
Introduction
Nowadays, everyone in IT is well versed in using ChatGPT and other LLM-powered Chat to retrieve information like Google or try to learn something with it.
The problem with those models is their accuracy. Current AI models only know what information they have been fed and expose it to you in a format you understand (which is already surprisingly effective).
But those models don’t discover new things yet and need human validation. The next phase of AI evolution is the implementation of AI workflows through agentic frameworks for large to medium-sized organizations. I am quite excited with what’s coming because where are going to tackle all the issues and limitations AI users are facing. The first one is going to be the reliability of the data source. The second one is going to be knowledge of your environment. Current models are trained on publicly available data, meaning that depending on what the LLM has been trained with, you might have a biased output (granted this could be a goal as well). Think of it like when you were searching for a solution in StackOverflow (which is still a pretty good source of knowledge!), you had to take a step back and try something similar but compose with what you know and adapt to your environment to reach a goal.
Now ChatGPT can search and propose a first solution for you. But can’t do the iterative process of refining the solution or know your environment, this is why prompting is becoming a field of expertise.
With the agentic framework, we will be able to provide the data that makes an organization what it is and provide operational data through Retrieve Augmented Generative (RAG) Search. If you add the fact that you’ll be able to implement business logic into it and an iterative process of refinement, you will have a tool that is going to increase internal productivity at an insane pace.
Some numbers from economic studies showed an increase in the productivity of IT engineers by 30% since ChatGPT was released which had an impact on the employment market and the consulting world by the way. Most observers anticipate an increase in productivity that will be drastically more, but I am not so sure that this will have a bad impact on jobs in the end. More on that in a future blog probably.
So what would an Agent be? We are going to create one in this blog post and it might puts some light on the technicalities behind it, but one way simple way to look at it is that an agent is any process that would make more than one LLM call to perform a specific task. Erik Schultz and his colleagues from Anthropic made this really good blog post on agents and how they categorized them if you want to know more about that. Others would describe AI agents like independent systems that would execute a task on your behalf.
For now, let’s focus on how to build a simple agent with the LAB that we already have set up in part 1.
As a reminder here is the Git repo with the instructions and all the links for the other parts of this series.
Part 1 : pgvector, a guide for DBA – Part1 LAB DEMO
Part 2 : pgvector, a guide for DBA – Part2 Indexes
Part 4 : pgvector, a guide for DBA – Part 4 AI Workflows Best practices ( not released yet )
RAG Search & AI Workflow
Here is the full sequence workflow of embeddings creation of a document and usage of those in the RAG search process.
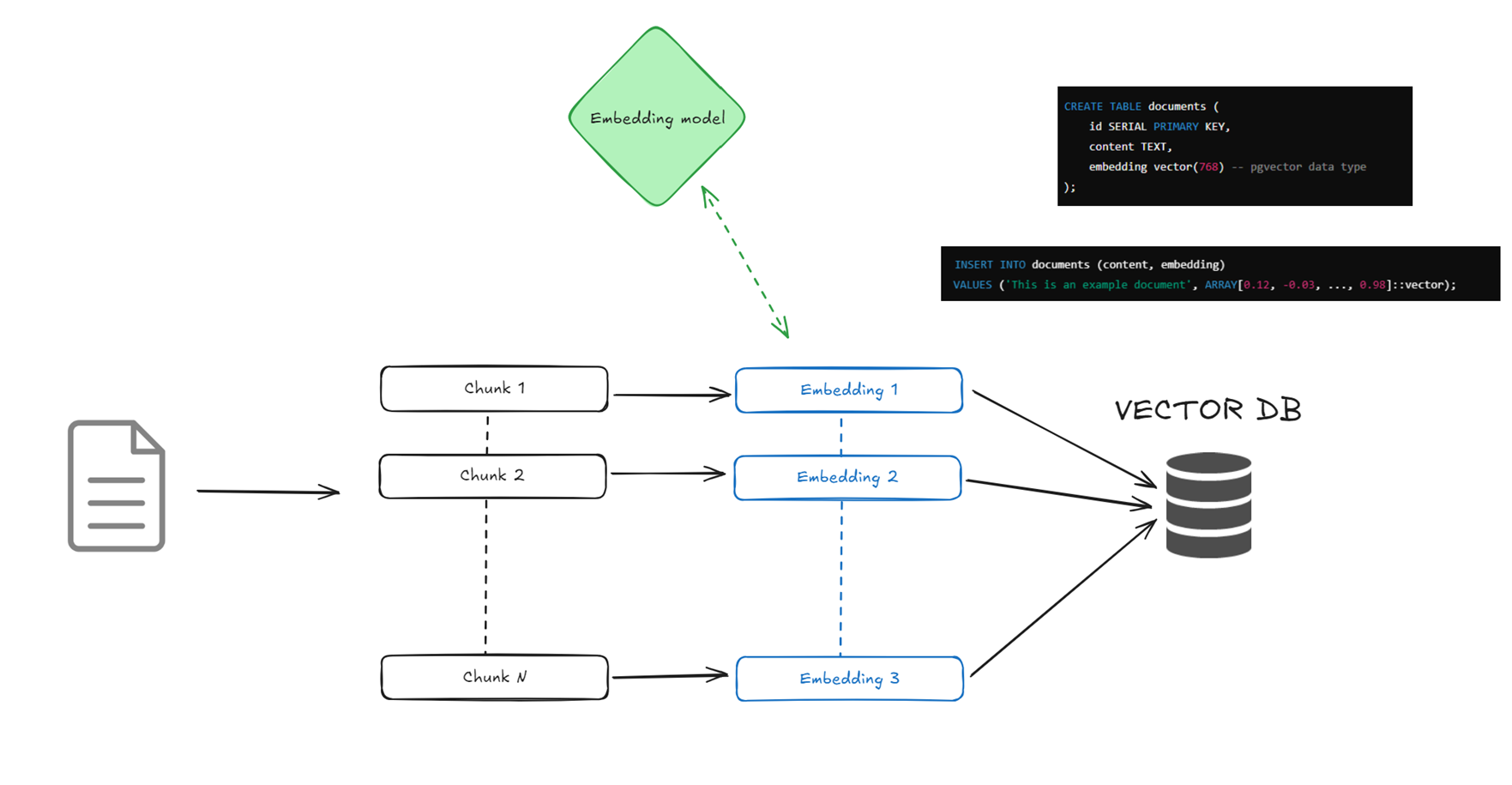
- Document ingestion and chunking :
In this first important step, you take a flat file (PDF, text, …) and split it into smaller chunks of text (200-500 tokens per chunk for example). This is done because embedding a large document can be difficult to embed efficiently. Smaller chunks make it easier to retrieve relevant parts of the text. We will talk in the part 4 why this part is important.
Note: a token is roughly equivalent to a word fragment—so 150 tokens for example might be around 100–150 words depending on the language. - Storing in pgvector :
Once the embedding model has generated the embeddings we are going to store them alongside the chunks and relevant metadata information into a PostgreSQL table.
The pgvector extension will provide the capability to create vector data type to store the embedding so you would typically have a table with columns like id, tags, categories, content, embedding…
As we talk in part 2, indexing this table with the relevant indexes is a key aspect to be able to allow the PostgreSQL optimizer to retrieve data in the most efficient way.
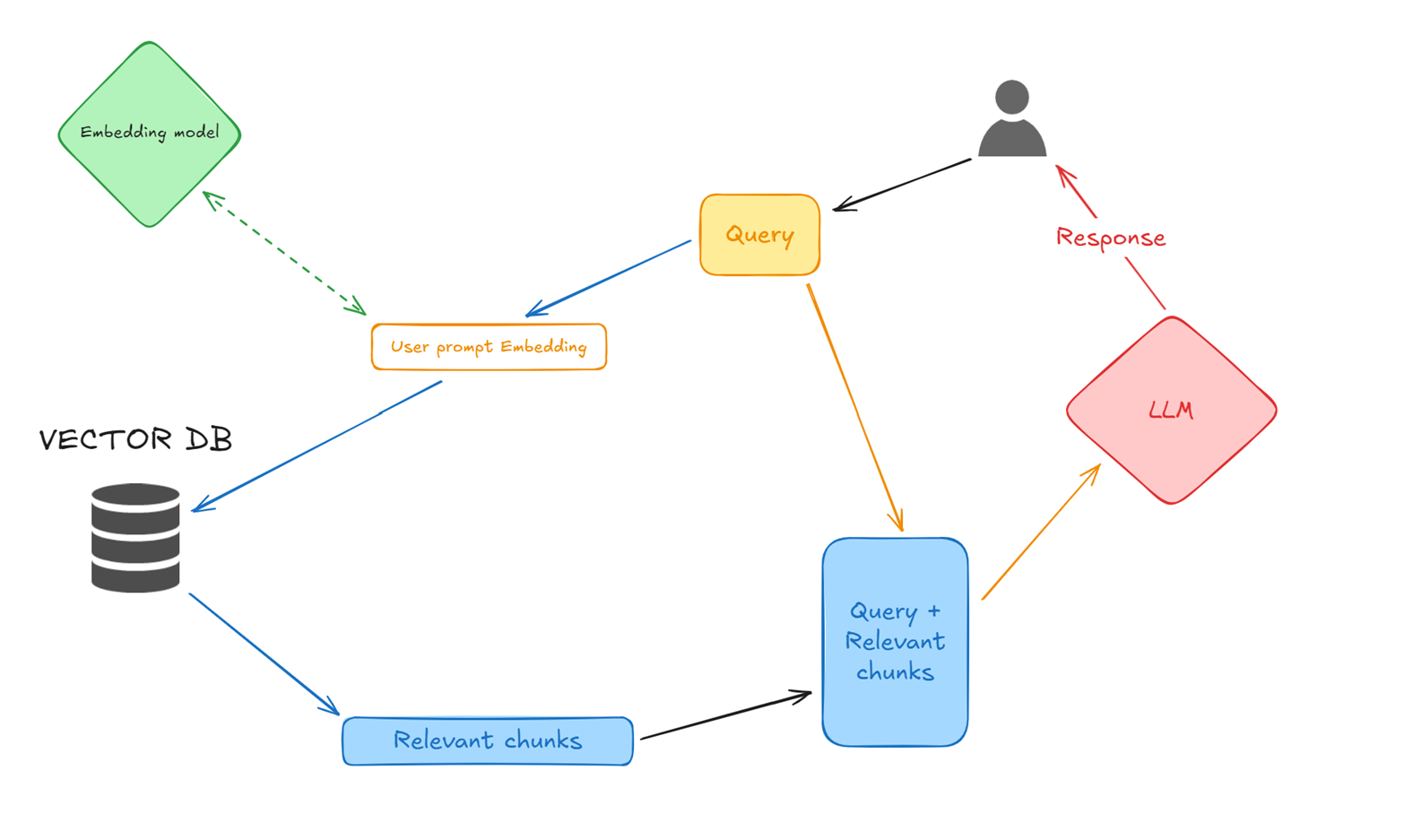
- User Query and Prompt Embedding :
A user submits a query/prompt in natural language, this is then converted into an embedding using the same embedding model and parameters used for the document embedding generation. - Vector similarity search in pgvector :
We are using then the user prompt embedding to perform a search against the table a retrieve the top X relevant chunks that are most similar. In this step, we can take advantage of the metadata
information to narrow the search space. It is also possible to add additional logic to this step depending on your requirements. - Constructing the LLM input (query + relevant chunks of data):
Here we are combining the user’s query and adding the relevant chunks as references to feed to the LLM. - LLM response generation :
The LLM generates a response that is more informed and references its knowledge with grounded specific data provided by the process.
This makes the answer more precise and reduces drastically hallucinations.
Example of AI Agent
So if you are a developer and want to build your own I would suggest looking into frameworks like LangChain (langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications) to help you build one or the recent OpenAI APIs (API Reference – OpenAI API;Web search – OpenAI API,File search – OpenAI API; Agents – OpenAI API).
Since an AI agent creation in your organization would be a very specific thing (it would be mostly related to the organization’s way of work), I will explain here how to create a simple AI agent that will help you understand and reflect the upper diagrams concepts.
In the Git repository, you will find a RAG_search.py file. Simply put this script is connecting to OpenAI 4o model API and looks for relevant data in the Netflix_shows table of our pgvector database.
Here is the code :
import os
import psycopg2
import openai
import json
# Set your environment variables: DATABASE_URL and OPENAI_API_KEY
# e.g., export DATABASE_URL="postgresql://postgres@localhost/dvdrental"
# e.g., export OPENAI_API_KEY="sk-123...."
DATABASE_URL = os.getenv("DATABASE_URL") # e.g., "postgresql://postgres@localhost/dvdrental"
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
openai.api_key = OPENAI_API_KEY
def get_embedding(text, model="text-embedding-ada-002"):
"""
Generate an embedding for the given text using the latest OpenAI API.
Access attributes using dot notation.
"""
response = openai.embeddings.create(
input=text,
model=model
)
embedding = response.data[0].embedding # dot notation for attribute access
return embedding
def query_similar_items(query_embedding, limit=5):
"""
Connect to PostgreSQL and perform a similarity search using pgvector.
Convert the embedding (a list of floats) into a JSON string.
"""
vec_str = json.dumps(query_embedding)
conn = psycopg2.connect(DATABASE_URL)
cur = conn.cursor()
sql = """
SELECT title, description, embedding <-> %s::vector AS distance
FROM netflix_shows
WHERE embedding IS NOT NULL
ORDER BY embedding <-> %s::vector
LIMIT %s;
"""
cur.execute(sql, (vec_str, vec_str, limit))
results = cur.fetchall()
cur.close()
conn.close()
return results
def generate_answer(query, context):
"""
Generate an answer using the OpenAI ChatCompletion API with model GPT-4o.
This uses the new openai.chat.completions.create interface.
"""
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": f"Context:\n{context}\n\nQuestion: {query}"}
]
response = openai.chat.completions.create(
model="gpt-4o", # Ensure you have access to GPT-4o, depending on your API plan and permissions - other models can be used as well
messages=messages,
max_tokens=150,
temperature=0.2,
)
return response.choices[0].message.content.strip()
def main():
query = input("Enter your question: ")
# Generate an embedding for the query
query_embedding = get_embedding(query)
# Retrieve top similar documents using pgvector similarity search
similar_items = query_similar_items(query_embedding)
if not similar_items:
print("No relevant documents were found.")
return
# Build a context string by concatenating retrieved titles and descriptions.
context = ""
for title, description, distance in similar_items:
context += f"Title: {title}\nDescription: {description}\n\n"
# Generate the final answer using the query and the retrieved context.
answer = generate_answer(query, context)
print("\nAnswer:", answer)
if __name__ == "__main__":
main()
In the “def generate_answer()” the max_tokens parameter controls the maximum number of tokens that the model can generate in its response. In this context, setting max_tokens=150 means that after processing your prompt (which includes the context and the question), the model’s answer will be capped at 150 tokens. This is useful for keeping responses concise and managing costs, as longer responses typically consume more compute resources and cost more.
The temperature parameter controls the randomness or creativity of the model’s output. A lower temperature (e.g., 0.2) makes the model’s responses more deterministic and focused—choosing high-probability tokens with less variation. This is ideal when you need factual, context-bound responses (such as in a RAG system that should strictly use local context). In contrast, a higher temperature would lead to more diverse and creative outputs, which might be useful in more open-ended scenarios but can also increase the risk of generating off-topic outputs.
When executing this agent here is an example of the output you might have :
(pgvector_lab) 17:40:49 postgres@PG1:/home/postgres/LAB_vector/ [PG17] python3 RAG_search.py
Enter your question: What movies would you suggest that are like starwars ?
Answer: If you're looking for movies similar to "Star Wars," you might enjoy the following films that share themes of space adventure, epic battles, and intriguing characters:
1. **Guardians of the Galaxy (2014)** - This film features a group of intergalactic misfits who band together to save the universe, offering a mix of humor, action, and a memorable ensemble cast.
2. **Star Trek (2009)** - A reboot of the classic series, this film follows the young crew of the USS Enterprise as they embark on their first mission, blending action, adventure, and a touch of nostalgia.
3. **The Fifth Element (1997)** - A visually stunning sci-fi adventure set in a futuristic world, where a cab driver
(pgvector_lab) 17:41:37 postgres@PG1:/home/postgres/LAB_vector/ [PG17]Ok, we have an output that makes sense, but when I look into the netflix_shows table I can’t find those movies, meaning that the LLM model decided to provide information from its database.
(pgvector_lab) 17:41:37 postgres@PG1:/home/postgres/LAB_vector/ [PG17] sqh
psql (17.2 dbi services build)
Type "help" for help.
postgres=# \c dvdrental
You are now connected to database "dvdrental" as user "postgres".
dvdrental=# select * from netflix_shows limit 1;
show_id | type | title | director | cast | country | date_added | release_year | rating | duration | liste>
---------+---------+----------+----------+-------------------------------------------------------------------------------------------------------------+----------------+-------------------+--------------+--------+-----------+------------------------->
s3083 | TV Show | Occupied | | Henrik Mestad, Ane Dahl Torp, Ingeborga Dapkunaite, Eldar Skar, Ragnhild Gudbrandsen, Kristin Braut-Solheim | Norway, Sweden | December 31, 2019 | 2019 | TV-MA | 3 Seasons | International TV Shows, >
(1 row)
dvdrental=# select * from netflix_shows where title like 'Guardians of the Galaxy (2014)';
show_id | type | title | director | cast | country | date_added | release_year | rating | duration | listed_in | description | embedding
---------+------+-------+----------+------+---------+------------+--------------+--------+----------+-----------+-------------+-----------
(0 rows)
dvdrental=# select * from netflix_shows where title like '%Guardians%';
show_id | type | title | director | cast >
---------+-------+-------------------------------------------------------------------------------+-----------------+-------------------------------------------------------------------------------------------------------------------------------------->
s7052 | Movie | Ice Guardians | Brett Harvey | Dave Brown, Brett Hull, Rob Ray, Jarome Iginla, Wendel Clark, Scott Parker, Dave schultz, Jay Baruchel >
s2774 | Movie | Willy and the Guardians of the Lake: Tales from the Lakeside Winter Adventure | Zsolt Pálfi | Csongor Szalay, Anna Kubik, Sári Vida, András Faragó, Róbert Bolla >
s4141 | Movie | LEGO Marvel Super Heroes: Guardians of the Galaxy | | >
s63 | Movie | Naruto the Movie 3: Guardians of the Crescent Moon Kingdom | Toshiyuki Tsuru | Junko Takeuchi, Chie Nakamura, Yoichi Masukawa, Kazuhiko Inoue, Akio Otsuka, Kyousuke Ikeda, Marika Hayashi, Umeji Sasaki, Masashi Su>
s3992 | Movie | The Super Parental Guardians | Joyce Bernal | Vice Ganda, Coco Martin, Onyok Pineda, Awra Briguela, Assunta de Rossi, Pepe Herrera, Joem Bascon, Matet De Leon, Kiray Celis, Lassy >
s7283 | Movie | Legend of the Guardians: The Owls of Ga'Hoole | Zack Snyder | Helen Mirren, Geoffrey Rush, Jim Sturgess, Hugo Weaving, Emily Barclay, Abbie Cornish, Ryan Kwanten, Anthony LaPaglia, Miriam Margoly>
(6 rows)
dvdrental=# select * from netflix_shows where title like '%Star Trek%';
show_id | type | title | director | cast | country >
---------+---------+--------------------------------+-------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------->
s5651 | TV Show | Star Trek: Deep Space Nine | | Avery Brooks, Nana Visitor, Rene Auberjonois, Cirroc Lofton, Alexander Siddig, Colm Meaney, Armin Shimerman, Terry Farrell, Michael Dorn | United States >
s595 | Movie | Star Trek | J.J. Abrams | Chris Pine, Zachary Quinto, Karl Urban, Zoe Saldana, Simon Pegg, John Cho, Anton Yelchin, Eric Bana, Leonard Nimoy, Bruce Greenwood, Ben Cross, Winona Ryder | United States, Ger>
s4947 | TV Show | Star Trek: The Next Generation | | Patrick Stewart, Jonathan Frakes, LeVar Burton, Michael Dorn, Marina Sirtis, Brent Spiner, Gates McFadden, Majel Barrett, Wil Wheaton | United States >
s5245 | TV Show | Star Trek: Enterprise | | Scott Bakula, John Billingsley, Jolene Blalock, Dominic Keating, Anthony Montgomery, Linda Park, Connor Trinneer | United States >
s5246 | TV Show | Star Trek: Voyager | | Kate Mulgrew, Robert Beltran, Roxann Dawson, Jennifer Lien, Robert Duncan McNeill, Ethan Phillips, Robert Picardo, Tim Russ, Jeri Ryan, Garrett Wang, Tarik Ergin | United States >
(5 rows)
dvdrental=# select * from netflix_shows where title like '%Element%';
show_id | type | title | director | cast | country | date_added | release_year | rating | duration | liste>
---------+-------+-------------------------+---------------+------------------------------------------------------------------------------------------------+---------------+--------------------+--------------+--------+----------+--------------------->
s6766 | Movie | Five Elements Ninjas | Cheh Chang | Tien-chi Cheng, Tien Hsiang Lung, Meng Lo, Michael Chan Wai-Man, Pei Hsi Chen, Li Wang, Ke Chu | Hong Kong | September 17, 2019 | 1982 | R | 104 min | Action & Adventure, >
s2398 | Movie | Jo Koy: In His Elements | Michael McKay | Jo Koy, Andrew Lopez, Joey Guila, Andrew Orolfo | United States | June 12, 2020 | 2020 | TV-MA | 55 min | Stand-Up Comedy >
(2 rows)
dvdrental=#But what if I wanted to only take into account information from my local database? Well, for that I could simply perform some prompt engineering and be more specific about where I want the information to come from. Here are changes to the Python code in that sense :
def generate_answer(query, context):
"""
Generate an answer using the OpenAI ChatCompletion API with model GPT-4o.
This uses the new openai.chat.completions.create interface.
"""
messages = [
{"role": "system", "content": "You are a helpful assistant. You must answer the following question using only the context provided from the local database. "
"Do not include any external information. If the answer is not present in the context, respond with 'No relevant information is available.'"},
{"role": "user", "content": f"Context:\n{context}\n\nQuestion: {query}"}
]
response = openai.chat.completions.create(
model="gpt-4o", # Ensure you have access to GPT-4o
messages=messages,
max_tokens=150,
temperature=0.2,
)
return response.choices[0].message.content.strip()
New Results :
(pgvector_lab) 17:55:01 postgres@PG1:/home/postgres/LAB_vector/ [PG17] python3 RAG_search.py
Enter your question: What movies would you suggest that are like starwars ?
Answer: Based on the context provided, movies that might be similar to Star Wars include:
1. Solo: A Star Wars Story
2. Elstree 1976
3. Jiu Jitsu
4. Forbidden Planet
These films involve themes of space, adventure, and battles, which are elements present in Star Wars.
(pgvector_lab) 17:55:18 postgres@PG1:/home/postgres/LAB_vector/ [PG17] sqh
psql (17.2 dbi services build)
Type "help" for help.
postgres=# \c dvdrental
You are now connected to database "dvdrental" as user "postgres".
dvdrental=# select * from netflix_shows where title like '%Solo%';
show_id | type | title | director | cast >
---------+-------+-------------------------------------------+---------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------->
s3212 | Movie | Kalushi: The Story of Solomon Mahlangu | Mandla Dube | Thabo Rametsi, Thabo Malema, Welile Nzuza, Jafta Mamabolo, Louw Venter, Pearl Thusi >
s8052 | Movie | Solo: A Star Wars Story | Ron Howard | Alden Ehrenreich, Woody Harrelson, Emilia Clarke, Donald Glover, Joonas Suotamo, Thandie Newton, Phoebe Waller-Bridge, Paul Bettany >
s8053 | Movie | Solo: A Star Wars Story (Spanish Version) | Ron Howard | Alden Ehrenreich, Woody Harrelson, Emilia Clarke, Donald Glover, Joonas Suotamo, Thandie Newton, Phoebe Waller-Bridge, Paul Bettany >
s8054 | Movie | Solomon Kane | Michael J. Bassett | James Purefoy, Pete Postlethwaite, Rachel Hurd-Wood, Alice Krige, Jason Flemyng, Mackenzie Crook, Patrick Hurd-Wood, Max von Sydow >
s4205 | Movie | Solo | Hugo Stuven | Alain Hernández, Aura Garrido, Ben Temple >
s8051 | Movie | Solo Con Tu Pareja | Alfonso Cuarón | Luis de Icaza, Dobrina Liubomirova, Isabel Benet, Claudia Fernandez, Luz María Jerez, Claudia Ramírez, Astrid Hadad, Toshiro Hisaki, Daniel Giménez Cacho>
s5280 | Movie | Fabrizio Copano: Solo pienso en mi | Rodrigo Toro, Francisco Schultz | Fabrizio Copano >
(7 rows)
dvdrental=# select * from netflix_shows where title like '%Elstree%';
show_id | type | title | director | cast | country | date_added | release_year | rating | d>
---------+-------+--------------+-----------+---------------------------------------------------------------------------------------------------------------------------------------------+----------------+-------------------+--------------+--------+-->
s6687 | Movie | Elstree 1976 | Jon Spira | Paul Blake, Jeremy Bulloch, John Chapman, Anthony Forrest, Laurie Goode, Garrick Hagon, Derek Lyons, Angus MacInnes, David Prowse, Pam Rose | United Kingdom | September 6, 2016 | 2015 | TV-PG | 1>
(1 row)
dvdrental=# select * from netflix_shows where title like '%Jiu%';
show_id | type | title | director | cast | country | date_added | release_>
---------+-------+-----------+--------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------+----------------+--------->
s1179 | Movie | Jiu Jitsu | Dimitri Logothetis | Alain Moussi, Nicolas Cage, Tony Jaa, Rick Yune, Frank Grillo, Marie Avgeropoulos, JuJu Chan, Ryan Tarran, Eddie Steeples, Raymond Pinharry, Mary Makariou | United States | March 20, 2021 | >
(1 row)
dvdrental=# select * from netflix_shows where title like '%Forbidden Planet%';
show_id | type | title | director | cast | country | date_added | release_year | rating | duration | l>
---------+-------+------------------+----------------+------------------------------------------------------------------------------------------------------+---------------+------------------+--------------+--------+----------+----------------------->
s6785 | Movie | Forbidden Planet | Fred M. Wilcox | Leslie Nielsen, Walter Pidgeon, Anne Francis, Jack Kelly, Warren Stevens, James Drury, Earl Holliman | United States | November 1, 2019 | 1956 | G | 98 min | Action & Adventure, Cl>
(1 row)
(pgvector_lab) 18:34:45 postgres@PG1:/home/postgres/LAB_vector/ [PG17] python3 RAG_search.py
Enter your question: Can you propose a movie that would talk about MTB ?
Answer: Based on the context provided, the movie "Deathgrip" would talk about MTB (mountain biking).
(pgvector_lab) 18:35:15 postgres@PG1:/home/postgres/LAB_vector/ [PG17] sqh
psql (17.2 dbi services build)
Type "help" for help.
postgres=# \c dvdrental
You are now connected to database "dvdrental" as user "postgres".
dvdrental=# select * from netflix_shows where title like '%Deathgrip%';
show_id | type | title | director | cast | country | date_added | release_year | rating | duration | >
---------+-------+-----------+-------------+-------------------------------------------------------------------------------------------------------------------------------------+----------------+---------------+--------------+--------+----------+---->
s6586 | Movie | Deathgrip | Clay Porter | Brendan Fairclough, Olly Wilkins, Kyle Jameson, Andrew Neethling, Nico Vink, Ryan Howard, Sam Hill, Josh Bryceland, Brandon Semenuk | United Kingdom | March 1, 2018 | 2017 | TV-MA | 53 min | Int>
(1 row)
dvdrental=#Ok so that’s really cool and there are a lot of subjects still to talk about like data privacy and optimizations… But, the clear advantage of having a well-designed agent used
in the context of any organization, is that it could iterate on a solution up until finds a level of precision that is “good enough” for business requirements. Here we kind of prove this capability to be reachable. OpenAI benchmarks show levels of precision that are very high for LLMs that are light.
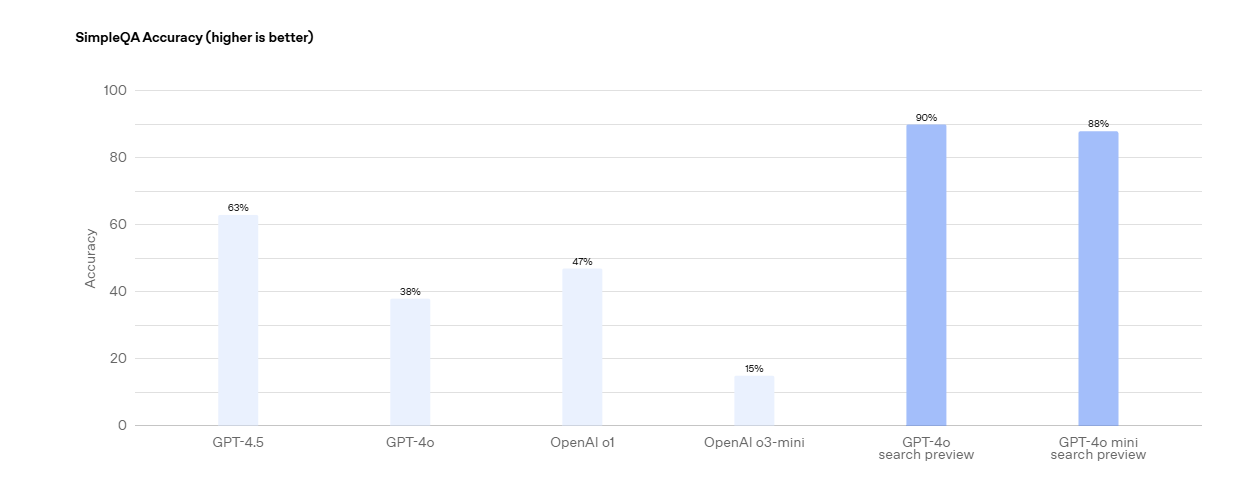
source: New tools for building agents | OpenAI
In this LAB setup, I am connecting an on-premise database with a “cloud” LLM, even if this setup is more and more common there is a critical aspect of data privacy. If I wanted to connect my ERP to a RAG Search solution like this how could I prevent leaks of sensitive business data?
There are several solutions for that.
The first one is to limit or filter simply the data sent to the API or even anonymize it.
The second one could be Enterprise plans like the one from OpenAI that allows you to have more API options, like Zero Data Retention that prevent your data from being stored and used for training.
The third one, which also makes more and more sense (since more solutions are open-source nowadays) is the full on-premise setup, this obviously implies compute capacity.
RAG with Differential Privacy (RAG-DP-paper ) is another way that we could implement data safeguards to limit exposure.
In all setups possible to guarantee data privacy you should probably implement tight access control towards your vector database so that only authorized queries include sensitive information. Additionally auditing your API calls for any unexpected behavior is also recommended.
We will talk more about all the recommended actions you can take to comply with best practices in part 4 of this series. That’s it for now!
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2025/03/OBA_web-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/FRJ_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2023/01/APY_web-scaled.jpg)