
A couple of weeks ago, I had to provide some best practices in term of architecture for a “heavy writes” environment that consists in importing data from different sources into SQL Server tables. At the customer place, I was asked about interesting new SQL Server features that could be used to increase the performance speed of the data import process. Indeed, SQL Server 2014 provides an interesting enhancement of SELECT INTO statement that is often used in ETL environments. It is now possible to run in parallel insert operations by using the SELECT INTO command.
First, let me say that for versions prior to SQL Server 2014, inserting data in parallel into a single table is possible by using SSIS packages (for instance with several import data tasks in parallel), but the destination must exist. However, it is the creation of the destination table “in-fly” that counts here.
After the release of SQL Server 2014 RTM I decided to test this new enhancement on my lab environment. The laptop I used for my tests is a Lenovo T530 with the following specifications:
- A quad core Intel Core I7 3630QM CPU @ 2,40 GHz. Hyper threading is enabled
- 16 GB RAM (max memory = 12GB for SQL Server)
- Windows 8 Pro x64
In addition I used two databases to simulate my data import workload process:
- An Adventureworks2012 database and a bigTransactionHistory table with a size of approximately 6GB and 156317184 of data rows.
- An empty AdventureWorks2012_DW database which we will import data from the bigTransactionHistory table in the AdventureWorks2012 database
- A simple recovery model for the both databases will be used during the tests
- Each database file is distributed as follows:
|
database_name |
file_id |
type_desc |
logical_name |
Drive |
size_MB |
|
AdventureWorks2012_DW |
1 |
ROWS |
AdventureWorks2012_DW |
C: |
6252 |
|
AdventureWorks2012_DW |
2 |
LOG |
AdventureWorks2012_DW_log |
D: |
8000 |
|
AdventureWorks2012_DW |
65537 |
FILESTREAM |
AdventureWorks2012_DW_xtp_ckpt |
C: |
0 |
|
AdventureWorks2012 |
1 |
ROWS |
AdventureWorks2012_Data |
C: |
6413 |
|
AdventureWorks2012 |
2 |
LOG |
AdventureWorks2012_Log |
I: |
8000 |
The C: drive is a solid-state Samsung 840 EVO drive with SATA 600. I decided to place both database mdf files on this disk because solid-state drives perform well for random IO. Unfortunately, I don’t have a second one to isolate each mdf database file, but in my context, it will be sufficient.
The D: drive is an mechanic disk with 7200 RPM and SATA 600. The AdventureWorks2012_DW transaction log file is placed here.
Finally, the I: drive is a USB drive with 5200 RPM only. It hosts the AdventureWorks2012 source database. In my context, the rotate speed of the I: drive is not important because during the test, we will only read the bigTransactionHistory table.
The hardware description of the environment is important here because the performance gain depends on many factors like the number of available processors, the amount of memory, the performance of the overall storage, the location of the database files, etc. For example, I did not notice a positive performance impact during my first tests because my mdf database files were located on slow disks, which was the main bottleneck regardless of the possibility to use (or not) the select into command in parallel.
So let’s talk about the test: First, I populated the bigTransactionHistory table based on the Adam Machanic’s script to have a sufficient size of data for a good comparison.

Then I used the following script to bulk insert data into a bigTransactionHistory2 in the AdventureWorks2012_DW database for each test:
For the first test, I changed the database compatibility of AdventureWorks2012 database to 110 in order to disable SELECT INTO statement in parallel before to lauch the import data script.
For the second test, I changed the database compatibility of the same database to 120 (like in the first test) in order to enable the new parallel capability of the SELECT INTO statement. No need to clear the procedure cache here because changing the compatibility level invalidates it automatically.
Here are the different results that I noticed:
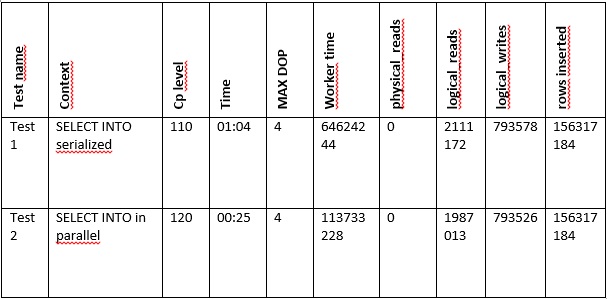
First, I noticed an important reduction of the execution time between the two tests (60%). Nevertheless, as expected in the second test, the total working time is greater than in the first test (43%), but the CPU overhead is minimal compared to the overall performance gain of the SELECT INTO statement.
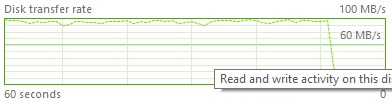
I also noticed a bigger use of the C: disk bandwidth between the two tests:
- Test 1 (SELECT INTO serialized – max throughput around 100 MB/s)
- Test 2 (SELECT INTO in parallel – max throughput around 250 MB/s)
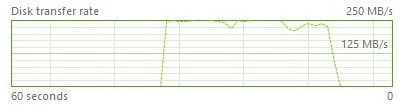
As I have said above, the disk performance is important here. Indeed, we are trying to increase the speed of the insert operation that implies increasing the disk throughput. If we can reach the maximum bandwidth of the disk with a serialized SELECT INTO operator, performing an import of data with a parallelized SELECT INTO will not guarantee a greater performance.
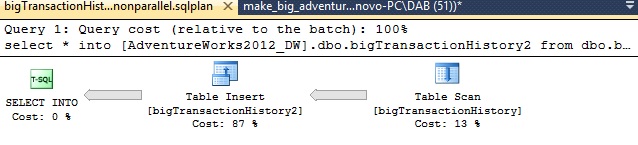
So, using the second test, I tried to confirm that the INSERT operator is used in parallel just for fun :-). We can confirm the INSERT operation in parallel by viewing the corresponding execution plan:
- Test 1 (SELECT INTO serialized)
By using the sys.dm_os_tasks, sys.dm_os_threads and sys.dm_exec_requests we can have a good overview of the dedicated threads used for the statement on a certain scheduler:
![]()
As expected, one thread was used for the first test on scheduler ID 3.
- Test 2 (SELECT INTO in parallel)

You will notice that all included Table Inserts are running in parallel.
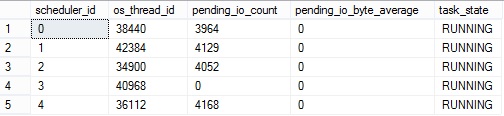
Several threads mapped to a scheduler are also used by the statement during the data processing import.
In this blog post I tried to demonstrate that using SELECT INTO in parallel can improve insert operation performances. In my opinion, this enhancement presents an interesting investment for many case scenarios with SQL Server. I’m very excited to test it in the real world with customer workloads. Please feel free to share your thoughts or your experience with me.
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/09/DDI_web-min-scaled.jpg)