This blog will be the first of a series on Alfresco HA/Clustering topics. It’s been too long I haven’t posted anything related to Alfresco so I thought about writing a few blogs about my experience with setting up more or less complex HA/Clustering infrastructures. So, let’s start this first part with an introduction to the Alfresco HA/Clustering.
If you want to setup a HA/Cluster environment, you will have to first think about where you want to go exactly. Alfresco is composed of several components so “what do you want to achieve exactly?”, that would probably be the first question to ask.
Alfresco offers a lot of possibilities, you can more or less do whatever you want. That’s really great, but it also means that you should plan what you want to do first. Do you just want a simple HA architecture for Share+Repository but you can live without Solr for a few minutes/hours (in case of issues) or you absolutely want all components to be always available? Or maybe you want an HA architecture which is better suited for high throughput? Obviously, there might be some costs details that need to be taken into consideration linked to the resources but also the licenses: the Alfresco Clustering license itself but also the Index Engine license if you go for separated Solr Servers.
That’s what you need to define first to avoid losing time changing configurations and adding more components into the picture later. Alternatively (and that’s something I will try to cover as much as I can), it’s also possible to setup an environment which will allow you to add more components (at least some of them…) as needed without having to change your HA/Clustering configuration, if you are doing it right from the start and if you don’t change too much the architecture itself.
I mentioned earlier the components of Alfresco (Alfresco Content Services, not the company), these are the ones we are usually talking about:
- *ActiveMQ
- Alfresco PDF Renderer
- Database
- File System
- *Front-end (Apache HTTPD, Nginx, …)
- ImageMagick
- Java
- LibreOffice
- *Share (Tomcat)
- *Solr6 (Jetty)
- *Repository (Tomcat)
In this series of blog, I won’t talk about the Alfresco PDF Renderer, ImageMagick & Java because these are just simple binaries/executables that need to be available from the Repository side. For LibreOffice, it’s usually Alfresco that is managing it directly (multi-processes, restart if crash, aso…). It wouldn’t really make sense to talk about these in blogs related to Clustering. I will also disregard the Database and File System ones since they are usually out of my scope. The Database is usually installed & managed by my colleagues which are DBAs, they are much better at that than me. That leaves us with all components with an asterisk (*). I will update this list with links to the different blogs.
Before jumping in the first component, which will be the subject of the next blog, I wanted to go through some possible architectures for Alfresco. There are a lot of schemas available on internet but it’s often the same architecture that is presented so I thought I would take some time to represent, in my own way, what the Alfresco’s architecture could look like.
In the below schemas, I represented the main components: Front-end, Share, Repository, Solr, Database & File System (Data) as little boxes. As mentioned previously, I won’t talk about the Database & File System so I just represented them once to see the communications with these but what is behind their boxes can be anything (with HA/Clustering or not). The arrows represent the way communications are initiated: an arrow in a single direction “A->B” means that B is never initiating a communication with A. Boxes that are glued together represent all components installed on the same host (a physical server, a VM, a container or whatever).
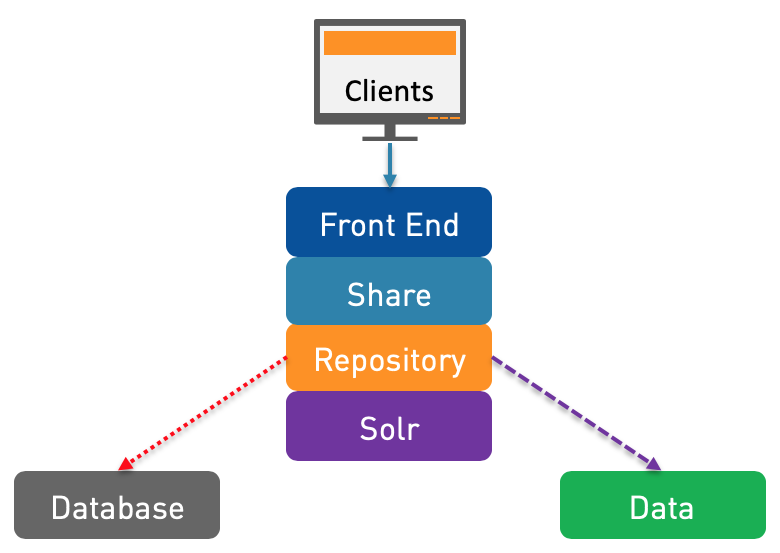 N°1: This is the simplest architecture for Alfresco. As you can see, it’s not a HA/Clustering architecture but I decided to start small. I added a Front-end (even if it’s not mandatory) because it’s a best practice and I would not install Alfresco without it. Nothing specific to say on this architecture, it’s just simple.
N°1: This is the simplest architecture for Alfresco. As you can see, it’s not a HA/Clustering architecture but I decided to start small. I added a Front-end (even if it’s not mandatory) because it’s a best practice and I would not install Alfresco without it. Nothing specific to say on this architecture, it’s just simple.
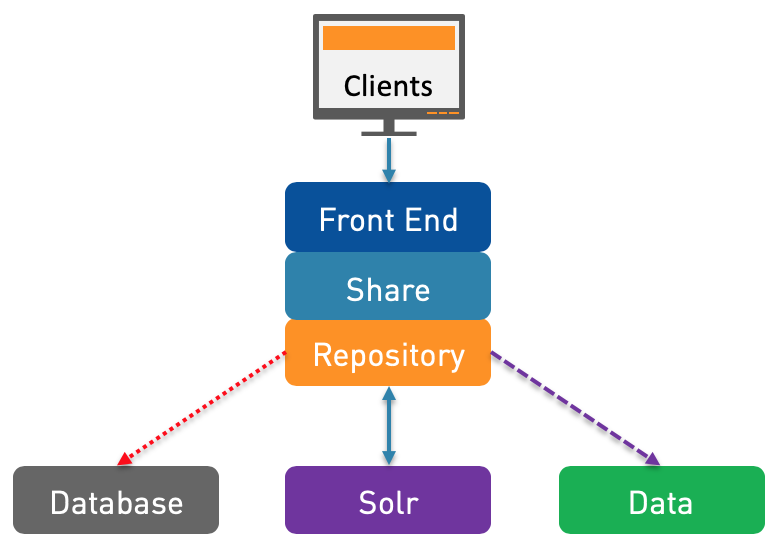 N°2: The first thing to do if you have the simplest architecture in place (N°1) and you start seeing some resources contention is to split the components and more specifically to install Solr separately. This should really be the minimal architecture to use, whenever possible.
N°2: The first thing to do if you have the simplest architecture in place (N°1) and you start seeing some resources contention is to split the components and more specifically to install Solr separately. This should really be the minimal architecture to use, whenever possible.
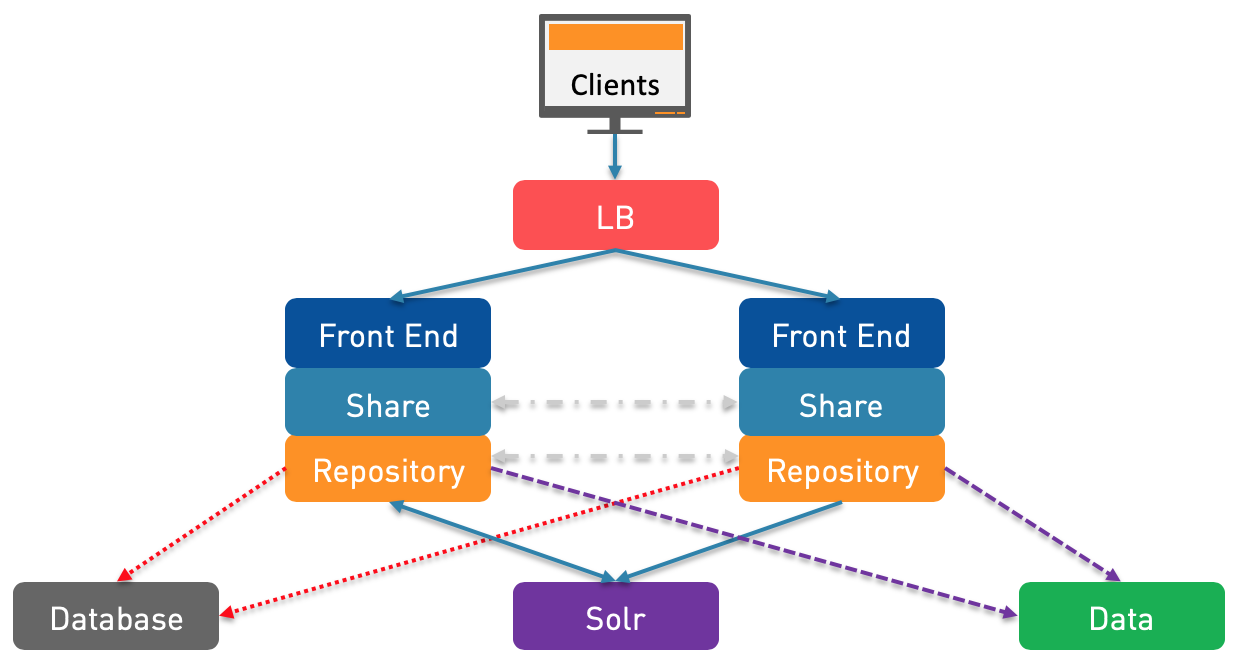 N°3: This is the first HA/Clustering architecture. It starts small as you can see with just two nodes for each Front-end/Share/Repository stack with a Load Balancer to dispatch the load on each side for an Active/Active solution. The dotted grey lines represent the Clustering communications. In this architecture, there is therefore a Clustering for Share and another one for the Repository layer. The Front-end doesn’t need Clustering since it just forwards the communications but the session itself is on the Tomcat (Share/Repository) side. There is only one Solr node and therefore both Repository boxes will communicate with the Solr node (through the Front-end or not). Between the Repository and Solr, there is one bidirectional arrow and another one unidirectional. That’s because both Repository boxes will initiate searches but the Solr will do tracking to index new content with only one Repository: this isn’t optimal.
N°3: This is the first HA/Clustering architecture. It starts small as you can see with just two nodes for each Front-end/Share/Repository stack with a Load Balancer to dispatch the load on each side for an Active/Active solution. The dotted grey lines represent the Clustering communications. In this architecture, there is therefore a Clustering for Share and another one for the Repository layer. The Front-end doesn’t need Clustering since it just forwards the communications but the session itself is on the Tomcat (Share/Repository) side. There is only one Solr node and therefore both Repository boxes will communicate with the Solr node (through the Front-end or not). Between the Repository and Solr, there is one bidirectional arrow and another one unidirectional. That’s because both Repository boxes will initiate searches but the Solr will do tracking to index new content with only one Repository: this isn’t optimal.
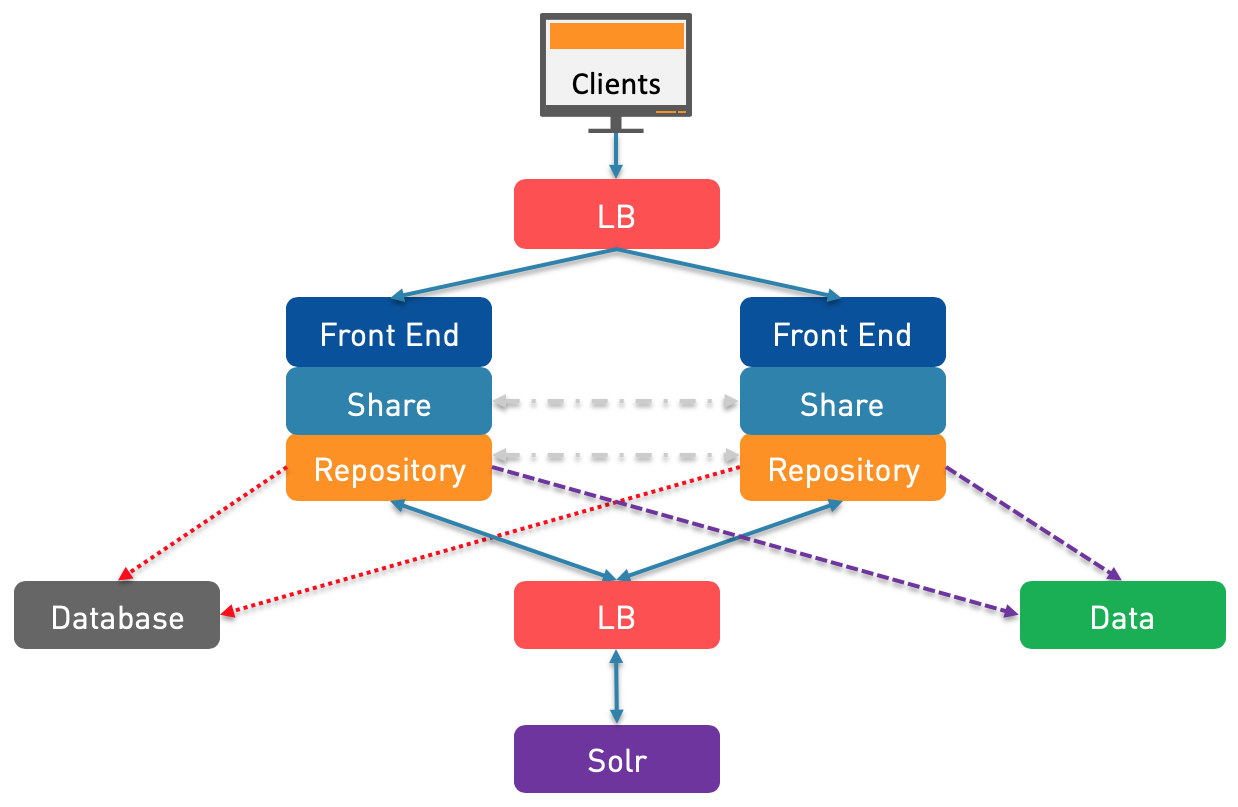 N°4: To solve this small issue with Solr tracking, we can add a second Load Balancer in between so that the Solr tracking can target any Repository node. The first bottleneck you will encounter in Alfresco is usually the Repository because a lot of things are happening in the background at that layer. Therefore, this architecture is usually the simplest HA/Clustering solution that you will want to setup.
N°4: To solve this small issue with Solr tracking, we can add a second Load Balancer in between so that the Solr tracking can target any Repository node. The first bottleneck you will encounter in Alfresco is usually the Repository because a lot of things are happening in the background at that layer. Therefore, this architecture is usually the simplest HA/Clustering solution that you will want to setup.
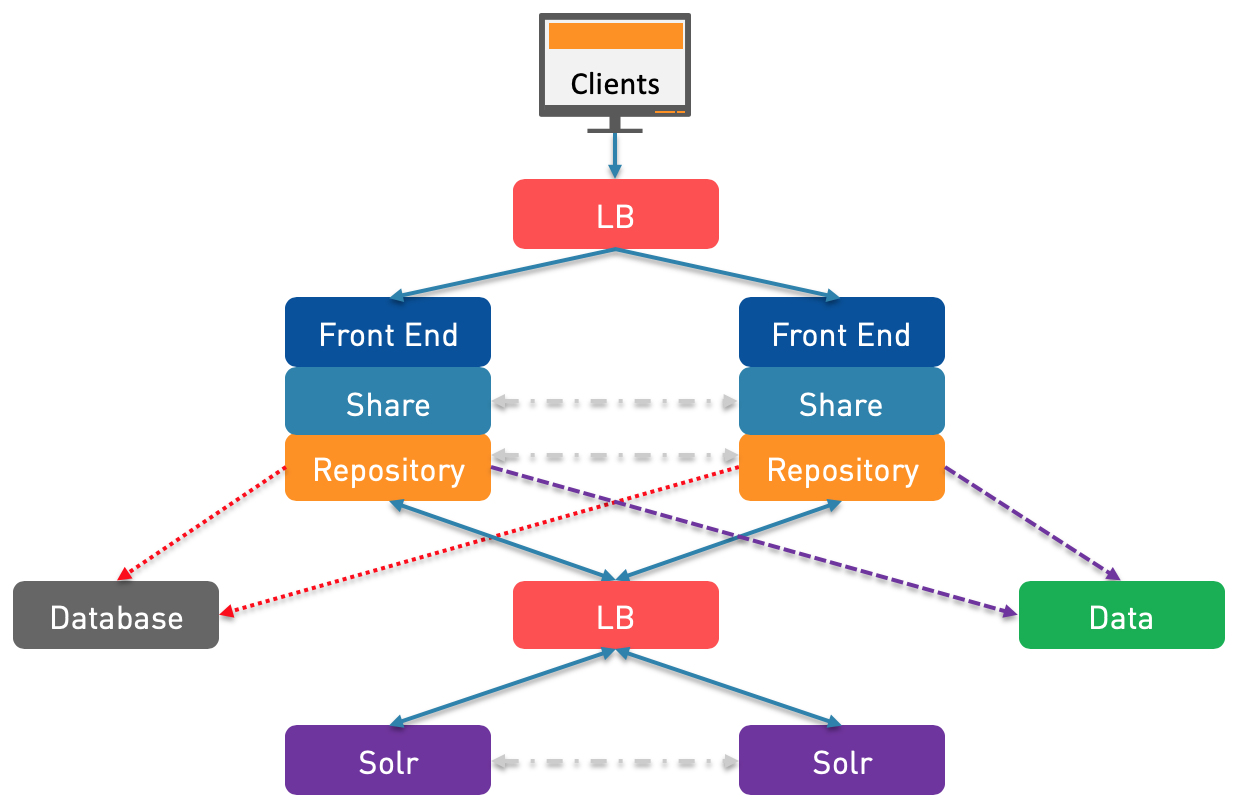 N°5: If you are facing some performance issues with Solr or if you want all components to be in HA, then you will have to duplicate the Solr as well. Between the two Solr nodes, I put a Clustering link, that’s in case you are using Solr Sharding. If you are using the default cores (alfresco and archive), then there is no communication between distinct Solr nodes. If you are using Solr Sharding and if you want a HA architecture, then you will have the same shards on both Solr nodes and in this case, there will be communications between the Solr nodes, it’s not really a Clustering so to speak, that’s how Solr Sharding is working but I still used the same representation.
N°5: If you are facing some performance issues with Solr or if you want all components to be in HA, then you will have to duplicate the Solr as well. Between the two Solr nodes, I put a Clustering link, that’s in case you are using Solr Sharding. If you are using the default cores (alfresco and archive), then there is no communication between distinct Solr nodes. If you are using Solr Sharding and if you want a HA architecture, then you will have the same shards on both Solr nodes and in this case, there will be communications between the Solr nodes, it’s not really a Clustering so to speak, that’s how Solr Sharding is working but I still used the same representation.
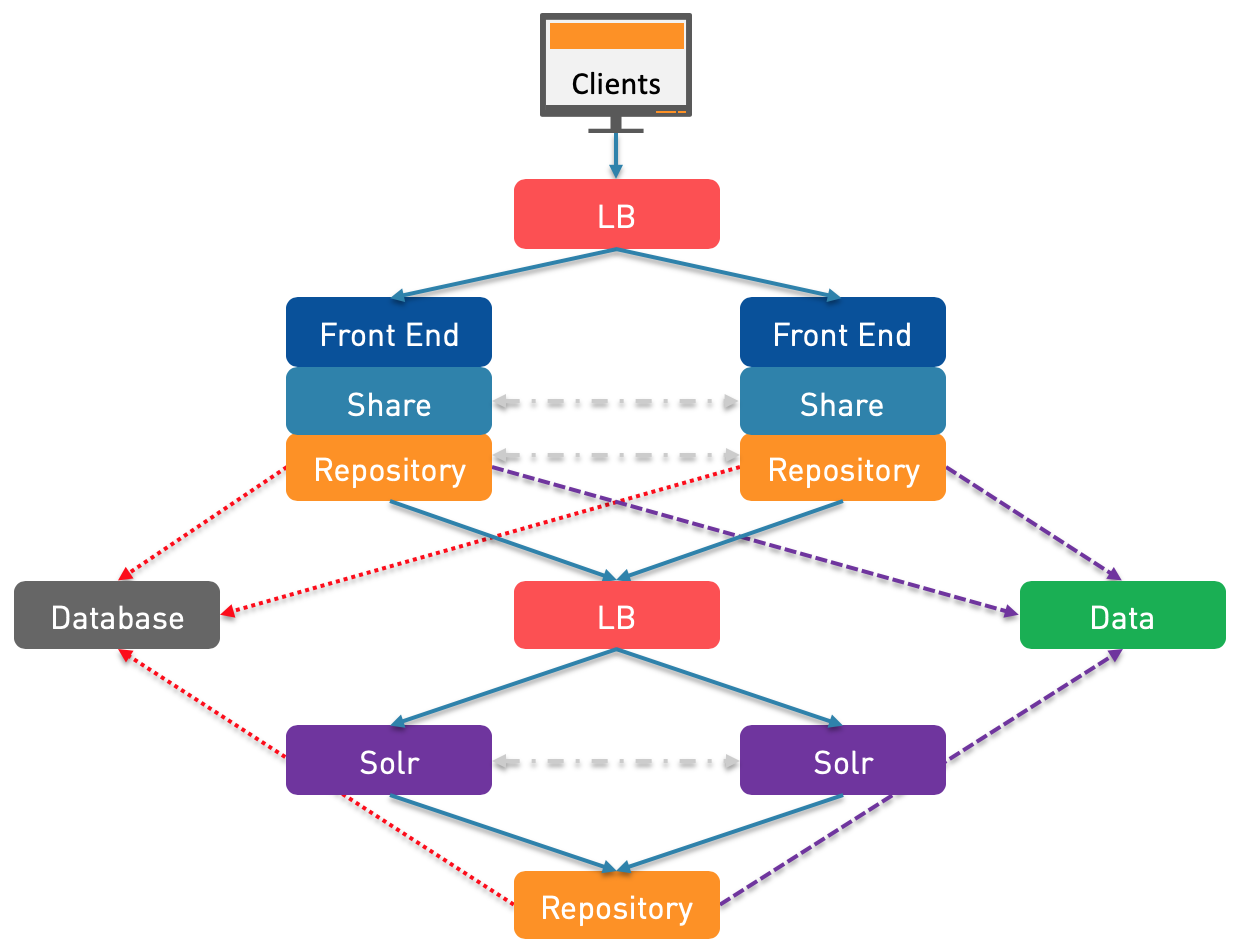 N°6: As mentioned previously (for the N°4), the Repository is usually the bottleneck. To reduce the load on this layer, it is possible to do several things. The first possibility is to install another Repository and dedicate it to the Solr Tracking. As you can see above, the communications aren’t bidirectional anymore but only unidirectional. Searches will come from the two Repository that are in Cluster and Solr Tracking will use the separated/dedicated Repository. This third Repository can then be set in read-only, the jobs and services can be disabled, the Clustering can be disabled as well (so it uses the same DB but it’s not part of the Clustering communications because it doesn’t have to), aso… I put this third Repository as a standalone box but obviously you can install it with one of the two Solr nodes.
N°6: As mentioned previously (for the N°4), the Repository is usually the bottleneck. To reduce the load on this layer, it is possible to do several things. The first possibility is to install another Repository and dedicate it to the Solr Tracking. As you can see above, the communications aren’t bidirectional anymore but only unidirectional. Searches will come from the two Repository that are in Cluster and Solr Tracking will use the separated/dedicated Repository. This third Repository can then be set in read-only, the jobs and services can be disabled, the Clustering can be disabled as well (so it uses the same DB but it’s not part of the Clustering communications because it doesn’t have to), aso… I put this third Repository as a standalone box but obviously you can install it with one of the two Solr nodes.
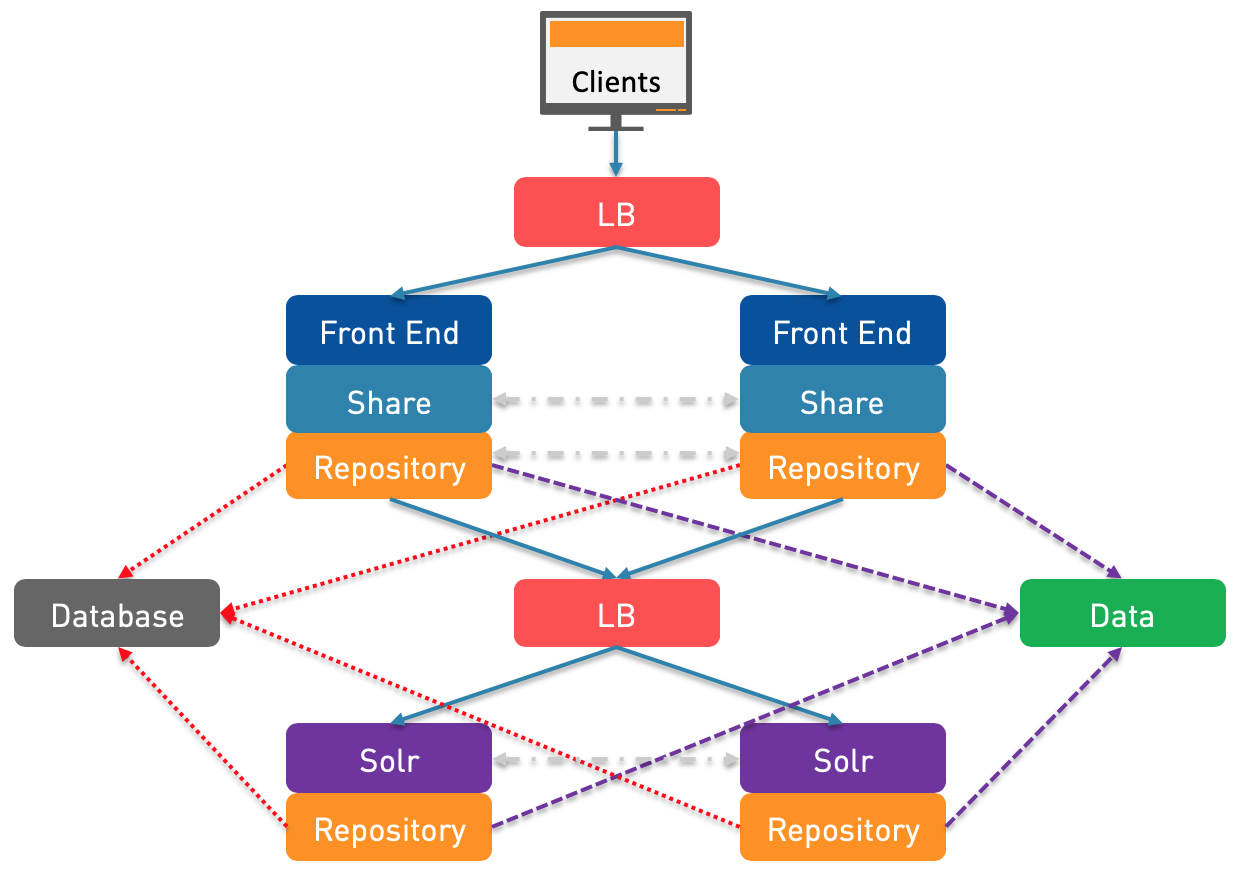 N°7: The next step can be to add another read-only Repository and put these two nodes side by side with the Solr nodes. This is to only have localhost communications for the Solr Tracking which is therefore a little bit easier to secure.
N°7: The next step can be to add another read-only Repository and put these two nodes side by side with the Solr nodes. This is to only have localhost communications for the Solr Tracking which is therefore a little bit easier to secure.
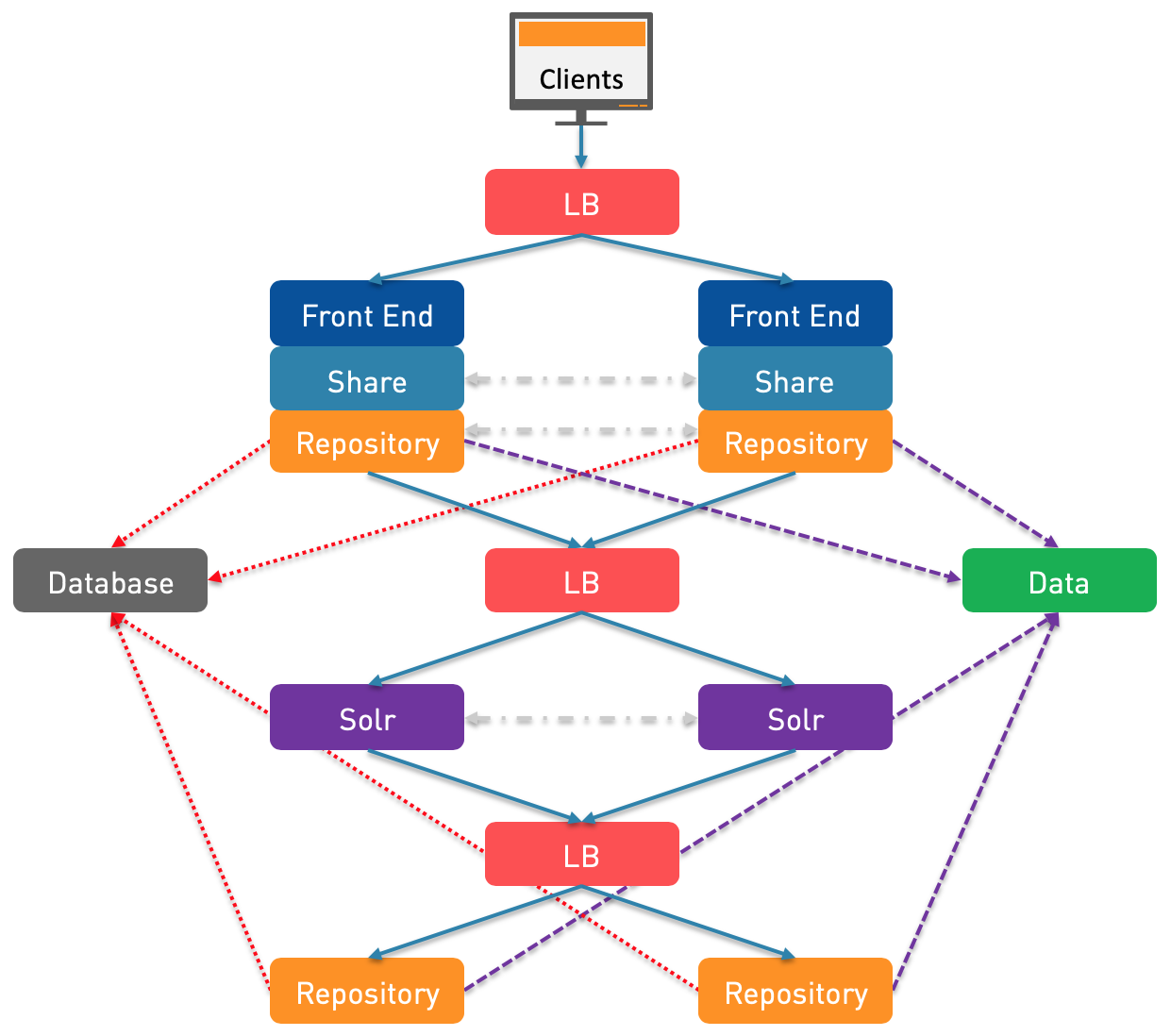 N°8: The previous architectures (N°6 & N°7) introduced a new single point of failure so to fix this, there is only one way: add a new Load Balancer between the Solr and the Repository for the tracking. Behind the Load Balancer, there are two solutions: keep the fourth Repository which is also in read-only or use a fallback to the Repository node1/node2 in case the read-only Repository (node3) isn’t available. For that purpose, the Load Balancer should be in, respectively, Active/Active or Active/Passive. As you can see, I choose to represent the first one.
N°8: The previous architectures (N°6 & N°7) introduced a new single point of failure so to fix this, there is only one way: add a new Load Balancer between the Solr and the Repository for the tracking. Behind the Load Balancer, there are two solutions: keep the fourth Repository which is also in read-only or use a fallback to the Repository node1/node2 in case the read-only Repository (node3) isn’t available. For that purpose, the Load Balancer should be in, respectively, Active/Active or Active/Passive. As you can see, I choose to represent the first one.
These were a few possible architectures. You can obviously add more nodes if you want to, to handle more load. There are many other solutions so have fun designing the best one, according to your requirements.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/MOP_web-min-scaled.jpg)


![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/GME_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ATR_web-min-scaled.jpg)
Azou
25.08.2024Hello, thank you for this well explained article. My question is as follows: can schemes 3 to 8 be implemented in the Community Edition, and if so, under which technologies for the load balancer, cache and user session manager?
Morgan Patou
25.08.2024In short, not really. Alfresco removed any clustering capabilities from the Community version in 4.2. There are components where you could partially achieve it like Share, since you might be ok with just multiple share and maybe a user session replication based on Tomcat. But Share isn't the issue usually, so it's not really a big benefit... For other components, you would need to develop (and maintain) it yourself, if you really want clustering. It might be easier to achieve HA than Clustering by using virtualization technologies.
Cheers,
Morgan