By Franck Pachot
.
This follows my previous post https://www.dbi-services.com/blog/aurora-serverless-v2-ram/ which you should read before this one. I was looking at the auto-scaling of RAM and it is now time to look at the CPU Utilization.
I have created an Aurora Serverless v2 database (please don’t forget it is the beta preview) with auto-scaling from 4 ACU to 32 ACU. I was looking at a table scan to show how the buffer pool is dynamically resized with auto-scaling. Here I’ll start to run this same cpu() procedure in one, then two, then tree… concurrent sessions to show auto-scaling and related metrics.
Here is the global workload in number of queries per second (I have installed PMM on AWS in a previous post so let’s use it):
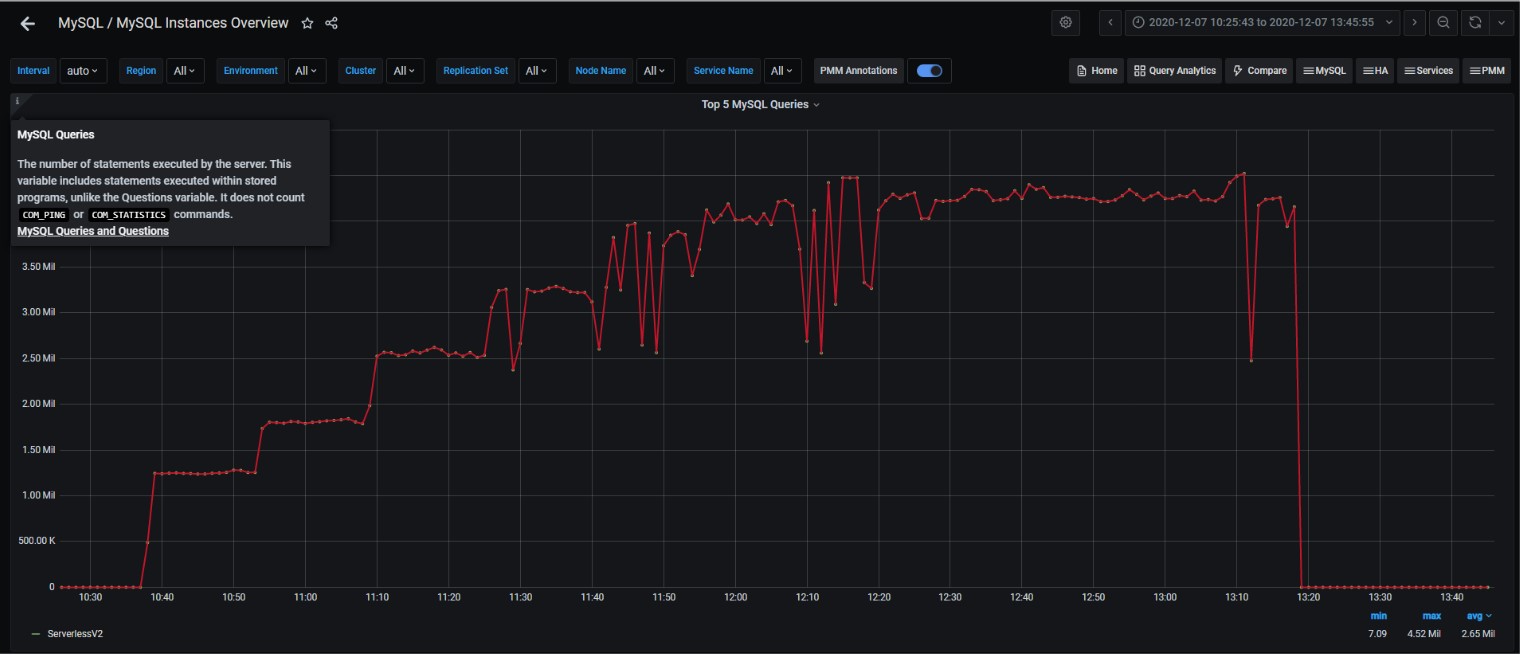
And the summary of what I’ve run, with the auto-scaled capacity and the CPU utilization measured:
10:38 1 session running, 6 ACU , 14% CPU usage
10:54 2 sessions running, 11 ACUs, 26% CPU usage
11:09 3 sessions running, 16 ACUs, 39% CPU usage
11:25 4 sessions running, 21 ACUs, 50% CPU usage
11:40 5 sessions running, 26 ACUs, 63% CPU usage
11:56 6 sessions running, 31 ACUs, 75% CPU usage
12:12 7 sessions running, 32 ACUs, 89% CPU usage
12:27 8 sessions running, 32 ACUs, 97% CPU usage
The timestamp shows when I started to add one more session running in CPU, so that we can match with the metrics from CloudWatch. From there, it looks like the Aurora database engine is running on an 8 vCPU machine and the increase of ACU did not change dynamically the OS threads the “CPU Utilization” metric is based on.
Here are the details from CloudWatch:
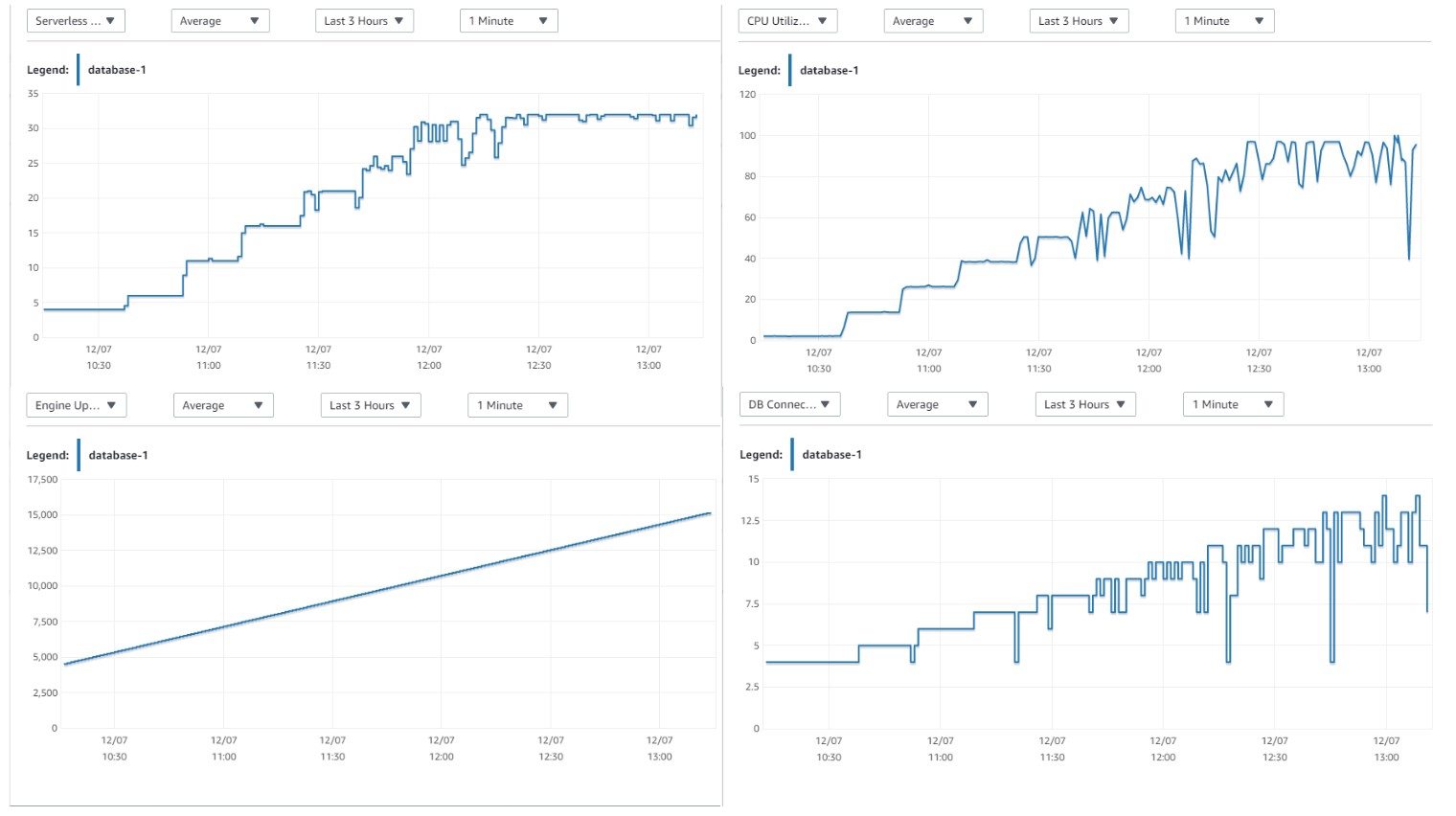
The metrics are:
- Serverless Capacity Units on top-left: the auto-scaled ACU from 4 to 32 (in the preview), with a granularity of 0.5
- CPU Utilization on top-right: the sessions running in CPU as a pourcentage of available threads
- Engine Uptime on bottom-left: there were no restart during those runs
- DB connections on botton right: I had 4 idle sessions before starting, then substract 4 and you have the sessions running
With 8 sessions in CPU, I’ve saturated the CPU and, as we reached 100%, my guess is that those are 8 cores, not hyperthreaded. As this is 32 ACUs, this would mean that an ACU is 1/4th of a core, but…
Here is the same metric I displayed from PMM, but here from CloudWatch, to look again how the workload scales:
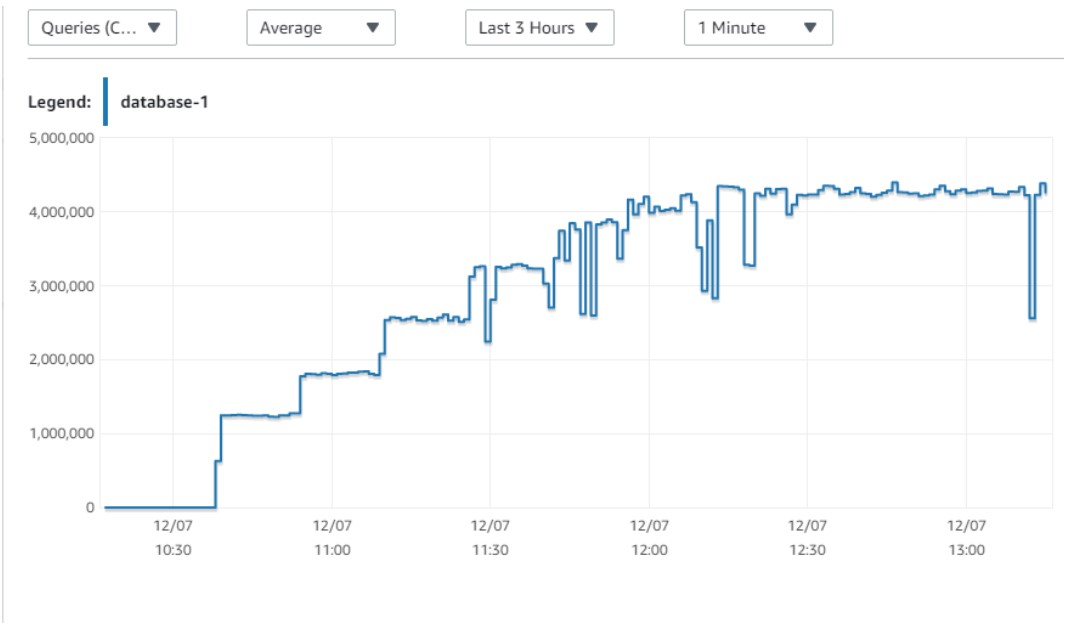
If ACUs were proportional to the OS cores, I would expect linear performance, which is not the case. One session runs at 1.25M queries per second on 6 ACUs. Two sessions are at 1.8M queries per second on 11 ACUs. Tree sessions at 2.5M queries/s on 16 ACU. So the math is not so simple. Does this mean that 16 ACU does not offer the same throughput as two times 8 ACU? Are we on burstable instances for small ACU? And, 8 vCPU with 64 GB, does that mean that when I start a serverless database with a 32 ACU maximum it runs on a db.r5.2xlarge, whatever the actual ACU it scales to? Is the VM simply provisioned on the maximum ACU and CPU limited by cgroup or similar?
I’ve done another test, this time fixing the min and max ACU to 16. So, maybe, this is similar to provisioning a db.r5.xlarge.
And I modified my cpu() procedure to stop after 10 million loops:
delimiter $
drop procedure if exists cpu;
create procedure cpu()
begin
declare i int default 0;
while i < 1e7 do
set i = i + 1;
end while;
end$
delimiter ;
1 million loops, this takes 50 seconds on dbfiddle, and you can test it on other platforms where you have an idea of the CPU speed.
I’ve run a loop that connects, run this function and displays the time and loop again:
Dec 07 18:41:45 real 0m24.271s
Dec 07 18:42:10 real 0m25.031s
Dec 07 18:42:35 real 0m25.146s
Dec 07 18:43:00 real 0m24.817s
Dec 07 18:43:24 real 0m23.868s
Dec 07 18:43:48 real 0m24.180s
Dec 07 18:44:12 real 0m23.758s
Dec 07 18:44:36 real 0m24.532s
Dec 07 18:45:00 real 0m23.651s
Dec 07 18:45:23 real 0m23.540s
Dec 07 18:45:47 real 0m23.813s
Dec 07 18:46:11 real 0m24.295s
Dec 07 18:46:35 real 0m23.525s
This is one session and CPU usage is 26% here (this is why I think that my 16 ACU serverless database runs on a 4 vCPU server)
Dec 07 18:46:59 real 0m24.013s
Dec 07 18:47:23 real 0m24.318s
Dec 07 18:47:47 real 0m23.845s
Dec 07 18:48:11 real 0m24.066s
Dec 07 18:48:35 real 0m23.903s
Dec 07 18:49:00 real 0m24.842s
Dec 07 18:49:24 real 0m24.173s
Dec 07 18:49:49 real 0m24.557s
Dec 07 18:50:13 real 0m24.684s
Dec 07 18:50:38 real 0m24.860s
Dec 07 18:51:03 real 0m24.988s
This is two sessions (I’m displaying the time for one only) and CPU usage is 50% which confirms my guess: I’m using half of the CPU resources. And the response time per session is till the same as when one session only was running.
Dec 07 18:51:28 real 0m24.714s
Dec 07 18:51:53 real 0m24.802s
Dec 07 18:52:18 real 0m24.936s
Dec 07 18:52:42 real 0m24.371s
Dec 07 18:53:06 real 0m24.161s
Dec 07 18:53:31 real 0m24.543s
Dec 07 18:53:55 real 0m24.316s
Dec 07 18:54:20 real 0m25.183s
I am now running 3 sessions there and the response time is still similar (I am at 75% CPU usage so obviously I have more than 2 cores here – no hyperthreading – or I should have seen some performance penalty when running more threads than cores)
Dec 07 18:54:46 real 0m25.937s
Dec 07 18:55:11 real 0m25.063s
Dec 07 18:55:36 real 0m24.400s
Dec 07 18:56:01 real 0m25.223s
Dec 07 18:56:27 real 0m25.791s
Dec 07 18:57:17 real 0m24.798s
Dec 07 18:57:42 real 0m25.385s
Dec 07 18:58:07 real 0m24.561s
This was with 4 sessions in total. The CPU is near 100% busy and the response time is still ok, which confirms I have 4 cores available to run that.
Dec 07 18:58:36 real 0m28.562s
Dec 07 18:59:06 real 0m30.618s
Dec 07 18:59:36 real 0m30.002s
Dec 07 19:00:07 real 0m30.921s
Dec 07 19:00:39 real 0m31.931s
Dec 07 19:01:11 real 0m32.233s
Dec 07 19:01:43 real 0m32.138s
Dec 07 19:02:13 real 0m29.676s
Dec 07 19:02:44 real 0m30.483s
One more session here. Now the CPU is a 100% and the processes have to wait 1/5th of their time in runqueue as there is only 4 threads available. That’s an additional 20% that we can see in the response time.
Not starting more processes, but increasing the capacity now, setting the maximum ACU to 24 which then enables auto-scaling:
...
Dec 07 19:08:02 real 0m33.176s
Dec 07 19:08:34 real 0m32.346s
Dec 07 19:09:01 real 0m26.912s
Dec 07 19:09:25 real 0m24.319s
Dec 07 19:09:35 real 0m10.174s
Dec 07 19:09:37 real 0m1.704s
Dec 07 19:09:39 real 0m1.952s
Dec 07 19:09:41 real 0m1.600s
Dec 07 19:09:42 real 0m1.487s
Dec 07 19:10:07 real 0m24.453s
Dec 07 19:10:32 real 0m25.794s
Dec 07 19:10:57 real 0m24.917s
...
Dec 07 19:19:48 real 0m25.939s
Dec 07 19:20:13 real 0m25.716s
Dec 07 19:20:40 real 0m26.589s
Dec 07 19:21:06 real 0m26.341s
Dec 07 19:21:34 real 0m27.255s
At 19:00 I increased to maximum ACU to 24 and let it auto-scale. The engine restarted at 19:09:30 and I got some errors until 19:21 where I reached the optimal response time again. I have 5 sessions running on a machine sized for 24 ACUs which I think is 6 OS threads and then I expect 5/6=83% CPU utilization if all my hypothesis are right. Here are the CloudWatch metrics:
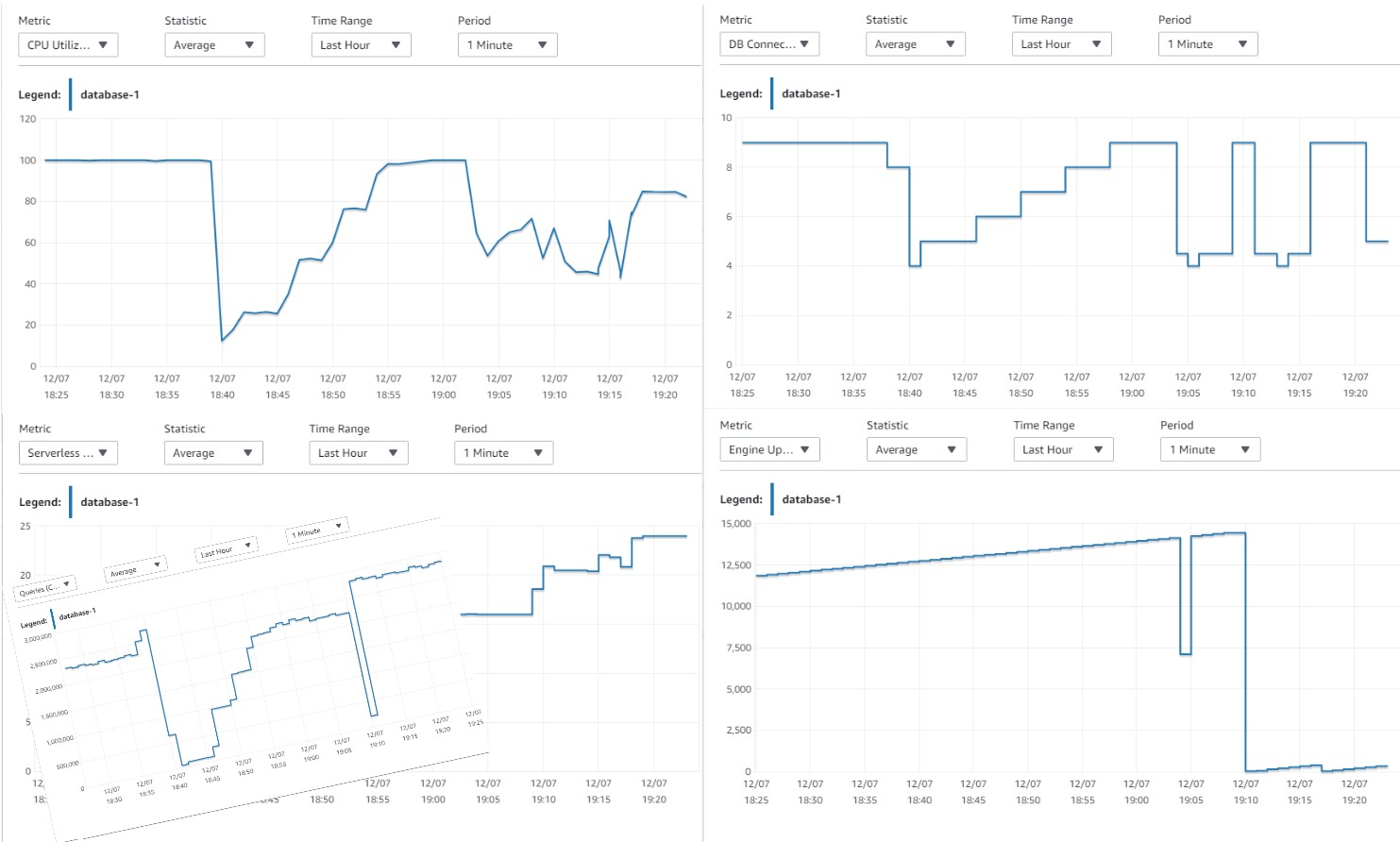
Yes, it seems we reached this 83% after some fluctuations. Those irregularities may be the consequence of my scripts running loops of long procedures. When the engine restarted (visible in “Engine Uptime”), I was disconnected for a while (visible in “DB Connections”), then the load decreased (visible in “CPU Utilization”), then scaling-down the available resources (visible in “Serverless Capacity Unit”)
The correspondence between ACU and RAM is documented (visible when defining the min/max and reported in my previous post) and the the instance types for provisioned Aurora gives the correspondance between RAM and vCPU (which confirms what I’ve seen here 16 ACU 32GB 4 vCPU as a db.r5.xlarge): https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Concepts.DBInstanceClass.html#aurora-db-instance-classes
Please remember, all those are guesses as very little information is disclosed about how it works internally. And this is a preview beta, many things will be different when GA. The goal of this blog is only to show that a little understanding about how it works will be useful when deciding between provisioned or serverless, think about side effects, and interpret the CloudWatch metrics. And we don’t need huge workloads for this investigation: learn on small labs and validate it on real stuff.
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ADE_WEB-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/NAC_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/HER_web-min-scaled.jpg)