This is Part II of a tour of rlwrap for idql/iapi. For Part I, please follow the link here.
Enhanced output visualization
This is one rlwrap’s most fantastic enhancement. It is not that different from what I suggested here only much smoother.
idql does not provide any flexible formatting and lines longer than the screen width get wrapped around, which results in hard to read output. rlwrap’s pipeto filter lets redirect this output to another executable, typically a capable pager such as less, as illustrated below with a query returning very long lines:
rlwrap --filter=pipeto --ansi-colour-aware --prompt-colour=RED --multi-line='__' idql dmtest72 -Udmadmin -Pdmadmin 1> select * from dm_user __ go __ | less -#10 -S r_object_id user_name ... ---------------- ------------------------------------------------... 1100c39880000110 dm_sysadmin 1100c39880000111 dm_create_user 1100c39880000112 dm_create_type 1100c39880000113 dm_create_group 1100c39880000114 dm_create_cabinet 1100c39880000115 dm_create_table ... 1100c3988000014d dmc_wdk_presets_coordinator 1100c3988000014e express_user (54 rows affected) (END)
Finally, a clear and readable output ! The -S (or ––chop-long-lines) parameter tells less not to wrap the lines longer than the screen width but to truncate them instead. This results in a cleaner screen. As less allows the output to be scrolled laterally, the user experience is now one hundred orders of magnitude more pleasant. The -#N tells less to scroll laterally by that amount of columns. It can be also changed interactively inside less via the same command -# followed by a number of columns.
Any executable can be used as a filter and such filters can be chained together for quite some flexibility. Now, if the filter is programmable like when using sed and awk, the output can finally be tamed any way we want. Here are some examples:
-- bracketed any r_object_id:
select * from dm_document __ go__ | gawk '{if (match($0, /([0-9a-f]{16})/, f)) {print substr($0, 1, RSTART - 1) "[" f[1] "]" substr($0, RSTART + RLENGTH)} else print}' | less -#10 -S
r_object_id object_name ...
---------------- ----------------------------------- ...
[0900c398800001d0] Default Signature Page Template
[6700c39880000100] CSEC Plugin
[6700c39880000101] Snaplock Connector
[0900c398800001da] Blank PowerPoint Pre-3.0 Presentation
[0900c398800001db] Blank WordPerfect 6 Document
[0900c398800001dc] Blank WordPerfect 7 Document
[0900c398800001dd] Blank WordPerfect 8 Document
[0900c398800001de] Blank Excel Workbook 5.0-7.0 Document
...
(817 rows affected)
-- same but shorter:
select * from dm_document __ go__ | gawk '{gsub(/([0-9a-f]{16})/, "[&]", $0); print}' | less -#10 -S
-- better, with colorization of the r_object_id using ANSI code sequences:
select * from dm_document __ go__ | gawk '{gsub(/([0-9a-f]{16})/, "[\033[1m\033[31m&\033[0m]", $0); print}' | less -#10 -R -S

Note less‘ -R option (or ––RAW-CONTROL-CHAR) so the ANSI codes are not processed by less but output as-is, resulting in them being correctly interpreted by the terminal. Note also that color rendering differs somewhat between terminal programs, xterm is quite accurate, terminator a bit off sometimes, see the comparison between several terminal emulators below.
For simple filter patterns, less internal search with regular expression can also do the job of highlighting the matches.
As written above, several rlwrap’s filters can be specified at once through the pipeline filter and we can define a macro that uses the pipe filter as well. Let’s revisit the above $sc to illustrate this:
rlwrap --no-warnings --filter='pipeline simple_macro:pipeto' --ansi-colour-aware --prompt-colour=RED --multi-line='__' iapi dmtest72 -Udmadmin -Pdmadmin
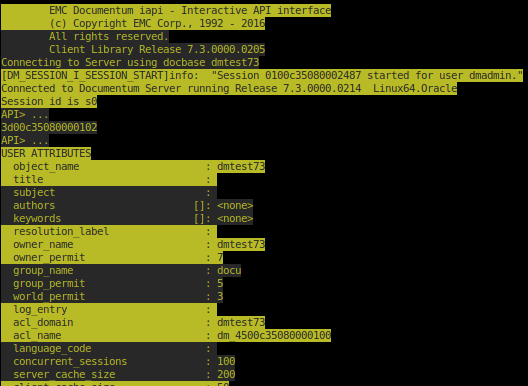
$sc((retrieve,c,dm_server_config ^Mdump,c,l^M | gawk 'BEGIN {col[0]="\033[1m\033[31m"; col[1]="\033[1m\033[92m"; reset="\033[0m"} {print col[NR%2] $0 reset}'))
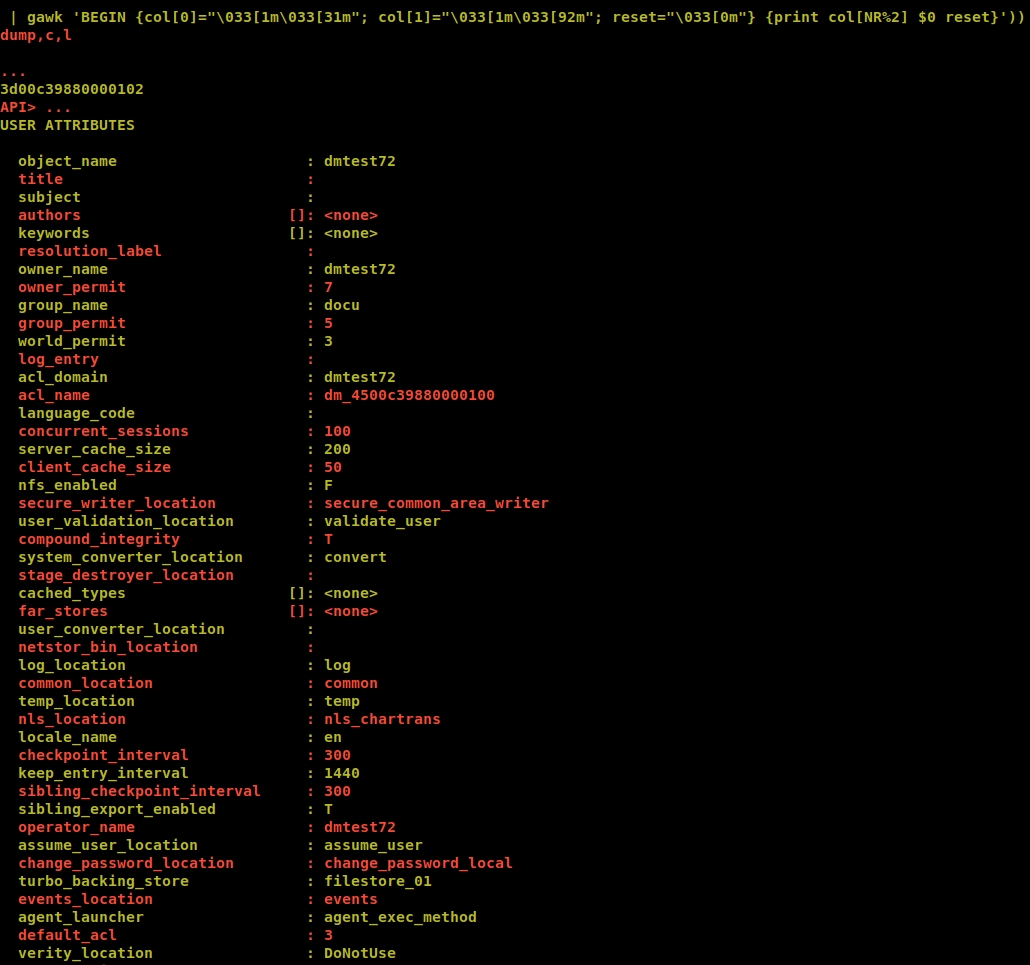
Color alternation really adds more readability to the output. Those long, indecipherable listings of properties are henceforth a thing of the past !
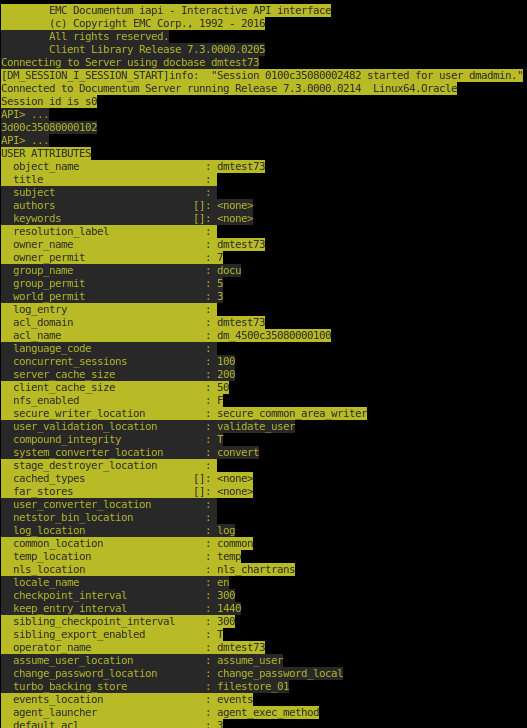
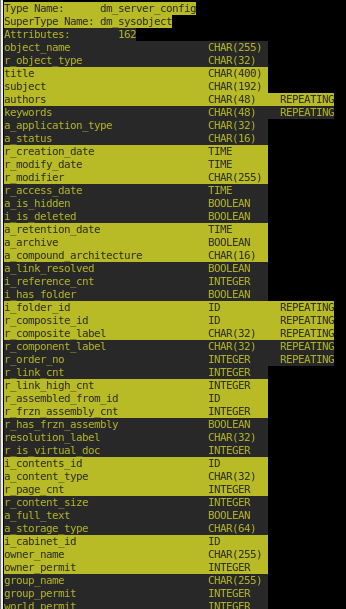
All this is nice but yet again we are stumbling against another limitation of idql: as shown in the image above, the displayed column width’s are determined by their definition in the repository not their actual content. E.g.:
1> describe dm_user Type Name: dm_user SuperType Name: Attributes: 43 user_name CHAR(255) user_os_name CHAR(32) user_address CHAR(300) user_group_name CHAR(255) ...
So, even though the user_name never exceed, say, 30 characters, 255 characters are actually always displayed, the ones plus as many trailing blanks needed to fill up the field width of 255 characters. That’s a lot of blanks ! Even with less‘ horizontal scrolling capability, there is a lot of scrolling to reach the useful information.
To be honest, both idql’s and iapi’s rarely used -W|-w command-line parameter gives some control but this option truncates the output without warning and is applied indiscriminately to all the displayed columns; surprinsingly, -W|-w is also a command of both idql and iapi, but with an odd syntax.
Oracle sql*plus has the col format command to narrow the width but rlwrap and its filtering functionality can help here too in providing the first step towards the solution. However, we have to write the filter ourselves. In past blogs, I proposed gawk filters for this purpose (see here); I also proposed some possible enhancements for the future. Now, for the special occasion, I implemented a few of them in a new release of compact_or_truncate_wwa. Here it comes:
cat compact_or_truncate_wwa.awk
# Usage:
# gawk [-v maxw=nn] [-v optimal_breadths=n1,n2,...] [-v truncate=0|1] [-v ellipsis=...] [-v wrap=1|0] -f compact_wwa.awk file
# or:
# cmd | gawk [-v maxw=nn] [-v optimal_breadths=n1,n2,...] [-v truncate=0|1] [-v ellipsis=...] [-v wrap=1|0] -f compact_wwa.awk
# where:
# missing numeric parameters assume the value 0;
# maxw is the maximum column width and defaults to 32;
# characters outside this limit are either wrapped around in their own column or truncated, depending on the parameters truncate and wrap;
# optimal_breadths is a comma-separated list of numbers for the column widths to use instead of the ones from the dictionary, in same order as the displayed columns;
# there can be less values than columns, in which case non-specified columns are not constrained;
# if there are more, extra-values are ignored;
# truncation of wrapping can still occur if maxw < optimal_breadths[i] for column i;
# wrapping is the default and has priority over truncating;
# truncate=0 wrap=0 --> wrapping around;
# truncate=0 wrap=1 --> wrapping around;
# truncate=1 wrap=0 --> truncate;
# truncate=1 wrap=1 --> wrapping around;
# truncating is therefore only done when explicitly and unambiguously requested; this is to preserve data integrity whenever possible;
# ellipsis string is only considered when truncating and defaults to '...'; thus, there is always one to warn of truncation;
# example:
# gawk -v maxw=50 -f compact_wwa.awk tmp_file | less -S
# C. Cervini, dbi-services;
BEGIN {
if (!maxw) maxw = 32
if (!truncate)
if (!wrap)
wrap = 1
else;
else if (!wrap);
else
truncate = 0
if (!ellipsis)
ellipsis = "..."
# ingest optimal_breadths if given;
delete optimal_breadths_tab
if (optimal_breadths)
nb_widths = split(optimal_breadths, optimal_breadths_tab, ",")
else
nb_widths = 0
while (getline && !match($0, /^-+/))
header = $0
# header now contains the header line and $0 the separation line;
nbFields = NF
fs[0] = 0; fw[0] = -1 # just so that fs[1] = 1, see below;
headerLine = ""; sepLine = ""
for (i = 1; i <= NF; i++) {
fs[i] = fs[i - 1] + fw[i - 1] + 2
fw[i] = length($i)
if (!nb_widths || nb_widths < i)
optimal_breadths_tab[i] = fw[i]
Min = min3(fw[i], optimal_breadths_tab[i], maxw)
if (1 == truncate)
Min = max(Min, length(ellipsis))
sepLine = sepLine sprintf("%s ", substr($0, fs[i], Min))
}
delete empties
delete optimal_widths
max_header_length = 0
printWithWA(1, header)
print sepLine
}
{
if (match($0, /^\([0-9]+ rows? affected\)/)) {
print
exit
}
printWithWA(0, $0)
}
function printWithWA(isHeader, S , i, Min, columnS, restColumn, restS, left_over) {
# find the query's optimal column widths, i.e. maximum column width when trailing blanks are removed;
# empty columns are candidates to be removed from query and will be reported;
for (i = 1; i <= nbFields; i++) {
# see if there is any data in that row's columns;
columnS = substr(S, fs[i], fw[i])
if (!isHeader) {
gsub(/ +$/, "", columnS)
optimal_widths[i] = max(length(columnS), optimal_widths[i])
empties[i] = empties[i] && !columnS
}
else {
empties[i] = 1
gsub(/ +$/, "", columnS)
headers[i] = columnS
optimal_widths[i] = length(columnS)
max_header_length = max(max_header_length, optimal_widths[i])
}
}
do {
left_over = ""
for (i = 1; i <= nbFields; i++) {
Min = min3(fw[i], optimal_breadths_tab[i], maxw)
if (1 == truncate)
Min = max(Min, length(ellipsis))
columnS = sprintf("%-*s", Min, substr(S, fs[i], Min))
if (1 == truncate) {
restColumn = substr(S, fs[i] + Min, fw[i] - Min); gsub(/ +$/, "", restColumn)
if (restColumn)
columnS = substr(columnS, 1, length(columnS) - length(ellipsis)) ellipsis
}
printf("%s ", columnS)
restS = substr(S, fs[i] + Min, fw[i] - Min)
if (length(restS) > 0) {
left_over = left_over sprintf("%-*s ", fw[i], restS)
}
else
left_over = left_over sprintf("%*s ", fw[i], "")
}
printf "\n"
gsub(/ +$/, "", left_over)
S = left_over
} while (left_over && wrap)
}
END {
print "following empty columns could be removed from query:"
bempty = 0
non_empty = ""
for (i = 1; i <= nbFields; i++)
if (empties[i]) {
printf("%s%s", bempty ? ", " : "", headers[i])
bempty = 1
}
else
non_empty = non_empty (non_empty ? ", " : "") headers[i]
if (bempty) {
printf "\n"
print "empty columns found for the current query; they could be removed"
print "compacter query could be: select " non_empty " from ..."
}
else {
print "no empty columns found for the current query"
print "cannot compact query: select " non_empty " from ..."
}
print "\noptimal (i.e. without trailing blanks) column widths for the current query:"
printf("%-*s %-10s %-13s %-13s %s\n", max_header_length, "headers", "repo width", "optimal width", "present width", "?")
boptimal_found = 0
optimal_widths_str = ""
for (i = 1; i <= nbFields; i++) {
printf("%-*s %10d %13d %13d %s\n", max_header_length, headers[i], fw[i], optimal_widths[i], optimal_breadths_tab[i], optimal_widths[i] != optimal_breadths_tab[i] ? "*" : "")
boptimal_found = boptimal_found || (optimal_widths[i] < fw[i] && optimal_widths[i] != optimal_breadths_tab[i])
optimal_widths_str = optimal_widths_str (optimal_widths_str ? "," : "") optimal_widths[i]
}
if (boptimal_found)
print "Suggestion: re-run the query and set the filter parameter optimal_widths=" optimal_widths_str
else
print "column widths are already optimal"
}
function min3(x, y, z) {
return(x <= y ? (x <= z ? x : z) : (y <= z ? y : z))
}
function min(x, y) {
return(x <= y ? x : y)
}
function max(x, y) {
return(x >= y ? x : y)
}
Usage:
rlwrap --filter='pipeline simple_macro:pipeto' --ansi-colour-aware --prompt-colour=RED --multi-line='__' idql dmtest72 -Udmadmin -Pdmadmin
select r_object_id, object_name, title, subject, owner_name, owner_permit, group_name, group_permit, world_permit, acl_domain, acl_name, r_object_type, r_creation_date, r_modify_date, a_content_type from dm_document __ go__ | gawk -v RS='[\r|\n]+' -v maxw=50 -v optimal_breadths=16,40,40,40,21,12,10,12,12,10,19,25,19,19,17 -v truncate=0 -v wrap=1 -f compact_or_truncate_wwa.awk | gawk '{gsub(/^([0-9a-f]{16})/, "\033[1m\033[92m&\033[0m", $0); print}' | less -#1 -R -S
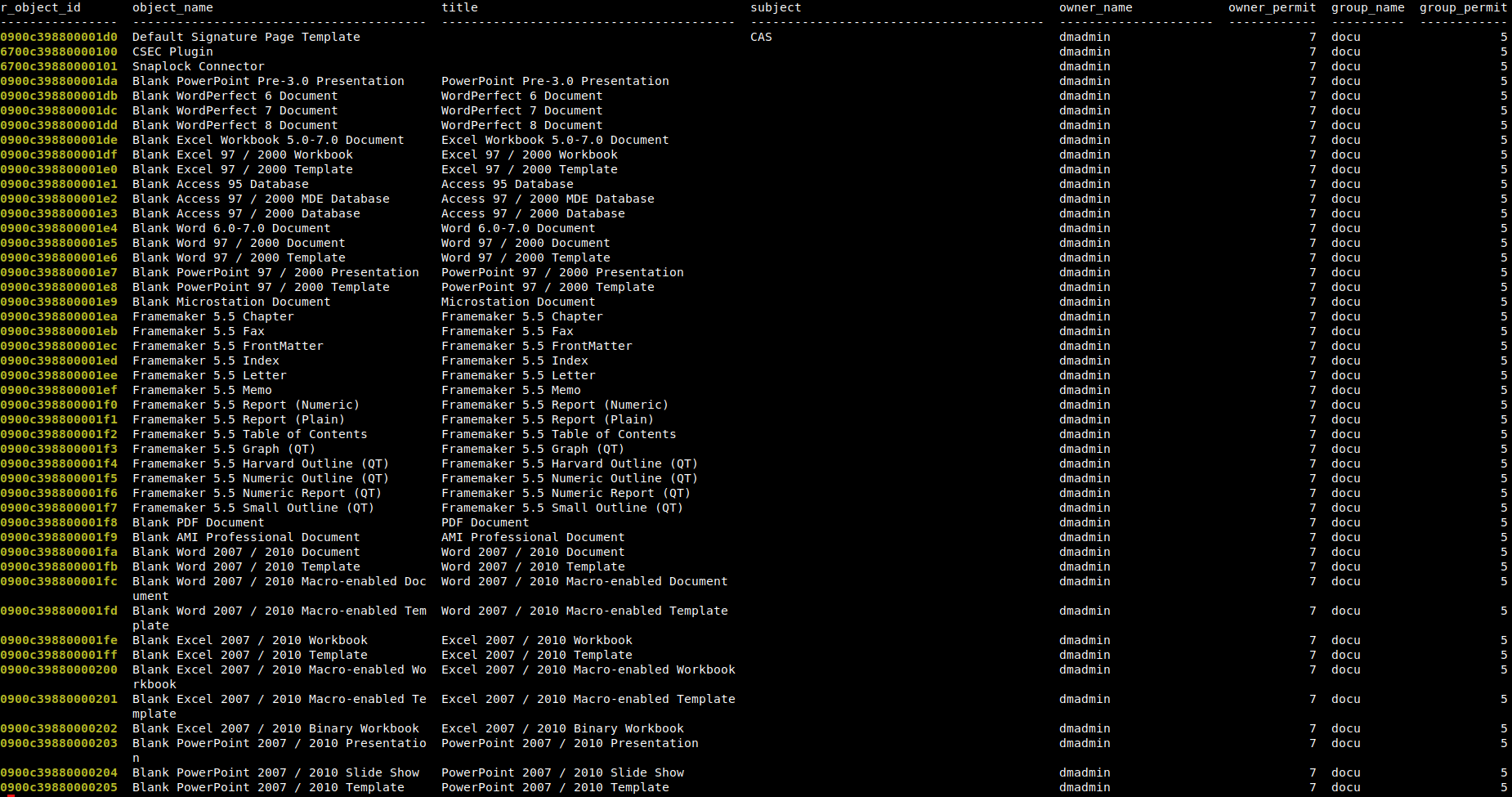
Here, the column formatting script compact_or_truncate_wwa.awk is invoked and its output is submitted to the second filter for highlighting the r_object_id in bright green color. compact_or_truncate_wwa.awk could do everything by itself but this is not the point as we want to show filter chaining here. Besides, it would not be a good idea from a design point of view.
Want to alternate colors for an even better visual experience ? Here we go:
$ rlwrap --no-warnings --filter='pipeline simple_macro:pipeto' --ansi-colour-aware --prompt-colour=RED --multi-line='__' idql dmtest72 -Udmadmin -Pdmadmin
select r_object_id, object_name, title, subject, owner_name, owner_permit, group_name, group_permit, world_permit, acl_domain, acl_name, r_object_type, r_creation_date, r_modify_date, a_content_type from dm_document __ go__ | gawk -v RS='[\r|\n]+' -v maxw=50 -v optimal_breadths=16,40,40,40,21,12,10,12,12,10,19,25,19,19,17 -v truncate=0 -v wrap=1 -f compact_or_truncate_wwa.awk | gawk 'BEGIN {col[0]="\033[1m\033[93m"; col[1]="\033[1m\033[94m"; reset="\033[0m"; l = 0} {printf("%s%s%s\n", !match($0, /^[0-9a-f]{16}/) ? col[l%2] : col[++l%2], $0, reset)}' | less -#1 -R -S
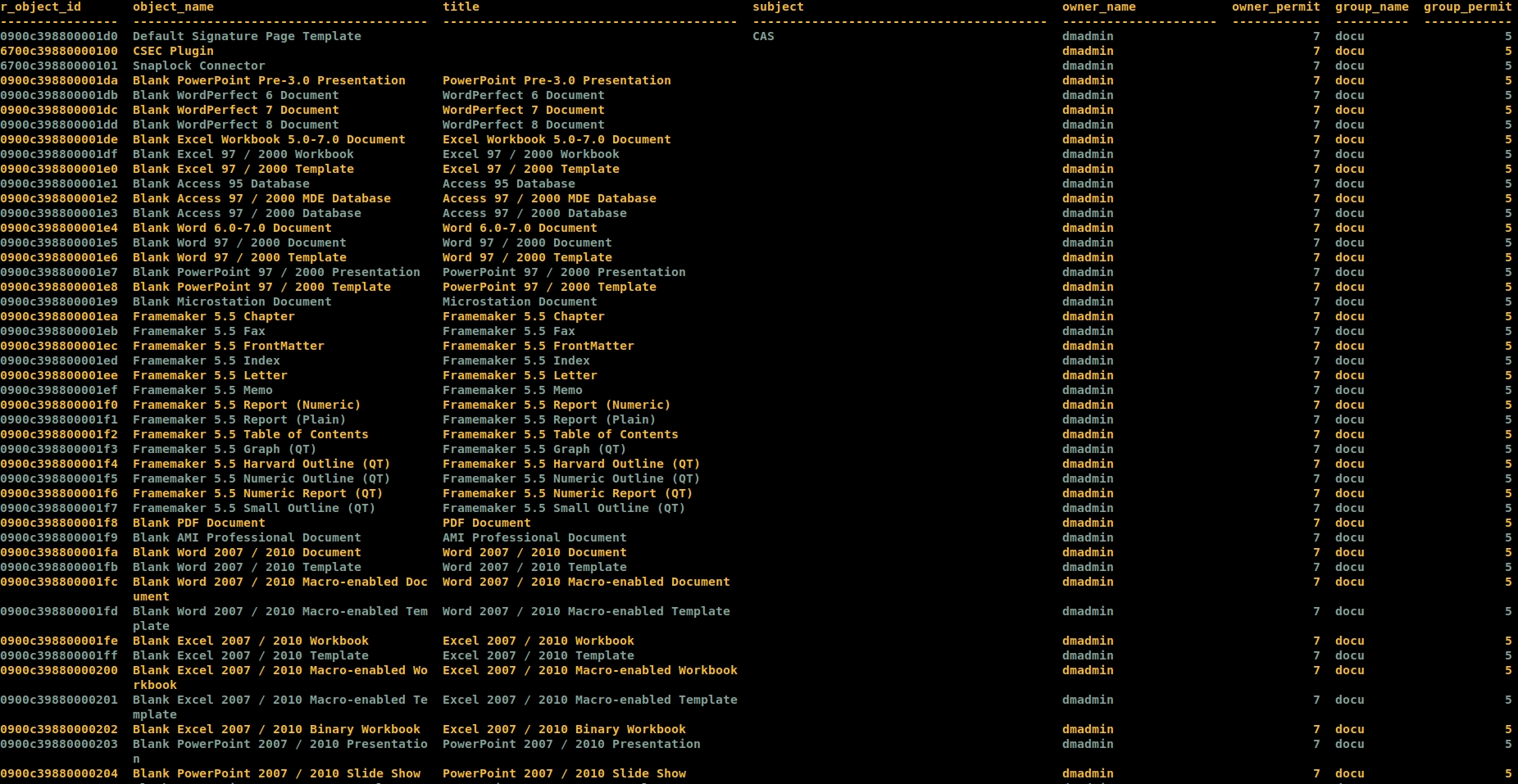
Why not make a macro out of it ?
rlwrap --no-warnings --filter='pipeline simple_macro:pipeto' --ansi-colour-aware --prompt-colour=RED --multi-line='__' iapi dmtest72 -Udmadmin -Pdmadmin
-- define the ac macro for the first alternate coloring gawk one-liner:
$ac((gawk -v RS="[\n\r]+" 'BEGIN {col[0]="\033[1m\033[31m"; col[1]="\033[1m\033[92m"; reset="\033[0m"} {print col[NR%2] $0 reset}' | less -S -R))
-- invoke it:
select * from dm_user | $ac
Want a more pleasing, yet somewhat flashy, alternated color display by being able to specify the grouping size (parameter alt_col, set to 5 here) ? No problem:
$ rlwrap --no-warnings --filter='pipeline simple_macro:pipeto' --ansi-colour-aware --prompt-colour=RED --multi-line='__' idql dmtest72 -Udmadmin -Pdmadmin
select r_object_id, object_name, title, subject, owner_name, owner_permit, group_name, group_permit, world_permit, acl_domain, acl_name, r_object_type, r_creation_date, r_modify_date, a_content_type from dm_document ^Mgo^M | gawk -v RS='[\r|\n]+' -v maxw=50 -v optimal_breadths=16,40,40,192,21,12,10,12,12,10,19,25,19,19,17 -v truncate=0 -v wrap=1 -f compact_or_truncate_wwa.awk | gawk -v alt_col=5 'BEGIN {col[0]="\033[93m\033[101m"; col[1]="\033[91m\033[103m"; reset="\033[0m"; l = 0; col_idx = 0; beoset = 0; getline; print; getline; print}{if (!(beoset = beoset || match($0, /^\([0-9]* rows affected\)/))) printf("%s%s%s\n", !match($0, /^[0-9a-f]{16}/) ? col[col_idx] : col[0 == l++%alt_col ? col_idx = ++col_idx % 2 : col_idx], $0, reset); else print}' | less -#1 -R -S
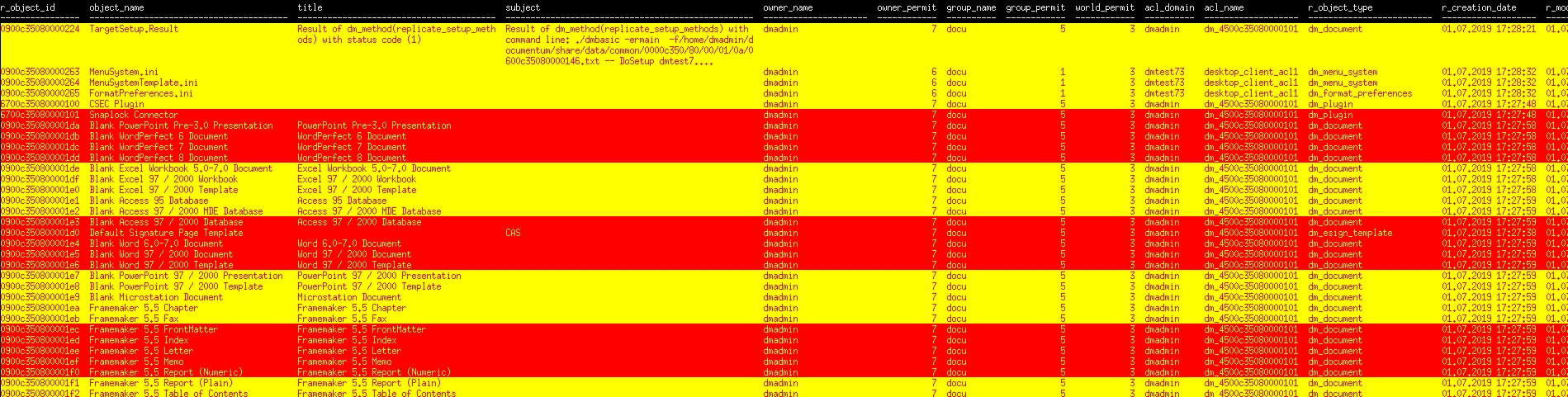
If you copy/paste the above select line, make sure to enter the ^M characters by typing ^V followed by ^M, or use the character string defined in rlwrap’s ––multi-line argument, e.g.:
$ rlwrap ... --multi-line='__' select ... from ... __ go __ ...
Let’s define a macro for the complicated highlighting filter above:
$ rlwrap --no-warnings --filter='pipeline simple_macro:pipeto' --ansi-colour-aware --prompt-colour=RED --multi-line='__' idql dmtest72 -Udmadmin -Pdmadmin
...
1> $hl_ac((gawk -v alt_col=5 'BEGIN {col[0]="\033[93m\033[101m"; col[1]="\033[91m\033[103m"; reset="\033[0m"; l = 0; col_idx = 0; beoset = 0; while ((getline > 0) && !match($0, /^(-+ *)+/) ) header = $0; print header; print $0}{if (!(beoset = beoset || match($0, /[0-9]* rows affected/) ) ) printf("%s%s%s\n", !match($0, /^[0-9a-f]{16}/) ? col[col_idx] : col[0 == l++%alt_col ? col_idx = ++col_idx % 2 : col_idx], $0, reset); else print}' | less -S -R))
sh: 1: Syntax error: "|" unexpected
2> clear
...
1> select r_object_id, object_name, title, subject, owner_name, owner_permit, group_name, group_permit, world_permit, acl_domain, acl_name, r_object_type, r_creation_date, r_modify_date, a_content_type from dm_document __ go __ | gawk -v RS='[\r|\n]+' -v maxw=50 -v optimal_breadths=16,40,40,192,21,12,10,12,12,10,19,25,19,19,17 -v truncate=0 -v wrap=1 -f compact_or_truncate_wwa.awk | $hl_ac
...
On line 3, we have carefully rewritten “))” respectively “)))” to “) )” and “) ) )”. Also, the “||” operator and the shell pipe symbol | cause an harmless error on line 5.
All these highlighting filters take into account the fact that some columns may be wrapped on several physical lines depending on the formatting parameters.
The filter compact_or_truncate_wwa.awk accepts the parameter optimal_breadths, a list of column widths so that it can truncates the columns that hold too long strings; this is aimed at trailing blanks, so no visible information is lost. The script itself helps in finding these optimal widths; it also finds the columns in the output that have no values in any of the returned rows so that these columns can be removed from the query, resulting in an even narrower table, e.g.:
select * from dm_document __ go__ | gawk -v RS='[\r|\n]+' -v maxw=50 -v truncate=0 -v wrap=1 -f compact_or_truncate_wwa.awk | gawk '{gsub(/^([0-9a-f]{16})/, "\033[1m\033[92m&\033[0m", $0); print}' | less -#1 -R -S1
...
(825 rows affected)
following empty columns could be removed from query:
resolution_label, log_entry, language_code
empty columns found for the current query; they could be removed
compacter query could be: select r_object_id, object_name, title, subject, owner_name, owner_permit, group_name, group_permit, world_permit, acl_domain, acl_name, r_object_type, r_creation_date, r_modify_date, a_content_type from ...
optimal (i.e. without trailing blanks) column widths for the current query:
headers repo width optimal width present width ?
r_object_id 16 16 16
object_name 255 55 255 *
title 400 68 400 *
subject 192 192 192
resolution_label 32 16 32 *
owner_name 255 21 255 *
owner_permit 12 12 12
group_name 255 10 255 *
group_permit 12 12 12
world_permit 12 12 12
log_entry 120 9 120 *
acl_domain 255 10 255 *
acl_name 32 19 32 *
language_code 13 13 13
r_object_type 32 25 32 *
r_creation_date 25 19 25 *
r_modify_date 25 19 25 *
a_content_type 32 17 32 *
Suggestion: re-run the query and set the filter parameter optimal_widths=16,55,68,192,16,21,12,10,12,12,9,10,19,13,25,19,19,17
On line 5, the script identified columns resolution_label, log_entry, language_code as empty columns in the whole query’s output; unselecting them would result in a compacter output table but as it is not possible to specify columns to be skipped, only columns to be selected, a better dql SELECT clause is proposed on line 7.
This is a first optimization. Next, the column widths as defined in the repository’s dictionary, the optimal column widths (after trailing blanks are removed) and the ones currently used (if constraints were specified in the parameter optimal_breadths) are listed in a table starting on line 10. Here for example, we can see that the attribute object_name can held up to 255 characters but it contains only up to 55 characters in any row of the whole output of this particular query; nevertheless, idql padded this column in all the rows with more than 200 trailing spaces. By imposing than no more than 55 characters should be used for this column, we can get rid of those spaces without truncation needed. This check is performed for all the columns and a string of optimal column widths is built up, ready to be used as parameter optimal_widths in the gawk script. Obviously, this optimization requires 2-steps, one for determining the best column widths and one to use them, and each step requires a run, if the suggestion is accepted.
In addition, the parameter maxw imposes a general maximum column width and the characters in excess are either truncated or wrapped on the next line(s), depending on the parameters truncate and wrap (see comments in script for details, or the article). When truncating, maxw works like the – W|-w command-line parameter or command.
If we wanted to get geeky, we could modify the script so that, if told so, after it has determined the optimal SELECT clause and column widths, it would re-run itself; we would need to pass the whole query, or at least the other clauses (FROM, WHERE, etc.) as well.
Although the command-line to invoke idql from rlwrap is not that complicated, it is still hard to remember and a function alias can be defined to alleviate this. Here is an example of such function to be added into ~/.bashrc:
# enhanced idql with rlwrap for any target;
function xidql() {
rlwrap --filter='pipeline simple_macro:pipeto' --ansi-colour-aware --prompt-colour=RED --multi-line='__' idql $*
}
# test idql;
function tidql() {
rlwrap --filter='pipeline simple_macro:pipeto' --ansi-colour-aware --prompt-colour=RED --multi-line='__' idql dmtest72 -Udmadmin -Pdmadmin $*
}
-- source it:
. ~/.bashrc
-- invoke it:
xidql my_repo -Udmadmin -Pxyz ...
tidql
A nice filter and a quirk
As the alternating color filter is so good, let’s generalize it for any input, not just a SELECT’s result set. In order to test it, suppose we’d like to dump the dm_server_config object, usually the first one; we are in idql and we’ll invoke iapi for the dump; the problem is that we cannot pass parameters to iapi, but we can pass statements. Let’s use the semi-colon “;” character as a separator:
rlwrap --filter='pipeline simple_macro:pipeto' --ansi-colour-aware --prompt-colour=RED --multi-line='__' idql $*
-- pass the statements to iapi and pipe to the in-line gawk filter;
1> echo retrieve,c,dm_server_config;dump,c,l|sed 's/;/\n/' | iapi dmtest73 -Udmadmin -Pdmadmin | gawk -v alt_col=3 -v RS='[\n\r]+' 'BEGIN {col[0]="\033[92m\033[40m"; col[1]="\033[30m\033[102m"; reset="\033[0m"; l = 0; col_idx = 0}{printf("%s%s%s\n", col[0 == l++%alt_col ? col_idx = ++col_idx % 2 : col_idx], $0, reset)}' | less -S -R
1> echo retrieve,c,dm_server_config;dump,c,l|sed 's/;/\n/' | iapi dmtest73 -Udmadmin -Pdmadmin | gawk -v alt_col=3 -v RS='[\n\r]+' 'BEGIN {col[0]="\033[92m\033[40m"; col[1]="\033[30m\033[102m"; reset="\033[0m"; l = 0; col_idx = 0}{printf("%s%s%s\n", col[0 == l++%alt_col ? col_idx = ++col_idx % 2 : col_idx], , reset)}' | less -S -R
gawk: cmd. line:1: BEGIN {col[0]="\033[92m\033[40m"; col[1]="\033[30m\033[102m"; reset="\033[0m"; l = 0; col_idx = 0}{printf("%s%s%s\n", col[0 == l++%alt_col ? col_idx = ++col_idx % 2 : col_idx], , reset)}
gawk: cmd. line:1: ^ syntax error
See what happened in the printf() statement ? $0 was removed which caused a syntax error; the simple work-around is to assign $0’s content to another variable without mentioning $0 explicitly. This is possible by using any gawk’s function that takes an optional parameter defaulting to $0, e.g. gensub(), as follows:
echo retrieve,c,dm_server_config;dump,c,l|sed 's/;/\n/' | iapi dmtest73 -Udmadmin -Pdmadmin | gawk -v alt_col=3 -v RS='[\n\r]+' 'BEGIN {col[0]="\033[92m\033[40m"; col[1]="\033[30m\033[102m"; reset="\033[0m"; l = 0; col_idx = 0}{s = gensub(/^(.+)$/, "\\1", "g"); printf("%s%s%s\n", col[0 == l++%alt_col ? col_idx = ++col_idx % 2 : col_idx], s, reset)}' | less -S -R
gensub() is used for substitution but here it is parameterized so to do a neutral edition of $0 implicitly, i.e. change $0 to itself; as a side effect, $0 is assigned to s.
But the alternating color filter is too good not to make a reusable macro out of it:
rlwrap --filter='pipeline simple_macro:pipeto' --ansi-colour-aware --prompt-colour=RED --multi-line='__' idql $*
-- definition of the $ac macro;
$ac((gawk -v alt_col=3 -v RS='[\n\r]+' 'BEGIN {col[0]="\033[92m\033[40m"; col[1]="\033[30m\033[102m"; reset="\033[0m"; l = 0; col_idx = 0}{printf("%s%s%s\n", col[0 == l++%alt_col ? col_idx = ++col_idx % 2 : col_idx], $0, reset)}' | less -S -R))
-- let's use it:
describe dm_server_config | $ac
Incidentally, the macro works around the above quirk too:
rlwrap --filter='pipeline simple_macro:pipeto' --ansi-colour-aware --prompt-colour=RED --multi-line='__' idql $*
-- definition of the $ac macro;
$ac((gawk -v alt_col=3 -v RS='[\n\r]+' 'BEGIN {col[0]="\033[92m\033[40m"; col[1]="\033[30m\033[102m"; reset="\033[0m"; l = 0; col_idx = 0}{printf("%s%s%s\n", col[0 == l++%alt_col ? col_idx = ++col_idx % 2 : col_idx], $0, reset)}' | less -S -R))
-- pass the statements to iapi and pipe to the $ac macro;
echo retrieve,c,dm_server_config;dump,c,l|sed 's/;/\n/' | iapi dmtest73 -Udmadmin -Pdmadmin | $ac
The morale here is to prefer macros over in-line filters, both for reusability and to work around possible quirks. In addition, if the script is too complex, then save it into a text file and pass it to the interpreter, as illustrated with compact_or_truncate_wwa.awk above.
Color rendition is highly dependent on the terminal emulator. Here is a screen capture of 5 common emulators for Linux:
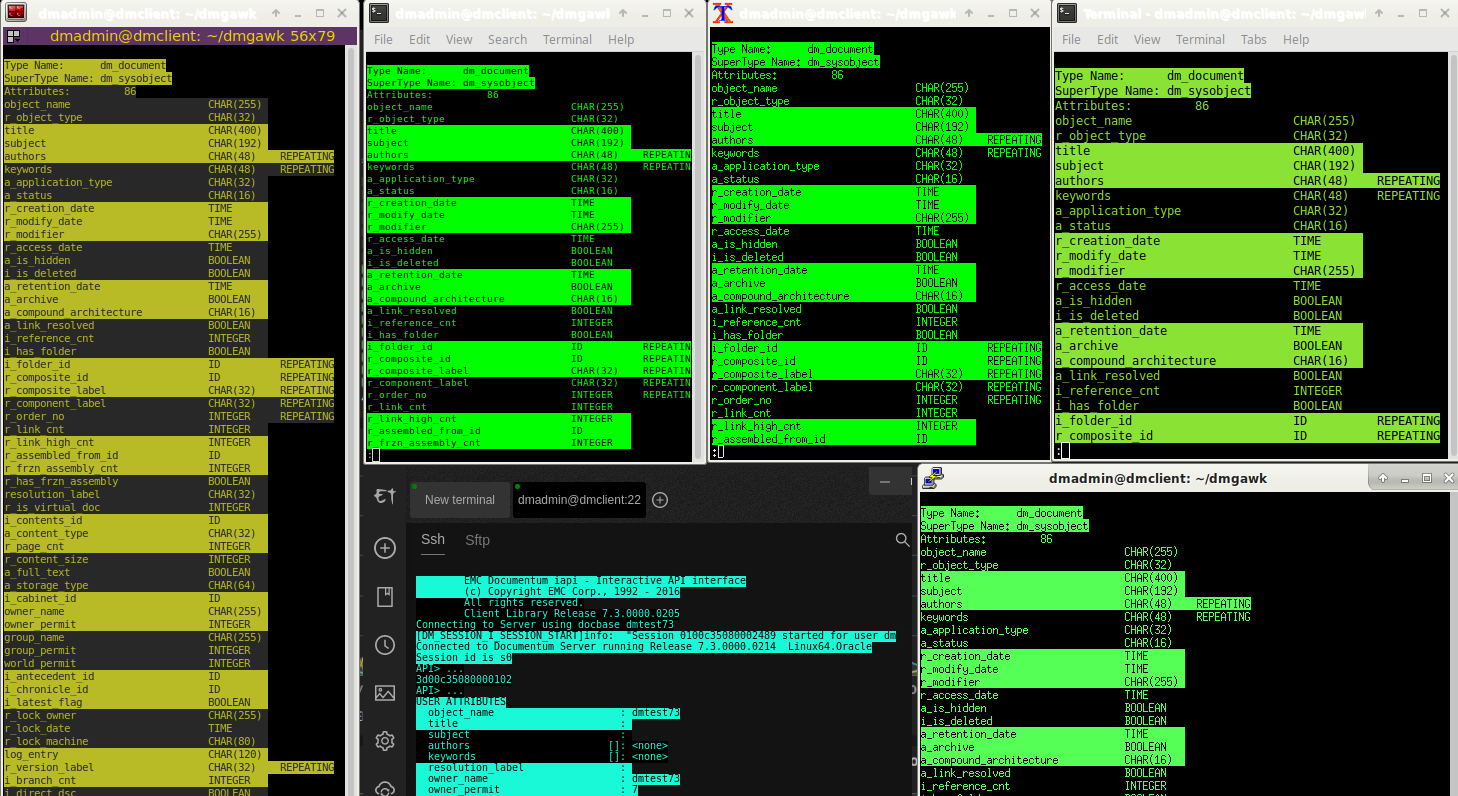
From left to right and top to bottom, we have terminator, Gnome terminal, xterm, xfce4-terminal, Elect-term, and putty for linux. Although Elect-term is based on xterm, its default color definition is totally inaccurate; for its defense, each pre-defined color slot is customizable through a RGB triplet. As Gnome terminal emulates xterm, no wonder they look identically good. Putty does a good job too while xfce4-terminal is not on the par but not bad either. Terminator is weak at coloring but its strength is elsewhere.
Executing external programs
idql/iapi don’t allow shelling out an external program, e.g. through the usual syntax !command, and neither do rlwrap nor readline. Actually, the bang (!) command should be a functionality of readline since it is the layer that processes user input. Unfortunately, there is no such command so no key binding is possible. Even rlwrap does not do that, although it implements the bindable rlwrap-call-editor command, an extension to readline. While it is possible to add this functionality to readline (it is open source after all), however, there are 2 the simple work-arounds.
The first one is using bash’s job control facilities and suspending the current program via ctrl-z, invoking whatever program is needed and, once completed, resuming the suspended program via bash’s fg, e.g.:
rlwrap --filter=pipeto --ansi-colour-aware --prompt-colour=GREEN --multi-line='__' idql dmtest72 -Udmadmin -Pdmadmin
1> 2> select * from dm_document
go
| gawk '{gsub(/([0-9a-f]{16})/, "[\033[1m\033[31m&\033[0m]", $0); print}' | less -#10 -R -S
1> 2>
3>
[1]+ Stopped rlwrap --filter=pipeto --ansi-colour-aware --prompt-colour=GREEN --multi-line='__' idql dmtest72 -Udmadmin -Pdmadmin
dmadmin@dmclient:~/dmgawk$ which iapi
/home/dmadmin/documentum/product/7.3/bin/iapi
dmadmin@dmclient:~/dmgawk$ fg
rlwrap --filter=pipeto --ansi-colour-aware --prompt-colour=GREEN --multi-line='__' idql dmtest72 -Udmadmin -Pdmadmin
3>
Ctrl-z was typed on line 8, an external command was called on line 10, and fg on line 12 resumed the execution inside rlwrap. A general, easy-to-apply work-around.
The second one is using the rlwrap’s pipeto filter to filter an empty idql command, as illustrated:
1> |pwd /home/dmadmin/dmgawk 2> |ls -l total 281992 .. drwxrwxr-x 3 dmadmin dmadmin 4096 Aug 28 12:51 com -rw-rw-r-- 1 dmadmin dmadmin 6203 Sep 5 11:43 compact_or_truncate_wwa.awk -rw-rw-r-- 1 dmadmin dmadmin 1530 Sep 2 18:35 compact_wwa.awk -rw-rw-r-- 1 dmadmin dmadmin 1001 Sep 1 19:12 file.txt ... -rw-rw-r-- 1 dmadmin dmadmin 1718 Sep 6 14:08 idql-completions.txt ... -rw-rw-r-- 1 dmadmin dmadmin 95 Aug 30 23:21 script.dql -rw-r--r-- 1 dmadmin dmadmin 279629824 Sep 1 2018 stress-test.db ... 3> |ls -l /tmp total 836 ... -rw-rw-r-- 1 dmadmin dmadmin 0 Sep 6 16:34 filterlog.19983 -rw-rw-r-- 1 dmadmin dmadmin 0 Sep 1 20:38 filterlog.29142 -rw-rw-r-- 1 dmadmin dmadmin 0 Sep 2 12:58 filterlog.8411 -rw-rw-r-- 1 dmadmin dmadmin 0 Sep 2 14:52 filterlog.9748 ... drwxrwxr-x 9 dmadmin dmadmin 4096 Sep 1 21:04 rlwrap-master -rw-rw-r-- 1 dmadmin dmadmin 195952 Sep 1 21:00 rlwrap-master.zip -rw------- 1 dmadmin dmadmin 0 Sep 1 21:13 rlwrap_idql_RbgjpO -rw------- 1 dmadmin dmadmin 0 Sep 1 21:14 rlwrap_idql_tDeKta ...
Any command typed after the pipe symbol | will be passed to the shell and its output will be printed on the screen. The command must be an executable; this rules out shell aliases or functions. Thankfully, for complex, frequently used bash commands, the simple_macro filter can be used to define macros for them, e.g.
-- macro-ize a complex command that, for all the files in the current directory, outputs its file name and type; in addition, it prints the first 2 lines only if the file is a text file;
$ft((|file * | gawk '{print; if (match($0, /^([^:]+): +(.+text)/, f) ) {system("head -2 \"" f[1] "\""); printf "\n"}}'))
...
-- call it;
$ft
com: directory
compact_or_truncate_wwa.awk: awk or perl script, ASCII text
# Usage:
# gawk [-v maxw=nn] [-v optimal_breadths=n1,n2,...] [-v truncate=0|1] [-v ellipsis=...] [-v wrap=1|0] -f compact_wwa.awk file
compact_wwa.awk: awk or perl script, ASCII text
# Usage:
# gawk -v maxw=nn -f compact_wwa.awk file
file.txt: ASCII text
total 278708
...
idql-completions.txt: ASCII text
r_object_id
object_name
script.dql: ASCII text
--hist
--?
stress-test.db: SQLite 3.x database
Another recurrent issue with the current idql and iapi tools is that they are specialized, the former to process DQL statement and the latter api statements. So, when you are in idql and want to quickly dump an object, you need to launch an iapi somewhere. Now, this can be done inside either one of the tools, i.e.:
$ rlwrap --no-warnings --filter='pipeline simple_macro:pipeto' --ansi-colour-aware --prompt-colour=RED --multi-line='__' idql dmtest72 -Udmadmin -Pdmadmin ... EMC Documentum idql - Interactive document query interface ... Connecting to Server using docbase dmtest72 ... Connected to Documentum Server running Release 7.2.0000.0155 Linux64.Oracle 1> |echo "dump,c,0b00c398800001c5" | iapi dmtest72 -Udmadmin -Pdmadmin ... EMC Documentum iapi - Interactive API interface ... Connecting to Server using docbase dmtest72 ... Connected to Documentum Server running Release 7.2.0000.0155 Linux64.Oracle Session id is s0 API> ... USER ATTRIBUTES object_name : Templates title : subject : authors []: keywords []: resolution_label : ...
Maybe it is worth defining a macro for this:
-- define $iapi to launch iapi: $iapi((iapi dmtest72 -Udmadmin -Pdmadmin)) ... -- invoke it: |echo "dump,c,0b00c398800001c5" | $iapi
Clearly, the pipeto filter is an unmissable option when using rlwrap; and so is simple_macro.
Name completion
Name completion can be quite useful for the lazy typists out there, or for any too long or hard-to-remember words such as doctypes, attributes, clauses or statements. For such cases, a completion file can be created containing a list of DQL frequently used statements, API verbs, idql and iapi commands, and doctypes. E.g.
r_object_id object_name count go quit select where from enable return_top ... alter change create delete drop execute grant insert register revoke unregister update dm_acs_config dm_activity dm_aggr_domain dm_app_ref dm_application dm_atmos_store dm_attachments_folder dm_audittrail_acl dm_audittrail_group dm_blobstore dm_bocs_config dm_builtin_expr dm_business_pro dm_ca_store dm_cabinet dm_cache_config dm_category dm_category_assign dm_category_class dm_ci_config dm_client_registration dm_client_rights dm_component dm_cond_expr dm_cond_id_expr dm_cont_transfer_config dm_cryptographic_key dm_decision dm_distributedstore dm_dms_config dm_docbase_config dm_docset dm_docset_run dm_document dm_folder dm_user ...
The default completion file for the rlwrapped program, e.g. ~/idql_completions here, can also be used directly and won’t need to be specified. Several completion files can be used at once and combined during the search for a match.
Next, rlwrap is launched with the -f or ––file argument to read the completion file and use it when the <tab> key is pressed:
$ rlwrap -f idql-completions.txt --filter=pipeto --ansi-colour-aware --prompt-colour=RED --multi-line='__' idql dmtest72 -Udmadmin -Pdmadmin
...
Connecting to Server using docbase dmtest72
...
Connected to Documentum Server running Release 7.2.0000.0155 Linux64.Oracle
1> select count(*) from dm_d
dm_decision dm_distributedstore dm_dms_config dm_docbase_config dm_docset dm_docset_run dm_document
1> select count(*) from dm_doc
dm_docbase_config dm_docset dm_docset_run dm_document
1> select count(*) from dm_document
2> g
go grant
2> go
count(*)
----------------------
860
(1 row affected)
The <tab> key was entered on lines 6, 8 and 11 and on the respective following line, rlwrap’s completion listed the possible candidates to choose from.
The syntax:
-f|--file completion_file { -f|--file completion_file}
allows each rlwrapped program to have its own specialized completion file and also to benefit from some common one(s).
Completion can work around macro’s execute-on-definition issue with the “quit” command. Just type q followed by <tab> and, if no ambiguity is present in the completion file, it will be directly resolved to “quit”; even faster than recalling the command from the history.
Note that with the pipeto filter, a completion file can also be used to quickly lookup words:
|less idql-completions.txt r_object_id object_name count go quit select ...
But the same effect can be reached by just typing <tab> on an empty line:
1> Display all 121 possibilities? (y or n) * dm_builtin_expr dm_dms_config dm_ftindex_agent_config dm_migrate_rule dm_sync_list_relation dm_xml_zone abort dm_business_pro dm_docbase_config dm_ftquery_subscription dm_mount_point dm_sysprocess_config drop ...
Wrapping up
As demonstrated throughout this 2-part article, rlwrap really shines. The idea of wrapping an external executable and forwarding it the input from the readline() function of the eponymous library is simply brilliant.
Now, even closed, commercial software that stayed away from it because of the restrictive GNU licensing can benefit from readline without violating its license. Thanks to rlwrap, without much effort and almost no coding at all, we could cover all the shortcomings listed in the beginning of this article and enhance idql/iapi so that they have finally reached a level of usability that we’ve been longing for so many years.
Notwithstanding the numerous enhancements that rlwrap brings to idql/iapi, there is still room for improvement but in order to reach the next step a complete rewrite of those tools is required. It will be the subject of an article to come soon, watch this space.
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ATR_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/MOP_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/GME_web-min-scaled.jpg)