
Two weeks ago, I was at the #SITF24 to talk about integration of External Repositories (SharePoint/Teams, shared folder,…) into M-Files. Surprisingly this is still a tricky topic for companies.
As an ECM consultant since years, I’m probably a bit too naive and think documents are already well managed in most of the firms. I got some feedback that prove me the reality is different.
What is the need?
Based on a study from Gartner conducted in 2023, people who work with data (producing documents and so on) have to deal with an average a 11 applications, this value increase if these people are working in an IT department.
This situation leads automatically to some problems like:
- Confusion: where to store my document, where is the previous version?
- Duplicates: Document recreated because it was not stored a the right place.
- Compliance: a new version of a document has been created, but not from the latest version because the collaborator was not able to identify the current version of the document.
- Security: document not stored a the right place thus right permissions are not applied.
Luckily, in general all these cases do not apply at the same time, but these are common issues companies are facing.
How M-Files can help?
M-Files has several interesting features to help the users.
The idea is to place M-files as the entry point for the user, as soon as someone from the company needs some data the reflex will be to go to M-Files.
Prior to that the administrator have configured some external repositories to connect other applications: network shares, SharePoint sites/document libraries, MS Teams channels, but also Google workplaces, Amazon S3…
You may want to connect also other applications to gather data which are not documents like Salesforce, SAP, Microsoft Dynamics CRM… or even a simple database.
You can retrieve all the existing connectors here. If you aren’t able to find what you need you can create your own.
Once the connections are made, M-Files starts indexing the data. After some time (depends the amount of data to index, of course), the users will be able to search in M-files and find data stored outside.

It’s already good but M-files can do more.
Intelligent Metadata Layer
In previous posts (like here) I already talked about IML, the AI capabilities of M-Files.
This time I will introduce another module, M-files Discovery.
With this module the M-Files magic appear!
M-Files Discovery can automatically classify and categorize documents stored on external repositories.
What does it means? Simply no matter where the documents are, if M-files was able to classify them, they will appear in the M-files Views.
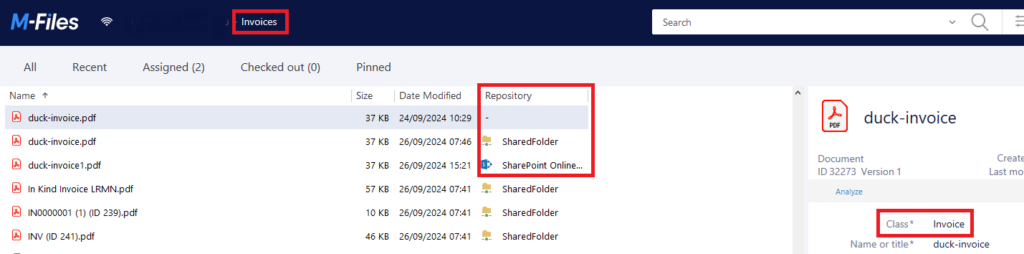
Then if a workflow is defined for this class of document, it can follow the different steps exactly like a native M-Files document.
Discovery can also detect Personal Identifiable Information, it can be really interesting to define specific scenario in that case and ensure the compliance.
Additionally, with the M-files duplicate detection you can easily identify a document stored in multiple repositories (c.f. previous screenshot, “duck-invoice.pdf” is stored in 3 different repositories).
As usual if you have any further questions, feel free to reach us and don’t hesitate to tell me f you want more technical information, I will be happy to write another blog on that topic.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/GME_web-min-scaled.jpg)

![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/MOP_web-min-scaled.jpg)