Last night, I had an interesting discussion with one of my MVP French friend that faces a weird situation where a query that uses a statement level RECOMPILE hint produces an execution plan that disappointed him. He told me we can simulate the same situation by using the AdventureWorks database and Sales.SalesOrderHeader table.
First, we have to add a nonclustered index on the orderdate column as follows:
Now, let me show you the query. In fact we compare two queries and two potential behaviours. Indeed, the first query will use a local variable and an inequality operator while the second query will be pretty the same except we add the recompile hint option.
Let’s compare the estimated execution plan of the both queries. In fact, the estimated plan produced by the query optimizer is the same in both cases.
Next, let’s compare their real execution plans.
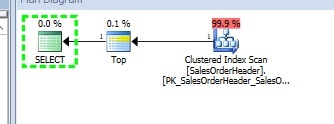
–> Concerning the first query:
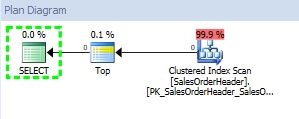
–> Concerning the second query (with recompile hint):
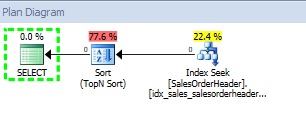
Interesting, isn’t it? For the same query except the recompile option the query optimizer has decided to use an index scan operator in the first case and an index seek in the second case. At this point, of course we supposed that the recompile hint affects the query optimizer decision but how far? Well, the response lies in the way the query optimizer handles the parameter @date.
In the first query, the query optimizer is not aware of the @date parameter value at the compile time.
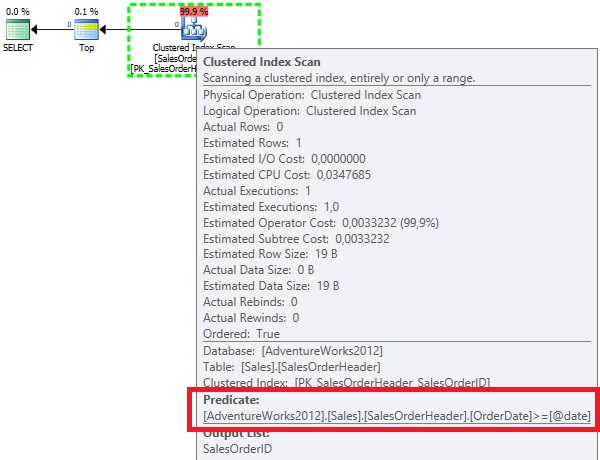
It means that it will not be able to use the density information and instead it will use the standard guess of 30% selectivity for inequality comparisons. If we take a look at the statistic object of the primary key we may see that 30% of the total rows is equal to 31465 * 0.3 = 9439
dbcc show_statistics (‘sales.salesorderheader’, ‘PK_SalesOrderHeader_SalesOrderID’) with stat_header;
![]()
But at this point, we may wonder why SQL Server is using the primary key rather than the index on the orderdate column for example. In fact, the primary key is a good candidate for this query includes an ORDER BY clause (order by SalesOrderId). It means that data is already ordered by SalesOrderId and the query optimizer doesn’t need to perform an extra step that consists in sorting data before using the top operator as shown below:
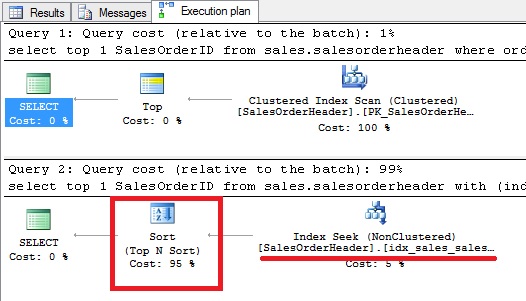
Let’s continue with the second query and notice how SQL Server is handling the @date parameter this time: the local variable value is transformed as parameter as shown below:
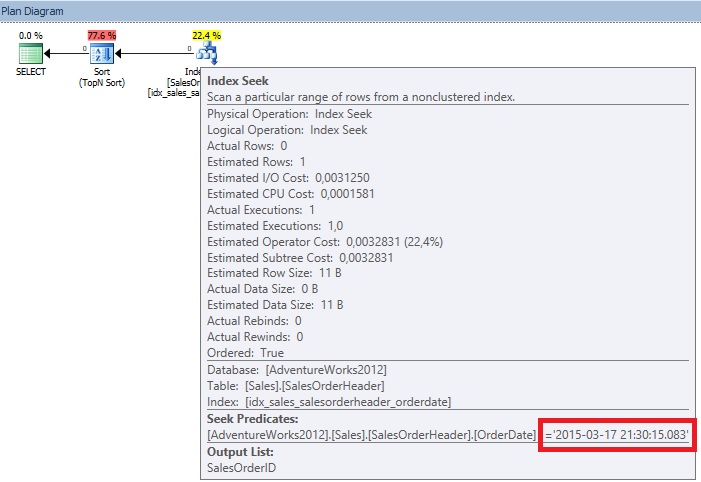
Hmm… does it mean that SQL Server is aware of local variable value when using the statement RECOMPILE hint? In fact, yes it does and this detail changes completely the story because in this case SQL Server is able to use the histogram of the index idx_salesorderheader_orderdate. However, we are in such situation where the predicate value is not represented on the histogram and SQL Server will use an estimate of 1 that implies to use an index seek operator. Likewise, we may wonder why SQL Server has decided to seek the index idx_salesorderheader_orderdate with a TopN Sort operator here. Once again, the query optimizer is cost-based and this strategy is surely the less costly. Let’s demonstrate by comparing the both strategies:

Let’s take a look at the statistics related on both CPU and IO consumption of the both queries
–> Concerning the first query (clustered index scan operator)
–> Concerning the second query (index seek operator). Yes, in this case you have only to read 2 pages (the index root page and one data page at leaf level)
The bottom line: in certain cases we may be surprised by the choices made by the query optimizer but most of the time, we can trust it and this is what I wanted to point out in the blog post! The truth often lies elsewhere 🙂
Happy optimization!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/09/DDI_web-min-scaled.jpg)