Ils nous font confiance

OMrun nous a apporté une grande valeur ajoutée pendant de nombreuses années. Les tests de fumée entièrement automatisés pour chaque environnement, intégrés à un grand nombre de tests de processus d’entreprise, nous ont permis de réduire notre cycle de publication de trimestriel à bimensuel.
L’aperçu permanent des données de référence et de la qualité du processus sur le tableau de bord OMdashboard nous a permis d’accroître la productivité, la transparence ainsi que la motivation et de réduire les temps de réaction à un minimum absolu..

OMrun nous a permis, de manière simple et transparente, d’aligner rapidement les données de base provenant de différents systèmes de reporting et d’identifier et de corriger rapidement les erreurs potentielles. Résultat : la qualité des données dans son ensemble a été considérablement améliorée.
La coopération avec OMIS a toujours été professionnelle et motivée par un esprit de partenariat, et la réussite du projet a été assurée très rapidement.

Dans une application complexe comportant de nombreuses interfaces avec d’autres systèmes, OMrun effectue nos contrôles d’assurance qualité, comme le contrôle quotidien de l’intégrité des données, le rapprochement du grand livre et des livres auxiliaires, ainsi que les contrôles de qualité de l’entrepôt de données. Nous sommes reconnaissants à OMrun de soutenir l’assurance qualité et les contrôles internes d’une manière aussi efficace.
C’est pourquoi je suis devenu un fan d’OMrun !
Vos données guident vos décisions. Assurez-vous qu’elles sont exactes.
Les données erronées ne se trahissent pas. Elles se cachent dans les tableaux de bord, passent inaperçues lors des migrations et ne se révèlent qu’après avoir causé des dégâts : une mise en production ratée, un indicateur de performance trompeur, une mise en service bâclée.
OMrun permet à vos équipes d’avoir pleinement confiance en leurs données. De manière automatique et continue. À chaque étape du cycle de vie des données.

Trois façons dont OMrun garantit la qualité de vos données
OMrun repose sur trois piliers clés, chacun répondant à un enjeu distinct et crucial en matière de qualité des données.
Pilier 1 : Contrôle des données
Tester automatiquement les données tout au long de leur cycle de vie
Lorsque vous publiez une nouvelle version logicielle, mettez à niveau un système ou regroupez des plateformes, les régressions au niveau des données peuvent passer inaperçues jusqu’à ce qu’elles atteignent l’environnement de production. OMrun simule l’activité réelle des applications, valide les résultats et détecte automatiquement les défaillances liées aux régressions avant qu’elles n’affectent les utilisateurs finaux.
Ce que vous y gagnez :
- Moins d’incidents de production
- Des mises à jour logicielles plus sûres et plus rapides
- Des économies tangibles grâce à la détection précoce
À qui s’adresse cette solution : aux responsables informatiques chargés de gérer les processus de traitement des données dans des environnements où la qualité et la stabilité des déploiements sont essentielles (par exemple, les services fiscaux, les administrations publiques).
Pilier 2 : Observabilité et cohérence des données
Faites confiance à tous les tableaux de bord et indicateurs clés de performance, et pas seulement à certains d’entre eux
Lorsque vos données analytiques ne sont plus synchronisées avec les systèmes sources, les décisions sont prises sur la base de données obsolètes ou erronées. OMrun surveille l’actualité, les volumes, les tendances et les anomalies des données sur l’ensemble de votre infrastructure analytique, y compris les API dans des environnements hétérogènes, et signale immédiatement tout écart, toute donnée manquante ou tout comportement anormal.
Ce que vous y gagnez :
- Exhaustivité, exactitude et cohérence garanties
- Des tableaux de bord et des indicateurs clés de performance fiables à tout moment
- Des alertes proactives avant même que les parties prenantes ne détectent un problème
À qui s’adresse cette solution : aux directeurs financiers et aux équipes de contrôle de gestion des banques et des compagnies d’assurance qui ont besoin de données précises en temps réel pour établir leurs rapports financiers et opérationnels.
Pilier 3 : Validation des données
Vérifiez l’exactitude de vos données avant la mise en service, et non après
Les migrations de plateformes (par exemple, d’Oracle vers PostgreSQL) constituent des opérations à haut risque. La validation manuelle des données est lente, source d’erreurs et impossible à mettre à l’échelle. OMrun génère automatiquement des scripts de comparaison, prend en compte les transformations prévues, détecte les modifications involontaires et fournit une preuve objective et vérifiable de la cohérence entre les données source et cible.
Ce que vous y gagnez :
- Validation sans ambiguïté avant la mise en service
- Comparaison automatisée entre les systèmes source et cible
- Réduction du risque lié à la migration et acceptation plus rapide par les parties prenantes
À qui s’adresse cette solution : aux chefs de projet et aux responsables de la relation client chez les éditeurs de logiciels chargés de superviser des migrations de bases de données ou de plateformes à grande échelle.
Processus de comparaison des données
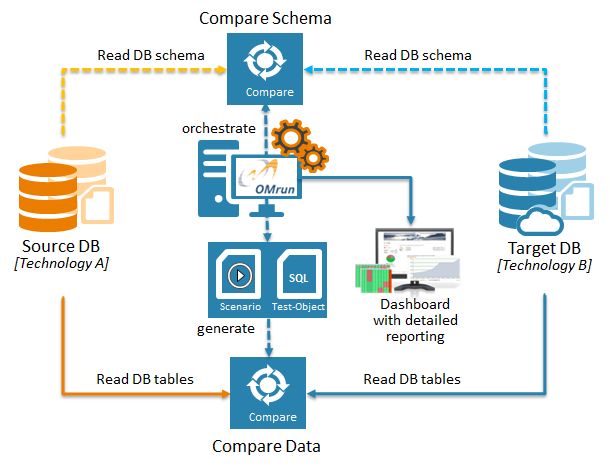
Conçu pour les équipes chargées de l’intégrité des données
| Défi | Rôle | Industry | Piliers OMrun |
|---|---|---|---|
| Régressions des données lors des mises à jour et des mises à niveau | IT Team Leader | Secteur public, autorités fiscales | Data Testing |
| Migrations de plateformes (d’Oracle vers PostgreSQL, etc.) | Project Manager, Customer Manager | Éditeurs de logiciels, industrie pharmaceutique | Data Validation |
| Des analyses et des tableaux de bord incohérents | CFO, Controlling | Secteur bancaire, secteur des assurances, industrie pharmaceutique | Observabilité et cohérence des données |
Qu’est-ce qui change quand on tourne sur OMrun ?
Les organisations qui utilisent OMrun bénéficient d’améliorations constantes tout au long de la chaîne de diffusion des données :
- Détection précoce des problèmes : ceux-ci sont détectés dans les environnements de test, et non en production
- Des mises en production plus rapides et plus sûres : les tests de régression automatisés éliminent les incertitudes liées aux mises en production
- Des analyses fiables : chaque tableau de bord et chaque rapport reflète la source de vérité
- Réduction du risque de migration : des preuves objectives remplacent les procédures de validation manuelles
- Moins de tâches manuelles : l’automatisation permet aux équipes d’ingénieurs de se concentrer sur la création de valeur
Modules OMrun
OMrun se compose de plusieurs modules, chacun conçu pour une fonctionnalité spécifique.
Modules OMrun
- OMrun CLI: automatise les scénarios pour une gestion fluide des processus.
- OMrun Studio: Crée et ajuste des scénarios pour faciliter la configuration et les tests.
- OMmigration: Migre les données d’un environnement source vers un environnement cible sans perte.
- OMconversion: Convertit divers formats de données en XML pour faciliter l’interopérabilité.
- OMgenerator: Génère des scripts de comparaison pour simplifier la gestion des comparaisons de données.
Foire aux questions
En quoi OMrun se distingue-t-il d’un outil classique de contrôle de la qualité des données ou de test ?
La plupart des outils de qualité des données se concentrent sur le profilage ou le nettoyage des données à un moment donné. OMrun est conçu pour assurer une qualité continue : il intervient tout au long du cycle de vie des données, couvrant les mises en production, les environnements d’analyse en temps réel et les migrations. Plutôt que de rendre compte de la qualité des données a posteriori, OMrun détecte les problèmes de manière proactive et automatique, avant qu’ils n’atteignent l’environnement de production ou n’influencent les décisions commerciales.
Peut-on utiliser OMrun lors d’une migration de plateforme d’Oracle vers PostgreSQL ?
Oui, c’est l’un des principaux atouts d’OMrun. Le pilier « Validation des données » est spécialement conçu pour les migrations de plateformes à grande échelle. OMrun génère automatiquement des scripts de comparaison entre les bases de données source et cible, prend en compte les transformations de données prévues et signale toute modification non souhaitée. Il en résulte une preuve objective et vérifiable de l’intégrité des données, qui accélère la mise en service et réduit les risques pour toutes les parties prenantes.
En combien de temps une équipe peut-elle tirer profit d’OMrun ?
OMrun est conçu pour s’intégrer aux environnements de données existants sans nécessiter de longues phases de configuration. Les équipes commencent généralement par un pilier, le plus souvent le test ou la validation des données, et constatent des résultats dès le premier cycle de sprint. Comme OMrun automatise des tâches auparavant manuelles (écriture de scripts, comparaison, détection d’anomalies), le gain de productivité est immédiat et mesurable dès le premier jour.
À quelles sources de données et à quels systèmes OMrun se connecte-t-il ?
OMrun prend en charge un large éventail de systèmes de bases de données et de types de données grâce à des adaptateurs préconfigurés. Chaque équipe peut intégrer de nouveaux adaptateurs de manière autonome, sans intervention du fournisseur, et la bibliothèque d’adaptateurs est constamment enrichie. Un aperçu complet de la compatibilité est disponible dans la documentation OMrun.
Comment OMrun facilite-t-il la mise en conformité avec le RGPD ?
OMrun intègre une fonctionnalité de pseudonymisation des données qui anonymise automatiquement les champs sensibles avant que les données ne soient transférées, comparées ou testées. Cela permet aux équipes de travailler avec des ensembles de données réalistes dans des environnements hors production tout en respectant pleinement le RGPD. Les règles régissant la pseudonymisation sont définies et stockées directement dans OMrun, garantissant ainsi une traçabilité et une auditabilité totales.
OMrun peut-il s’intégrer aux pipelines d’orchestration et de CI/CD existants ?
Oui. OMrun intègre un moteur de processus capable de se connecter en natif aux principales plateformes d’orchestration et de gestion des tests : UC4 (Automic), Control-M, Tosca Testsuite, HP ALM/QC et Jenkins. OMrun peut servir d’orchestrateur principal ou être appelé en tant que processus secondaire au sein d’un pipeline d’automatisation existant, ce qui facilite son intégration dans n’importe quelle chaîne de livraison d’entreprise.
OMrun est-il adapté aux secteurs réglementés tels que la banque, l’assurance ou l’industrie pharmaceutique ?
Tout à fait. OMrun a été conçu spécialement pour les environnements réglementés. Ses rapports de comparaison vérifiables, ses fonctionnalités de pseudonymisation et ses workflows de validation automatisés en font un outil idéal pour les secteurs où l’intégrité des données, la traçabilité et la conformité sont des impératifs incontournables. Les entreprises des secteurs des services financiers, de l’assurance et de l’industrie pharmaceutique utilisent OMrun pour répondre à des exigences réglementaires strictes tout en accélérant leurs processus de traitement des données.
Ressources et liens utiles
Pour en savoir plus sur OMrun et ses fonctionnalités, consultez les ressources suivantes :
Votre solution de pointe pour vérifier et améliorer la qualité des données
See OMrun in Action

OMrun est un logiciel suisse étiqueté
swiss made software désigne des produits TIC suisses de pointe et des valeurs telles que la qualité, l’innovation et la précision dans le développement de logiciels.
Ils nous font confiance
OMrun nous a apporté une grande valeur ajoutée pendant de nombreuses années. Les tests de fumée entièrement automatisés pour chaque environnement, intégrés à un grand nombre de tests de processus d'entreprise, nous ont permis de réduire notre cycle de publication de trimestriel à bimensuel.
L'aperçu permanent des données de référence et de la qualité du processus sur le tableau de bord OMdashboard nous a permis d'accroître la productivité, la transparence ainsi que la motivation et de réduire les temps de réaction à un minimum absolu..
Nous avons utilisé OMrun pour répondre aux attentes des audits externes concernant la gestion de notre pare-feu et pour réaliser un nettoyage complet des données et plusieurs rapprochements avant la migration vers un nouveau moteur de flux de travail.
OMrun a établi la transparence de nos systèmes en un minimum de temps, ce que nous n'aurions pas pu faire par nous-mêmes.
OMrun nous a aidés dans ces domaines en très peu de temps :
Mise en place d'un rapprochement de données entre le système bancaire central Avaloq et le système de banque électronique AFS en trois jours. Les incohérences détectées ont donné lieu à un nettoyage des données et à des corrections logicielles.
Le jour suivant, la réconciliation a été automatisée afin d'assurer la cohérence quotidienne des données. Cela a généré un sentiment de confiance au sein de l'entreprise et a considérablement réduit les risques opérationnels.
En raison de ces bonnes expériences, Rothschild Bank prévoit d'étendre l'utilisation d'OMrun à d'autres applications / sources de données.
OMrun nous a permis, de manière simple et transparente, d'aligner rapidement les données de base provenant de différents systèmes de reporting et d'identifier et de corriger rapidement les erreurs potentielles. Résultat : la qualité des données dans son ensemble a été considérablement améliorée.
La coopération avec OMIS a toujours été professionnelle et motivée par un esprit de partenariat, et la réussite du projet a été assurée très rapidement.
Dans une application complexe comportant de nombreuses interfaces avec d'autres systèmes, OMrun effectue nos contrôles d'assurance qualité, comme le contrôle quotidien de l'intégrité des données, le rapprochement du grand livre et des livres auxiliaires, ainsi que les contrôles de qualité de l'entrepôt de données. Nous sommes reconnaissants à OMrun de soutenir l'assurance qualité et les contrôles internes d'une manière aussi efficace.
C'est pourquoi je suis devenu un fan d'OMrun !

Améliorez la qualité des données pour des décisions précises.
Ali Türk Account Manager
Contactez-nous