In a previous blog, we got an overview on Elastic Stack (Elasticsearch, Logstash, Kibana, and Beets), in next blogs I will go through all these components to understand them, today we will go more in deep in Elasticsearch the heart of Elastic Stack.
To really discover Elasticsearch we need to understand the below concepts and terminologies:
Node
Is a single instance of Elasticsearch. All nodes know about all the other nodes in the cluster and can forward client requests to the appropriate node!
By default, a node is all of the following types:
Master Node
The master node is responsible for actions such as creating or deleting an index, tracking which nodes are part of the cluster, and deciding which shards to allocate to which nodes. So you can imagine how much it is important for cluster health to have a stable master node!
By default, all nodes may be elected to become the master node by the master election process which will be explained in a separate blog 😉
To create a dedicated master node, set the below:
node.master: true node.data: false node.ingest: false cluster.remote.connect: false
We will go into details when we speak about Elasticsearch installation.
Data Node
Data nodes hold the shards that contain the documents you have indexed. Data nodes handle data related operations which are I/O-, memory-, and CPU-intensive. So, it is very important to monitor these resources and to add more data nodes if they are overloaded.
The main benefit of having dedicated data nodes is the separation of the master and data roles.
To create a dedicated data node, set the below:
node.master: false node.data: true node.ingest: false cluster.remote.connect: false
Ingest Node
Ingest nodes can execute pre-processing pipelines, composed of one or more ingest processors.
Depending on the type of operations performed by the ingest processors and the required resources, it may make sense to have dedicated ingest nodes, that will only perform this specific task.
To create a dedicated ingest node, set the below:
node.master: false node.data: false node.ingest: true cluster.remote.connect: false
Coordinating ONLY Node
Coordinating only nodes can benefit large clusters by offloading the coordinating node role from data and master nodes. They join the cluster and receive the full cluster state, like every other node, and they use the cluster state to route requests directly to the appropriate place!
CAUTION : Adding too many coordinating only nodes to a cluster can increase the burden on the entire cluster because the elected master node must await acknowledgement of cluster state updates from every node!
To create a dedicated Coordinating ONLY node, set the below:
node.master: false node.data: false node.ingest: false cluster.remote.connect: false
Machine Learning Node
The machine learning features provide machine learning nodes, which run jobs and handle machine learning API requests.
To create a dedicated Coordinating ONLY node, set the below:
node.master: false node.data: false node.ingest: false node.ml: true xpack.ml.enabled: true
Cluster
An Elasticsearch cluster is a group of nodes that have the same cluster.name attribute. As nodes join or leave a cluster, the cluster automatically reorganizes itself to evenly distribute the data across the available nodes.
If you are running a single instance of Elasticsearch, you have a cluster of one node, in this case no replica shards can be allocated! The cluster is fully functional but is at risk of data loss in the event of a failure!
On the other hand, with a cluster with multiple nodes you increase its capacity and reliability. In fact, when you add more nodes to a cluster, it automatically allocates replica shards which considerably reduces the risk of data loss 😉
Index
Indices are the largest unit of data in Elasticsearch, are logical partitions of documents and can be compared to a database in the world of relational databases.
In fact, there are two concepts! First, an index is some type of data organization mechanism, allowing the user to partition data a certain way. The second concept relates to replicas and shards, the mechanism Elasticsearch uses to distribute data around the cluster.
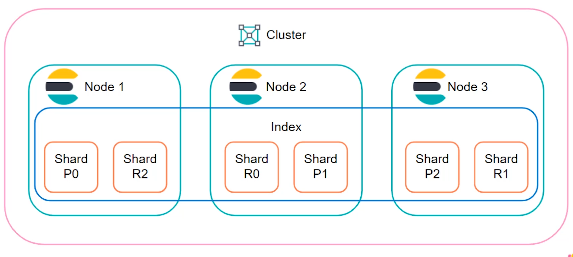
To sum up, data in Elasticsearch is organized into indices. Each index is made up of one or more shards.
Shards
In Elasticsearch data is written to a shard, it is periodically published into new immutable Lucene segments on disk, and it is at this time it becomes available for querying. As the number of segments grow, these are periodically consolidated into larger segments. This process is referred to as merging.
As all segments are immutable, this means that the disk space used will typically fluctuate during indexing, as new, merged segments need to be created before the ones they replace can be deleted. Merging can be quite resource intensive, especially with respect to disk I/O.
At the end, the shard is the unit at which Elasticsearch distributes data around the cluster, to better understand, below is an overview of Elasticsearch cluster:
Documents
Documents are JSON objects that are stored within an Elasticsearch index and are considered the base unit of storage. In the world of relational databases, documents can be compared to a row in table.
Data in documents is defined with fields comprised of keys and values. A key is the name of the field, and a value can be an item of many different types such as a string, a number, a boolean expression, another object, or an array of values.
Documents also contain reserved fields that constitute the document metadata such as:
- _index – the index where the document resides
- _type – the type that the document represents
- _id – the unique identifier for the document
An example of a document:
{
"_id": 3,
“_type”: [“your index type”],
“_index”: [“your index name”],
"_source":{
"age": 28,
"name": ["daniel”],
"year":1989,
}
}
These are the main concepts you should understand when getting started with Elasticsearch, for sure not enough as there are other components and terms as well… We will try to cover more and more in the next blog speaking about Elasticsearch installation.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/09/DDI_web-min-scaled.jpg)