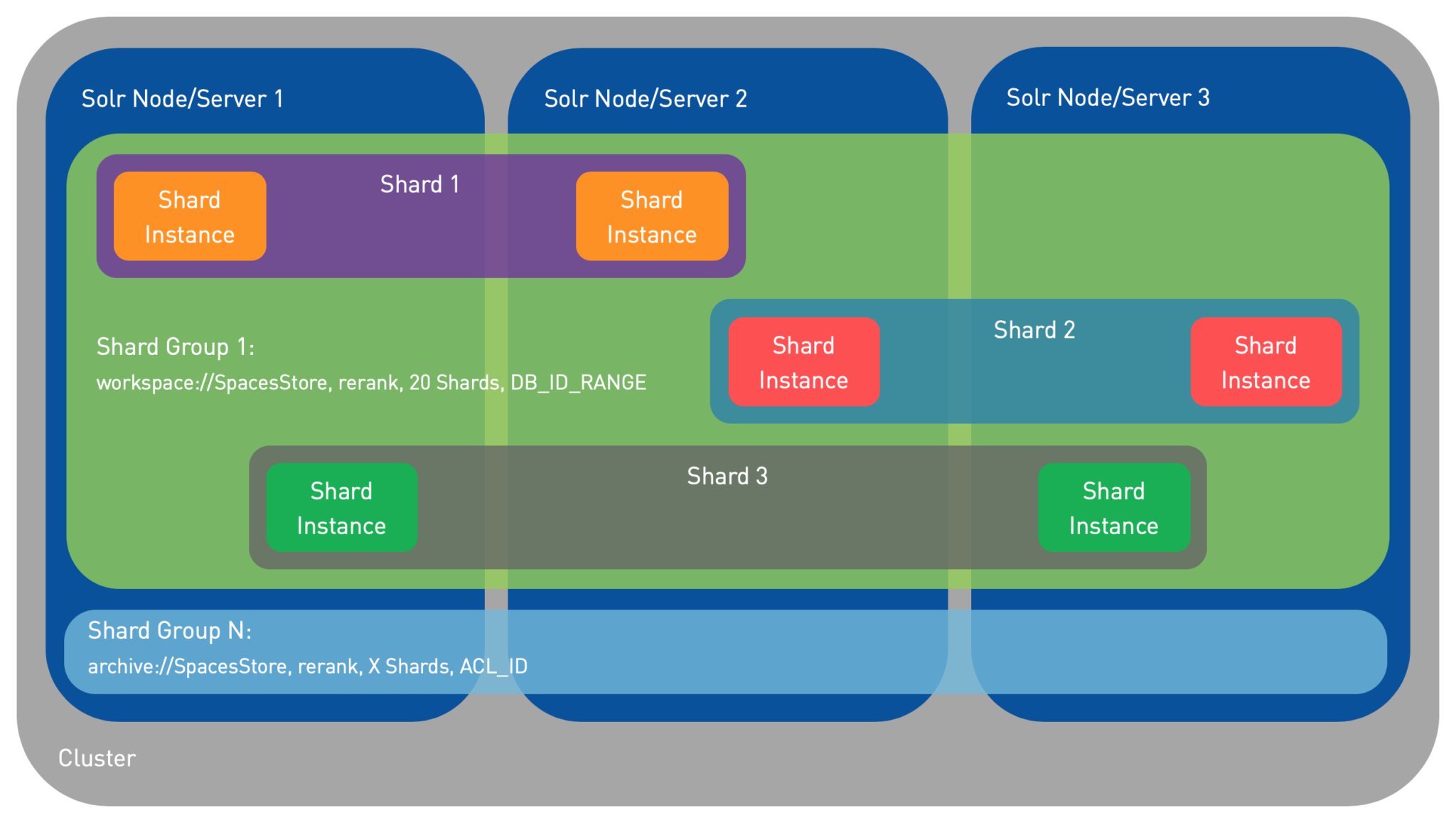
- Cluster: It’s a set of Solr Servers all working together to index the same repository
- Shard: A part of the index. In other words, it’s a representation (virtual concept) of the index composed of a certain set of nodes (Alfresco Documents)
- Shard Instance: It’s one Instance of a specific Shard. A Shard is like a virtual concept while the Instance is the implementation of that virtual concept for that piece of the index. Several Shard Instances of the same Shard will therefore contain the same set of Alfresco nodes
- Shard Group: It’s a collection of Shards (several indices) that forms a complete index. Shards are part of the same index (same Shard Group) if they:
- Track the same store (E.g.: workspace://SpacesStore)
- Use the same template (E.g.: rerank)
- Have the same number of Shards max (“numShards“)
- Use the same configuration (Sharding methods, Solr settings, …)
Shard is often (wrongly) used in place of Shard Instance which might lead to some confusion… When you are reading “Shard”, sometimes it means the Shard itself (the virtual concept), sometimes it’s all its Shard Instances. This is these concepts can look like:
II. Solr Sharding – Methods
Alfresco supports several methods for the Solr Sharding and they all have different attributes and different ways of working:
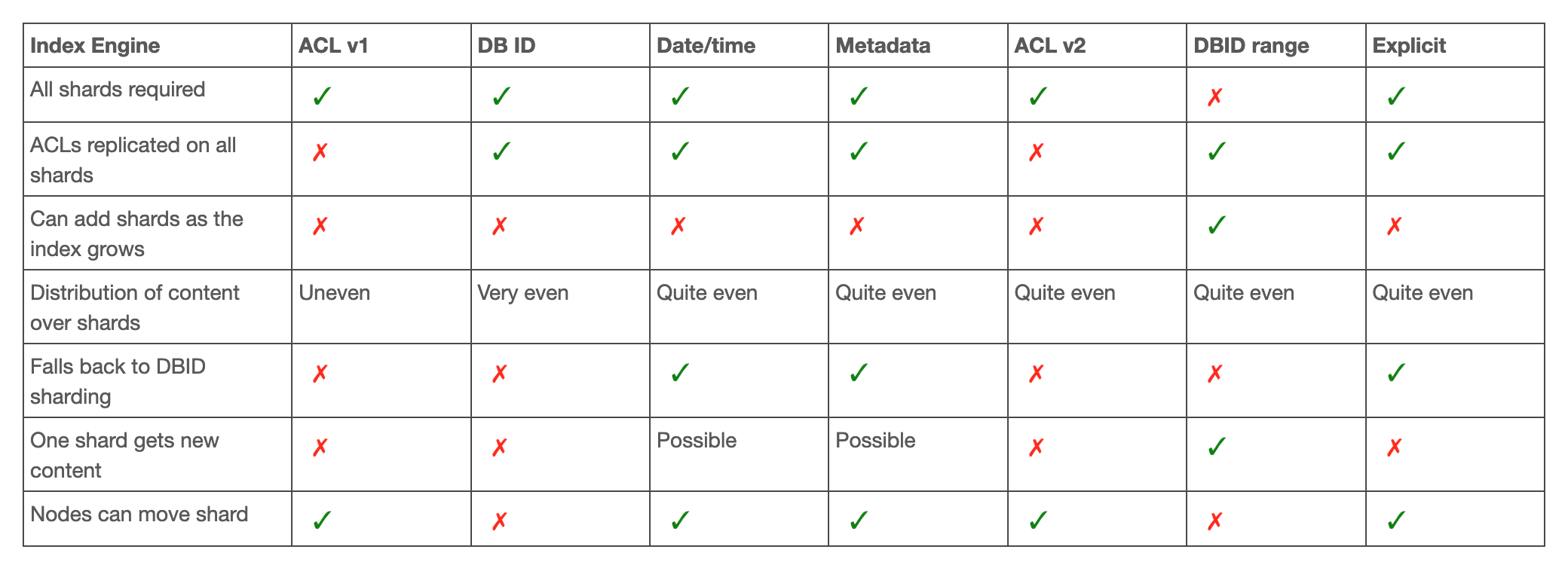
- MOD_ACL_ID (ACL v1): Alfresco nodes and ACLs are grouped by their ACL ID and stored together in the same Shard. Different ACL IDs will be assigned randomly to different Shards (depending on the number of Shards you defined). Each Alfresco node using a specific ACL ID will be stored in the Shard already containing this ACL ID. This simplifies the search requests from Solr since ACLs and nodes are together, so permission checking is simple. If you have a lot of documents using the same ACL, then the distribution will not be even between Shards. Parameters:
- shard.method=MOD_ACL_ID
- shard.instance=<shard.instance>
- shard.count=<shard.count>
- ACL_ID (ACL v2): This is the same as the MOD_ACL_ID, the only difference is that it changes the method to assign to ACL to the Shards so it is more evenly distributed but if you still have a lot of documents using the same ACL then you still have the same issue. Parameters:
- shard.method=ACL_ID
- shard.instance=<shard.instance>
- shard.count=<shard.count>
- DB_ID: This is the default Sharding Method in Solr 6 which will evenly distribute the nodes in the different Shards based on their DB ID (“alf_node.id“). The ACLs are replicated on each of the Shards so that Solr is able to perform the permission checking. If you have a lot of ACLs, then this will obviously make the Shards a little bit bigger, but this is usually insignificant. Parameters:
- shard.method=DB_ID
- shard.instance=<shard.instance>
- shard.count=<shard.count>
- DB_ID_RANGE: Pretty much the same thing as the DB_ID but instead of looking into each DB ID one by one, it will just dispatch the DB IDs from the same range into the same Shard. The ranges are predefined at the Shard Instance creation and you cannot change them later, but this is also the only Sharding Method that allows you to add new Shards dynamically (auto-scaling) without the need to perform a full reindex. You should only create the needed number of Shards (to avoid unnecessary DB requests) but always prepare to have more in the future. The lower value of the range is included and the upper value is excluded (for Math lovers: [begin-end[ ;)). Since DB IDs are incremental (increase over time), performing a search query with a date filter might end-up as simple as checking inside a single Shard. Parameters:
- shard.method=DB_ID_RANGE
- shard.range=<begin-end>
- shard.instance=<shard.instance>
- DATE: Months will be assigned to a specific Shard sequentially and then nodes are indexed into the Shard that was assigned the current month. Therefore, if you have 2 Shards, each one will contain 6 months (Shard 1 = Months 1,3,5,7,9,11 // Shard 2 = Months 2,4,6,8,10,12). It is possible to assign consecutive months to the same Shard using the “shard.date.grouping” parameter which defines how many months should be grouped together (a semester for example). If the date of the property chosen as “shard.key” is null, the fallback method is to use DB_ID instead. Parameters:
- shard.method=DATE
- shard.key=cm:modified
- shard.date.grouping=<1-12>
- shard.instance=<shard.instance>
- shard.count=<shard.count>
- PROPERTY: A property is specified as the base for the Shard assignment. The first time that a node is indexed with a new value for this property, the node will be assigned randomly to a Shard. Each node coming in with the same value for this property will be assigned to the same Shard. Valid properties are either d:text (single line text), d:date (date only) or d:datetime (date+time). It is possible to use only a part of the property’s value using “shard.regex” (To keep only the first 4 digits (d) of a date for example: shard.regex=^\d{4}). If this property doesn’t exist on a node or if the regex doesn’t match (if any is specified), the fallback method is to use DB_ID instead. Parameters:
- shard.method=PROPERTY
- shard.key=cm:creator
- shard.instance=<shard.instance>
- shard.count=<shard.count>
- EXPLICIT_ID: Pretty much similar to the PROPERTY but instead of using the value of a “random” property, this method requires a specific property (d:text) to define explicitly on which Shard the node should be indexed. Therefore, this will require an update of the Data Model to have one property dedicated to the assignment of a node to a Shard. In case you are using several types of documents, then you will potentially want to do that for all. If this property doesn’t exist on a node or if an invalid Shard number is given, the fallback method is to use DB_ID instead. Parameters:
- shard.method=EXPLICIT_ID
- shard.key=<property> (E.g.: cm:targetShardInstance)
- shard.instance=<shard.instance>
- shard.count=<shard.count>
As you can see above, each Sharding Method has its own set of properties. You can define these properties in:
- The template’s solrcore.properties file in which case it will apply to all Shard Instance creations
- E.g.: $SOLR_HOME/solrhome/templates/rerank/conf/solrcore.properties
- The URL/Command used to create the Shard Instance in which case it will only apply to the current Shard Instance creation
- E.g.: curl -v “http://host:port/solr/admin/cores?action=newCore&…&property.shard.method=DB_ID_RANGE&property.shard.range=0-50000000&property.shard.instance=0“
Summary of the benefits of each method:
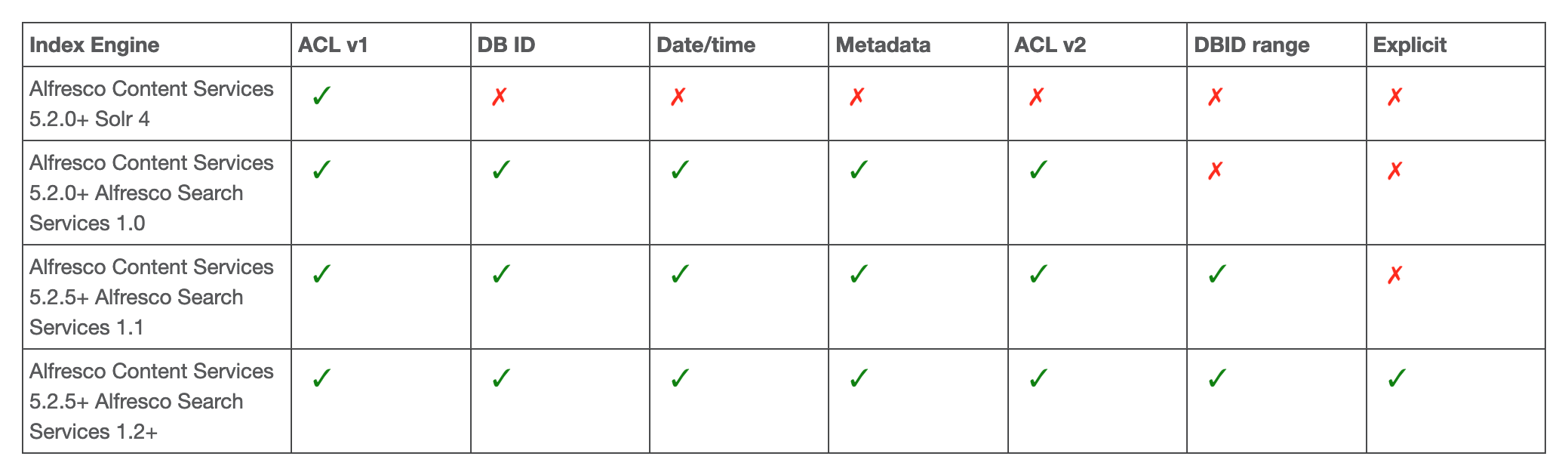
First supported versions for the Solr Sharding in Alfresco:
Hopefully, this is a good first look into the Solr Sharding. In a future blog, I will talk about the creation process and show some example of what is possible. If you want to take a look at the Alfresco documentation (link might change in the future since the Alfresco Documentation site will be changed), it doesn’t always explain everything in details, but it is an excellent starting point with a LOT of information.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/MOP_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/GME_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ATR_web-min-scaled.jpg)