Introduction
TimescaleDB is a “time-series” database (TSDB). This kind of databases are optimized for storing, manipulating and querying time-series data. But… what is time-series data ?
Time-series data is a collection of metrics (regular) or measurements (irregular) that are tracked over time. In other words, time-series data is data that collectively represents how a system, process, or behavior changes over time.

As you can imagine, time-series database are not new. The first time-series databases were mainly used for storing financial data. Today, time-series data are everywhere and we can find them in several applications and across various industries and business. The major reason is that we live surrounded by objects that are more and more connected and therefore have more and more sensors. IoT is thus one of the main use cases of time-series data, but it is obviously not the only one. Here are some other areas where this kind of data is used :
- Weather (e.g. rainfall measurement)
- Medical (e.g. heartbeat per minutes)
- Website (e.g. daily visitors on a blog)
- Retail (e.g. annual sales)
- And much more…
TimescaleDB is actually a relational database for time-series data. It’is packaged as an extension of PostgreSQL, bringing new capabilities and features for data management and analytics as well as new optimizations and mechanisms for storage and query planner/execution.
Being integrated to PostgreSQL as an extension allows TimescaleDB to take advantage of all the possibilities PostgreSQL offers in terms of data (data types, index types, schema, etc,…) but also of all the other available extensions. Some of them are particularly well adapted to work with TimescaleDB, I am thinking in particular of the well known PostGIS and pg_stat_statement.
TimescaleDB features have been designed specifically for time-series data management. Among them, we can find :
- Transparent and automated partitioning
– To improve performance by keeping latest data and indexes in memory
- Native columnar compression
– Compression according to data type (up to 97% storage reduction)
- Continuous and real-time aggregations
– By maintaining a materialized view of aggregate time-series data to improve query performance
- Automated time-series data management
– Retention policies, reordering policies, compression policies, aso…
- In-database job-scheduling framework
– To run native and user-defined actions
- Horizontally-scalable multi-node operation
– To scale the the time-series data across many databases
Hypertables
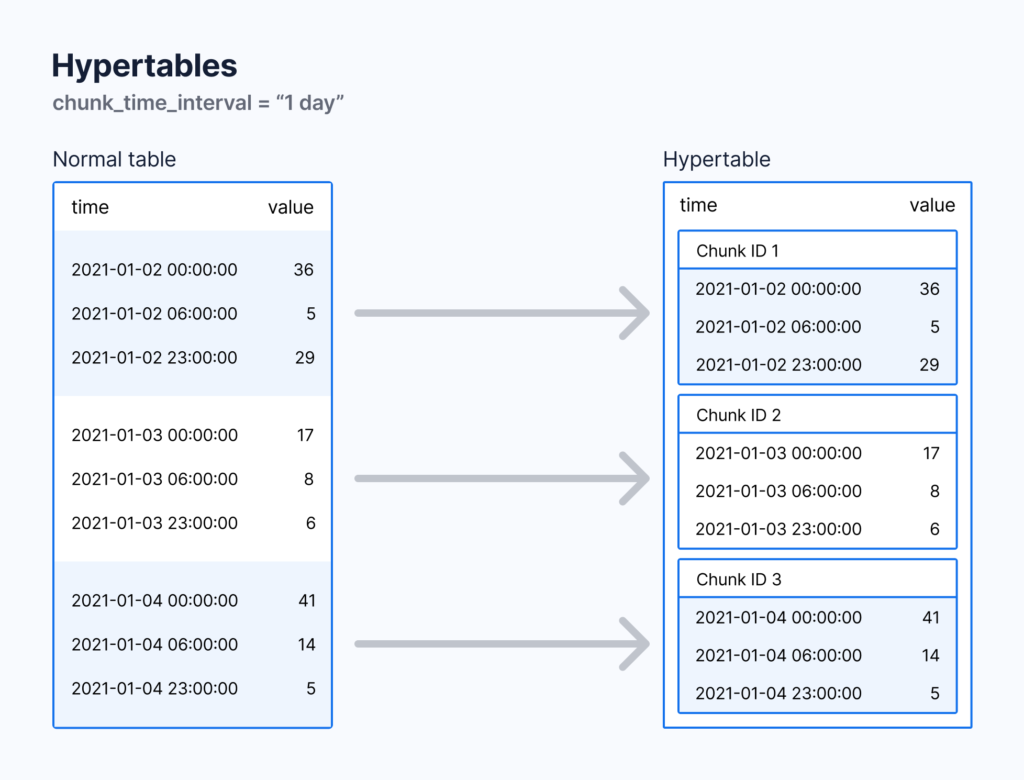
TimescaleDB works with a specific type of tables called hypertables. Hypertables are designed to improve insert and query performance by partitioning time-series data on its time parameter.
The hypertables are actually parent tables made of many regular PostgreSQL child tables, called “chunks”. Each chunk is a partition based on a time constraint and only contains data from that time range. They are automatically set up and maintained by the database, meanwhile you insert and read the data as if it stored in a single and standard PostgreSQL table.
You can have both hypertables and regular PostgreSQL tables in the same database. Obviously, you should choose hypertables for time-series data, and regular PostgreSQL tables for relational data.
Deployment
TimescaleDB is available with several deployment options :
- Timescale Cloud
Fully managed service with automatic backup and restore, HA via replication, scaling, resizing, aso…
https://console.cloud.timescale.com/
- Managed Service for TimescaleDB
A service is a cloud instance on your chosen cloud provider, which you can install your database on. Available cloud providers are Azure, GCP and certain regions in AWS.
https://portal.managed.timescale.com/login
- Self hosted
Of course, TimescaleDB can also be installed on-premise on Linux (Debian, Ubuntu, RHEL, Rocky Linux, Fedora), on Windows or MacOS.
This is the option I chose for this blog.
Installation
I decided to install TimescalDB on one of my PostgreSQL 14.6 instance that I have deployed with YaK :-). When deploying TimescalDB on an already existing instance, it is recommended to install it from source instead of using the package manager of the Linux distribution. Please check before the compatibility matrix between PostgreSQL and TimescaleDB : https://docs.timescale.com/timescaledb/latest/how-to-guides/upgrades/upgrade-pg/.
The first thing to do is to clone the git repository and to checkout to the latest version (here 2.9.3) :
postgres@timescale:/home/postgres/ [pg14.6] git clone https://github.com/timescale/timescaledb
Cloning into 'timescaledb'...
remote: Enumerating objects: 58335, done.
remote: Counting objects: 100% (238/238), done.
remote: Compressing objects: 100% (161/161), done.
remote: Total 58335 (delta 126), reused 142 (delta 77), pack-reused 58097
Receiving objects: 100% (58335/58335), 30.13 MiB | 17.35 MiB/s, done.
Resolving deltas: 100% (48073/48073), done.
09:08:42 postgres@timescale:/home/postgres/ [pg14.6]
postgres@timescale:/home/postgres/ [pg14.6] cd timescaledb/
postgres@timescale:/home/postgres/timescaledb/ [pg14.6] git checkout 2.9.3
Note: switching to '2.9.3'.
...
...
...
postgres@timescale:/home/postgres/timescaledb/ [pg14.6]
Then, bootstrap the built system :
postgres@timescale:/home/postgres/timescaledb/ [pg14.6] ./bootstrap
-- The C compiler identification is GNU 10.2.1
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working C compiler: /usr/bin/cc - skipped
-- Detecting C compile features
-- Detecting C compile features - done
-- TimescaleDB version 2.9.3. Can be updated from version 2.9.2
-- Build type is Release
-- Install method is 'source'
-- Performing Test CC_SUPPORTS_NO_UNUSED_CLI_ARG
...
...
...
-- Configuring done
-- Generating done
-- Build files have been written to: /home/postgres/timescaledb/build
TimescaleDB build system initialized in ./build. To compile, do:
cd ./build && make
postgres@timescale:/home/postgres/timescaledb/ [pg14.6]
Build the extension :
postgres@timescale:/home/postgres/timescaledb/ [pg14.6] cd build && make
Scanning dependencies of target sqlupdatescripts
[ 1%] Generating /home/postgres/timescaledb/build/sql/updates/post-update.sql.processed
[ 1%] Generating /home/postgres/timescaledb/build/sql/timescaledb--2.9.2--2.9.3.sql
[ 2%] Generating /home/postgres/timescaledb/build/sql/timescaledb--2.9.1--2.9.3.sql
[ 2%] Generating /home/postgres/timescaledb/build/sql/timescaledb--2.9.0--2.9.3.sql
[ 3%] Generating /home/postgres/timescaledb/build/sql/timescaledb--2.8.1--2.9.3.sql
...
...
...
[ 99%] Building C object tsl/src/CMakeFiles/timescaledb-tsl.dir/remote/utils.c.o
[100%] Linking C shared module timescaledb-tsl-2.9.3.so
[100%] Built target timescaledb-tsl
postgres@timescale:/home/postgres/timescaledb/build/ [pg14.6]
And install it :
postgres@timescale:/home/postgres/timescaledb/build/ [pg14.6] make install
Install the project...
-- Install configuration: "Release"
-- Installing: /u01/app/postgres/product/14/db_6/share/extension/timescaledb.control
-- Installing: /u01/app/postgres/product/14/db_6/share/extension/timescaledb--2.9.3.sql
...
...
...
-- Installing: /u01/app/postgres/product/14/db_6/lib/timescaledb-2.9.3.so
-- Installing: /u01/app/postgres/product/14/db_6/lib/timescaledb.so
-- Installing: /u01/app/postgres/product/14/db_6/lib/timescaledb-tsl-2.9.3.so
postgres@timescale:/home/postgres/timescaledb/build/ [pg14.6]
Once the extension is installed, we need to add it to list of the shared_preload_libraries PostgreSQL parameter :
shared_preload_libraries = 'pg_stat_statements,timescaledb'
The instance must be restarted to take the new value in account.
Some other instance parameters can be automatically adapted using timescaledb-tune (memory, parallelism, WAl, aso) but I’ll not do it for this demo.
Like all PostgreSQL extensions, TimescalDB needs to be added to the database. I usually create the extensions in the template1 database, so that they are automatically available for all the databases that will be created in the future :
postgres=# \c template1
You are now connected to database "template1" as user "postgres".
template1=# create extension if not exists timescaledb;
WARNING:
WELCOME TO
_____ _ _ ____________
|_ _(_) | | | _ \ ___ \
| | _ _ __ ___ ___ ___ ___ __ _| | ___| | | | |_/ /
| | | | _ ` _ \ / _ \/ __|/ __/ _` | |/ _ \ | | | ___ \
| | | | | | | | | __/\__ \ (_| (_| | | __/ |/ /| |_/ /
|_| |_|_| |_| |_|\___||___/\___\__,_|_|\___|___/ \____/
Running version 2.9.3
For more information on TimescaleDB, please visit the following links:
1. Getting started: https://docs.timescale.com/timescaledb/latest/getting-started
2. API reference documentation: https://docs.timescale.com/api/latest
3. How TimescaleDB is designed: https://docs.timescale.com/timescaledb/latest/overview/core-concepts
Note: TimescaleDB collects anonymous reports to better understand and assist our users.
For more information and how to disable, please see our docs https://docs.timescale.com/timescaledb/latest/how-to-guides/configuration/telemetry.
CREATE EXTENSION
template1=#
Once done, let’s create a new database to check the extension availability :
postgres=# create database timescaledb;
CREATE DATABASE
postgres=#
postgres=# \c timescaledb
You are now connected to database "timescaledb" as user "postgres".
timescaledb=#
timescaledb=# \dx
List of installed extensions
Name | Version | Schema | Description
--------------------+---------+------------+------------------------------------------------------------------------
pg_prewarm | 1.2 | extensions | prewarm relation data
pg_stat_statements | 1.9 | extensions | track planning and execution statistics of all SQL statements executed
pg_trgm | 1.6 | extensions | text similarity measurement and index searching based on trigrams
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
timescaledb | 2.9.3 | public | Enables scalable inserts and complex queries for time-series data
(5 rows)
timescaledb=#
All right !
Hypertable creation
The process of creating a hypertable is easy. First of all, let’s create some standard tables :
timescaledb=# CREATE TABLE "locations"(
device_id TEXT,
location TEXT,
environment TEXT
);
CREATE TABLE
timescaledb=#
timescaledb=# CREATE TABLE "conditions"(
time TIMESTAMP WITH TIME ZONE NOT NULL,
device_id TEXT,
temperature NUMERIC,
humidity NUMERIC
);
timescaledb=# CREATE INDEX ON "conditions"(time DESC);
CREATE INDEX
timescaledb=# CREATE INDEX ON "conditions"(device_id, time DESC);
CREATE INDEX
timescaledb=#
timescaledb=# \dt
List of relations
Schema | Name | Type | Owner
--------+------------+-------+----------
public | conditions | table | postgres
public | locations | table | postgres
(2 rows)
Then convert one of the table to hypertable :
timescaledb=# SELECT create_hypertable('conditions', 'time', chunk_time_interval => INTERVAL '24 hours');
The first argument is the name of the table we want to convert. The second argument is the name of the column containing time values as well as the primary column to partition by. The 3rd argument is the event time that each chunk covers. Default is 7 days, here we set it to 1 day.
To populate the tables, I have loaded the sample datasets provided by Timescale :
postgres@timescale:/home/postgres/ [PG01] psql -U postgres -d timescaledb -c "\COPY locations FROM weather_big_locations.csv CSV"
COPY 2000
As the quantity of data loaded into the conditions table is huge and the native COPY function of PostgreSQL is transactional and single-threaded, I used the timescaledb-parallel-copy tool to bulk insert the data :
postgres@timescale:/home/postgres/ [PG01] ./timescaledb-parallel-copy --db-name timescaledb --table conditions --file weather_big_conditions.csv --workers 2 --reporting-period 30s
at 30s, row rate 47817.24/sec (period), row rate 47817.24/sec (overall), 1.435000E+06 total rows
at 1m0s, row rate 34509.19/sec (period), row rate 41165.22/sec (overall), 2.470000E+06 total rows
at 1m30s, row rate 32162.36/sec (period), row rate 38164.07/sec (overall), 3.435000E+06 total rows
...
...
COPY 40000000
postgres@timescale:/home/postgres/ [PG01]
There are several views that can be query to get information about TimescaleDB objects. We can for instance list the chunks using the view timescaledb_information.chunks.
timescaledb=# select hypertable_name, chunk_name, primary_dimension, range_start, range_end, is_compressed from timescaledb_information.chunks;
hypertable_name | chunk_name | primary_dimension | range_start | range_end | is_compressed
-----------------+-------------------+-------------------+------------------------+------------------------+---------------
conditions | _hyper_2_1_chunk | time | 2016-11-15 01:00:00+01 | 2016-11-16 01:00:00+01 | f
conditions | _hyper_2_2_chunk | time | 2016-11-16 01:00:00+01 | 2016-11-17 01:00:00+01 | f
conditions | _hyper_2_3_chunk | time | 2016-11-17 01:00:00+01 | 2016-11-18 01:00:00+01 | f
conditions | _hyper_2_4_chunk | time | 2016-11-18 01:00:00+01 | 2016-11-19 01:00:00+01 | f
conditions | _hyper_2_5_chunk | time | 2016-11-19 01:00:00+01 | 2016-11-20 01:00:00+01 | f
conditions | _hyper_2_6_chunk | time | 2016-11-20 01:00:00+01 | 2016-11-21 01:00:00+01 | f
conditions | _hyper_2_7_chunk | time | 2016-11-21 01:00:00+01 | 2016-11-22 01:00:00+01 | f
conditions | _hyper_2_8_chunk | time | 2016-11-22 01:00:00+01 | 2016-11-23 01:00:00+01 | f
conditions | _hyper_2_9_chunk | time | 2016-11-23 01:00:00+01 | 2016-11-24 01:00:00+01 | f
conditions | _hyper_2_10_chunk | time | 2016-11-24 01:00:00+01 | 2016-11-25 01:00:00+01 | f
conditions | _hyper_2_11_chunk | time | 2016-11-25 01:00:00+01 | 2016-11-26 01:00:00+01 | f
conditions | _hyper_2_12_chunk | time | 2016-11-26 01:00:00+01 | 2016-11-27 01:00:00+01 | f
conditions | _hyper_2_13_chunk | time | 2016-11-27 01:00:00+01 | 2016-11-28 01:00:00+01 | f
conditions | _hyper_2_14_chunk | time | 2016-11-28 01:00:00+01 | 2016-11-29 01:00:00+01 | f
conditions | _hyper_2_15_chunk | time | 2016-11-29 01:00:00+01 | 2016-11-30 01:00:00+01 | f
conditions | _hyper_2_16_chunk | time | 2016-11-30 01:00:00+01 | 2016-12-01 01:00:00+01 | f
conditions | _hyper_2_17_chunk | time | 2016-12-01 01:00:00+01 | 2016-12-02 01:00:00+01 | f
conditions | _hyper_2_18_chunk | time | 2016-12-02 01:00:00+01 | 2016-12-03 01:00:00+01 | f
conditions | _hyper_2_19_chunk | time | 2016-12-03 01:00:00+01 | 2016-12-04 01:00:00+01 | f
conditions | _hyper_2_20_chunk | time | 2016-12-04 01:00:00+01 | 2016-12-05 01:00:00+01 | f
conditions | _hyper_2_21_chunk | time | 2016-12-05 01:00:00+01 | 2016-12-06 01:00:00+01 | f
conditions | _hyper_2_22_chunk | time | 2016-12-06 01:00:00+01 | 2016-12-07 01:00:00+01 | f
conditions | _hyper_2_23_chunk | time | 2016-12-07 01:00:00+01 | 2016-12-08 01:00:00+01 | f
conditions | _hyper_2_24_chunk | time | 2016-12-08 01:00:00+01 | 2016-12-09 01:00:00+01 | f
conditions | _hyper_2_25_chunk | time | 2016-12-09 01:00:00+01 | 2016-12-10 01:00:00+01 | f
conditions | _hyper_2_26_chunk | time | 2016-12-10 01:00:00+01 | 2016-12-11 01:00:00+01 | f
conditions | _hyper_2_27_chunk | time | 2016-12-11 01:00:00+01 | 2016-12-12 01:00:00+01 | f
conditions | _hyper_2_28_chunk | time | 2016-12-12 01:00:00+01 | 2016-12-13 01:00:00+01 | f
conditions | _hyper_2_29_chunk | time | 2016-12-13 01:00:00+01 | 2016-12-14 01:00:00+01 | f
(29 rows)
timescaledb=#
Or the view timescaledb_information.hypertables to get information about the existing hypertables :
timescaledb=# select hypertable_name, num_dimensions, num_chunks, compression_enabled, is_distributed from timescaledb_information.hypertables;
hypertable_name | num_dimensions | num_chunks | compression_enabled | is_distributed
-----------------+----------------+------------+---------------------+----------------
conditions | 1 | 29 | f | f
(1 row)
timescaledb=#
Query the data
After insertion, the data can be read as usual :
timescaledb=# SELECT * FROM conditions ORDER BY time DESC LIMIT 10;
time | device_id | temperature | humidity
------------------------+--------------------+-------------+----------
2016-11-30 07:04:00+01 | weather-pro-001641 | 60.2 | 48
2016-11-30 06:04:00+01 | weather-pro-001803 | 62 | 55.9
2016-11-30 05:50:00+01 | weather-pro-001082 | 63.9 | 48
2016-11-30 05:18:00+01 | weather-pro-001601 | 60 | 55.8
2016-11-30 04:50:00+01 | weather-pro-000372 | 60 | 48.2
2016-11-30 04:22:00+01 | weather-pro-000799 | 55 | 40.8
2016-11-30 03:46:00+01 | weather-pro-001288 | 60 | 48.2
2016-11-30 03:36:00+01 | weather-pro-001969 | 62 | 48.1
2016-11-30 03:34:00+01 | weather-pro-000043 | 62 | 55.9
2016-11-30 03:34:00+01 | weather-pro-000732 | 61.9 | 48
(10 rows)
timescaledb=#
And using functions like avg, min, max, we can have interesting results.
timescaledb=# SELECT date_trunc('hour', time) "hour",
trunc(avg(temperature), 2) avg_temp,
trunc(min(temperature), 2) min_temp,
trunc(max(temperature), 2) max_temp
FROM conditions c
WHERE c.device_id IN (
SELECT device_id FROM locations
WHERE location LIKE 'field-%'
) GROUP BY "hour" ORDER BY "hour" ASC LIMIT 24;
hour | avg_temp | min_temp | max_temp
------------------------+----------+----------+----------
2016-11-15 13:00:00+01 | 73.57 | 68.00 | 79.29
2016-11-15 14:00:00+01 | 74.57 | 68.79 | 80.49
2016-11-15 15:00:00+01 | 75.57 | 69.39 | 81.49
2016-11-15 16:00:00+01 | 76.56 | 70.09 | 82.59
2016-11-15 17:00:00+01 | 77.57 | 71.09 | 83.59
2016-11-15 18:00:00+01 | 78.57 | 71.99 | 84.89
2016-11-15 19:00:00+01 | 79.55 | 72.49 | 86.59
2016-11-15 20:00:00+01 | 80.54 | 73.29 | 87.39
2016-11-15 21:00:00+01 | 81.52 | 74.59 | 88.39
2016-11-15 22:00:00+01 | 82.51 | 75.79 | 89.29
2016-11-15 23:00:00+01 | 83.51 | 76.49 | 90.00
2016-11-16 00:00:00+01 | 84.49 | 77.49 | 90.00
2016-11-16 01:00:00+01 | 85.45 | 77.99 | 90.00
2016-11-16 02:00:00+01 | 85.37 | 77.89 | 90.00
2016-11-16 03:00:00+01 | 84.37 | 76.79 | 89.60
2016-11-16 04:00:00+01 | 83.38 | 75.99 | 88.70
2016-11-16 05:00:00+01 | 82.36 | 75.09 | 87.90
2016-11-16 06:00:00+01 | 81.35 | 73.79 | 86.90
2016-11-16 07:00:00+01 | 80.38 | 72.49 | 86.10
2016-11-16 08:00:00+01 | 79.41 | 71.09 | 85.19
2016-11-16 09:00:00+01 | 78.43 | 69.79 | 84.40
2016-11-16 10:00:00+01 | 77.44 | 68.50 | 83.69
2016-11-16 11:00:00+01 | 77.49 | 68.50 | 83.99
2016-11-16 12:00:00+01 | 78.52 | 69.29 | 84.89
(24 rows)
timescaledb=#
Compression
When compression is enabled, the data stored in the hypertables is compressed chunk by chunk. A compressed chunk stores the data in a hybrid row-columnar format, where multiple records are grouped into a single row. The goal is to store the data into a single row instead of using a lot of rows to store the same data. Less rows means less disk space required. Easy, isn’t ? Let’s see how it work.
To enable compression on the table :
timescaledb=# ALTER TABLE conditions SET (timescaledb.compress, timescaledb.compress_segmentby = 'device_id');
ALTER TABLE
timescaledb=#
As you can see, we have the possibility to define which column to segment by. As I’m not able to write an understandable explanation about this, I will simply reuse the explanation that you can find in the official documentation :
“…The column that a table is segmented by contains only a single entry, while all other columns can have multiple arrayed entries.
Because a single value is associated with each compressed row, there is no need to decompress to evaluate the value in that column. This means that queries with WHERE clauses that filter by a segmentby column are much more efficient, because decompression can happen after filtering instead of before. This avoids the need to decompress filtered-out rows altogether.
Because some queries are more efficient than others, it is important to pick the correct set of segmentby columns. If your table has a primary key all of the primary key columns, except for time, can go into the segmentby list.”
We can now add a compression policy to compress chunks that are older than 7 days.
timescaledb=# SELECT add_compression_policy('conditions', INTERVAL '7 days');
add_compression_policy
------------------------
1000
(1 row)
timescaledb=# \x
Expanded display is on.
timescaledb=# SELECT * FROM timescaledb_information.jobs WHERE proc_name='policy_compression';
-[ RECORD 1 ]-----+-------------------------------------------------
job_id | 1000
application_name | Compression Policy [1000]
schedule_interval | 12:00:00
max_runtime | 00:00:00
max_retries | -1
retry_period | 01:00:00
proc_schema | _timescaledb_internal
proc_name | policy_compression
owner | postgres
scheduled | t
fixed_schedule | f
config | {"hypertable_id": 2, "compress_after": "7 days"}
next_start | 2023-02-15 19:44:40.692243+01
initial_start |
hypertable_schema | public
hypertable_name | conditions
check_schema | _timescaledb_internal
check_name | policy_compression_check
timescaledb=#
It’s very important that you don’t compress all the data because compressed rows can not be updated or deleted. Therefore, take care to compress only data that are old enough and for which you are sure that no update will be required.
Good. We have now enabled the compression on the hypertable, and created an automatic job to perform the compression of chunks which contains data older than 7 days.
Thanks to the view hypertable_compression_stats, we can compare the size of the table before and after the compression :
timescaledb=# SELECT pg_size_pretty(before_compression_total_bytes) as "before compression", pg_size_pretty(after_compression_total_bytes) as "after compression" FROM hypertable_compression_stats('conditions');
before compression | after compression
--------------------+-------------------
6603 MB | 186 MB
(1 row)
timescaledb=#
Quite impressive, isn’t ? This performance is due to the fact that TimescaleDB uses, behind the scene, the best time-series data compression algorithms. Actually, you can not choose the algorithme you want to use when compressing your hypertables as TimescaleDB chooses the most appropriate one according to the type of data :
- Delta-of-delta + Simple-8b with run-length encoding compression
for integers, timestamps, and other integer-like types
- XOR-based compression
for floats
- Whole-row dictionary compression
for columns with a few repeating values (plus LZ compression on top)
- LZ-based array compression
for all other types
If you want to take a deep dive into these various algorithms and know how they are implemented in TimescaleDB, I recommend to read this blog.
Retention
As we have seen, setting up compression is an efficient way to save disk space. But is it really worth to keep very old data, even if they are compressed ? Of course this depends on the requirements of the business, but in a general way it’s always good to configure an automatic purge of old data. TimescaleDB offers this possibility :
timescaledb=# SELECT add_retention_policy('conditions', INTERVAL '6 months');
add_retention_policy
----------------------
1001
(1 row)
timescaledb=#
timescaledb=# \x
Expanded display is on.
timescaledb=# SELECT * FROM timescaledb_information.jobs WHERE job_id=1001;
-[ RECORD 1 ]-----+---------------------------------------------
job_id | 1001
application_name | Retention Policy [1001]
schedule_interval | 1 day
max_runtime | 00:05:00
max_retries | -1
retry_period | 00:05:00
proc_schema | _timescaledb_internal
proc_name | policy_retention
owner | postgres
scheduled | t
fixed_schedule | f
config | {"drop_after": "6 mons", "hypertable_id": 2}
next_start | 2023-02-16 15:07:31.789794+01
initial_start |
hypertable_schema | public
hypertable_name | conditions
check_schema | _timescaledb_internal
check_name | policy_retention_check
timescaledb=#
Old chunks can also be dropped manually :
timescaledb=# SELECT drop_chunks('conditions', INTERVAL '6 months');
Conclusion
This was my first test with TimescaleDB. It seems to be very powerful product when it comes to store and manage time-series data. The compression and the retention features are particularly interesting to save disk space, especially when your data are stored in the cloud. Your monthly bill can be reduced considerably with this :-).
There are still other features that seem to be interesting to test, for example the continuous aggregates or the distributed hypertables. Maybe for another blog…
I hope you enjoyed reading this blog as much as I enjoyed writing it.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/JOC_web-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/11/LTO_WEB.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2023/01/APY_web-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/FRJ_web-min-scaled.jpg)