Sie vertrauen uns

OMrun hat uns über viele Jahre hinweg einen grossen Nutzen gebracht. Die vollständig automatisierten Smoke-Tests für jede Umgebung, die mit einer grossen Anzahl von Geschäftsprozesstests integriert sind, ermöglichten es uns, unseren Release-Zyklus von vierteljährlich auf zweimal im Monat zu verkürzen.
Der permanente Überblick über Stammdaten und Prozessqualität über das offen dargestellte OMdashboard hat uns einen Zuwachs an Produktivität, Transparenz sowie Motivation gebracht und die Reaktionszeiten auf ein absolutes Minimum reduziert.

OMrun hat es uns auf einfache und transparente Weise ermöglicht, Stammdaten aus verschiedenen Berichtssystemen schnell abzugleichen und mögliche Fehler frühzeitig zu erkennen und zu korrigieren. Hierdurch konnte die Datenqualität insgesamt signifikant verbessert werden.
Die Zusammenarbeit mit OMIS war stets professionell und partnerschaftlich, und der Projekterfolg wurde sehr schnell sichergestellt.

In einer komplexen Anwendung mit vielen Schnittstellen zu anderen Systemen führt OMrun unsere Qualitätssicherungsprüfungen durch, wie die tägliche Überwachung der Datenintegrität, die Abstimmung des Hauptbuchs und der Nebenbücher sowie die Qualitätsprüfungen des Data Warehouse. So unterstützt uns OMrun effizient in der Qualitätssicherung und im IKS (internes Kontrollsystem).
Und genau deshalb bin ich ein Fan von OMrun geworden!
Ihre Daten bestimmen Ihre Entscheidungen. Stellen Sie sicher, dass sie korrekt sind.
Fehlerhafte Daten machen nicht auf sich aufmerksam. Sie verstecken sich in Dashboards, schlüpfen durch die Maschen bei Migrationen und treten erst zutage, wenn sie bereits Schaden angerichtet haben: ein fehlgeschlagenes Release, ein irreführender KPI, ein verpatzter Go-Live.
OMrun vermittelt Ihren Teams objektives Vertrauen in ihre Daten. Automatisch und kontinuierlich. In jeder Phase des Datenlebenszyklus.

Drei Wege, wie OMrun Ihre Datenqualität schützt
OMrun basiert auf drei gezielten Säulen, von denen jede eine spezifische und entscheidende Herausforderung im Bereich der Datenqualität angeht.
Säule 1: Datenprüfung
Daten während ihres gesamten Lebenszyklus automatisch testen
Wenn Sie eine neue Softwareversion veröffentlichen, ein System aktualisieren oder Plattformen zusammenführen, können Datenregressionen unentdeckt bleiben, bis sie die Produktionsumgebung erreichen. OMrun simuliert reale Anwendungsaktivitäten, überprüft die Ausgaben und erkennt Regressionsfehler automatisch, bevor sie sich auf die Endbenutzer auswirken.
Was Sie davon haben:
- Weniger Produktionsstörungen
- Sicherere und schnellere Software-Releases
- Messbare Kosteneinsparungen durch Früherkennung
Für wen ist dies gedacht: IT-Teamleiter, die Datenprozesse in Umgebungen verwalten, in denen die Qualität und Stabilität von Releases von entscheidender Bedeutung sind (z. B. Finanzämter, öffentliche Verwaltungen).
Säule 2: Datenüberblickbarkeit und -konsistenz
Vertrauen Sie jedem Dashboard und jedem KPI, nicht nur einigen davon
Wenn Ihre Analysen nicht mehr mit den Quellsystemen synchronisiert sind, werden Entscheidungen auf der Grundlage veralteter oder falscher Daten getroffen. OMrun überwacht die Aktualität, das Volumen, Trends und Anomalien der Daten in Ihrem gesamten Analytics-Stack, einschliesslich APIs in heterogenen Umgebungen, und meldet Abweichungen, fehlende Daten oder ungewöhnliches Verhalten umgehend.
Was Sie davon haben:
- Garantierte Vollständigkeit, Richtigkeit und Konsistenz
- Zuverlässige Dashboards und KPIs zu jeder Zeit
- Proaktive Benachrichtigungen, bevor die Beteiligten ein Problem bemerken
Für wen ist das gedacht: Finanzvorstände und Controlling-Teams in Banken und Versicherungsgesellschaften, die für ihr Finanz- und operatives Berichtswesen auf die Genauigkeit von Echtzeitdaten angewiesen sind.
Säule 3: Datenvalidierung
Überprüfen Sie die Richtigkeit Ihrer Daten vor der Inbetriebnahme, nicht erst danach
Plattformmigrationen (z. B. von Oracle zu PostgreSQL) sind risikoreiche Vorgänge. Die manuelle Datenvalidierung ist zeitaufwendig, fehleranfällig und lässt sich nicht skalieren. OMrun generiert automatisch Vergleichsskripte, berücksichtigt erwartete Transformationen, erkennt unbeabsichtigte Änderungen und liefert objektive, überprüfbare Nachweise dafür, dass Quell- und Zieldaten übereinstimmen.
Was Sie davon haben:
- Eindeutige Freigabe vor der Inbetriebnahme
- Automatischer Vergleich zwischen Quell- und Zielsystemen
- Geringeres Migrationsrisiko und schnellere Akzeptanz durch die Beteiligten
Für wen ist das gedacht: Projektmanager und Kundenbetreuer bei Softwareanbietern, die gross angelegte Datenbank- oder Plattformmigrationen betreuen.
Prozess des Datenvergleichs
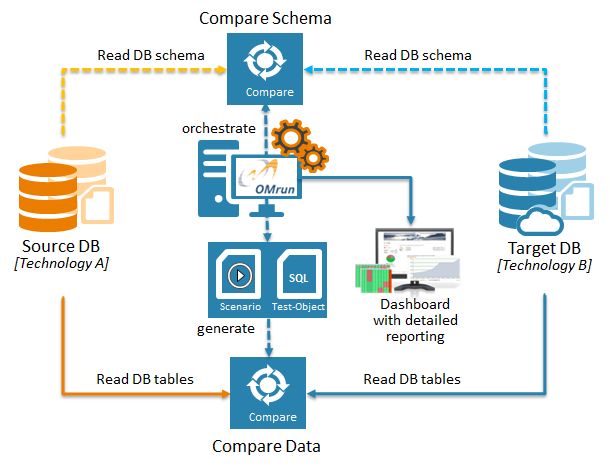
Entwickelt für die Teams, die für die Datenintegrität verantwortlich sind
| Herausforderung | Rolle | Industrie | OMrun-Säule |
|---|---|---|---|
| Datenverluste bei Releases und Upgrades | IT-Teamleiter | Öffentlicher Sektor, Steuerbehörden | Data Testing |
| Plattformmigrationen (Oracle zu PostgreSQL usw.) | Projektmanager, Kundenbetreuer | Softwareanbieter, Pharmaindustrie | Datenvalidierung |
| Uneinheitliche Analysen und Dashboards | CFO, Controlling | Bankwesen, Versicherungswesen, Pharmaindustrie | Datenüberblickbarkeit und -konsistenz |
Was ändert sich, wenn man mit OMrun läuft?
Unternehmen, die OMrun einsetzen, profitieren von kontinuierlichen Verbesserungen entlang der gesamten Datenlieferkette:
- Frühzeitige Erkennung von Problemen: Probleme werden in Testumgebungen erkannt, nicht in der Produktion
- Schnellere und sicherere Releases: Automatisierte Regressionstests machen Schluss mit dem Rätselraten bei der Inbetriebnahme
- Zuverlässige Analysen: Jedes Dashboard und jeder Bericht spiegelt die verlässliche Datenquelle wider
- Geringeres Migrationsrisiko: Objektive Nachweise ersetzen manuelle Freigabeverfahren
- Weniger manueller Aufwand: Durch Automatisierung können sich die Ingenieurteams auf das Wesentliche konzentrieren
OMrun-Module
OMrun besteht aus mehreren Modulen, die jeweils für eine bestimmte Funktionalität entwickelt wurden.
OMrun-Module
- OMrun CLI: Automatisiert Szenarien für eine reibungslose Prozessverwaltung.
- OMrun Studio: Erstellt und passt Szenarien für einfache Konfiguration und Tests an.
- OMmigration: Migriert Daten aus einer Quellumgebung in eine Zielumgebung ohne Verlust.
- OMconversion: Konvertiert verschiedene Datenformate in XML für einfache Interoperabilität.
- OMgenerator: Erzeugt Vergleichsskripte, um die Verwaltung von Datenvergleichen zu vereinfachen.
Häufig gestellte Fragen
Wodurch unterscheidet sich OMrun von einem herkömmlichen Tool für Datenqualität oder Datentests?
Die meisten Tools zur Datenqualitätssicherung konzentrieren sich auf die Profilierung oder Bereinigung von Daten zu einem bestimmten Zeitpunkt. OMrun ist auf kontinuierliche Qualität ausgelegt: Es deckt den gesamten Datenlebenszyklus ab, einschliesslich Releases, Live-Analyseumgebungen und Migrationen. Anstatt erst im Nachhinein über die Datenqualität zu berichten, erkennt OMrun Probleme proaktiv und automatisch, bevor sie in die Produktion gelangen oder geschäftliche Entscheidungen beeinflussen.
Kann OMrun während einer Plattformmigration von Oracle zu PostgreSQL verwendet werden?
Ja, dies ist eine der Kernkompetenzen von OMrun. Der Bereich „Datenvalidierung“ wurde speziell für gross angelegte Plattformmigrationen entwickelt. OMrun generiert automatisch Vergleichsskripte zwischen Quell- und Zieldatenbanken, berücksichtigt erwartete Datenumwandlungen und kennzeichnet alle unbeabsichtigten Änderungen. Das Ergebnis ist ein objektiver, überprüfbarer Nachweis der Datenintegrität, der die Abnahme vor dem Go-Live beschleunigt und das Risiko für alle Beteiligten verringert.
Wie schnell kann ein Team von OMrun profitieren?
OMrun ist so konzipiert, dass es sich ohne langwierige Einrichtungsphasen in bestehende Datenumgebungen integrieren lässt. Teams beginnen in der Regel mit einem Bereich – meist „Datentests“ oder „Datenvalidierung“ – und sehen bereits im ersten Sprint-Zyklus erste Ergebnisse. Da OMrun bisher manuelle Aufgaben (Erstellung von Skripten, Abgleich, Erkennung von Anomalien) automatisiert, ist der Produktivitätsgewinn unmittelbar und vom ersten Tag an messbar.
Mit welchen Datenquellen und Systemen ist OMrun verbunden?
OMrun unterstützt durch vorkonfigurierte Adapter eine Vielzahl von Datenbanksystemen und Datentypen. Neue Adapter können von jedem Team eigenständig integriert werden, ohne dass die Mitwirkung des Anbieters erforderlich ist, und die Adapterbibliothek wird kontinuierlich erweitert. Eine vollständige Übersicht über die Kompatibilität finden Sie in der OMrun-Dokumentation.
Wie unterstützt OMrun die Einhaltung der DSGVO?
OMrun verfügt über eine integrierte Funktion zur Pseudonymisierung von Daten, die sensible Felder automatisch anonymisiert, bevor Daten verschoben, verglichen oder getestet werden. So können Teams in Nicht-Produktionsumgebungen mit realistischen Datensätzen arbeiten und dabei die DSGVO vollständig einhalten. Die Regeln für die Pseudonymisierung werden direkt in OMrun definiert und gespeichert, wodurch vollständige Rückverfolgbarkeit und Nachprüfbarkeit gewährleistet sind.
Lässt sich OMrun in bestehende Orchestrierungs- und CI/CD-Pipelines integrieren?
Ja. OMrun verfügt über eine integrierte Prozess-Engine, die sich nativ mit führenden Orchestrierungs- und Testmanagement-Plattformen verbinden lässt: UC4 (Automic), Control-M, Tosca Testsuite, HP ALM/QC und Jenkins. OMrun kann als primärer Orchestrator fungieren oder als sekundärer Prozess innerhalb einer bestehenden Automatisierungspipeline aufgerufen werden, wodurch sich das Tool problemlos in jede unternehmensinterne Lieferkette einbinden lässt.
Ist OMrun für regulierte Branchen wie das Bankwesen, das Versicherungswesen oder die Pharmaindustrie geeignet?
Auf jeden Fall. OMrun wurde speziell für regulierte Umgebungen entwickelt. Dank seiner überprüfbaren Vergleichsberichte, Pseudonymisierungsfunktionen und automatisierten Validierungsworkflows eignet sich das System ideal für Branchen, in denen Datenintegrität, Rückverfolgbarkeit und Compliance unverzichtbar sind. Unternehmen aus den Bereichen Finanzdienstleistungen, Versicherungen und Pharmazie nutzen OMrun, um strenge regulatorische Anforderungen zu erfüllen und gleichzeitig ihre Datenprozesse zu beschleunigen.
Ressourcen und nützliche Links
Wenn Sie mehr über OMrun und seine Funktionen erfahren möchten, lesen Sie die folgenden Ressourcen:
Ihre hochmoderne Lösung zur Überprüfung und Verbesserung der Datenqualität
Sehen Sie OMrun in Aktion

OMrun ist Software aus der Schweiz mit der Bezeichnung
swiss made software steht für hochwertige Schweizer ICT-Produkte und Werte wie Qualität, Innovation und Präzision in der Softwareentwicklung.
Sie vertrauen uns
OMrun hat uns über viele Jahre hinweg einen großen Nutzen gebracht. Die vollständig automatisierten Smoke-Tests für jede Umgebung, die mit einer großen Anzahl von Geschäftsprozesstests integriert sind, ermöglichten es uns, unseren Release-Zyklus von vierteljährlich auf zweimal im Monat zu verkürzen.
Der permanente Überblick über Stammdaten und Prozessqualität über das offen dargestellte OMdashboard hat uns einen Zuwachs an Produktivität, Transparenz sowie Motivation gebracht und die Reaktionszeiten auf ein absolutes Minimum reduziert.
Wir haben OMrun eingesetzt, um die Erwartungen externer Audits in Bezug auf unser Firewall-Management zu erfüllen und um eine umfangreiche Datenbereinigung und mehrere Abstimmungen vor der Migration auf eine neue Workflow-Engine durchzuführen.
OMrun hat uns dabei sehr wertvolle Dienste geleistet und konnte in kurzer Zeit Transparenz in unser System bringen, was wir aus eigener Kraft nicht geschafft hätten.
OMrun hat uns in diesen Bereichen innerhalb einer sehr kurzen Zeitspanne geholfen:
Einrichtung eines Datenabgleichs zwischen dem Kernbankensystem Avaloq und dem E-Banking-System AFS in drei Tagen. Die aufgezeigten Inkonsistenzen haben zur Datenbereinigung und zu Korrekturen der Software geführt.
n einem weiteren Tag konnte die Reconciliation automatisiert werden, womit sie täglich die Konsistenz der Daten sicherstellt. Dies hat viel Vertrauen im Business geschaffen und operative Risiken stark reduziert.
Rothschild Bank plant aufgrund der guten Erfahrungen den Einsatz von OMrun auf weitere Applikationen / Datenquellen auszubauen.
OMrun hat es uns auf einfache und transparente Weise ermöglicht, Stammdaten aus verschiedenen Berichtssystemen schnell abzugleichen und mögliche Fehler frühzeitig zu erkennen und zu korrigieren. Hierdurch konnte die Datenqualität insgesamt signifikant verbessert werden.
Die Zusammenarbeit mit OMIS war stets professionell und partnerschaftlich, und der Projekterfolg wurde sehr schnell sichergestellt.
In einer komplexen Anwendung mit vielen Schnittstellen zu anderen Systemen führt OMrun unsere Qualitätssicherungsprüfungen durch, wie die tägliche Überwachung der Datenintegrität, die Abstimmung des Hauptbuchs und der Nebenbücher sowie die Qualitätsprüfungen des Data Warehouse. So unterstützt uns OMrun effizient in der Qualitätssicherung und im IKS (internes Kontrollsystem).
Und genau deshalb bin ich ein Fan von OMrun geworden!

Verbessern Sie die Datenqualität für präzise Entscheidungen.
Ali Türk Account Manager
Kontakt aufnehmen