A few weeks ago, I faced an issue at a customer where xPlore PrimaryDsearch would stop responding to curl/wget/browser requests from time to time. The impacted environments were containers (pods) hosted on Kubernetes. At this customer, we were in progress of migrating their standalone xPlore installations (also on pods) to Multi-Node, meaning that before, there was only 1 pod containing a PrimaryDsearch+IndexAgent and after, there is a pod containing a PrimaryDsearch, another one with an IndexAgent and then several other pods with CPS Only instances.
All these pods have liveness checks (readiness too but it’s irrelevant here) that basically perform a small wget to make sure the installed component(s) in the pod is(are) responding in a timely manner. A few working days after the end of the xPlore migration to the Multi-Node installation (well after the migration of the 1st Federation, there are 2 Federations for HA and to avoid downtime during such activities), some of the pods containing a PrimaryDsearch would suddenly restart a few times a day, while some others wouldn’t restart at all. After some quick checks, it was the liveness that was failing, meaning that three consecutive checks (executed every 10s) were timing out.
This same liveness check is in place since years and xPlore would always respond in around 20-30ms, so this issue happening only on some of the Productive environments (2 out 10) was a little strange. To confirm this behavior, I executed the same wget command from the liveness check (with a slightly higher timeout of 30s instead of 3s) and recorded the execution time taken to be able to process/analyze all the data after a restart of the pod:
[xplore@ds1-0 ~]$ ## Before issue
[xplore@ds1-0 ~]$ ## Triggering loop to monitor the response time of xPlore Dsearch UI
[xplore@ds1-0 ~]$ echo; while true; do
time timeout 30s wget -q --spider --no-check-certificate --no-proxy https://localhost:9302/dsearch
date
echo
sleep 10
done > /data/mop_`hostname -s`.log 2>&1
command terminated with exit code 137
[morgan@k8s_m1 ~]$
####
####
[xplore@ds1-0 ~]$ ## After issue
[xplore@ds1-0 ~]$ ## Analysis of the execution time
[xplore@ds1-0 ~]$ echo; \
echo " -- Nb wget with response < 1s: $(grep 'real.*0m0' /data/mop_`hostname -s`.log | wc -l)"; echo; \
echo " -- Nb wget with response > 1s: $(grep 'real.*0m[1-9]' /data/mop_`hostname -s`.log | wc -l)"; \
awk '/^real/ {a=$0; getline; getline; getline; print $0 " -- " a;}' /data/mop_`hostname -s`.log | grep "real.*0m[1-9]"; echo
-- Nb wget with response < 1s: 2309
-- Nb wget with response > 1s: 27
Fri Nov 11 08:32:09 UTC 2022 -- real 0m3.468s
Fri Nov 11 09:06:47 UTC 2022 -- real 0m2.986s
Fri Nov 11 09:07:20 UTC 2022 -- real 0m22.783s
Fri Nov 11 09:07:32 UTC 2022 -- real 0m2.606s
Fri Nov 11 09:07:51 UTC 2022 -- real 0m8.395s
Fri Nov 11 09:18:16 UTC 2022 -- real 0m18.204s
Fri Nov 11 09:25:21 UTC 2022 -- real 0m1.387s
Fri Nov 11 09:31:04 UTC 2022 -- real 0m9.129s
Fri Nov 11 10:41:48 UTC 2022 -- real 0m9.055s
Fri Nov 11 10:43:38 UTC 2022 -- real 0m8.167s
Fri Nov 11 10:54:31 UTC 2022 -- real 0m4.019s
Fri Nov 11 11:03:27 UTC 2022 -- real 0m1.082s
Fri Nov 11 11:04:40 UTC 2022 -- real 0m1.334s
Fri Nov 11 11:05:53 UTC 2022 -- real 0m1.095s
Fri Nov 11 11:06:05 UTC 2022 -- real 0m2.755s
Fri Nov 11 13:20:03 UTC 2022 -- real 0m1.916s
Fri Nov 11 14:14:54 UTC 2022 -- real 0m21.306s
Fri Nov 11 14:15:05 UTC 2022 -- real 0m1.506s
Fri Nov 11 14:15:46 UTC 2022 -- real 0m30.003s
Fri Nov 11 14:16:26 UTC 2022 -- real 0m30.007s
Fri Nov 11 14:16:56 UTC 2022 -- real 0m20.026s
Fri Nov 11 14:17:36 UTC 2022 -- real 0m30.003s
Fri Nov 11 14:18:16 UTC 2022 -- real 0m30.003s
Fri Nov 11 14:18:56 UTC 2022 -- real 0m30.002s
Fri Nov 11 14:19:36 UTC 2022 -- real 0m30.002s
Fri Nov 11 14:20:16 UTC 2022 -- real 0m30.002s
Fri Nov 11 14:20:56 UTC 2022 -- real 0m30.002s
[xplore@ds1-0 data]$
As you can see above, the small monitoring command was running for around 6.5h (~2350 checks, every 10s) and 98.8% of the checks were properly replying in under 1s (the expected response time being ~0.030s), but during that time, there was still some checks that were significantly slower. However, the pod didn’t restart because there weren’t 3 consecutive liveness checks in failure. It’s only starting at 14:15 UTC that the response time was consistently at 30s (timeout), meaning that xPlore wasn’t responding at all.
At the same time, I was thinking at what exactly the reason for xPlore to stop responding could be and the first thing that came to my mind was that WildFly could be running out of threads. Therefore, it wouldn’t reply because all the threads would be used by ongoing activities (indexing & searches). To validate this assumption, I launched another small command that would retrieve the Java PID and then perform a thread dump every 30s, so that I could correlate the thread dumps with the xPlore response time and hopefully find what is happening:
[xplore@ds1-0 ~]$ ## Before issue
[xplore@ds1-0 ~]$ ## Triggering loop to monitor the threads
[xplore@ds1-0 ~]$ echo; while true; do
d=$(date "+%Y-%m-%d_%H-%M-%S")
dh=${d::13}
mkdir -p /data/threads_${dh}
jcmd $(pgrep -f "java.*DctmServer_PrimaryDsearch") Thread.print > /data/threads_${dh}/${d}.log 2>&1
sleep 30
done
command terminated with exit code 137
[morgan@k8s_m1 ~]$
As shown previously, the issue started around 14:15 UTC. Therefore, I defined 2 periods across 8 threads each (~3.5min), to analyze the thread dumps before (14:10:42 to 14:14:14) and while the issue appeared (14:14:14 to 14:17:46), respectively. Using the online tool FastThread (please see below the reports generated by fastthread.io), to do the analysis of thread dumps, it’s clear that the issue is present because of the “default task” threads. While there are 16 of them (it’s really not a lot), most of these were “WAITING” under normal behavior and when xPlore wasn’t responding, all these were “TIMED_WAITING“:

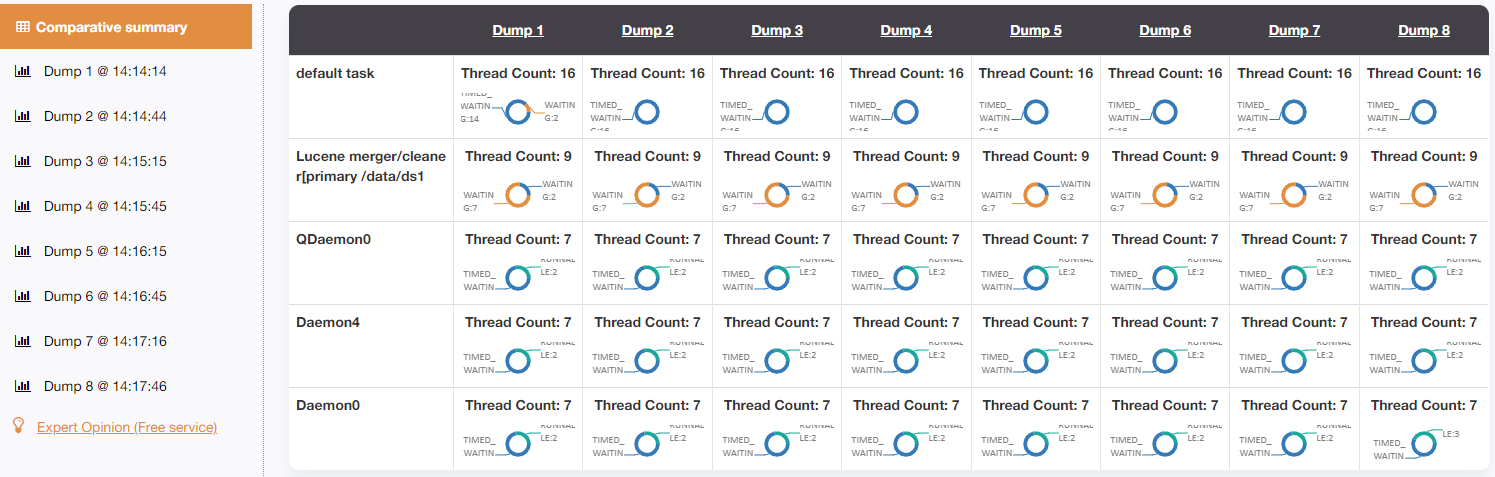
When looking at the thread dump in details, it was clear that:
- “WAITING” status is when the thread isn’t doing anything, because the stack is very short (~10 lines), and it’s generic
- “TIMED_WAITING” status is when the thread is doing something, because the stack is longer (~40/50 lines), and it usually contains things like “at c.e.d.c.f.i.c.h.impl.SearchQueryHandler.executeAction(SearchQueryHandler.java:21)” or “at c.e.d.c.f.i.c.i.ESSIndexServer.waitForUpdates(ESSIndexServer.java:456)”
The thread dumps confirmed the assumption that xPlore PrimaryDsearch isn’t responding simply because it is running out of available threads to process the request. Going deeper in that direction, the number of worker threads that WildFly uses is defined using the “task-max-threads” parameter of the worker inside the “standalone.xml” file. OpenText do not set any value for that parameter since the definition is simply: ‘<worker name=”default”/>‘. Therefore, based on the documentation (it’s for version 19 but you get the idea)), if nothing is specified, WildFly will use a default of “cpuCount*16“.
The Kubernetes Node on which this pod was running was a VM with 1 physical CPU (1 socket) and 16 vCPU. Before the migration to Multi-Node, the xPlore containers had a limit set to 6 CPUs but for the migration, the limit wasn’t set, to allow xPlore to use whatever is available during the full reindex. If the documentation of WildFly is correct, from my point of view, it means that there should be 16*16=256 worker threads, since it would, I assume, take the number of CPUs available at the VM/OS. But it was stuck at 16 in our case and that didn’t make too much sense to me.
Initially, I thought that WildFly was using the “1 socket” to define the amount of worker threads, but after a test on DEV on a Node having 2 sockets and 32 vCPU, it was still using only 16 worker threads in the same conditions. Even though the xPlore container itself had no request/limit, but the pod had 3 containers (1 for xPlore and 2 sidecar containers for monitoring) and the 2 sidecars did, still, have their limits in place (0.1 CPU), since we only wanted to allow the main xPlore container to run wild. I thought that maybe the sidecar containers would be the reason why it is assuming that there is only 1 CPU (and hence uses 16 worker threads). Maybe it would sum-up all the limits and then use this value or divide it by the number of containers or maybe it would take the max limit of the pod (from any containers). So, I did a lot of tests to check what was true and what was really happening. In summary, it doesn’t seem to be any of the above. Whatever is happening on the sidecar or on the K8s Node has no relation to the number of WildFly worker threads, only the container’s requests/limits matters (as it should):
| Requests / Limits | WildFly worker threads |
| No request/limit set on any containers | 16 |
| Request/limit set on sidecar (any value) No request/limit set on WildFly container | 16 |
| Request/limit set on sidecar (any value) Request set to 1.5 CPU on WildFly container | 32 (2*16) |
| Request/limit set on sidecar (any value) Request set to 2 CPU and limit set to 4.1 CPU on WildFly container | 80 (5*1.6) |
Therefore, it looks like the number of WildFly worker threads, if there is no “task-max-threads” parameter defined, will be: MAX(1, ROUNDUP(Request_CPU,0), ROUNDUP(Limit_CPU,0)) * 16. If you aren’t familiar with excel formulas or if you simply don’t understand what I meant by that, it does the following: it will round up (always up, never down) the Request and Limit CPU value to the integer (e.g.: 2 remains 2 but 2.1 becomes 3) and then it will multiply 16 by the maximum value between 1, the rounded value for the request and the rounded value for the limit.
To be able to retrieve these details, I simply updated the limits, waited for the pod to be re-created and once xPlore was running again, I launched a bunch of HTTP requests (wget or browser for example) until the value reached its maximum:
[morgan@k8s_m1 ~]$ ## xPlore container with 2 CPU (limit)
[morgan@k8s_m1 ~]$ kubectl describe pod ds1-0 | grep -A1 -B10 "Limits:" | grep -E "^ [a-z]|cpu:"
ds:
cpu: 2
grok:
cpu: 100m
procexp:
cpu: 100m
[morgan@k8s_m1 ~]$ kubectl exec -it ds1-0 -c ds -- bash -l -c 'echo; PID=$(pgrep -o -f "java.*DctmServer_PrimaryDsearch"); jcmd ${PID} Thread.print > /tmp/mop.txt; echo "Nb worker threads: `grep "default task" /tmp/mop.txt | wc -l`"; rm /tmp/mop.txt; echo;'
Nb worker threads: 7
[morgan@k8s_m1 ~]$
[morgan@k8s_m1 ~]$ kubectl exec -it ds1-0 -c ds -- bash -l -c 'for i in $(seq 1 50); do timeout 1s wget -q --spider --no-check-certificate --no-proxy https://localhost:9302/dsearch; done'
[morgan@k8s_m1 ~]$
[morgan@k8s_m1 ~]$ kubectl exec -it ds1-0 -c ds -- bash -l -c 'echo; PID=$(pgrep -o -f "java.*DctmServer_PrimaryDsearch"); jcmd ${PID} Thread.print > /tmp/mop.txt; echo "Nb worker threads: `grep "default task" /tmp/mop.txt | wc -l`"; rm /tmp/mop.txt; echo;'
Nb worker threads: 32
[morgan@k8s_m1 ~]$
[morgan@k8s_m1 ~]$
[morgan@k8s_m1 ~]$ ## xPlore container with 3.1 CPU (limit)
[morgan@k8s_m1 ~]$ kubectl describe pod ds1-0 | grep -A1 -B10 "Limits:" | grep -E "^ [a-z]|cpu:"
ds:
cpu: 3100m
grok:
cpu: 1100m
procexp:
cpu: 2100m
[morgan@k8s_m1 ~]$ kubectl exec -it ds1-0 -c ds -- bash -l -c 'echo; PID=$(pgrep -o -f "java.*DctmServer_PrimaryDsearch"); jcmd ${PID} Thread.print > /tmp/mop.txt; echo "Nb worker threads: `grep "default task" /tmp/mop.txt | wc -l`"; rm /tmp/mop.txt; echo;'
Nb worker threads: 9
[morgan@k8s_m1 ~]$
[morgan@k8s_m1 ~]$ kubectl exec -it ds1-0 -c ds -- bash -l -c 'for i in $(seq 1 75); do timeout 1s wget -q --spider --no-check-certificate --no-proxy https://localhost:9302/dsearch; done'
[morgan@k8s_m1 ~]$
[morgan@k8s_m1 ~]$ kubectl exec -it ds1-0 -c ds -- bash -l -c 'echo; PID=$(pgrep -o -f "java.*DctmServer_PrimaryDsearch"); jcmd ${PID} Thread.print > /tmp/mop.txt; echo "Nb worker threads: `grep "default task" /tmp/mop.txt | wc -l`"; rm /tmp/mop.txt; echo;'
Nb worker threads: 64
[morgan@k8s_m1 ~]$
As a conclusion, it is very important to have at least a request or a limit set for Documentum containers using WildFly (JMS before Dctm 21.x and xPlore). If you do not want to set either of these, you will most probably need to manually define the “task-max-threads” parameter, so that WildFly starts with enough worker threads. Having 16 worker threads might be enough for some use-cases but it’s going to be filled quite easily if there are a lot of searches being done in parallel.
Note: on WildFly9 (Documentum 16.4 defaults to wildfly9.0.1), the number of “default task” present in the thread dump will only increase, up to the maximum value defined (or the default value). On WildFly17 (Documentum 20.2 defaults to wildfly17.0.1), it behaves differently, the value of “default task” will have a minimum of 2 it seems, and it will increase when needed but then decrease again. Therefore, on WildFly9, you can easily find the max value used by simply launching dozens of HTTP requests. When xPlore 16.4 starts for example, it should have around 7/8 “default task” and then triggering 50 HTTP requests will lead to a value of 16 or 32 or 48 or whatever, depending on the number of CPUs that are configured. On WildFly17, it will stay at 2. You might see it increase temporarily to 3 or 4 if you are launching a lot of such requests in parallel but it won’t continue to increase, it will go back to 2 afterwards.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/MOP_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/GME_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ATR_web-min-scaled.jpg)