Optimizing Multi-Billion Row Tables in Tabular in 2018
I wanted to attend the session moderated by Marco Russo to see his approach of optimizing performance in Tabular model
The first thing to understand is how the data is stored and organized in a Tabular model. It is of course using the xVelocity in-memory capabilities with the Vertipac column storage layout engine. It organizes the data, compressing it by column, in combination with a dictionary encoding mechanism.
Therefore the most important aspects in a model to take care at are:
- Reducing the number of distinct values of columns
- Focus on columns with many distinct values
What impacts the performance of data retrieval is also the relationships in the model that define the cardinality. The higher the cardinality is, the slower the query will be.
In order to measure there criteria the following tools are available:
- Vertipac analyzer: it can help you to get insight on your tabular model, to get information on the number of items in your columns and their size.
- DAX studio: it is an open source that you can download visiting https://Daxstudio.org
DAX Studio will help you to analyze how your queries are performing and you will be able to see how the performance is related to the number of cores, the size of the columns queried and as already said above the size of the cardinality involved.
What is recommended for tabular model is to have the fastest CPU speed (>= 3GHz) and CPU L2/L3 large caches; large cache of the CPU is essential to avoid quickly performance problems, but having to many CPU can be counterproductive, having more sockets can negatively impact your performance. Fastest RAM is also recommended(>=3200). You have to be aware of the latency of memory and storage access and see the huge impact it has on the performance.
Marco delivers best practice using the Azure tiers available

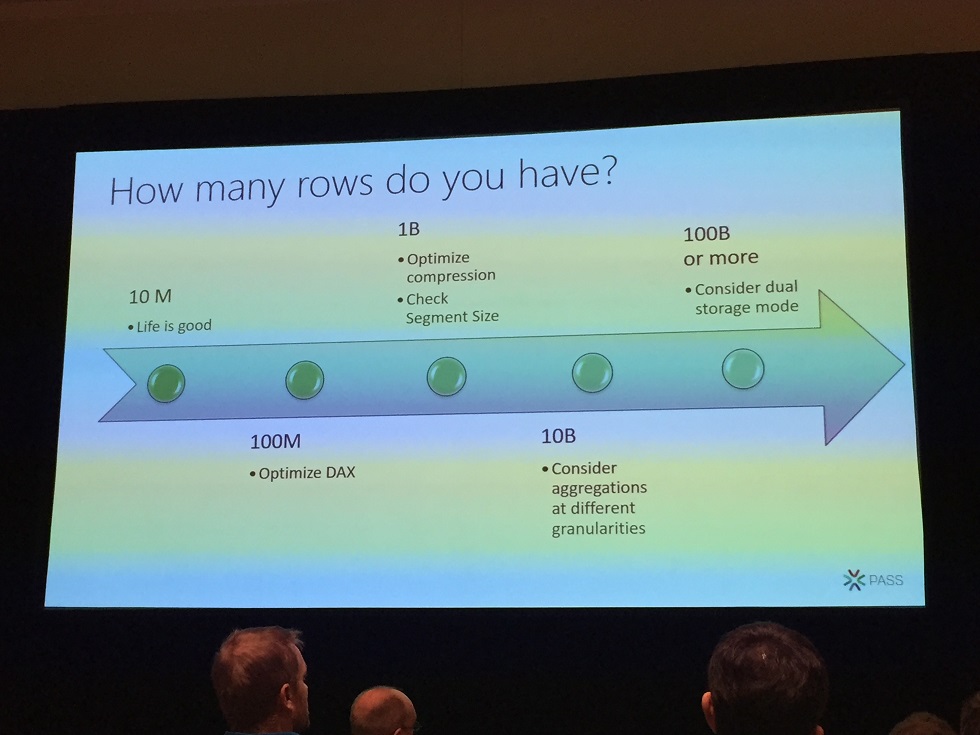
The way you can influence having too high cardinality between fact and dimension is reduce the dimension with sub category but also to reduce you fact by splitting it and doing aggregates. You have to re-shape your data model.
The great thting is that a new “Dual storage mode and aggregation option” is a new feature in Power BI Premium that enable to defined aggregation table of your big fact tables that do not fit in memory within Power BI.
Again an interesting data analytic day…stay tuned..
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/09/CHC_web-min-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/11/LTO_WEB.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2023/01/APY_web-scaled.jpg)