Introduction
The first release of pgvector occurred in April 2021. Since then a lot has changed and is still changing. Even though we could say that the level of maturity of AI stacks and usage is currently really amazing, things are still changing fast and will probably continue to do so for a while. This is quite exciting because as a DBA consultant, I am no longer getting questions about theory on vectors, but more about how we can leverage this PostgreSQL extension and deploy it in production data hubs or enterprise applications.
We have reached a level of simplicity of use and maturity of the AI/ML tools that implementing it is no longer reserved for huge organizations. Anyone can build its own stack or use a cloud provider at a fairly decent price. Since I am going to give some talks on that subject throughout the year, I thought it was useful to make a small series of blog posts and share some knowledge on how a “traditional” PostgreSQL user can extend his SQL knowledge and solve problems that would have been out of reach otherwise.
In this first part, I will talk about the basics, how it works and how you can play with it in a simple LAB DEMO. In the next parts we will dig a bit deeper into performance tuning, scalability, index tuning and internals of vector workflows in our beloved open source RDBMS.
As a reminder here is the Git repo with the instructions and all the links for the other parts of this series.
Part 2 : pgvector, a guide for DBA – Part2 Indexes
Part 3 : pgvector, a guide for DBA – Part3 AI Agent and workflows
Part 4 : pgvector, a guide for DBA – Part 4 AI Workflows Best practices ( not released yet )
Why ?
Before jumping into the LAB DEMO, let’s talk about why you would use pgvector. If you’re not familiar with this, we could say simply that pgvector is an extension of PostgreSQL that adds a vector data type, with facilities (indexes, operators, …) to store embeddings alongside standard known relational data.
Embeddings are mathematical representations of other objects (like text, images, videos,… etc) into multi-dimensional vectors. The more dimensions your vector has, the more you will be able to encapsulate “meanings” into it. This comes with a cost of complexity of the mathematical operations hence, more compute and token consumption. Embeddings are still kinda magic to me, the simplicity and the elegance of putting words meaning into numbers blows my mind. If you don’t know how it works then it’s magic 🙂

Here are a few use cases of vectors: similarity search, semantic text search, hybrid search, recommendation system, geospatial + vector search, RAG search, …
I would suggest looking at the PostgreSQLconf.eu Youtube Channel and particularly this talk from Varun Dhawan which I had the chance to see live in Athens last October.
LAB DEMO
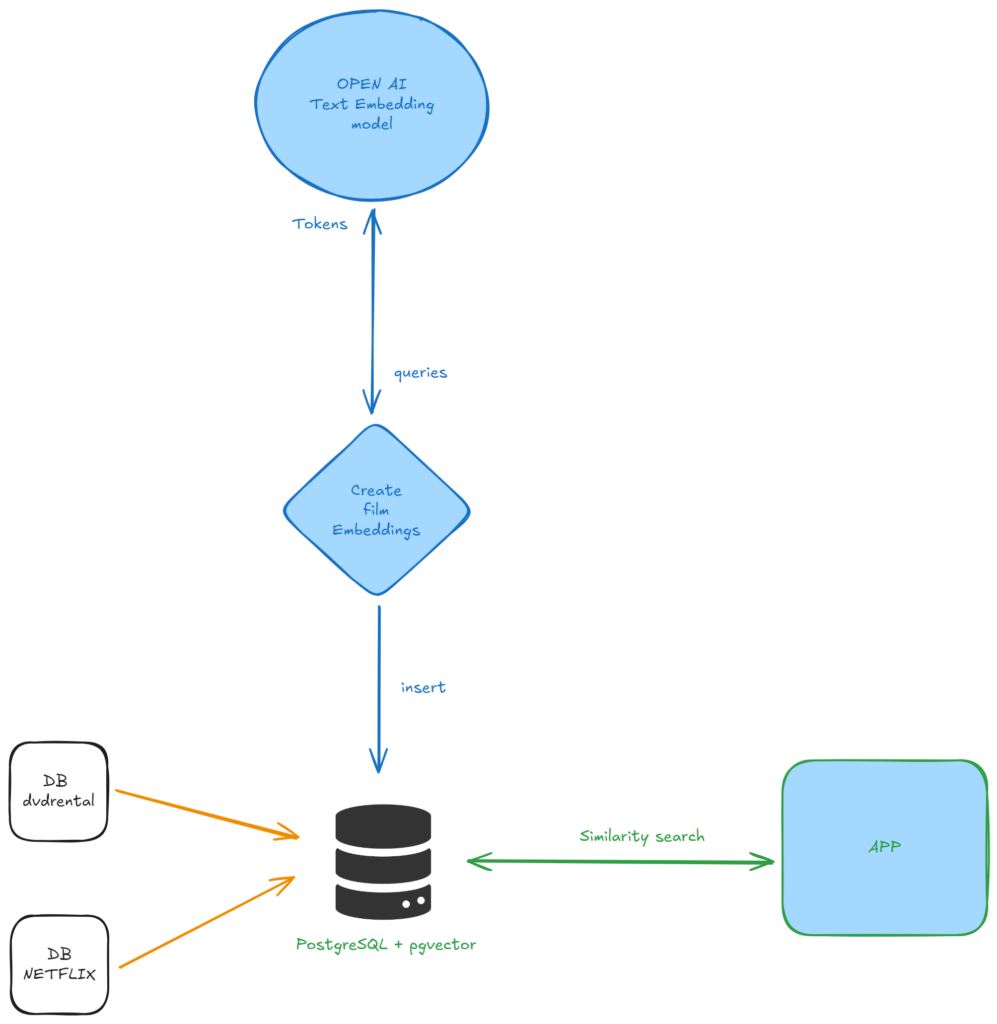
Architecture
We have initially 2 sample databases, dvdrental and netflix_shows. The idea is to merge both databases into one the be able to query tables from both. This can be associated to our standard DWH process.
Then we are going to create new fields on the film and the netflix_shows tables to host our embeddings (this is possible because of the pgvector extension).
Embeddings are mathematical representations of the movies descriptions in our case.
We are going to use a Python script to connect to OpenAI embedding generation model to inserts those in our tables. Then with another script, we will query those embedding and look for similarities.
The aim here is to propose to DVDRental’s users, Netflix shows they might like based on their rental activity. Similar processes can be found on numerous modern applications in order to propose something that would fit your taste or mood. This practical case can help you see the underlying complexity or in this case the simplicity of extending PostgreSQL.
Installation steps
Here are the steps to build your environment :
- Provision a Linux server that will host your PostgreSQL instance.
- Install PostgreSQL 17.2 and pgvector 0.8.0 extension with it.
- Import both dvdrental and netflix_shows databases into one database (this makes it easier to query both sources at the same time).
- Add the vector fields in the target tables.
- On your user environment create the two python scripts to create the embeddings and to run the query search for similarity.
- Setup your Python virtual environment.
- Get an API key for your AI model, in my case OpenAI, may even host locally your own LLM.
- Run the script that creates the embeddings.
- Run the script that queries your vectors and look for similarities.
Installing pgvector
Link to the source and official documentation : pgvector/pgvector: Open-source vector similarity search for Postgres.
Clone the Repository:
Clone the pgvector extension from GitHub:
cd /tmp
git clone https://github.com/pgvector/pgvector.git
cd pgvectorBuild and Install:
Use make to compile the extension and then install it:
make
sudo make installVerify Installation:
In psql, connect to the dvdrental database and run:
CREATE EXTENSION IF NOT EXISTS vector;
SELECT * FROM pg_extension WHERE extname = 'vector';
Import data and prepare the database.
Download the Data:
Visit Kaggle’s Netflix Shows dataset and download the CSV file (e.g., netflix_titles.csv).
Visit Neon’s PostgreSQL Sample Database and download the SQL dump file.
Create the Database and make it ready to receive the embeddings :
--psql
CREATE DATABASE dvdrental;
--bash
unzip dvdrental.zip
pg_restore -U postgres -d dvdrental dvdrental.tar
--psql
\c dvdrental
CREATE TABLE netflix_shows (
show_id TEXT PRIMARY KEY,
type VARCHAR(20),
title TEXT,
director TEXT,
"cast" TEXT,
country TEXT,
date_added TEXT, -- stored as text; later you can convert to DATE with TO_DATE if desired
release_year INTEGER,
rating VARCHAR(10),
duration VARCHAR(20),
listed_in TEXT,
description TEXT
);
--import from the csv file
COPY netflix_shows(show_id, type, title, director, "cast", country, date_added, release_year, rating, duration, listed_in, description)
FROM '/home/postgres/LAB_vector/netflix_titles.csv'
WITH (
FORMAT csv,
HEADER true,
DELIMITER ',',
NULL ''
);
ALTER TABLE film ADD COLUMN embedding vector(1536);
ALTER TABLE netflix_shows ADD COLUMN embedding vector(1536);
CREATE INDEX IF NOT EXISTS film_embedding_idx ON film USING hnsw (embedding vector_l2_ops);
CREATE INDEX IF NOT EXISTS netflix_shows_embedding_idx ON netflix_shows USING hnsw (embedding vector_l2_ops);
Creating the embeddings and getting the first recommendations.
The execution of the create_emb.py script took around 10 minutes on the default batch size of 30 and OpenAI API dashboard showed an input of around 280 000 tokens (on my test plan this equates to $0.03).
14:18:02 postgres@PG1:/home/postgres/LAB_vector/ [PG17] source pgvector_lab/bin/activate
(pgvector_lab) 14:33:36 postgres@PG1:/home/postgres/LAB_vector/ [PG17] export DATABASE_URL="postgresql://postgres@localhost/dvdrental"
(pgvector_lab) 14:33:46 postgres@PG1:/home/postgres/LAB_vector/ [PG17] export OPENAI_API_KEY="sk-proj-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
(pgvector_lab) 14:34:34 postgres@PG1:/home/postgres/LAB_vector/ [PG17] python create_emb.py
Updating film embeddings...
Processing 1000 rows from film in 34 batches (batch size = 30)...
Updated batch for film: [11, 382, 400, 418, 426, 436, 448, 463, 621, 622, 474, 626, 641, 493, 511, 528, 530, 546, 12, 25, 33, 26, 566, 568, 585, 597, 604, 664, 678, 697]
Updated batch for film: [745, 752, 771, 787, 806, 213, 824, 842, 859, 876, 54, 932, 949, 950, 951, 969, 976, 116, 143, 170, 198, 293, 15, 133, 58, 60, 61, 63, 66, 52]
Updated batch for film: [404, 500, 654, 914, 717, 808, 5, 234, 353, 4, 456, 484, 659, 679, 896, 8, 87, 89, 90, 91, 93, 94, 95, 96, 1, 2, 3, 131, 132, 134]
Updated batch for film: [135, 6, 7, 9, 10, 164, 13, 179, 14, 98, 28, 218, 232, 233, 217, 294, 295, 296, 297, 298, 299, 307, 308, 291, 29, 31, 267, 268, 269, 270]
Updated batch for film: [271, 255, 253, 32, 16, 27, 292, 300, 301, 302, 303, 304, 305, 306, 17, 19, 331, 332, 333, 20, 347, 346, 374, 375, 376, 377, 379, 380, 381, 365]
Updated batch for film: [385, 386, 387, 388, 389, 390, 21, 685, 22, 397, 398, 399, 383, 23, 24, 39, 450, 431, 432, 433, 434, 435, 419, 40, 41, 42, 466, 467, 468, 469]
Updated batch for film: [470, 471, 472, 265, 43, 45, 496, 499, 501, 502, 503, 47, 50, 34, 563, 564, 565, 547, 38, 36, 596, 598, 599, 600, 601, 602, 603, 586, 44, 616]
Updated batch for film: [46, 631, 632, 633, 634, 635, 636, 639, 48, 49, 37, 665, 666, 667, 55, 683, 680, 726, 727, 728, 729, 736, 737, 738, 739, 740, 741, 742, 743, 744]
Updated batch for film: [746, 56, 57, 59, 730, 731, 732, 733, 62, 464, 64, 765, 766, 767, 768, 769, 770, 754, 65, 67, 797, 798, 799, 800, 801, 802, 803, 126, 53, 71]
Updated batch for film: [830, 831, 832, 833, 73, 74, 77, 78, 894, 895, 877, 79, 80, 926, 927, 928, 929, 930, 931, 915, 81, 82, 83, 960, 961, 962, 963, 964, 965, 966]
Updated batch for film: [84, 85, 72, 70, 75, 997, 998, 999, 1000, 76, 69, 99, 101, 102, 103, 104, 92, 100, 97, 88, 107, 108, 109, 110, 111, 112, 113, 114, 115, 117]
Updated batch for film: [118, 119, 120, 121, 122, 106, 127, 128, 129, 130, 154, 136, 137, 138, 139, 140, 141, 125, 124, 144, 145, 147, 148, 149, 150, 151, 152, 153, 155, 157]
Updated batch for film: [158, 159, 160, 146, 156, 163, 184, 165, 166, 167, 168, 169, 171, 172, 173, 174, 175, 176, 177, 162, 180, 181, 182, 183, 185, 186, 187, 188, 189, 191]
Updated batch for film: [192, 193, 194, 195, 196, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 214, 215, 219, 220, 221, 222, 223, 224, 225, 226, 227]
Updated batch for film: [228, 229, 230, 236, 237, 238, 239, 240, 241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 235, 256, 257, 258, 259, 260, 261, 262, 263, 264, 266]
Updated batch for film: [275, 276, 277, 278, 279, 280, 309, 327, 345, 364, 378, 281, 282, 702, 716, 734, 283, 284, 285, 878, 384, 286, 287, 288, 274, 273, 311, 312, 313, 314]
Updated batch for film: [315, 316, 317, 318, 319, 320, 321, 322, 323, 324, 325, 326, 310, 329, 328, 330, 334, 335, 336, 337, 338, 339, 340, 341, 342, 343, 344, 348, 349, 350]
Updated batch for film: [351, 352, 554, 354, 355, 356, 357, 358, 359, 360, 361, 362, 363, 366, 367, 368, 369, 370, 371, 372, 373, 391, 392, 393, 394, 449, 395, 396, 402, 403]
Updated batch for film: [405, 406, 407, 408, 409, 410, 411, 412, 413, 414, 415, 416, 417, 401, 420, 421, 422, 423, 424, 425, 427, 428, 429, 430, 438, 439, 440, 441, 442, 443]
Updated batch for film: [444, 445, 446, 447, 451, 452, 453, 454, 455, 437, 458, 459, 460, 461, 462, 465, 473, 457, 476, 477, 478, 479, 480, 481, 482, 483, 485, 486, 487, 488]
Updated batch for film: [489, 490, 491, 492, 475, 495, 497, 498, 504, 505, 753, 506, 507, 508, 509, 510, 494, 513, 514, 515, 516, 517, 518, 519, 520, 521, 522, 523, 560, 524]
Updated batch for film: [525, 526, 527, 512, 531, 532, 533, 534, 535, 536, 537, 538, 539, 540, 541, 561, 542, 543, 544, 545, 529, 548, 549, 550, 551, 552, 553, 555, 556, 557]
Updated batch for film: [558, 559, 562, 569, 570, 580, 581, 582, 583, 584, 567, 571, 572, 573, 574, 575, 576, 577, 578, 579, 587, 588, 589, 590, 591, 592, 593, 594, 595, 606]
Updated batch for film: [607, 608, 609, 610, 611, 612, 613, 614, 615, 617, 618, 619, 620, 605, 624, 625, 627, 628, 629, 630, 637, 638, 640, 623, 643, 644, 645, 646, 647, 648]
Updated batch for film: [649, 650, 651, 652, 653, 655, 656, 657, 658, 642, 661, 662, 663, 668, 669, 670, 671, 672, 673, 674, 675, 676, 677, 660, 681, 682, 684, 686, 687, 688]
Updated batch for film: [689, 690, 691, 692, 693, 694, 695, 696, 699, 700, 701, 703, 704, 705, 706, 707, 708, 709, 710, 711, 712, 713, 714, 715, 698, 718, 719, 720, 721, 722]
Updated batch for film: [723, 724, 725, 747, 748, 749, 750, 751, 735, 755, 756, 757, 758, 759, 760, 761, 762, 763, 764, 772, 773, 774, 775, 776, 777, 778, 779, 780, 781, 782]
Updated batch for film: [783, 784, 785, 786, 788, 790, 791, 792, 793, 794, 795, 796, 804, 805, 789, 809, 810, 817, 818, 819, 820, 821, 822, 823, 811, 812, 813, 814, 815, 816]
Updated batch for film: [807, 826, 827, 828, 829, 834, 835, 836, 837, 838, 839, 840, 841, 825, 844, 845, 846, 847, 848, 849, 850, 851, 852, 853, 890, 854, 855, 856, 857, 858]
Updated batch for film: [843, 861, 862, 863, 864, 865, 866, 867, 868, 869, 870, 871, 891, 872, 873, 874, 875, 860, 879, 880, 905, 881, 882, 883, 884, 885, 886, 887, 888, 889]
Updated batch for film: [892, 893, 898, 899, 900, 901, 902, 903, 904, 906, 907, 908, 909, 910, 911, 912, 913, 897, 916, 917, 918, 919, 920, 921, 922, 923, 924, 925, 934, 935]
Updated batch for film: [936, 937, 938, 939, 940, 941, 942, 943, 944, 945, 946, 947, 948, 933, 953, 954, 955, 956, 957, 958, 959, 967, 968, 952, 971, 972, 973, 974, 975, 977]
Updated batch for film: [978, 979, 992, 980, 981, 982, 983, 984, 985, 986, 970, 993, 994, 995, 996, 987, 989, 990, 988, 991, 18, 30, 35, 51, 68, 86, 105, 123, 142, 161]
Updated batch for film: [178, 190, 197, 216, 231, 252, 254, 272, 289, 290]
Updating netflix_shows embeddings...
Processing 8807 rows from netflix_shows in 294 batches (batch size = 30)...
Updated batch for netflix_shows: ['s2236', 's1398', 's1399', 's1400', 's1401', 's1403', 's1404', 's1405', 's2484', 's2485', 's2486', 's2487', 's2488', 's2489', 's2490', 's2492', 's2494', 's2495', 's1406', 's31', 's32', 's33', 's34', 's35', 's36', 's1407', 's1408', 's1409', 's1410', 's1411']
Updated batch for netflix_shows: ['s1412', 's1413', 's1414', 's1415', 's2253', 's1417', 's1418', 's1423',
....
(pgvector_lab) 14:44:08 postgres@PG1:/home/postgres/LAB_vector/ [PG17] python recommend_netflix.py
Enter customer id: 524
Top 5 Netflix recommendations for customer 524:
1. Alarmoty in the Land of Fire (similarity distance: 0.4505)
2. Baaghi (similarity distance: 0.4518)
3. Into the Badlands (similarity distance: 0.4526)
4. Antidote (similarity distance: 0.4527)
5. Duplicate (similarity distance: 0.4553)
(pgvector_lab) 14:46:16 postgres@PG1:/home/postgres/LAB_vector/ [PG17] python recommend_netflix.py
Enter customer id: 10
Top 5 Netflix recommendations for customer 10:
1. Antidote (similarity distance: 0.4406)
2. Krutant (similarity distance: 0.4441)
3. Kung Fu Yoga (similarity distance: 0.4450)
4. Hunt for the Wilderpeople (similarity distance: 0.4469)
5. The Truth (similarity distance: 0.4476)
(pgvector_lab) 14:46:21 postgres@PG1:/home/postgres/LAB_vector/ [PG17]
Once the embeddings are created and inserted into the tables, we can check if the recommendations works. In my case I use the text-embedding-ada-002 embedding model in the inference process part and then I use pgvector to look for similarities based in SQL.
This has the advantages of being very simple, cost-effective and really powerful at scale although you have to develop your own application part. You could use Chatpgt to replace your application at the cost of doubling the inference.
That’s it for now. If you want to have access to the source files, scripts I used and full procedure, you can check this repository : Movies_pgvector_lab.
Enjoy !
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2025/03/OBA_web-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/FRJ_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2023/01/APY_web-scaled.jpg)