Over 1 million IOPS (@8 KByte) and more than 26 GByte/s (@1MByte): Read more to see all impressive benchmark figures from a server with 14 NVMe drives and read why this is still not the best you could get…
End of last year, I have gotten a call from Huawei. They (finally) agreed to provide me a server with their enterprise NVMe drives for performance testing.
To say that I was delighted is a huge understatement. It felt like an 8-year old waiting for Christmas to get his present.
Choosing the right hardware for a database server is always important and challenging. Only if you build a rock-solid, stable and performant base you can build a reliable database service with predictable performance. Sounds expensive and most of the time, it is, but NVMe drives can be a game-changer in this field.
After a very nice and friendly guy from Huawei delivered this server to me, I immediately started to inspect this wonderful piece of hardware I’ve got.
Testserver
Huawei provided an H2288 2 Socket Server with 15x 800GByte NVMe drives (ES3600P V5 800 GBytee PCI Gen3) to me.


The server would be able to handle 25 NVMe drives but I think I’ve got every drive, which was available at this time 🙂
All drives have a U.2 PCIe connector. The drives are connected over two PCIe Gen3 16x adapter card with 4 cables on each card (this information will get important later…)


The PCIe cards provide the PCIe lanes for the NVMe drives. These cards are just passthrough cards without any RAID function at all.
So all your RAID configuration has to be done within a software raid (e.g. ASM, LVM, etc.)
The drives are also available with the sizes of 1-6.4 TByte.
Expected performance
As often with SSD/NVMe drives the performance is tied to the size of the drive. We are testing the smallest drive from the series with the lowest specs. But “low” depends on your angle of view.
The 800 GByte drive has a spec performance of
420k IOPS read @ 4KByte blocksize
115k IOPS write @ 4KByte blocksize
3500 IOPS read @ 1MByte blocksize
1000 IOPS write @ 1MByte blocksize
Because we are testing with the Oracle default blocksize we can translate that to
210k IOPS read
57k IOPS write @ 8KByte blocksize PER DRIVE!
The bigger drives have even higher specs as you can see in the picture.

Even more impressive is the specified read and write latency which is 0.088ms and 0.014ms
Of course, these numbers are a little bit like the fuel usage numbers in a car commercial: Impressive but mostly not true. At least when you exceed the cache size of your drive your performance will drop. How much? The interesting question is: How big is the drop?
Test setup
I used an Oracle Linux 7.7 OS and ext4 filesystem with fio for benchmarking tests as well as Oracle 19c with ASM and calibrate_io to prove the result.
Because I used 1 drive for the OS I had “only” 14 drives for testing the performance.
Please see my other blog post Storage performance benchmarking with FIO for detailed information about the fio tests.
Test results with fio
Because SSD/NVMe drives tend to be faster when empty, all drives were first filled 100% before the performance measuring started.
The test was made with 1 drive and 1 thread up to 14 drives and 10 threads per drive.
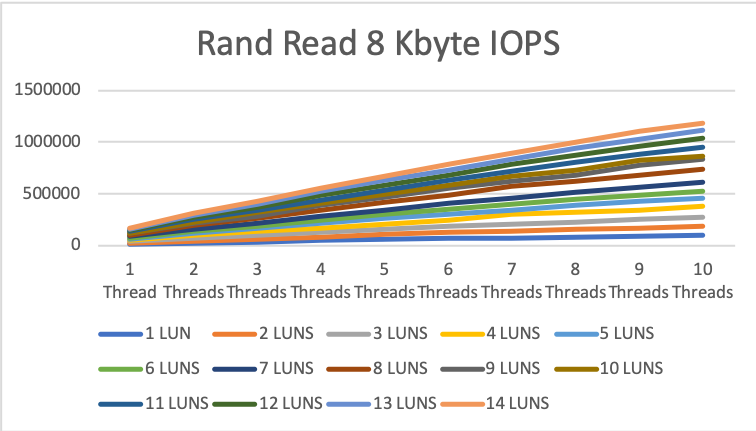
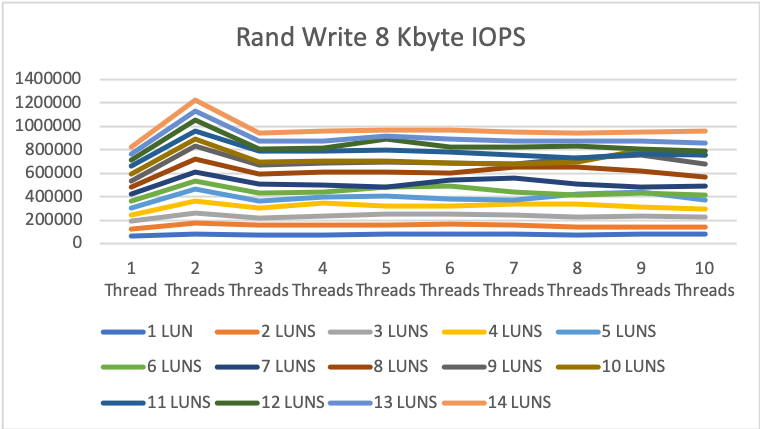
8KByte random read/write
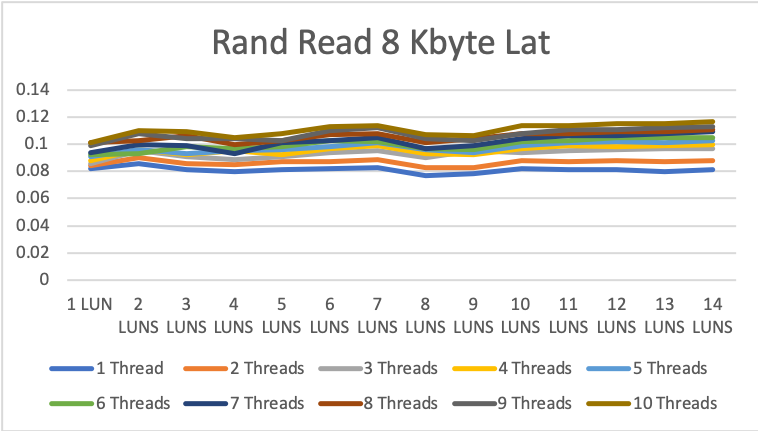
For random read, the results of the test start at 12k IOPS for 1 drive and 1 thread up 1.186 million IOPS (roughly 9.5GByte/s!!) with 14 drives and 10 threads per drive. The latency was between 82 and 117 microseconds
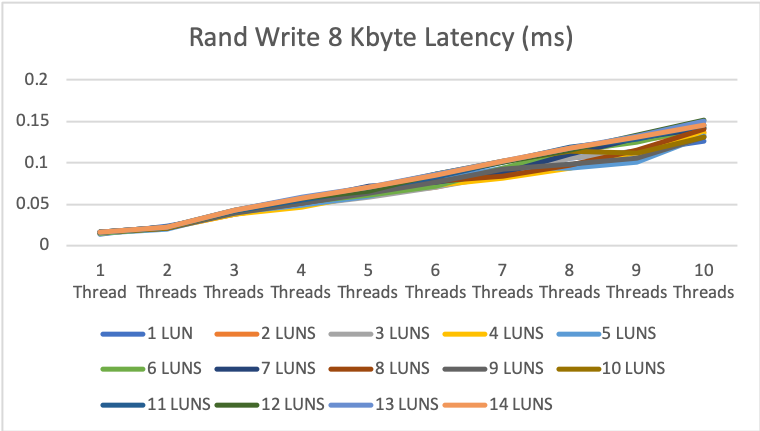
Random write tests started even more impressive with 64.8k IOPS with 1 drive and 1 thread up to 0.956 million IOPS (roughly 7.6GByte/s!!) at max.
The write latency was between 14 and 145 microseconds which is absolutely insane, especially compared to the latency you can expect from an all-flash storage system with an FC network in between.
8KByte sequential read/write
The numbers for 8KB sequential read and write are even better but in the life of a DB server a little bit less important.
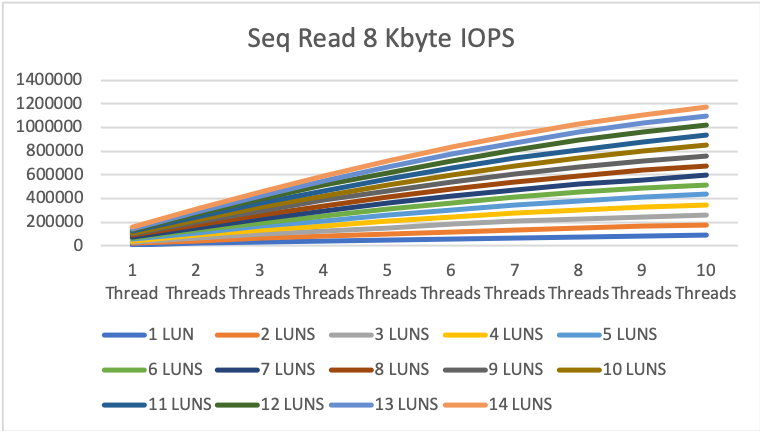
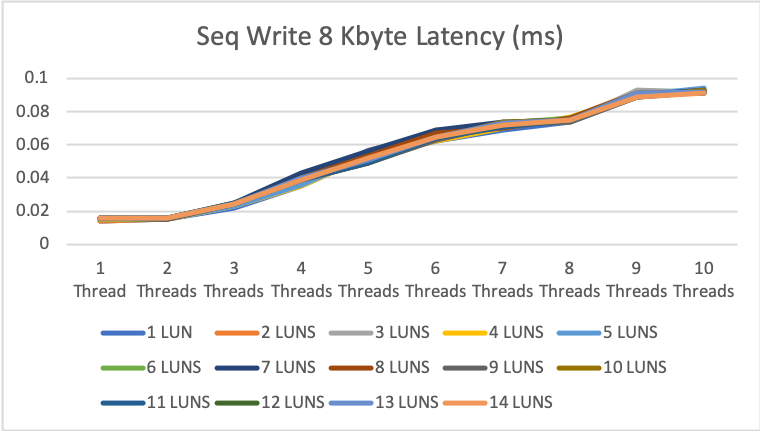
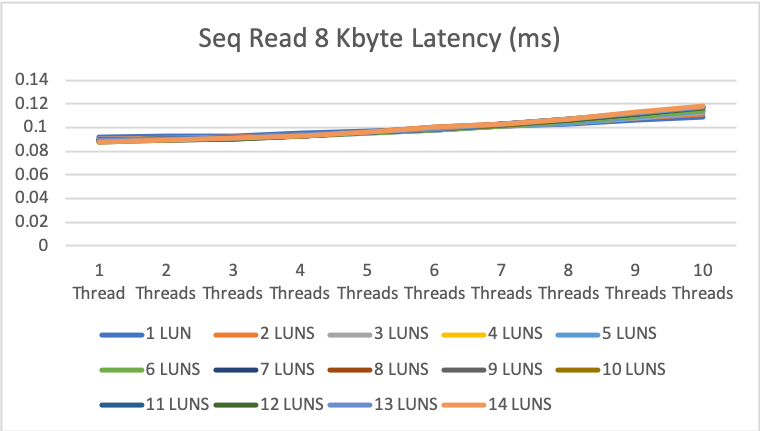
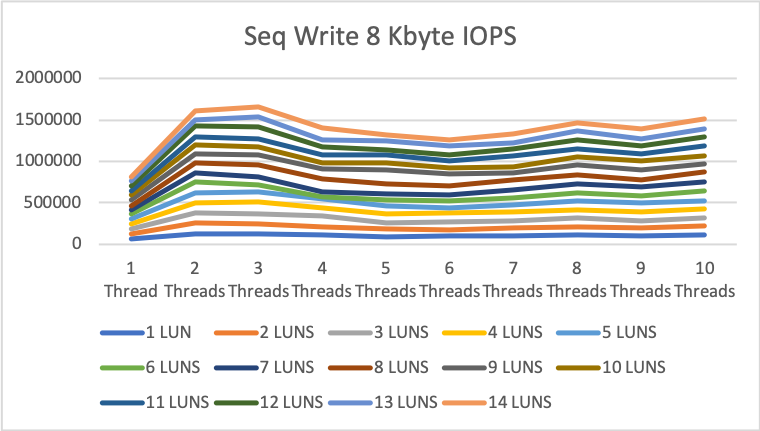
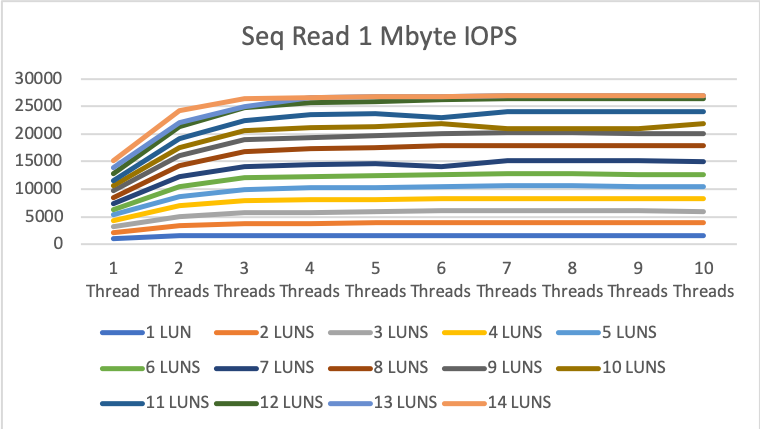
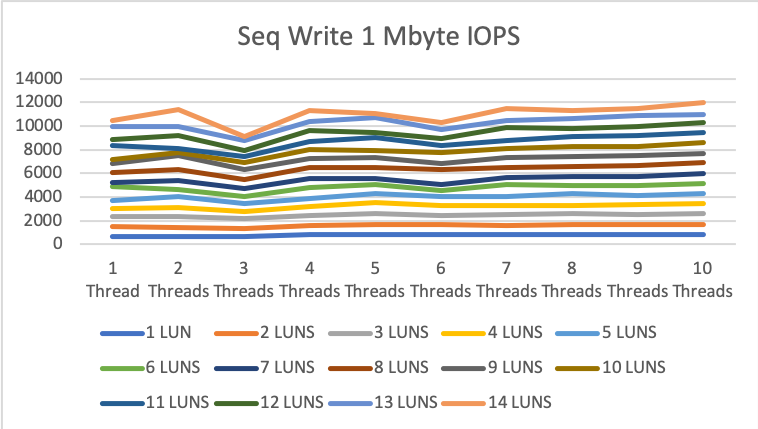
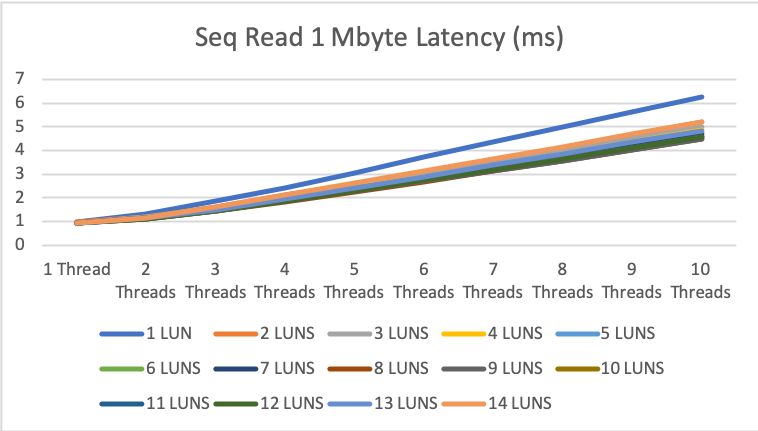
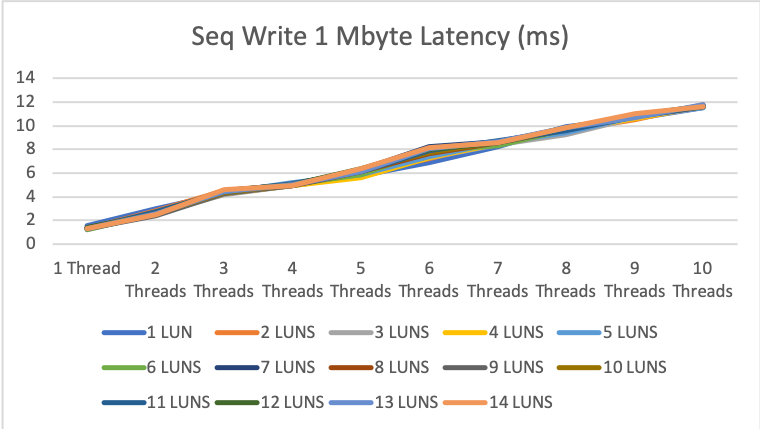
1MByte sequential read/write
Let us talk about the 1MByte blocksize results.
Here we are starting around 1GByte/s with 1 drive and 1 thread up to 26.9 GByte/s with 14 drives and 10 thread. The max value was already reached with 13 drive and 6 threads per drive.
Latency also looks good with 1-5ms which is a good value for IO of this blocksize.
The 2x 16x PCIe Gen3 adapter cards are here the bottleneck. We hit the maximum throughput of the bus. The drives could deliver more performance than the bus and this with just 14 of the possible 25 drives!
The number for sequential writes are not as high as for sequential reads but still quite impressive. We reached 0.656 GByte with 1 drive/1thread up to a maximum speed of 12GByte/s.
The latency is also good with 1.5-12ms.
If you wanna compare these numbers with an all-flash SAN storage go to my blog post about the Dorado 6000 V3 Benchmark.
Verify the results with a secondary tool
To verify the results of the filesystem test with a secondary tool, created a database with all the 14 drives in one ASM diskgroup with external redundancy.
dbms_resource_manager.calibrate_io supports the fio results with 1.35 million IOPS and 25 Gbyte/s throughput. Not exactly the same numbers, but close enough to prove the fio results. Not only we added ASM as an additional layer instead of LVM, but we also tested within the database instead of directly on the OS layer.

Even more speed possible?
There is not a clear answer:
If we could switch to bigger drives and higher capacity of the drives we could expect up to 4 times more IOPS for 8Kbyte (2x more for the double numbers of drives and 2x more for the better specs with the bigger drives).
BUT the controller will be the limitation. We already hit the limit of the 2xPCIe 16x Gen3 bus with 1MByte sequential read in this test and will possibly do so for the other tests when we are testing with more drives.
The server has at least 4 additional PCIe slots but all with only 8 lanes. So here is a bottleneck we are not able to solve in a server with Intel CPUs.
AMD already switched to PCI Gen4 (2x bandwidth then PCIe Gen3) and much more PCI lanes at with their CPUs, but most of the enterprise servers are Intel-based and even when AMD based servers should be available they are rarely seen at customer’s side (at least by my customers).
Intel also has a roadmap for providing PCIe Gen4 but the CPUs will be available earliest end of this year ;-(
Conclusion
This setup is freaking fast! Not only the throughput numbers are astonishing, but also the latency is very impressive. Even a modern storage system has a hard time to provide such numbers and has almost no chance to get down to this latency level.
Not talking about the fact, that a storage system eventually can hit these numbers but you need a 200GBit/s connection to get it down to your server…
With local NVMe drives you can get these numbers out of every box, not sharing with anybody!
As my colleague has written very well in his blog post Make Oracle Database simple again I could not agree more: Do not use SAN when it is not necessary, especially when your other option is local NVMe drives!
As long as you are not using Oracle RAC, you’ve got everything you need for your high availability with Data Guard or other HA solutions. Combine it with Oracle Multitenant and snapshot standbys: Ready is your high-performance database platform to consolidate all your databases on.
Skip the SAN Storage and put the saved money in some additional NVMe drives and set your database to hyperspeed.
When choosing the right CPUs with the needed numbers of Cores and the best available clock speed you can build a beast of a database server (not only for Oracle databases…).
Talking about money, the NVMe drives are getting cheaper almost every month and you can get a 6.4 TByte enterprise NVMe drive quite cheap today.
Of course, there is a downside: Scalability and RAID
At the moment your journey ends with 25×6.4 TByte drives (160 TBye raw / 80 TByte mirrored) capacity.
If you need more space, you have to go to another solution at least for the moment. I expect to see NVMe drives with >15 TByte this year and switch from PCIe Gen3 to Gen4 will bring even more performance for a single drive.
The other downside is the raid controller. Which just does not exist at the moment (as far as I know). You have to go with software RAID.
Not a big deal if you are using Oracle ASM, even when you just can do a RAID-1 where you are “loosing” 50% of your raw capacity. With DM/LVM you could do a software Raid-5. I can not tell you about the performance impact of that, because I just had not enough time to test this out.
But stay tuned, I am looking for a server with bigger and more drives for my next tests.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/oracle-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/11/TBR-web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/11/LTO_WEB.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/MAW_web-min-scaled.jpg)