Have you ever wondered what is the impact of SSL communications or the impact of a specific Load Balancing mechanisms on the performance of your Alfresco environment? Alfresco (the Company at that time, before it became Hyland) ran some benchmark and published the results a few years ago but that might not be very relevant to you as you might be running your infrastructure very differently to what they used. Networking & latency, CPUs, memory, disks, virtualization, etc… All that will have an impact on the performance so you cannot really take external data for granted. In this blog, I will look specifically on the import side of things.
I. Setup details
Recently, I had a customer which wanted to migrate 3 million documents to Alfresco and they wanted to know how long it could take. This specific environment has 2 Alfresco Content Services (7.x) Nodes in Cluster as well as 2 Alfresco Search Services (Solr6) Nodes using Sharding. It’s not a new environment, it has been running since several years already and has around 10TB of content stored inside. At dbi services, we have a team that can help customers execute Load Tests / Stress Tests for their applications (e.g. this blog). However, that will usually require a certain amount of time to integrate the Load Test software (like JMeter) and the target application as well as to design the needed scenarios beforehand. This customer didn’t really need to pull out the big gun as it was just to get an idea on the import speed. Instead, I proposed to simply script a small importer to be as close as possible to the exact performance that the migration would have, using the REST-API from outside of the Alfresco Cluster Nodes (to consider also the networking & latency), using the same user/permissions/ACLs, etc.
To give a bit more details regarding the setup, there is an Apache HTTPD installed on each Alfresco Nodes. The customer doesn’t have any global load balancer solution (neither hardware nor software) and therefore, to avoid single point of failure (SPOF), the DNS would redirect the traffic to any of the 2 Apache HTTPD, which would then again redirect the traffic to any of the 2 Apache Tomcat hosting the alfresco.war application. That’s one way to do it but there are other solutions possible. Therefore, the question came about what the impact of the SSL communications was exactly as well as what would be the difference if the Load Balancing mechanisms would be different. Like, for example, only redirecting the requests to the local Tomcat and not caring about the second Node. If you do that, of course you might introduce a SPOF, but for the migration purpose, which is very short-lived and that can use a decided URL/PORT, it could be an option (assuming it brings a non-negligeable performance gain).
II. Test cases
On a TEST environment, I decided to slightly update the Apache HTTPD and Apache Tomcat configurations to allow for these test cases:
- Apache HTTPD in HTTPS with Load Balancing (mod_jk) >> standard day-to-day configuration used so far, to avoid SPOF
- Apache HTTPD in HTTP with Load Balancing (mod_jk) >> normally redirect the traffic to HTTPS (above config) but I modified that to send the request to Tomcat instead
- Apache Tomcat in HTTP (bypass Apache HTTPD) >> normally blocked but I allowed it
- Apache HTTPD in HTTPS without Load Balancing (proxy) >> normally doesn’t exist but I added a simple proxy config to send the request to Tomcat instead
- Apache HTTPD in HTTP without Load Balancing (proxy) >> normally doesn’t exist but I added a simple proxy config to send the request to Tomcat instead
III. Documents, metadata & import script
To be as close as possible with the real migration for this customer, I took, as input, a few of the smallest documents that will be imported, a few of the biggest (300 times bigger than the smallest) and a few around the average size (30 times bigger than the smallest). I also took different mimetypes like PDF, XML, TXT and the associated expected metadata for all of these. These documents are all using a custom type with ~10 custom properties.
I love bash/shell scripting, it’s definitively not the fastest solution (C/C++, Go, Python, Perl or even Java would be faster) but it’s still decent and above all, it’s simple, so that’s what I used. The goal isn’t to have the best performance here, but just to compare apples to apples. The script itself is pretty simple, it defines a few variables like the REST-API URL to use (which depends on the Access Method chosen), the parent folder under which imports will be done, the username and asks for a password. It takes three parameters as command line arguments, the Access Method to be used, the type of documents to import (small/average/large sizes) and the number of documents to create in Alfresco. For example:
## script_name --access_method --doc_size nb_doc_to_import
./alf_import.sh --apache-https-lb --small 1000
./alf_import.sh --apache-http-lb --average 1000
./alf_import.sh --direct --large 1000
./alf_import.sh --apache-https-nolb --small 1000
./alf_import.sh --apache-http-nolb --small 1000
With these parameters, the script would select the templates to use and their associated metadata and then start a timer and a loop to import all the documents, in a single-thread (meaning 1 after the other). As soon as the last document has been imported, it would stop the timer and provide the import time as outcome. It’s really nothing complex, around 20 lines of code, simple and straightforward.
IV. Results – HTTPS vs HTTP & different access methods – Single-thread
I did 3 runs of 1000 documents, for each combination possible (between the access method and the document size). I then took the average execution time for the 3 runs which I transformed into an import speed (Docs/sec). The resulting graph looked like that:
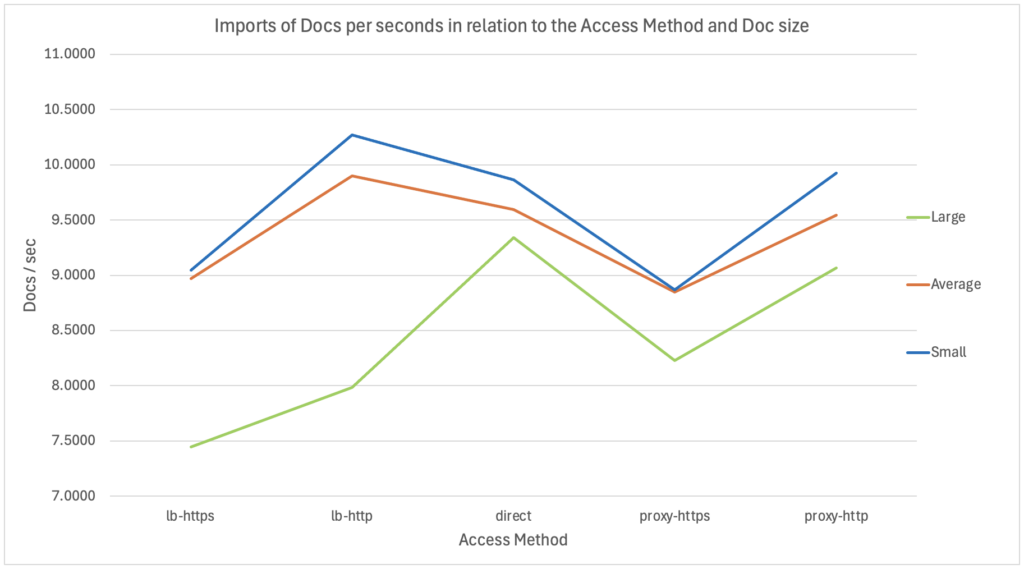
As a reminder, this is a single-thread import using REST-API inside a bash/shell script executed from a remote server (through the Network). So, what can we see on these results?
- First, and as I expected, we can see around 10/15% degradation when using HTTPS instead of HTTP.
- Then, between the smallest and the average size documents, we can only see a very small difference (with the same access method): around 1-3%. Which could indicate that the network might not be the limiting factor when documents aren’t too big, since the documents size increased by 30 times while the import speed is “only” 1-3% slower.
- A third interesting point is that with bigger files, the import is noticeably slower. That’s especially true when using the Load Balancing methods, as that means that irrespective of which Apache HTTPD we are talking to, there will be 50% of the requests going to the local Alfresco Node while the remaining 50% will be redirected to the second, remote, Alfresco Node. Therefore, the bigger the document, the slower it will be compared to other methods, as for 50% of the requests, it will need to transfer the document through the network twice (client -> Apache HTTPD + Apache HTTPD -> remote Alfresco Node). With the large documents, the size increased by 10 times (vs average) and the import speed is 10-25% slower.
- In relation to the previous point, there is another interesting thing to note for the small/medium documents. Indeed, even with a single thread execution, using the Load Balancing method is actually 3-4% faster than the direct access to Tomcat and than a plain Reverse Proxy. How could that be? If we consider the network, it should be slower, no? I believe this shows that the Apache HTTPD implementation of the Load Balancing via “mod_jk” is really the most efficient way to access an Apache Tomcat. This difference would probably be even more exacerbated with multi-threads, while doing Load Tests / Stress Tests.
V. Import script with Multi-threads?
With the previous script, it was possible to test different import/access methods, but it was only using a single thread. This means that new requests would only come in when the previous one was already completed, and the result was returned to the client. That’s obviously not like that in reality, as you might have several users working at the same time, on different things. In terms of Migration, to increase the import speed, you will also most probably have a multi-threaded architecture as it can drastically reduce the time required. In a similar approach, the customer also wanted to see how the system behaves when we add several importers running in parallel.
Therefore, I used a second script, a wrapper of sort, that would trigger/manage/monitor multiple threads executing the first script. The plan is, of course, to provide the exact same command line arguments as before, but we would also need a new one for the number of threads to start. For example:
## script_name --access_method --doc_size nb_doc_to_import nb_threads
./alf_multi_thread.sh --apache-https-lb --small 1000 2
./alf_multi_thread.sh --apache-http-lb --average 1000 6
Most parameters would just be forwarded to the first script, except for the number of threads (obviously) and the number of documents to import. To keep things consistent, the parameter “nb_doc_to_import” should still represent the total number of documents to import and not the number per thread. This is because if you try to import 1000 documents on 6 threads, for example, you will be able to do either 996 (6166) documents or 1002 (6167) but not 1000… Giving 1000 documents to import, the script would do some division with remainder so that the threads #1, #2, #3 and #4 would import 167 documents while the threads #5 and #6 would only import 166 documents. This distribution would be calculated first and then all threads would be started at the same time (+/- 1ms). The script would then monitor the progress of the different threads and report the execution time when everything is completed.
VI. Results – Scaling the import – Multi-threads
As previously, I did 3 imports of 1000 documents each of took the average time. I executed the imports for 1 to 10 threads as well as 15, 20, 30, 50, 70, 90 and 100 threads. In addition, I did all that with both 1 Alfresco Node or 2 Alfresco Nodes, to be able to compare the speed if only 1 Tomcat is serving 100% of the requests or if the load is shared 50/50. The resulting graph looked like that:
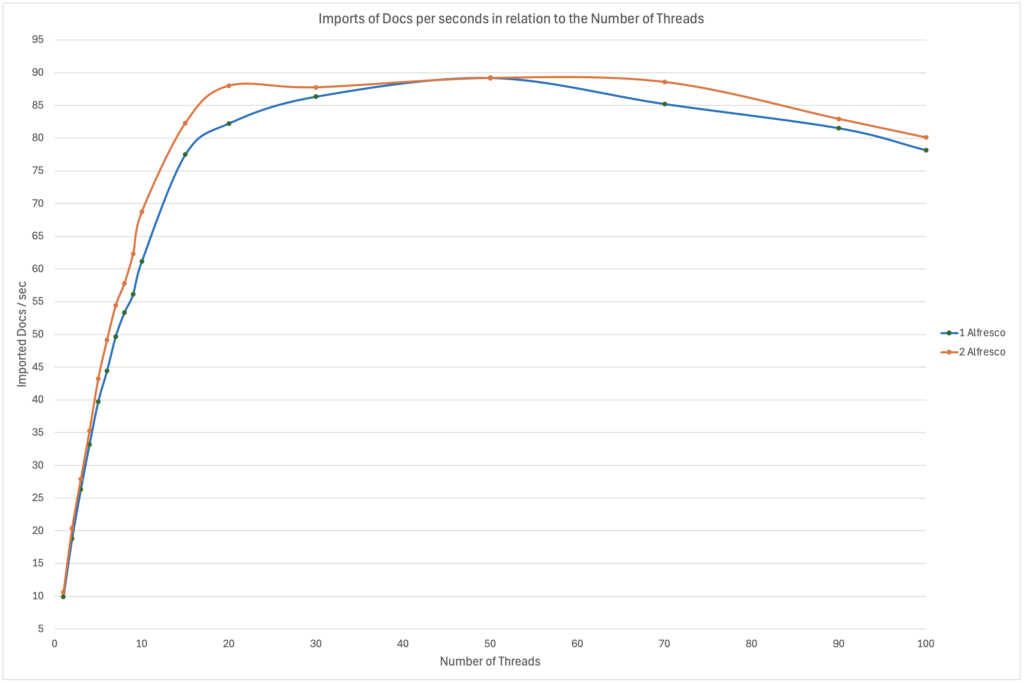
So, what can we see on these results?
- It’s pretty clear that the ingestion speed is increasing in an almost linear way from 1 to ~8/10 threads. The increase then slows down between 10 and 50 threads before the import speed actually starts decreasing from 70 parallel threads. The limit reached and the number of threads seen might just be related to the fact that I was using a bash/shell script and the fact that the OS on which I was running the importer (my client workstation) was obviously limited in terms of processing power. I had only 4 CPUs, so when you try to run 20/50/70 threads on it, it’s bound to reach a threshold where your threads are actually just waiting for some CPU time before it gets executed. Therefore, adding more might not improve the performance and it might actually Have the opposite effect.
- There isn’t much difference in terms of ingestion speed whether we used only 1 or 2 Alfresco Node(s). With 1 to 4 threads, it was ~6% faster to use 2 Alfresco Nodes. From 5 to 10 threads, the gap widens a bit but, in the end, the maximum difference was only ~10%. After 10 parallel threads, the gap reduces again and then the threshold/limit is pretty much the same. You might think something like: “Why is it not 2x faster to use 2 Alfresco Nodes?”. Well, it’s just not enough threads. Whether you are running 6 threads on 1 Alfresco Node or 3 threads on each of 2 Alfresco Nodes (3×2=6), it’s just not enough to see a big difference. The number of threads is fixed, so you need to compare 6 threads in total. With that in mind, this test isn’t sufficient because we are far from what Tomcat can handle and that means the small difference seen is most probably coming from the client I was using and not Alfresco.
In summary, what is the limiting factor here? The CPU of my client workstation? The networking? The Clustering? The DB? It’s pretty hard to say without further testing. For example, adding more CPU and/or other client workstations to spread the source of the requests. Or removing the clustering on this environment so that Alfresco doesn’t need to maintain the clustering-related caches and other behaviours required. In the end, the customer just wanted to get an idea of how the import speed increases with additional threads, so the limit wasn’t really relevant here.
As a closing comment, it actually took much more time to run the tests and gather/analyse the results than to create the scripts used. As mentioned previously, if you would like to do real Load Tests / Stress Tests (or something quick&dirty as here :D), don’t hesitate to contact us, some of my colleagues would be very happy to help.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/MOP_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/GME_web-min-scaled.jpg)