
Do you use partitioning with SQL Server? If yes this post is for you because there are good news about partitioning with SQL Server 2014. I remember an old job with a healthcare customer who we decided to implement a partitioning strategy for a big transaction archive table for medical records. We used SQL Server 2005 and we already faced to some challenges like statistics updates. Database administrators who use partitioning with version older than SQL Server 2014 know what I mean.
The first news that concern this blog post is the new incremental statistic strategy provided with SQL Server 2014. This feature allows to update statistics without reading the entire table that can be a problem when your table becomes very big! Imagine for instance you have only one small active partition with recent records and a lot of changes (update, insert or delete) against 30 read only big partitions with billions of records. With SQL Server you have different strategies to update statistics by using either the sample method or the full scan method. The latter is more reliable with partitioned tables because in this case we have to deal with skewed data but requires more time (and more resources) because SQL Server have to read all the table records. With big partitioned tables we talk about potentially many hours. Adding a new non empty partition could be also problematic because we have to deal with same issue. New data are not represented into the concerned statistic.
Using incremental statistics it is possible to update only one or several partitions as necessary. The information is then gathered or merged with existing information to create the final statistic. We will see later how works this new mechanism.
During my tests I will use a modified transaction history table in the AdventureWorks2012. The table records are generated from the Adam Machanic’s T-SQL script. This table will contain 49270382 records for a total size of 2 GB. We will partition the bigTransactionHistory table as following:
Now we can create a clustered index by using the partition scheme TransactionPS1 and the new instruction STATISTICS_INCREMENTAL.
The sys.stats system view has a new is_incremental column which indicates if a statistic is incremental or not.
The new partition configuration of the bigTransactionHistory table is the following:

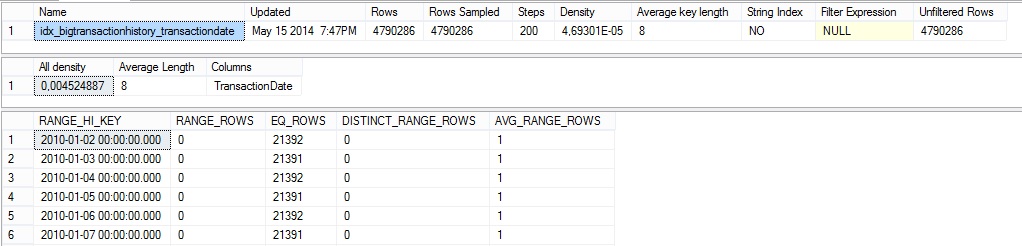
Now let’s take a look at the statistics by using the DBCC SHOW_STATS command:
DBCC SHOW_STATISTICS(‘bigtransactionhistory’,‘idx_bigtransactionhistory_transactiondate’);
![]()
…
![]()
…

We retrieve the same information as the older versions. In fact we’re trying to read statistic data from the final statistic. You will understand why later in the blog post. Note here that the final statistic can have a maximum of 200 steps. In others words currently new incremental statistics does not change the story: we already have a maximum of 200 steps for the entire table. I hope we will see some improvements maybe in the next version.
Now let’s fill up the table with some records which will have a transaction date greater than 2011-01-01 in order to move them to the last partition.
The new row has been moved to the correct partition number 8:

If we take a look at the statistic histogram of the index idx_bigtransactionhistory_transactiondate we can notice that the new record is not propagated to the existing histogram.

Of course, an update statistics is mandatory here. Before SQL Server 2014 we had to update statistics from the entire table but as said earlier we can now use a new option: WITH RESAMPLE ON PARTITIONS (). The concerned partition is the number 8 in my case. The word RESAMPLE is important here because all pages in the new statistic tree structure must be aligned with the same sample.

Good news: the incremental statistics works ! In addition the following table gives us an idea of the performance we could obtain by using the incremental statistic (I used and compared the both methods with full scan and with resample on partitions):
|
Update statistics option |
Elapsed Time (ms) |
CPU Time (ms) |
|
WITH FULLSCAN |
3085 |
20935 |
|
WITH RESAMPLE ON PARTITIONS(8) |
6 |
0 |
I guess you can easily imagine the result with this new method on a real production environment …
What about auto update statistic with incremental statistics? As you certainly know SQL Server uses a specific algorithm to update automatically statistics when the table has more than 500 rows. The update operation is triggered when the number of rows reaches 20% of the total existing rows + 500 rows. With tables that have a billions of rows, we can spend much time without any automatic update statistics operation. Besides, adding a new partition that does not modify more than 20% of the total rows will not issue an automatic update statistic operation and no information about it will not be available. Fortunately incremental statistics changes the story here. The update statistic can be triggered per partition when the number of modification reaches the threshold value = (total rows / number of partitions) * 20%.
Let’s try with the following test. In my case the bigTransactionhistory table contains 46895292 rows. According to the above formula the theoretical threshold should be: 46895292 / 8 * 0.2 = 1172383. Thus, I will update 1172892 rows in the partition number 7 to be sure to issue an automatic update statistic operation by using a SELECT statement with a predicate on the TransactionDate column.
I can confirm the number of changes is over the threshold by viewing the rowmodctr column from the legacy system view sysindexes:

Then, I perform a SELECT statement with a predicate on the TransactionDate column …
… and I can conclude the SELECT statement has issued an automatic update statistic by viewing the rowmodctr column value equal to 0 for the idx_bigtransactionhistory_transactiondate column.

The automatic update statistic operation has been issued for only 2.5% of total rows change in the entire table in my case.
Now as promise I will give you more information about statistic pages with incremental statistics. First, I would like to thank you Frédéric Pichaud, Senior Escalor Engineer at Microsoft in France, for giving us the following information. We can use the new internal dynamic management function to figure out how statistic pages are organized with incremental statistics.
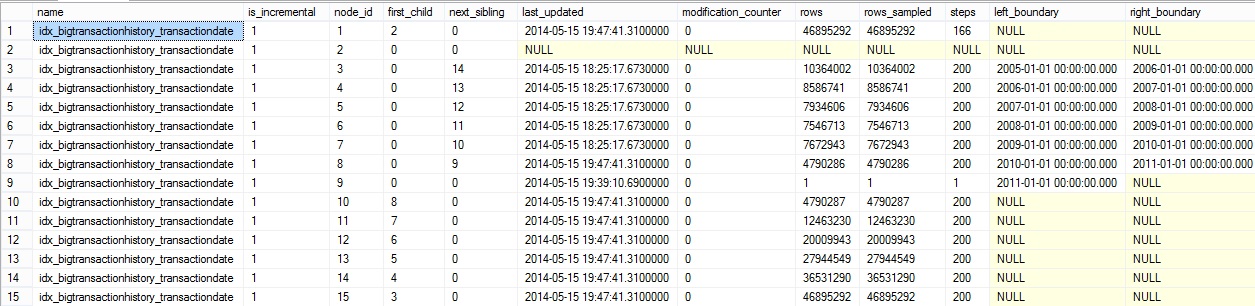
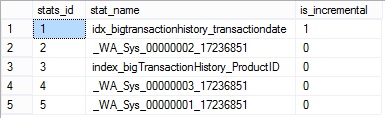
We have to focus on 3 columns here: node_id, first_child and next_cibling columns. node_id is an identifier for a page statistic. The page with the node_id equal to 1 is the final statistic page we’ve seen earlier by using DBCC SHOW_STATISTICS. This page contains the total number of rows in the bigTransactionHistory table (column rows = 46895292). We can notice that each partition, easily identifiable by the left and right boundaries, has its own page statistic (node_id 3 to 9). The first_child and the next sibling columns help us to rebuild the complete tree of statistics objects as shown below:
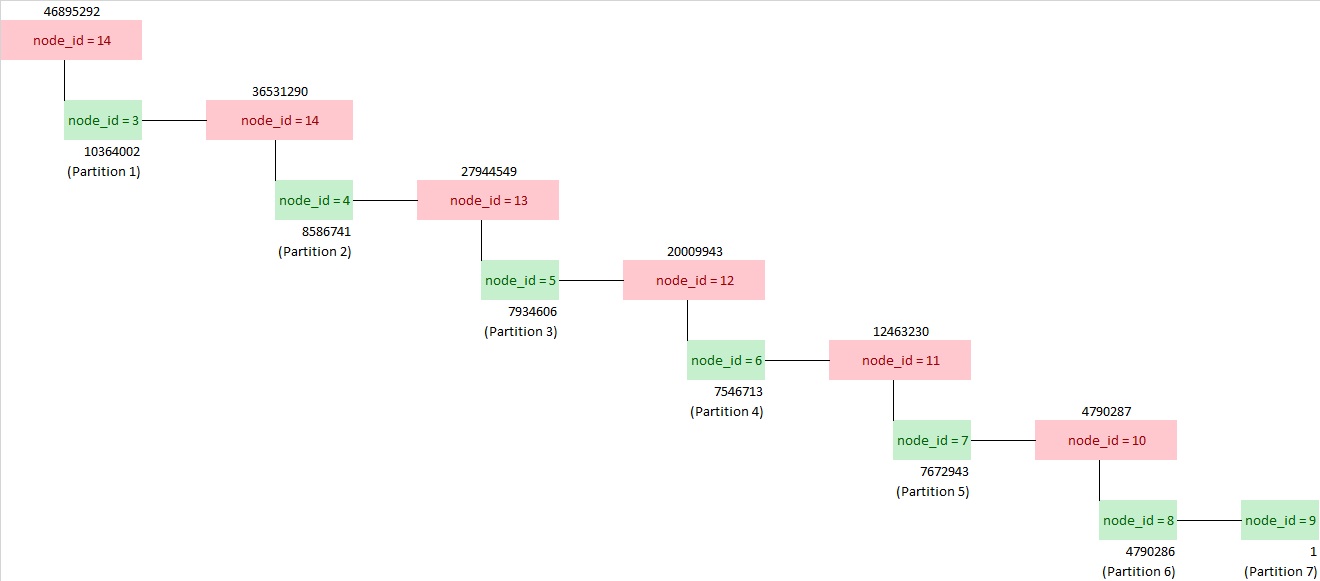
From my understanding, the green squares are the statistic page at the leaf level linked to a partition and red squares are the binary merge pages. For instance pages with node_id = 8 (4790286 rows) and 9 (1 row) are merged to the page with node_id = 10 (4790286 + 1 = 4790287). In turn, the page with node_id = 7 (7672943 rows) and the page with node_id = 10 are merged into the page with node_id = 12 (7672943 + 4790287 = 12463230) and so on… The page with node_id = 1 is the final page statistic that merges all the others pages. The page with node_id = 2 is a reserved page for future needs.
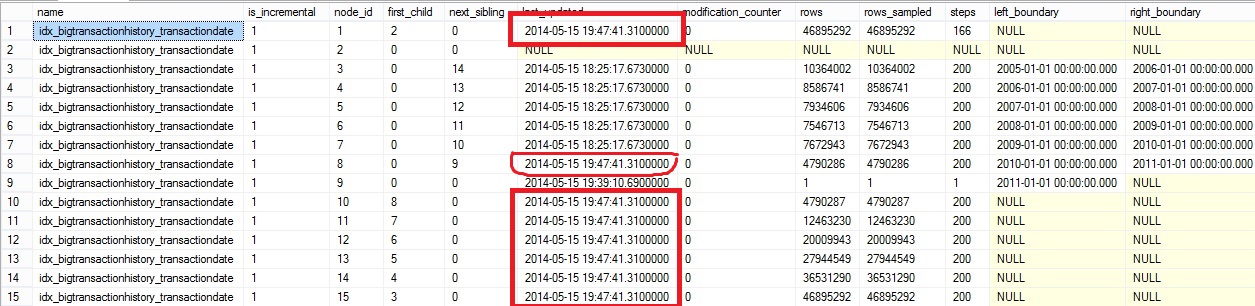
Earlier in the blog post we issued an automatic update statistic and the partition with the number 10 was concerned. The page with node_id = 8 is linked to this partition and we can notice the update statistic propagation throughout the statistic objects tree. Only the page statistic of this partition is updated with all the merge pages.
Finally we can use the traceflag 2309 to see the detail of a page in the statistic tree. After enabling this traceflag we can use the DBCC SHOW_STATISTICS command with an additional third parameter node_id
The results is the same as a classic DBCC SHOW_STATISTICS command but the detail is only for the concerned page in the tree. Enabling this traceflag is only for debugging purpose. For instance if we suspect a general update statistic issue we can try to identify which pages are relevant.
Database administrators who faced to statistics problems with partitioned tables will probably have fun to try this new feature. See you soon for the next good news about partitioning 😉
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/09/DDI_web-min-scaled.jpg)