Elasticsearch is a very versatile platform that supports a variety of use cases and provides great flexibility around data organization. After a global overview on Elastic Stack, understanding Elasticsearch terminologies, and setup Elasticsearch. Today, we will go more in deep with data management inside Elasticsearch.
Data categories
The data you store in Elasticsearch generally falls into one of two categories:
- Content: a collection of items you want to search, such as a catalog of products. Content might be frequently updated, but the value of the content remains relatively constant over time. You want to be able to retrieve items quickly regardless of how old they are!
- Time series data: a stream of continuously-generated timestamped data, such as log entries. Time series data keeps accumulating over time, so you need strategies for balancing the value of the data against the cost of storing it. As it ages, it tends to become less important and less-frequently accessed, so you can move it to less expensive, less performant hardware. For your oldest data, what matters is that you have access to the data. It’s ok if queries take longer to complete.
Depending on your data category and the business need you can define your architecture and configure the data tiers.
Data tiers
A data tier is a collection of nodes with the same data role that typically share the same hardware profile:
- Content tier nodes handle the indexing and query load for content such as a product catalog. As said before, unlike time series data, the value of the content remains relatively constant over time, so it doesn’t make sense to move it to a tier with different performance characteristics as it ages. Content data typically has long data retention requirements, and you want to be able to retrieve items quickly regardless of how old they are.
- Hot tier nodes handle the indexing load for time series data such as logs or metrics and hold your most recent, most-frequently-accessed data. In fact, the hot tier is the entry point for time series data and holds your most-recent, most-frequently-searched time series data. Nodes in the hot tier need to be fast for both reads and writes, which requires more hardware resources and faster storage (SSDs).
- Warm tier nodes hold time series data that is accessed less-frequently and rarely needs to be updated. Time series data can move to the warm tier once it is being queried less frequently than the recently-indexed data in the hot tier. Nodes in the warm tier generally don’t need to be as fast as those in the hot tier.
- Cold tier nodes hold time series data that is accessed infrequently and not updated normally. To save space, you can keep fully mounted indices of searchable snapshots on the cold tier. These fully mounted indices eliminate the need for replicas, reducing required disk space by approximately 50% compared to the regular indices.
- Frozen tier nodes hold time series data that is accessed rarely and never updated. The frozen tier stores partially mounted indices of searchable snapshots exclusively. This extends the storage capacity even further.
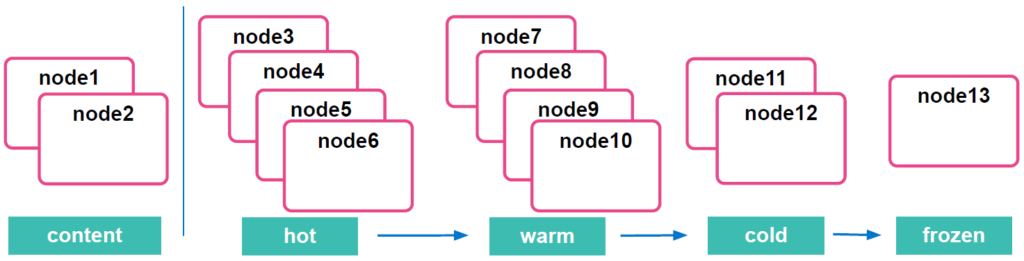
To recapitulate, when you index documents directly to a specific index, they remain on content tier nodes indefinitely. On the other hand, when you index documents to a data stream, they initially reside on hot tier nodes. You can configure Index Lifecycle Management (ILM) policies to automatically transition your time series data through the hot, warm, and cold tiers according to your performance, resiliency and data retention requirements.
Index Lifecycle Management
You can create and apply Index lifecycle management (ILM) policies to automatically manage your indices according to your performance, resiliency, and retention requirements.
Index lifecycle policies can trigger actions such as:
- Rollover: Creates a new write index when the current one reaches a certain size, number of docs, or age.
- Shrink: Reduces the number of primary shards in an index.
- Force merge: Triggers a force merge to reduce the number of segments in an index’s shards.
- Delete: Permanently remove an index, including all of its data and metadata.
ILM makes it easier to manage indices in hot-warm-cold architectures, which are common when you’re working with time series data such as logs and metrics.
You can specify:
- The maximum shard size, number of documents, or age at which you want to roll over to a new index.
- The point at which the index is no longer being updated and the number of primary shards can be reduced.
- When to force a merge to permanently remove documents marked for deletion.
- The point at which the index can be moved to less performant hardware.
- The point at which the availability is not as critical and the number of replicas can be reduced.
- When the index can be safely deleted.
An Index Lifecycle Management could be configured like the following:
PUT _ilm/policy/filebeat
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_size": "50gb",
"max_age": "5d"
}
}
},
"warm": {
"min_age": "10d",
"actions": {
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "20d",
"actions": {
"set_priority": {
"priority": 0
}
}
},
"delete": {
"min_age": "60d",
"actions": {
"delete": {
"delete_searchable_snapshot": true
}
}
}
}
}
}
Don’t worry, there is a way to configure ILM via Kibana, you don’t have to write the above from scratch 😉
In a next blog, we will explore different ways to configure ILM with some use cases, in the meantime please don’t hesitate to ask questions or share your feedback.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/09/DDI_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/05/martin_bracher_2048x1536.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/03/AHI_web.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/HER_web-min-scaled.jpg)
KeithLim
30.05.2023I've created the ILM, but somehow it is not moving any data. I suspect I need to setup Linked Index Template, but the information is not available. Can you give a guide?
David Diab
01.06.2023Hi KeithLim,
How you proceed to create the ILM, could you please share more information?
How you checked if your data are moving or not?
No Index Template is needed for ILM to work.