A few weeks ago, as the final steps of a cloning procedure, I wanted to check if the cloned repository was OK. One of the tests was to peek and poke around in the repository and try to access its content. This is typically the kind of task for which you’d use a GUI-based program because it is much quicker and easier this way rather than by sending manually typed commands to the server from within idql and iapi and transferring the contents to a desktop where a pdf reader, word processor and spreadsheet programs can be used to visualize them. Documentum Administrator (alias DA) is the tool we generally use for this purpose. It is a browser-based java application deployed on a web application server such as Oracle WebLogic (which is overkill just for DA) or tomcat. It also requires IE as the browser because DA needs to download an executable extension for Windows in order to enable certain functionalities. So, I had to download and install the full requirements’ stack to enable DA: an openjdk (several trials before the correct one, an OpenJDK v11, was found), tomcat, DA (twice, one was apparently crippled), configure and deploy DA (with a lots of confusing date errors which could relate to the cloning process but were not, after all), start my Windows VM (all 8 Gb of RAM of it), start IE (which I never use, and you shouldn’t either), point IE to the aws instance DA was installed in, download and install the extension when prompted to do so, all this only to notice that 1. content visualization still did not work and 2. its installation did not stick as it kept asking to download and install the extension over and over again. All this DA part took twice as long as the cloning process itself. All I wanted was to browse the repository, click on a few random files here and there to see if their content was reachable, and to do that I had to install several Gb of, dare I say ?, bloatware. “This is ridiculous”, I thought, there has to be a better way. And indeed there is.
I remembered a cute little python module I use sometimes, server.py. It embarks a web server and presents a navigable web interface to the file system directory it is started from. From there, one can click on a file link and the file is opened in the browser or by the right application if it is installed and the mime file association is correct; or click on a sub-directory link to enter it. Colleagues can also use the URL to come and fetch files from my machines if needed, a quick way to share files, albeit temporarily.
Starting the file server in the current directory:
![]()
Current directory’s listing:
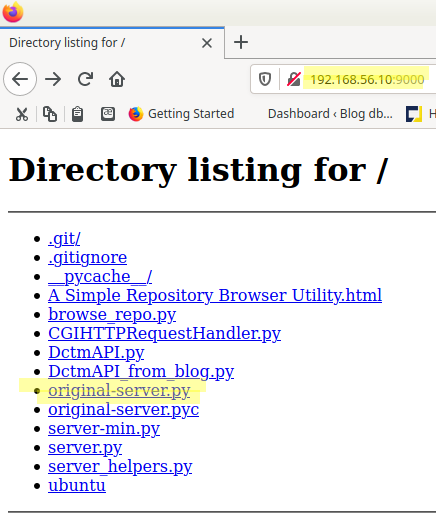
As it is open source, its code is available here server.py.
The file operations per se, mainly calls to the os module, were very few and thin and so I decided to gave it a try, replacing them with calls to the repository through the module DctmApi.py (see blog here DctmAPI.py). The result, after resolving a few issues due to the way Documentum repositories implement the file system metaphor, was quite effective and is presented in this blog. Enjoy.
Installing the module
As the saying goes, The shoemaker’s Son Always Goes Barefoot, so no git hub here and you’ll have to download the module’s original code from the aforementioned site, rename it to original-server.py and patch it. The changes have been kept minimal so that the resulting patch file is small and manageable.
On my Linux box, the downloaded source had extraneous empty lines, which I removed with following one-liner:
$ gawk -v RS='\n\n' '{print}' original-server.py > tmp.py; mv tmp.py original-server.py
After that, save the following patch instructions into the file delta.patch:
623a624,625
> import DctmBrowser
>
637a640,644
> session = None
>
> import re
> split = re.compile('(.+?)\(([0-9a-f]{16})\)')
> last = re.compile('(.+?)\(([0-9a-f]{16})\).?$')
666,667c673,674
< f = None
# now path is a tuple (current path, r_object_id)
> if DctmBrowser.isdir(SimpleHTTPRequestHandler.session, path):
678,685c685,686
< for index in "index.html", "index.htm":
< index = os.path.join(path, index)
< if os.path.exists(index):
< path = index
< break
< else:
< return self.list_directory(path)
return self.list_directory(path)
> f = None
687c688
f = DctmBrowser.docopen(SimpleHTTPRequestHandler.session, path[1], 'rb')
693c694
self.send_header("Content-type", DctmBrowser.splitext(SimpleHTTPRequestHandler.session, path[1]))
709a711
> path is a (r_folder_path, r_object_id) tuple;
712c714
list = DctmBrowser.listdir(SimpleHTTPRequestHandler.session, path)
718c720
list.sort(key=lambda a: a[0].lower())
721,722c723,726
< displaypath = urllib.parse.unquote(self.path,
if ("/" != self.path):
> displaypath = "".join(i[0] for i in SimpleHTTPRequestHandler.split.findall(urllib.parse.unquote(self.path, errors='surrogatepass')))
> else:
> displaypath = "/"
724c728
displaypath = urllib.parse.unquote(path[0])
727c731
title = 'Repository listing for %s' % displaypath
734c738
< r.append('\n<h1>%s</h1>' % title)
---
> r.append('<h3>%s \n' % title)
736,737c740,745
< for name in list:
# add an .. for the parent folder;
> if ("/" != path[0]):
> linkname = "".join(i[0] + "(" + i[1] + ")" for i in SimpleHTTPRequestHandler.split.findall(urllib.parse.unquote(self.path, errors='surrogatepass'))[:-1]) or "/"
> r.append('%s' % (urllib.parse.quote(linkname, errors='surrogatepass'), html.escape("..")))
> for (name, r_object_id) in list:
> fullname = os.path.join(path[0], name)
740c748
if DctmBrowser.isdir(SimpleHTTPRequestHandler.session, (name, r_object_id)):
742,749c750,751
< linkname = name + "/"
< if os.path.islink(fullname):
< displayname = name + "@"
< # Note: a link to a directory displays with @ and links with /
< r.append('Apply the patch using the following command:
$ patch -n original-server.py delta.patch -o server.py
server.py is the patched module with the repository access operations replacing the file system access ones.
As the command-line needs some more parameters for the connectivity to the repository, an updated main block has been added to parse them and moved into the new executable browser_repo.py. Here it is:
import argparse
import server
import textwrap
import DctmAPI
import DctmBrowser
if __name__ == '__main__':
parser = argparse.ArgumentParser(
formatter_class=argparse.RawDescriptionHelpFormatter,
description = textwrap.dedent("""\
A web page to navigate a docbase's cabinets & folders.
Based on Aukasz Langa python server.py's module https://hg.python.org/cpython/file/3.5/Lib/http/server.py
cec at dbi-services.com, December 2020, integration with Documentum repositories;
"""))
parser.add_argument('--bind', '-b', default='', metavar='ADDRESS',
help='Specify alternate bind address [default: all interfaces]')
parser.add_argument('--port', action='store',
default=8000, type=int,
nargs='?',
help='Specify alternate port [default: 8000]')
parser.add_argument('-d', '--docbase', action='store',
default='dmtest73', type=str,
nargs='?',
help='repository name [default: dmtest73]')
parser.add_argument('-u', '--user_name', action='store',
default='dmadmin',
nargs='?',
help='user name [default: dmadmin]')
parser.add_argument('-p', '--password', action='store',
default='dmadmin',
nargs='?',
help=' user password [default: "dmadmin"]')
args = parser.parse_args()
# Documentum initialization and connecting here;
DctmAPI.logLevel = 1
# not really needed as it is done in the module itself;
status = DctmAPI.dmInit()
if status:
print("dmInit() was successful")
else:
print("dmInit() was not successful, exiting ...")
sys.exit(1)
session = DctmAPI.connect(args.docbase, args.user_name, args.password)
if session is None:
print("no session opened in docbase %s as user %s, exiting ..." % (args.docbase, args.user_name))
exit(1)
try:
server.test(HandlerClass=server.SimpleHTTPRequestHandler, port=args.port, bind=args.bind, session = session)
finally:
print("disconnecting from repository")
DctmAPI.disconnect(session)
Save it into file browser_repo.py. This is the new main program.
Finally, helper functions have been added to interface the main program to the module DctmAPI:
#
# new help functions for browser_repo.py;
#
import DctmAPI
def isdir(session, path):
"""
return True if path is a folder, False otherwise;
path is a tuple (r_folder_path, r_object_id);
"""
if "/" == path[0]:
return True
else:
id = DctmAPI.dmAPIGet("retrieve, " + session + ",dm_folder where r_object_id = '" + path[1] + "'")
return id
def listdir(session, path):
"""
return a tuple of objects, folders or documents with their r_object_id, in folder path[0];
path is a tuple (r_folder_path, r_object_id);
"""
result = []
if path[0] in ("/", ""):
DctmAPI.select2dict(session, "select object_name, r_object_id from dm_cabinet", result)
else:
DctmAPI.select2dict(session, "select object_name, r_object_id from dm_document where folder(ID('" + path[1] + "')) UNION select object_name, r_object_id from dm_folder where folder(ID('" + path[1] + "'))", result)
return [[doc["object_name"], doc["r_object_id"]] for doc in result]
def docopen(session, r_object_id, mode):
"""
returns a file handle on the document with id r_object_id downloaded from its repository to the temporary location and opened;
"""
temp_storage = '/tmp/'
if DctmAPI.dmAPIGet("getfile," + session + "," + r_object_id + "," + temp_storage + r_object_id):
return open(temp_storage + r_object_id, mode)
else:
raise OSError
def splitext(session, r_object_id):
"""
returns the mime type as defined in dm_format for the document with id r_object_id;
"""
result = []
DctmAPI.select2dict(session, "select mime_type from dm_format where r_object_id in (select format from dmr_content c, dm_document d where any c.parent_id = d.r_object_id and d.r_object_id = '" + r_object_id + "')", result)
return result[0]["mime_type"] if result else ""
Save this code into the file DctmBrowser.py.
To summarize, we have:
1. the original module original_server.py to be downloaded from the web
2. delta.patch, the diff file used to patch original_server.py into file server.py
3. DctmAPI.py, the python interface to Documentum, to be fetched from the provided link to a past blog
4. helper functions in module DctmBrowser.py
5. and finally the main executable browser_repo.py
Admittedly, a git repository would be nice here, maybe one day …
Use the command below to get the program’s help screen:
$ python browser_repo.py --help
usage: browser_repo.py [-h] [--bind ADDRESS] [--port [PORT]] [-d [DOCBASE]]
[-u [USER_NAME]] [-p [PASSWORD]]
A web page to navigate a docbase's cabinets & folders.
Based on Aukasz Langa python server.py's module https://hg.python.org/cpython/file/3.5/Lib/http/server.py
cec at dbi-services.com, December 2020, integration with Documentum repositories;
optional arguments:
-h, --help show this help message and exit
--bind ADDRESS, -b ADDRESS
Specify alternate bind address [default: all
interfaces]
--port [PORT] Specify alternate port [default: 8000]
-d [DOCBASE], --docbase [DOCBASE]
repository name [default: dmtest73]
-u [USER_NAME], --user_name [USER_NAME]
user name [default: dmadmin]
-p [PASSWORD], --password [PASSWORD]
user password [default: "dmadmin"]
Thus, the command below will launch the server on port 9000 with a session opened in repository dmtest73 as user dmadmin with password dmadmin:
$ python browse_repo.py --port 9000 -d dmtest73 -u dmadmin -p dmadmin
If you prefer long name options, use the alternative below:
$ python browser_repo.py --port 9000 --docbase dmtest73 --user_name dmadmin --password dmadmin
Start your favorite browser, any browser, just as God intended it in the first place, and point it to the host where you started the program with the specified port, e.g. http://192.168.56.10:9000/:
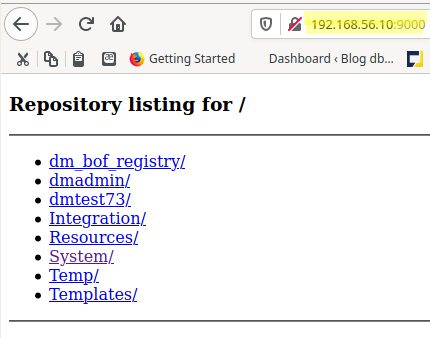
You are gratified with a very spartan, yet effective, view on the repository’s cabinets. Congratulations, you did it !
Moving around in the repository
As there is no root directory in a repository, the empty path or “/” are interpreted as a request to display a list of all the cabinets; each cabinet is a directory’s tree root. The program displays dm_folders and dm_cabinets (which are sub-types of dm_folder after all), and dm_document. Folders have a trailing slash to identify them, whereas documents have none. There are many other objects in repositories’ folders and I chose not to display them because I did not need to but this can be changed on lines 25 and 27 in the helper module DctmBrowser.py by specifying a different doctype, e.g. the super-type dm_sysobject instead.
An addition to the original server module is the .. link to the parent folder; I think it is easier to use it rather than the browser’s back button or right click/back arrow, but those are still usable since the program is stateless. Actually, a starting page could even be specified manually in the starting URL if it weren’t for its unusual format. In effect, the folders components and documents’ full path in URLs and html links are suffixed with a parenthesized r_object_id, e.g.:
http://192.168.56.10:9000/System(0c00c35080000106)/Sysadmin(0b00c3508000034e)/Reports(0b00c35080000350)/ -- or, url-encoded: http://192.168.56.10:9000/System%280c00c35080000106%29/Sysadmin%280b00c3508000034e%29/Reports%280b00c35080000350%29/
This looks ugly but it allows to solve 2 issues specific to repositories:
1. Document names are not unique in the same folder but are on the par with any other document’s attribute. Consequently, a folder can quietly contains hundreds of identically named documents without any name conflict. In effect, what tells two documents apart is their unique r_object_id attribute and that is the reason why it is appended to the links and URLs. This is not a big deal because this potentially annoying technical information is not displayed in the web page but is only visible while hovering over links and in the browser’s address bar.
2. Document names can contain any character, even “/” and “:”. So, given a document’s full path name, how to parse it and separate the parent folder from the document’s name so it can be reached ? There is no generic, unambiguous way to do that. With the appended document’s unique r_object_id, it is a simple matter to extract the id from the full path and Bob’s your uncle (RIP Jerry P.).
Both above specificities make it impossible to access a document through its full path name, therefore the documents’ ids must be carried around; for folder, it is not necessary but it has been done in order to have an uniform format. As a side-effect, database performance is also possibly better.
If the program is started with no stdout redirection, log messages are visible on the screen, e.g.:
dmadmin@dmclient:~/dctm-webserver$ python browser_repo.py --port 9000 --docbase dmtest73 --user_name dmadmin --password dmadmin dmInit() was successful Serving HTTP on 0.0.0.0 port 9000 ... 192.168.56.1 - - [05/Dec/2020 22:57:00] "GET / HTTP/1.1" 200 - 192.168.56.1 - - [05/Dec/2020 22:57:03] "GET /System%280c00c35080000106%29/ HTTP/1.1" 200 - 192.168.56.1 - - [05/Dec/2020 22:57:07] "GET /System%280c00c35080000106%29/Sysadmin%280b00c3508000034e%29/ HTTP/1.1" 200 - 192.168.56.1 - - [05/Dec/2020 22:57:09] "GET /System%280c00c35080000106%29/Sysadmin%280b00c3508000034e%29/Reports%280b00c35080000350%29/ HTTP/1.1" 200 - 192.168.56.1 - - [05/Dec/2020 22:57:14] "GET /System%280c00c35080000106%29/Sysadmin%280b00c3508000034e%29/Reports%280b00c35080000350%29/ConsistencyChecker%280900c3508000211e%29/ HTTP/1.1" 200 - 192.168.56.1 - - [05/Dec/2020 22:57:22] "GET /System%280c00c35080000106%29/Sysadmin%280b00c3508000034e%29/Reports%280b00c35080000350%29/StateOfDocbase%280900c35080002950%29/ HTTP/1.1" 200 - 192.168.56.1 - - [05/Dec/2020 22:57:27] "GET /System%280c00c35080000106%29/Sysadmin%280b00c3508000034e%29/ HTTP/1.1" 200 - ...
The logged information and format are quite standard for web servers, one log line per request, beginning with the client’s ip address, the timestamp, request type (there will be only GETs as the utility is read-only) and resource, and the returned http status code.
If the variable DctmAPI.logLevel is set to True (or 1 or an non-empty string or collection, as python interprets them all as the boolean True) in the main program, API statements and messages from the repository are logged to stdout too, which can help if troubleshooting is needed, e.g.:
dmadmin@dmclient:~/dctm-webserver$ python browser_repo.py --port 9000 --docbase dmtest73 --user_name dmadmin --password dmadmin
'in dmInit()'
"dm= after loading library libdmcl.so"
'exiting dmInit()'
dmInit() was successful
'in connect(), docbase = dmtest73, user_name = dmadmin, password = dmadmin'
'successful session s0'
'[DM_SESSION_I_SESSION_START]info: "Session 0100c35080002e3d started for user dmadmin."'
'exiting connect()'
Serving HTTP on 0.0.0.0 port 9000 ...
'in select2dict(), dql_stmt=select object_name, r_object_id from dm_cabinet'
192.168.56.1 - - [05/Dec/2020 23:02:59] "GET / HTTP/1.1" 200 -
"in select2dict(), dql_stmt=select object_name, r_object_id from dm_document where folder(ID('0c00c35080000106')) UNION select object_name, r_object_id from dm_folder where folder(ID('0c00c35080000106'))"
192.168.56.1 - - [05/Dec/2020 23:03:03] "GET /System%280c00c35080000106%29/ HTTP/1.1" 200 -
"in select2dict(), dql_stmt=select object_name, r_object_id from dm_document where folder(ID('0b00c3508000034e')) UNION select object_name, r_object_id from dm_folder where folder(ID('0b00c3508000034e'))"
192.168.56.1 - - [05/Dec/2020 23:03:05] "GET /System%280c00c35080000106%29/Sysadmin%280b00c3508000034e%29/ HTTP/1.1" 200 -
"in select2dict(), dql_stmt=select object_name, r_object_id from dm_document where folder(ID('0b00c35080000350')) UNION select object_name, r_object_id from dm_folder where folder(ID('0b00c35080000350'))"
192.168.56.1 - - [05/Dec/2020 23:03:10] "GET /System%280c00c35080000106%29/Sysadmin%280b00c3508000034e%29/Reports%280b00c35080000350%29/ HTTP/1.1" 200 -
"in select2dict(), dql_stmt=select mime_type from dm_format where r_object_id in (select format from dmr_content c, dm_document d where any c.parent_id = d.r_object_id and d.r_object_id = '0900c3508000211e')"
192.168.56.1 - - [05/Dec/2020 23:03:11] "GET /System%280c00c35080000106%29/Sysadmin%280b00c3508000034e%29/Reports%280b00c35080000350%29/ConsistencyChecker%280900c3508000211e%29/ HTTP/1.1" 200 -
Feel free to initialize that variable from the command-line if you prefer.
A nice touch in the original module is that execution errors are trapped in an exception handler so the program does not need to be restarted in case of failure. As it is stateless, errors have no effect on subsequent requests.
Several views on the same repositories can be obtained by starting several instances of the program at once with different listening ports. Similarly, if one feels the urge to explore several repositories at once, just start as many modules as needed with different listening ports and appropriate credentials.
To exit the program, just type ctrl-c; no data will be lost here as the program just browses repositories in read-only mode.
A few comments on the customizations
Lines 8 and 9 in the diff above introduce the regular expressions that will be used later to extract the path component/r_object_id couples from the URL’s path part; “split” is for one such tuple anywhere in the path and “last” is for the last one and is aimed at getting the r_object_id of the folder that is clicked on from its full path name. python’s re module allows to pre-compile them for efficiency. Note the .+? syntax to specify a non-greedy regular expression.
On line 13, the function isdir() is now implemented in the module DctmBrowser and returns True if the clicked item is a folder.
Similarly, line 25 calls a reimplementation of os.open() in module DctmBrowser that exports locally the clicked document’s content to /tmp, opens it and returns the file handle; this will allow the content to be sent to the browser for visualization.
Line 31 calls a reimplementation of os.listdir() to list the content of the clicked repository folder.
Line 37 applies the “split” regular expression to the current folder path to extract its tuple components (returned in an array of sub-path/r_object_id couples) and then concatenating the sub-paths together to get the current folder to be displayed later. More concretely, it allows to go from
/System(0c00c35080000106)/Sysadmin(0b00c3508000034e)/Reports(0b00c35080000350)/
to
/System/Sysadmin/Reports
which is displayed in the html page’s title.
The conciseness of the expression passed to the join() is admirable; lots of programming mistakes and low-level verbosity is prevented thanks to python’s list comprehensions.
Similarly, on line 52, the current folder’s parent folder is computed from the current path.
On line 86, the second regular expression, “last”, is applied to extract the r_object_id of the current folder (i.e. the one that is clicked on).
Line 89 to 121 were removed from the original module because mime processing is much simplified as the repository maintains a list of mime formats (table dm_format) and the selected document’s mime type can be found by just looking up that table, see function splitext() in module DctmBrowser, called on line 27. By returning to it a valid mime type, the browser can cleverly process the content, i.e. display the supported content types (such as text) and prompt for some other action if not (e.g. office documents).
One line 126, the session id is passed to class SimpleHTTPRequestHandler and stored as a class variable; later it is referenced as SimpleHTTPRequestHandler.session in the class but self.session would work too, although I prefer the former syntax as it makes clear that session does not depend on the instantiations of the class; the session is valid for any such instantiations. As the program connects to only one repository at startup time, no need to make session an instance variable.
The module DctmBrowser is used as a bridge between the module DctmAPI and the main program browser_repo.py. This is were most of the repository stuff is done. As it is blatant here, not much is needed to go from listing directories and files from a filesystem to listing folders and documents from a repository.
Security
As showed by the usage message above (option ––help), a bind address can be specified. By default, the embedded web server listens on all the machine’s network interfaces and, as there is not identification against the web server, another machine on the same network could reach the web server on that machine and access the repository through the opened session, if there is no firewall in the way. To prevent this, just specify the loopback IP adress, 127.0.0.1 or localhost:
dmadmin@dmclient:~/dctm-webserver$ python browser_repo.py --bind 127.0.0.1 --port 9000 --docbase dmtest73 --user_name dmadmin --password dmadmin ... Serving HTTP on 127.0.0.1 port 9000 ... # testing locally (no GUI on server, using wget): dmadmin@dmclient:~/dctm-webserver$ wget 127.0.0.1:9000 --2020-12-05 22:06:02-- http://127.0.0.1:9000/ Connecting to 127.0.0.1:9000... connected. HTTP request sent, awaiting response... 200 OK Length: 831 Saving to: 'index.html' index.html 100%[=====================================================================================================================>] 831 --.-KB/s in 0s 2020-12-05 22:06:03 (7.34 MB/s) - 'index.html' saved [831/831] dmadmin@dmclient:~/dctm-webserver$ cat index.htmlRepository listing for / Repository listing for /
In addition, as the web server carries the client’s IP address (variable self.address_string), some more finely tuned address restriction could also be implemented by filtering out unwelcome clients and letting in authorized ones.
Presently, the original module does not support https and hence the network traffic between clients and server is left unencrypted. However, one could imagine to install a small nginx or apache web server as a front on the same machine, setup security at their level and insert a redirection to the python module listening on localhost with the http protocol, a quick and easy solution that does not required any change in the code, although that would be way out of scope of the module, whose primary goal is to serve requests from the same machine it is running on. Note that if we’re starting talking about adding another web server, we could as well move all the repository browsing code into a separate (Fast)CGI python program directly invoked by the web server and make it available to any allowed networked users as a full blown service complete with authentication and access rights.
Conclusion
This tool is really a nice utility for browsing repositories, especially those running a Unix/linux machines because most of the time the servers are headless and have no GUI applications installed. The tool interfaces any browser, running on any O/S or device, with such repositories and alleviate the usual burden of executing getfile API statements and scp commands to transfer the contents to the desktop for visualization. For this precise functionality, it is even better than dqman, at least for browsing and visualizing browser-readable contents.
There is a lot of room for improvement if one would like a full repository browser, e.g. to display the metadata as well. In addition, if needed, the original module’s functionality, browsing the local sub-directory tree, could be reestablished as it is not incompatible with repositories.
The tool also proves again that the approach of picking an existing tool that implements most of the requirements, and customizing it to a specific need is quite an very effective one.
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/GME_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ATR_web-min-scaled.jpg)