I had the opportunity to test the new Dorada 6000 V3 All-Flash storage system.
See what the all-new Dorado 6000 V3 All-Flash Storage system is capable as storage for your database system.
Before you read
This is a series of different blog posts:
In the first blog post, I talk about “What you should measure on your database storage and why”.
The second blog post will talk about “How to do database storage performance benchmark with FIO”.
The third blog post will show “How good is the new HUAWEI Dorada 6000V3 All-Flash System for databases” measured with the methods and tools from post one and two (aka this one here).
The first two posts give you the theory to understand all the graphics and numbers I will show in the third blog post.
So in this post, we see, what are the results when we test a Huawei Dorado 6000V3 All-Flash storage system with these technics.
I uploaded all the files to a github repository: Huawei-Dorado6000V3-Benchmark.
Foreword
The setup was provided by Huawei in Shengsen, China. I’ve got remote access with a timeout at a certain point. Every test run runs for 10h, because of the timeout I was sometimes not able to capture all performance view pictures. That’s why some of the pictures are missing. Storage array and servers were provided free of charge, there was no exercise of influence from Huawei on the results or conclusion in any way.
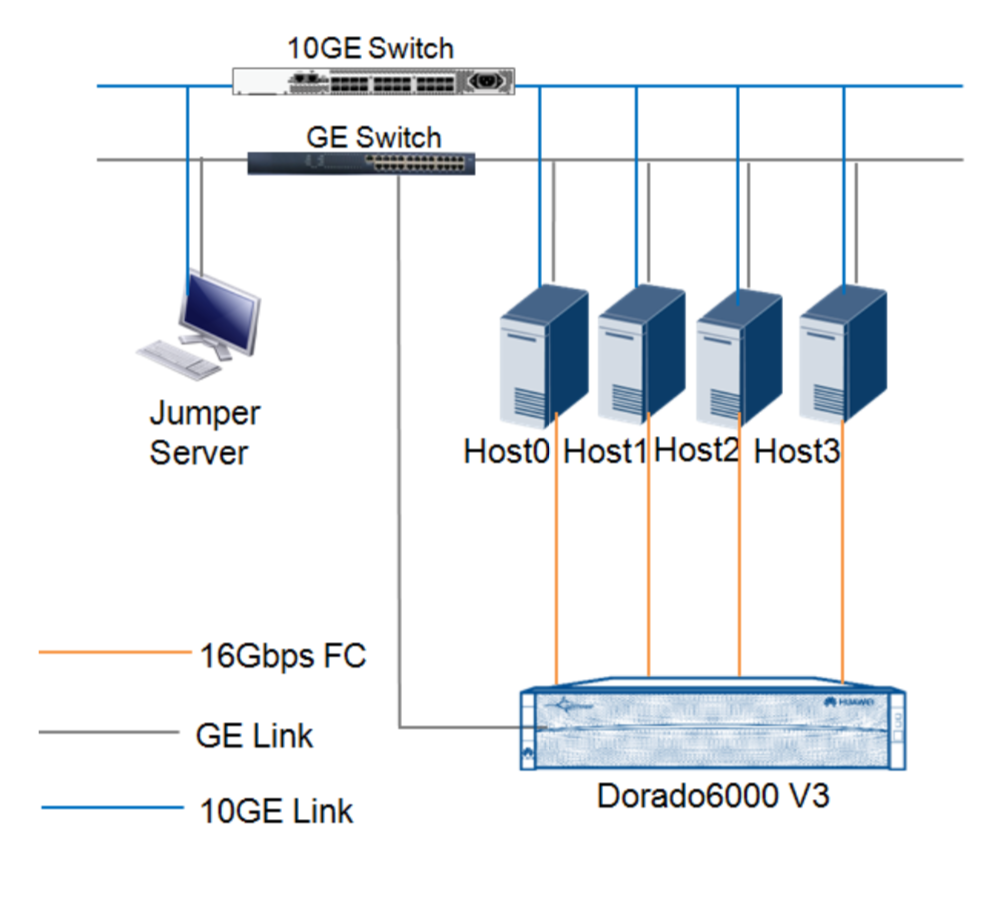
Setup
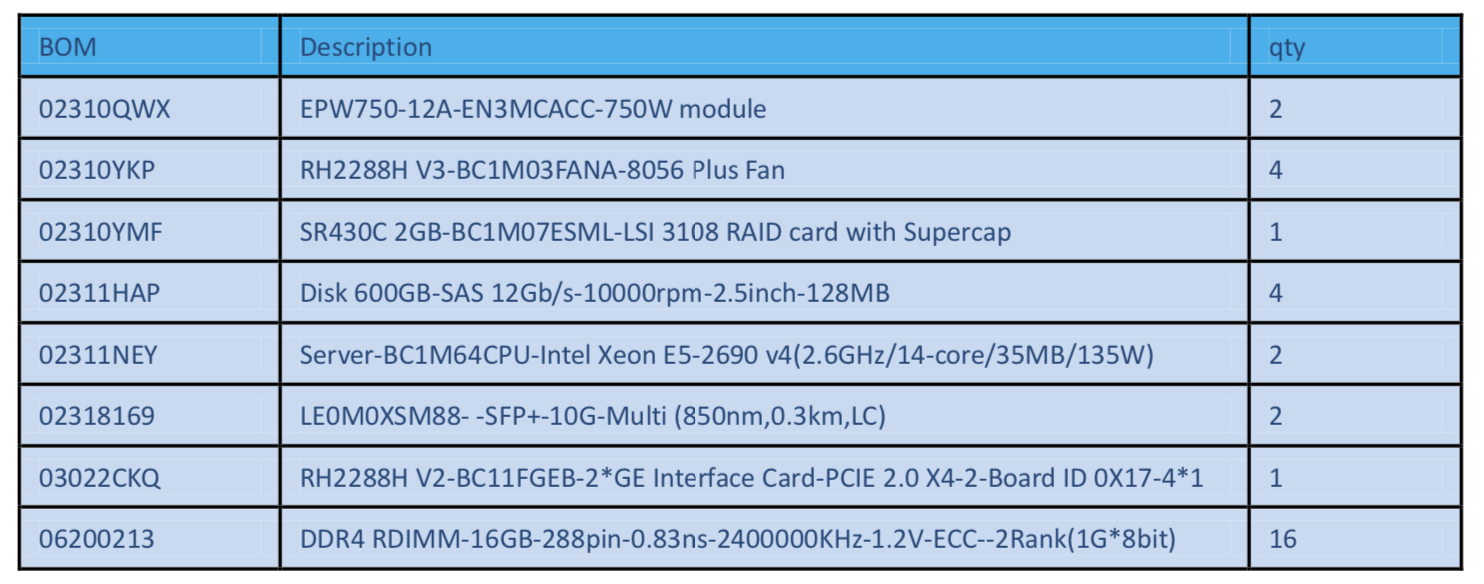
4 Server were. provided, each with 4×16 GBit/s FC adapter direct connected to the storage systems.
There are 256 GByte of memory installed and 2x 14 Cores 2.6 GHz E5-2690 Intel CPUs.
Hyperthreading is disabled.
The 10 GBit/s network interfaces are irrelevant for this test here because all storage. traffic runs over FC.
The Dorado 6000 V3 System has 1 TByte of cache and 50x 900 GByte SSD from Huawei.
Deduplication was disabled.
Tests were made with and without compression.

Theoretical max speed
With 4x16GBit/s a maximal throughput of 64 GBit/s or 8 GByte/s is possible.
In IOPS this means we can transmit 8192 IOPS with 1 MByte block size or 1’048’576 IOPS with 8 KByte block size.
As mentioned in the title, this is theoretically or raw bandwidth, the usable bandwidth or payload is, of course, smaller: A FC-frames is 2112 bytes with 36 bytes of protocol overhead.
So in a 64 GBit/s FC network we can transfer: 64GBit/s / 8 ==> 8GByte/s * 1024 ==> 8192 MByte/s (raw) * (100-(36/2.112))/100 ==> 6795MByte/s (payload).
So we end up with a maximum of 6975 IOPS@1MByte or 869’841 IOPS@8KByte (payload) not included is the effect, that we are using multipathing* with 4x16GBit/s, which will also consume some power.
*If somebody out there has a method to calculate the overhead of multipathing in such a setup, please contact me!
Single-Server Results
General
All single server tests were made on devices with enabled data compression. Unfortunately, I do not have the results from my tests with uncompressed devices for single server anymore, but you can see the difference in the multi-server section.
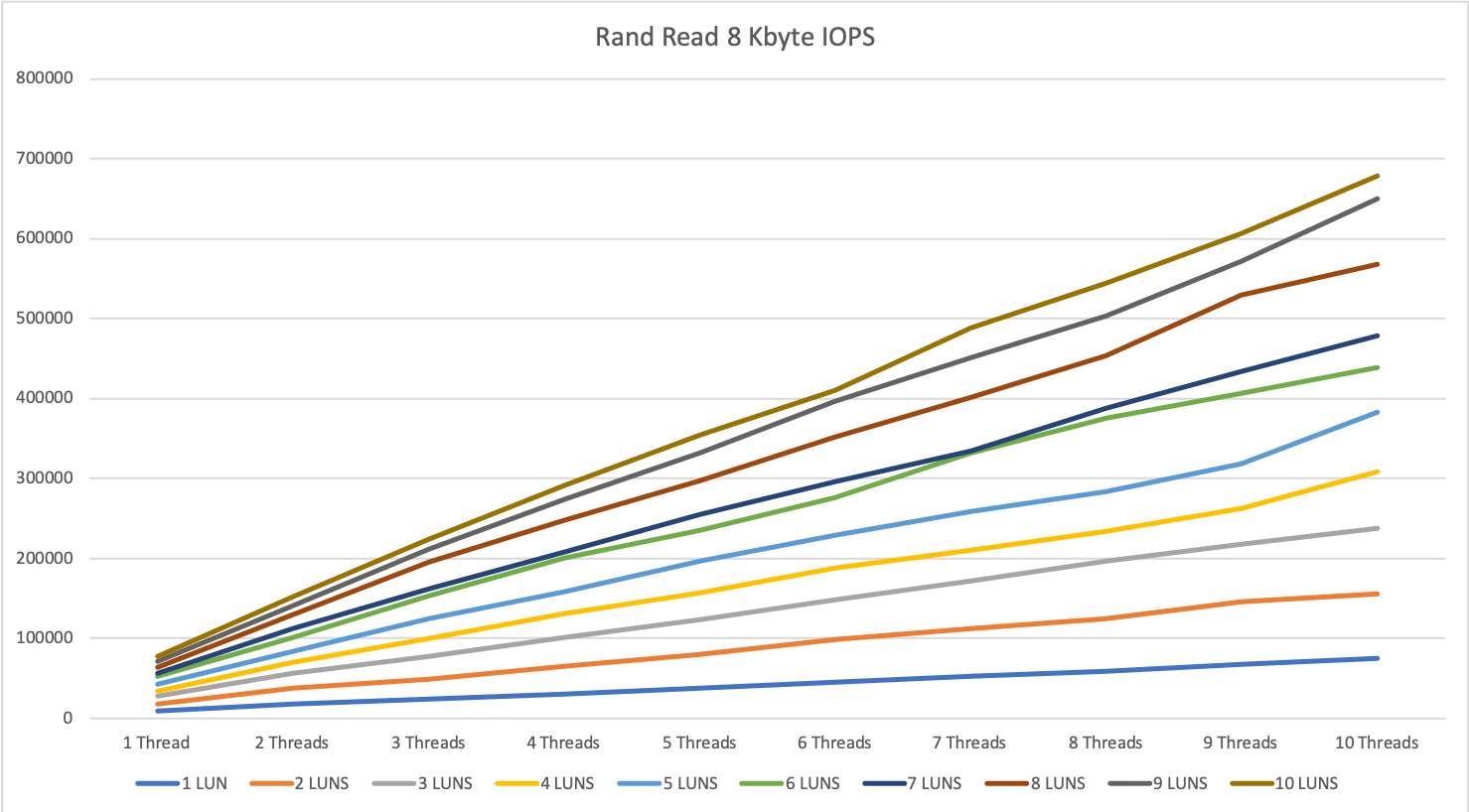
8 KByte block size
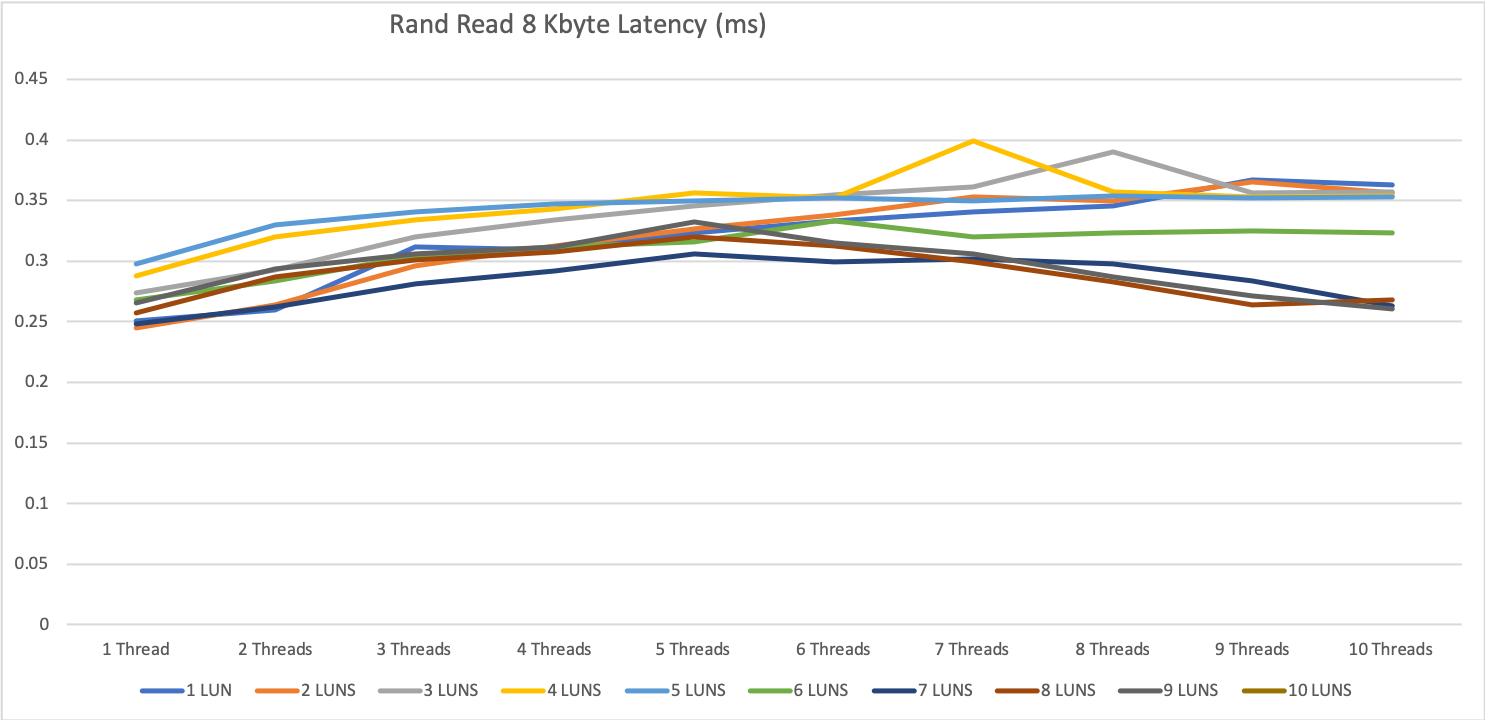
The 8 KByte block size tests on a single server were very performant.
What we can already tell, as higher the parallelity as better the storage performs. This is not really a surprise. Most storage systems work better, as higher the parallel access is.
Specialy for 1 thread, we see the differenc between having one disk in a diskgroup and be able to use 3967 IOPS or using e.g. 5 disks and 1 thread an be able to use 16700 IOPS.
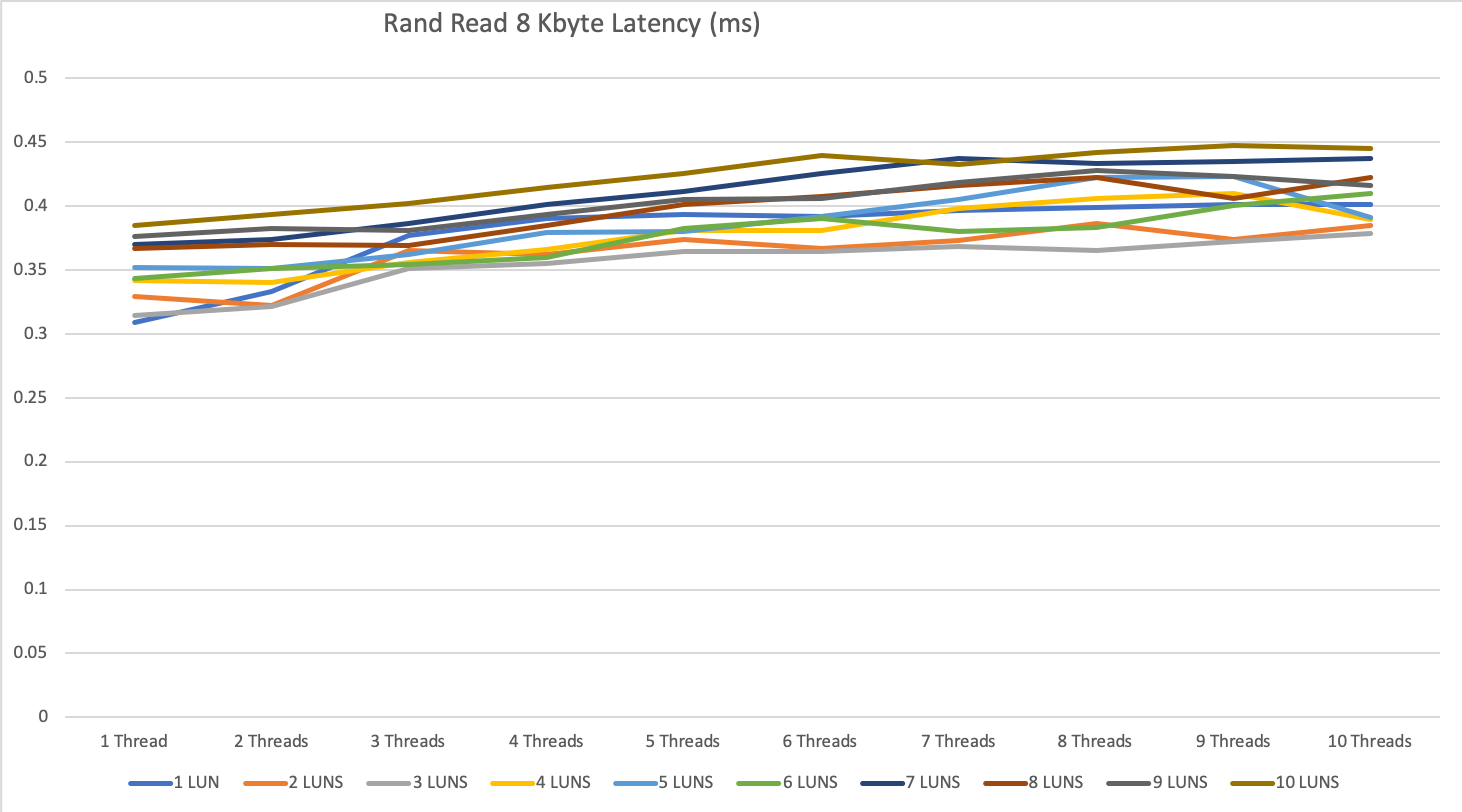
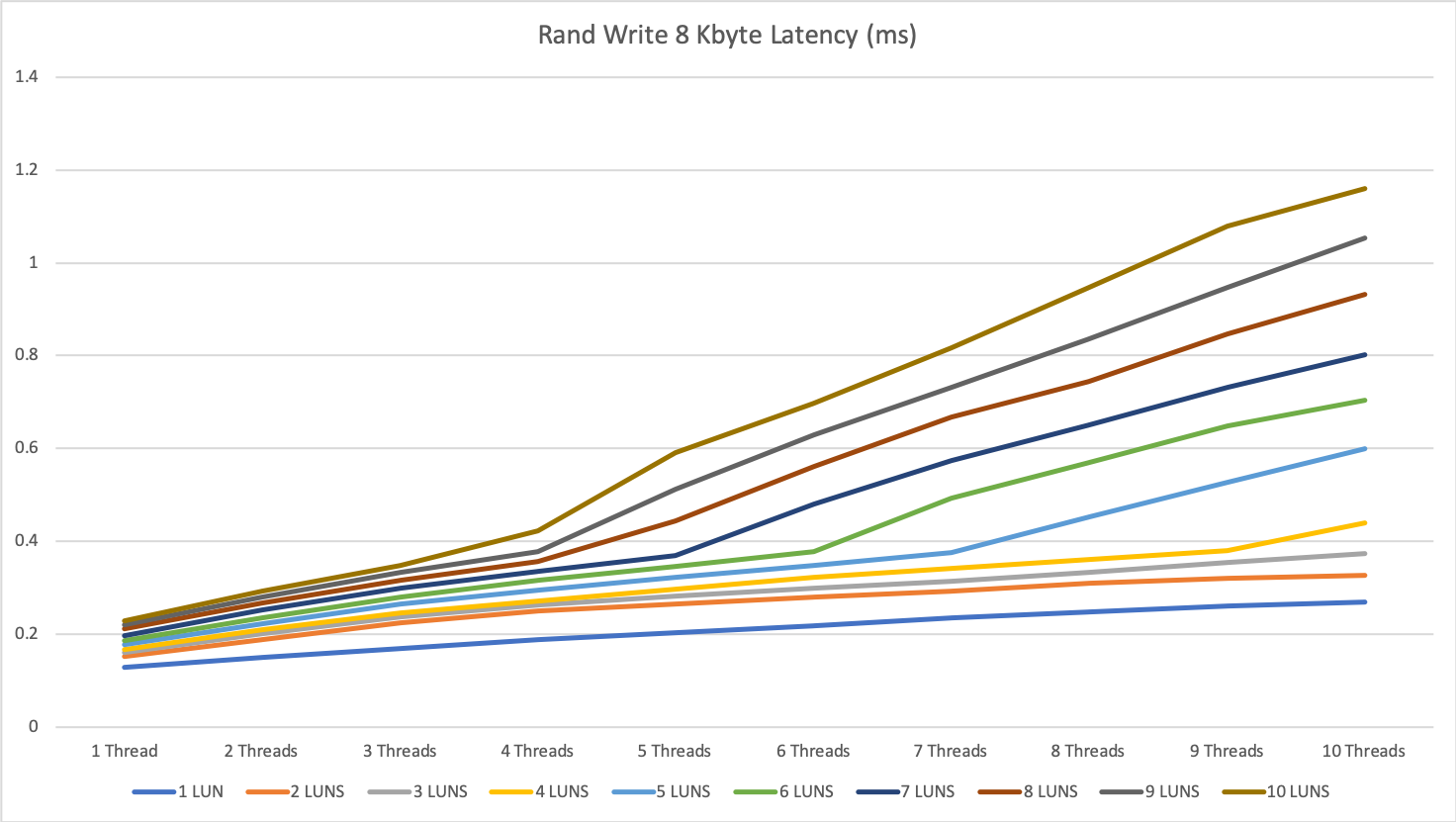
The latency for all tests was great with 0.25ms to 0.4ms for reading operation and 0.1 to 0.4ms for write operations.
The 0.1ms for write is not that impressive, because it is mainly the performance of the write cache, but even when we exceeded the write cache we were not higher then 0.4ms

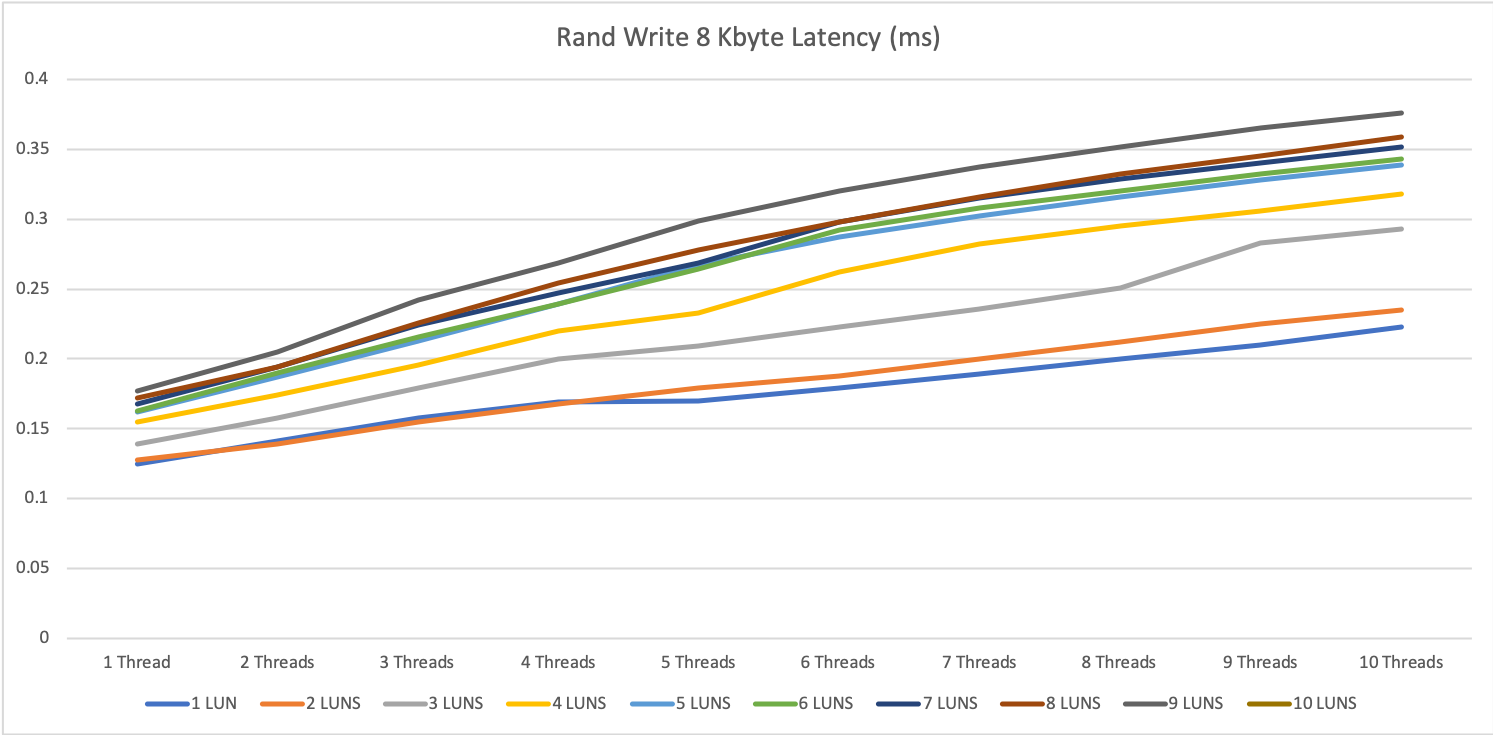
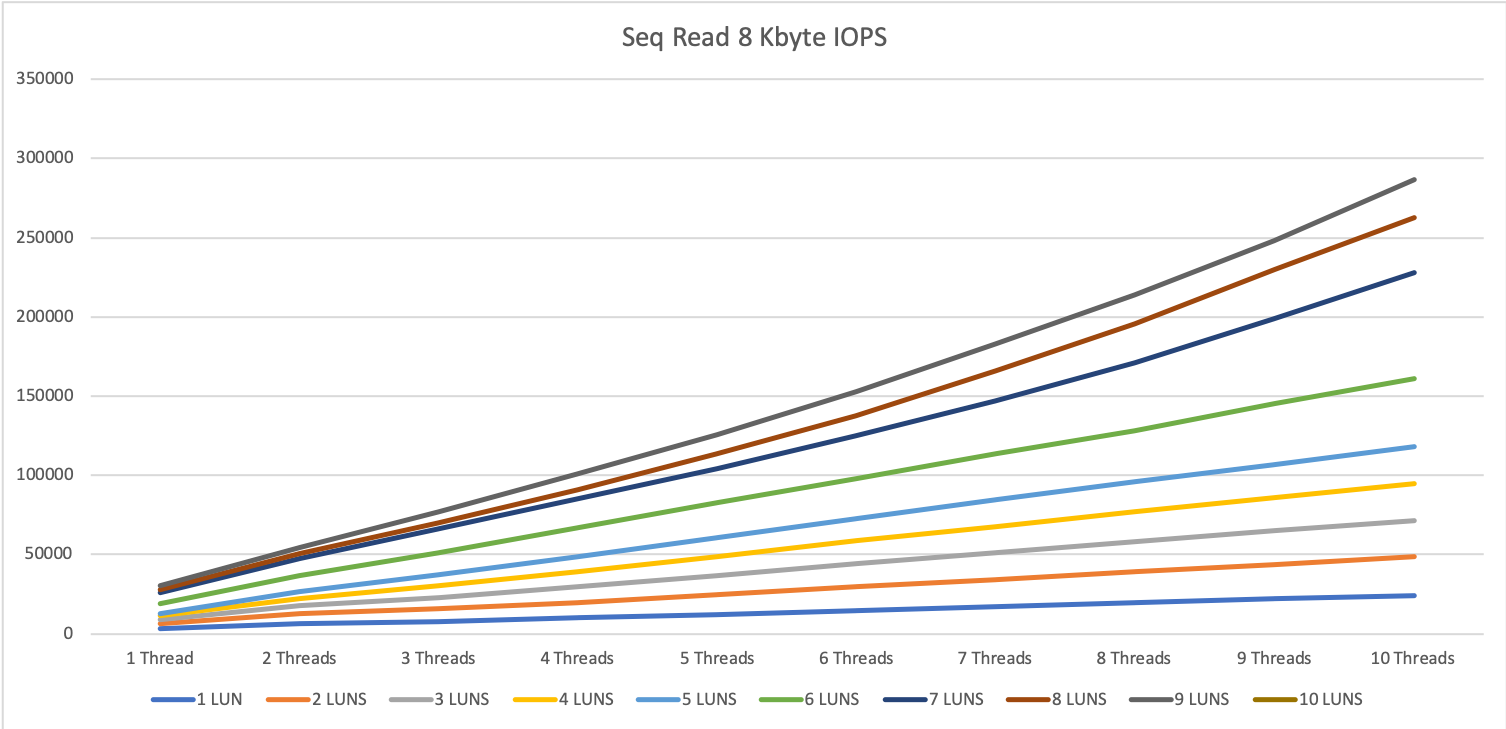
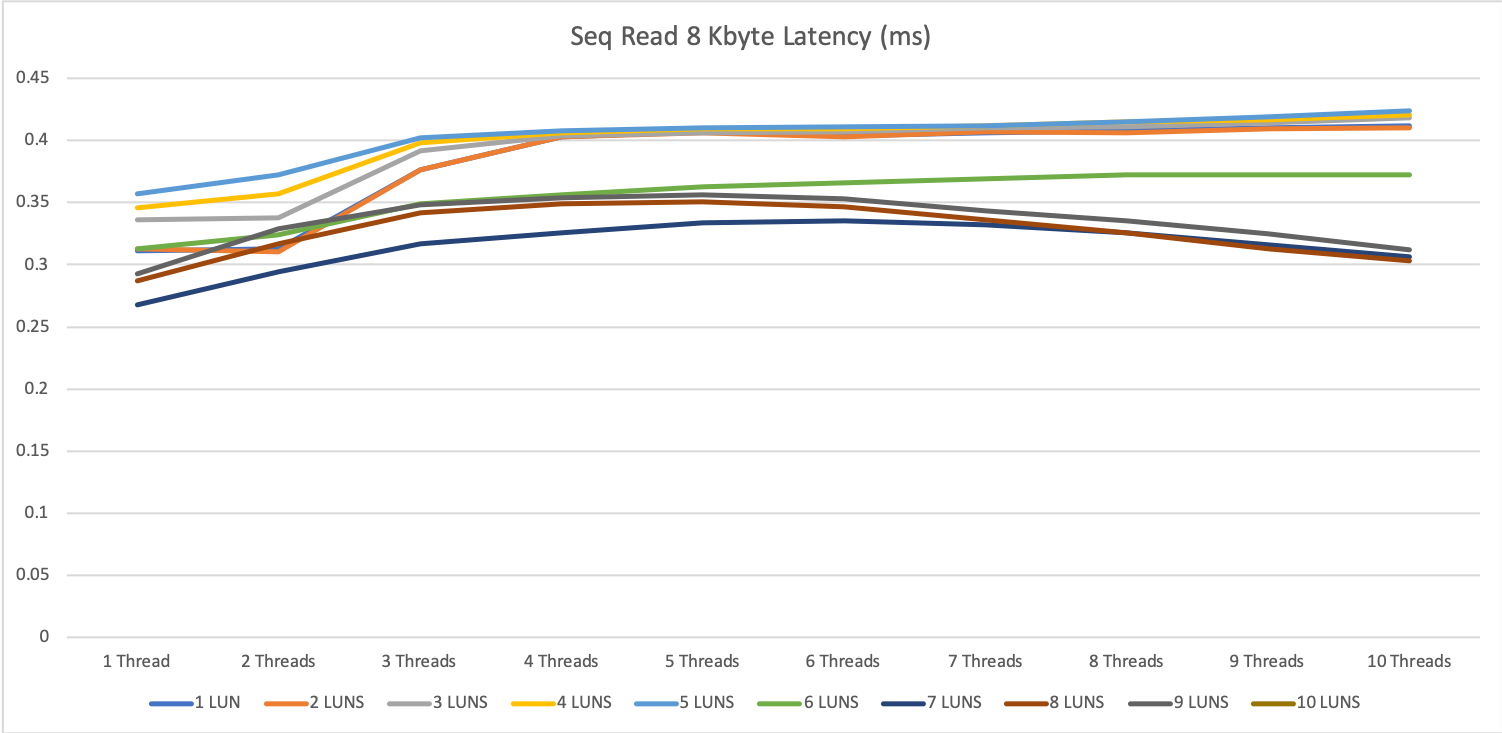

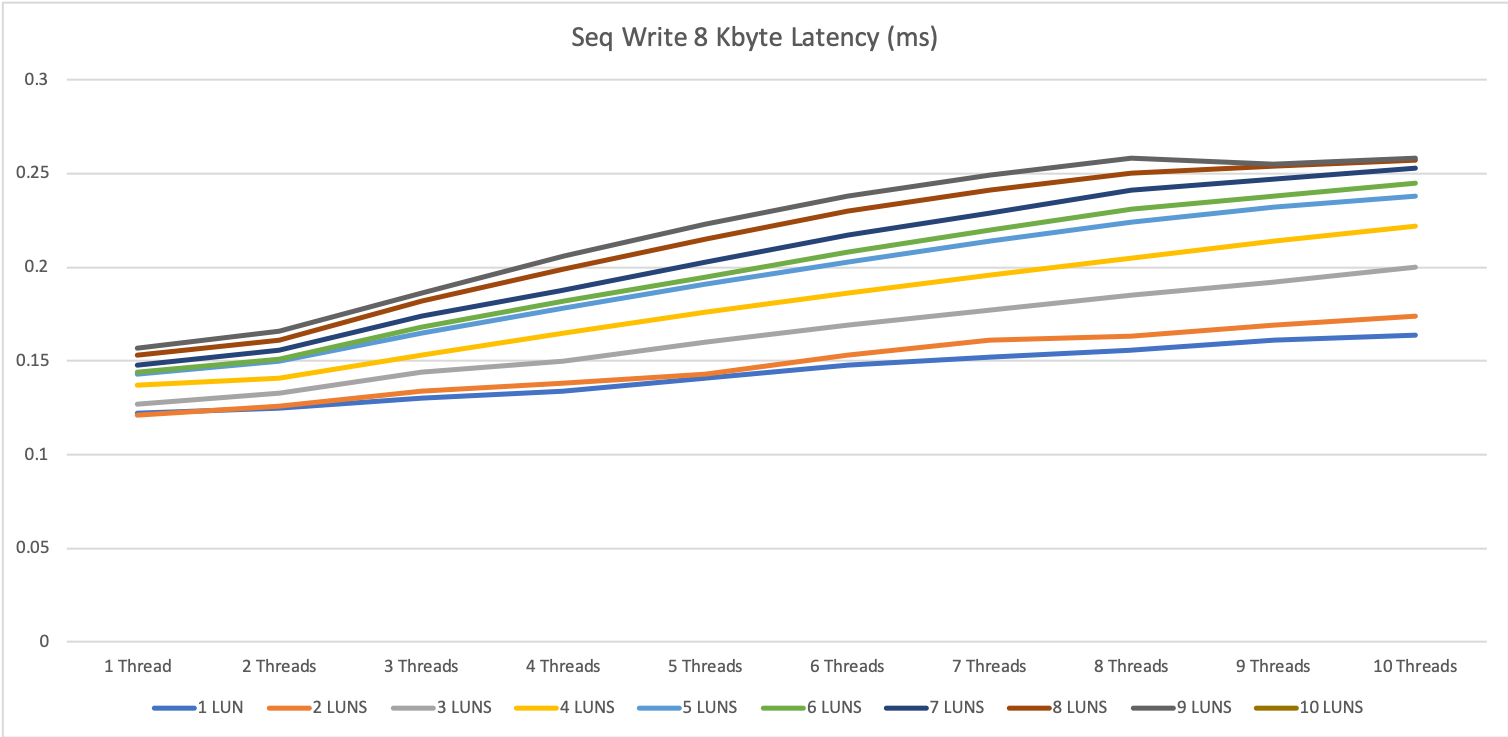
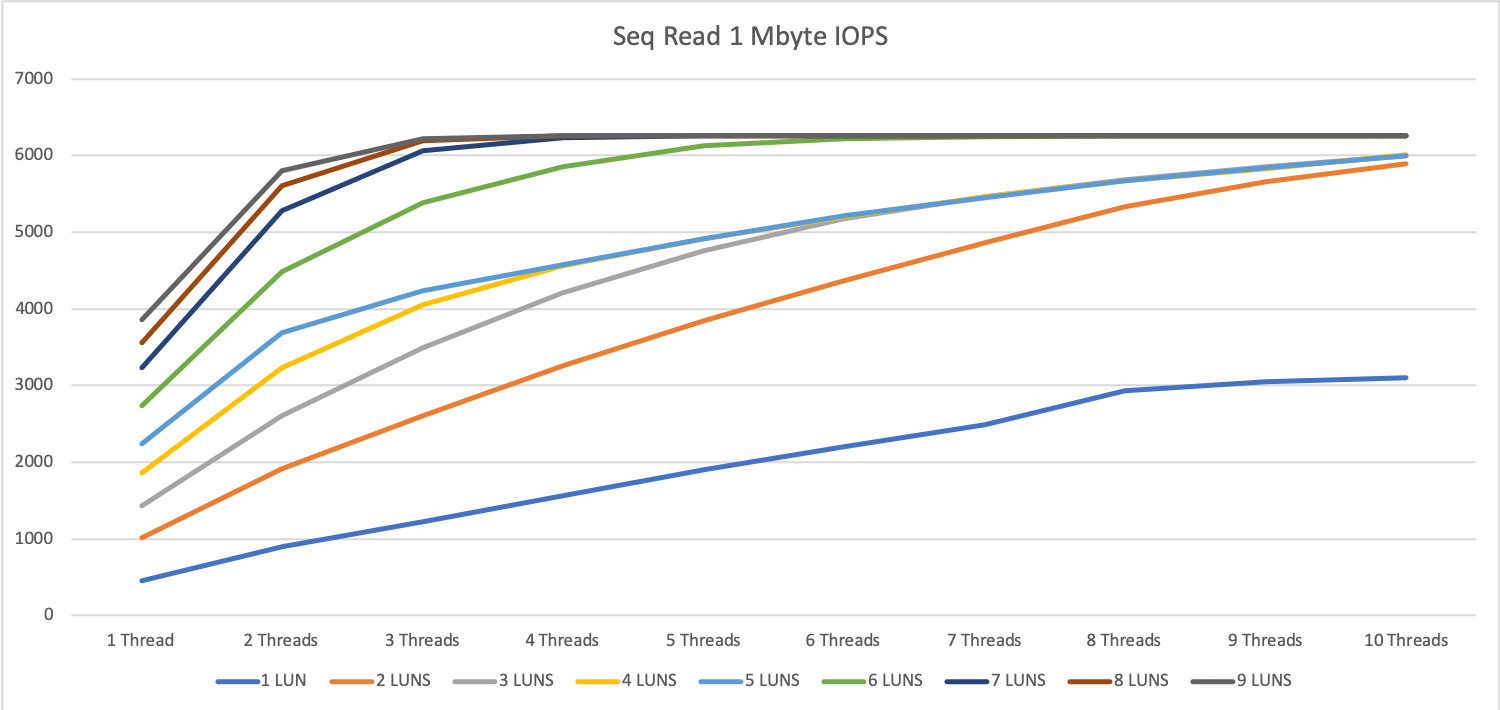
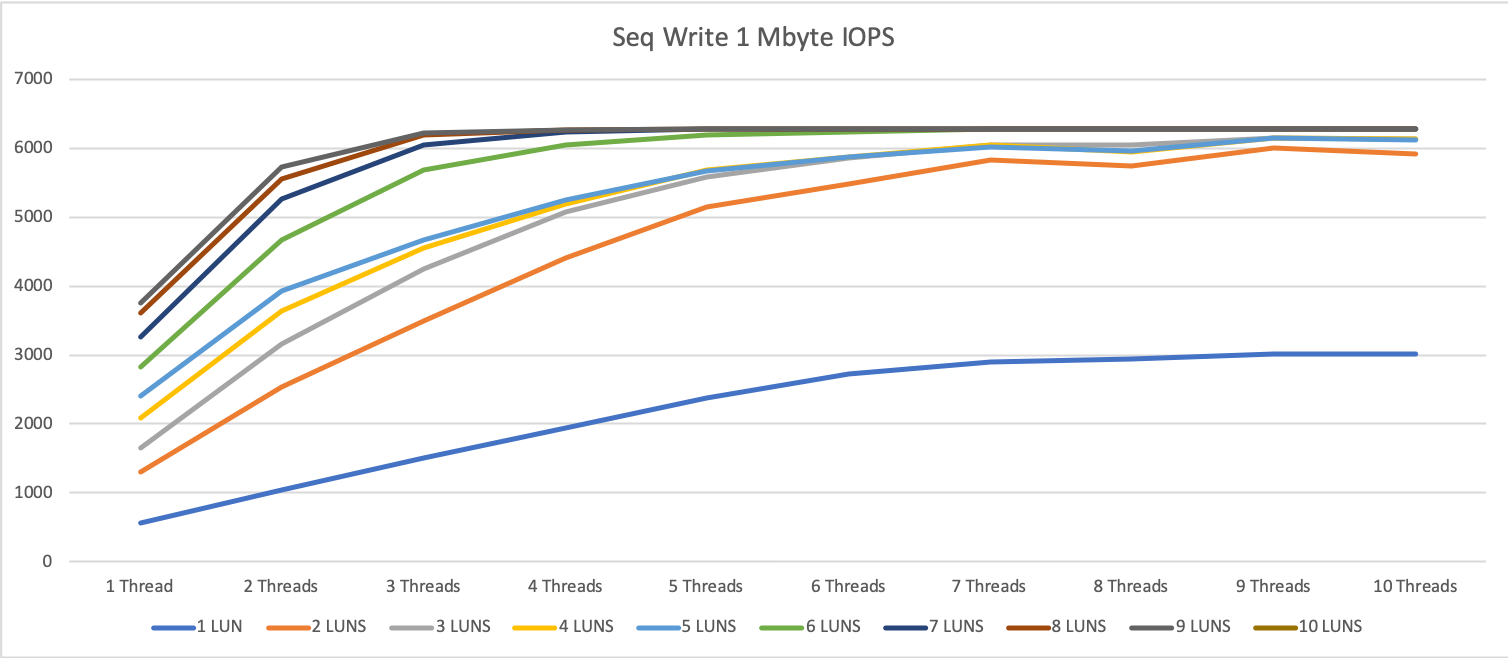
1 MByte block size
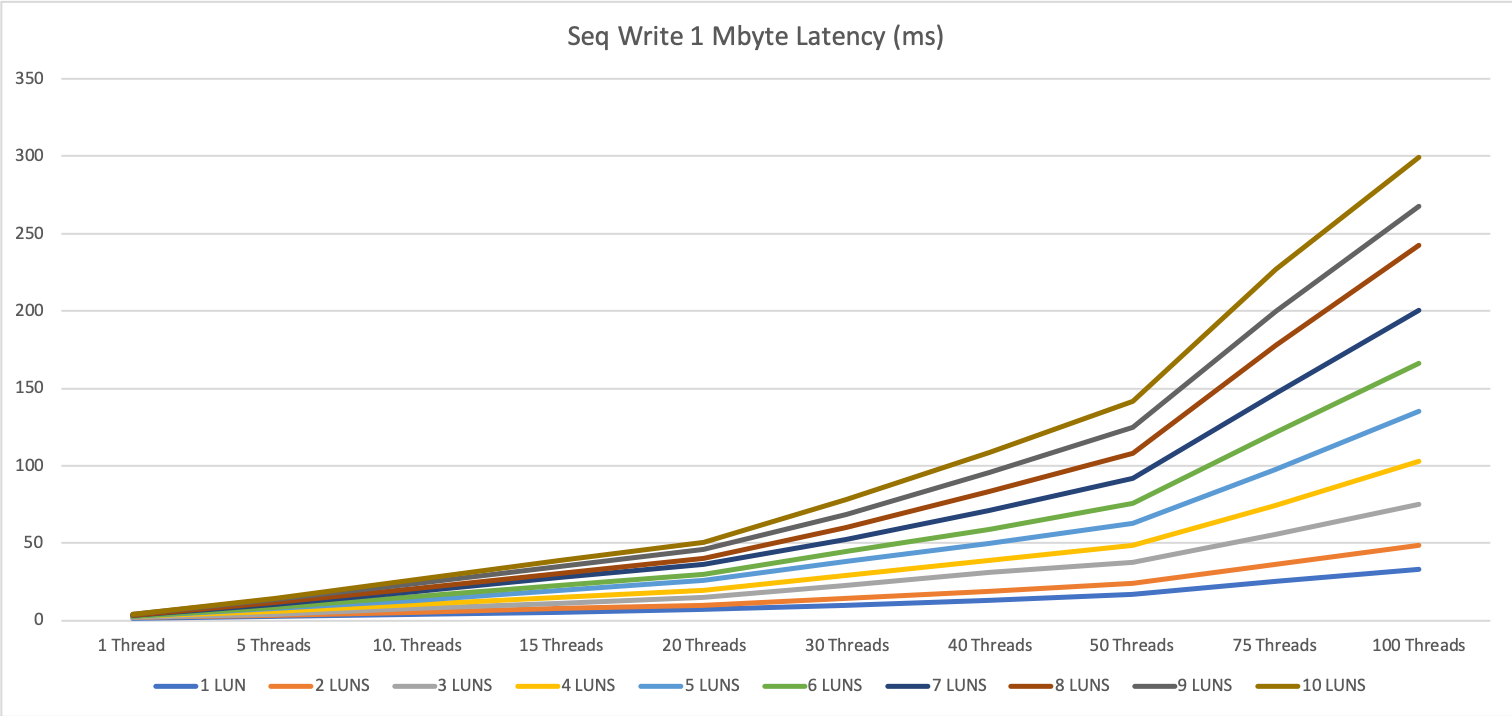
On the 1 MByte tests, we see, that we already hit the max speed with 6 devices (parallelity of 6) to 9 devices (parallelity 2).
As an example to interpret the graphic, when you have a look at the green line (6 devices), we reach the peak performance at a parallelity of 6.
For the dark blue line (7 devices) we hit the max peak at parallelity 4 and so on.
If we increase the parallelity over this point, the latency will grow or even the throughput will decrease.
For the 1 MByte tests, we hit a limitation at around 6280 IOPS. This is around 90% of the calculated maximum speed.
So if we go with Oracle ASM, we should bundle at least 5 devices together to a diskgroup.
We also see, that when we run a rebalance diskgroup we should go for a small rebalance power. A value smaller than 4 should be chosen, every value over 8 is counterproductive and will consume all possible I/O on your system and slow all databases on this server.


Monitoring / Verification
To verify the results, I am using dbms_io_calibration on the very same devices as the performance test was running. The expectation is, that we will see more or less the same results.
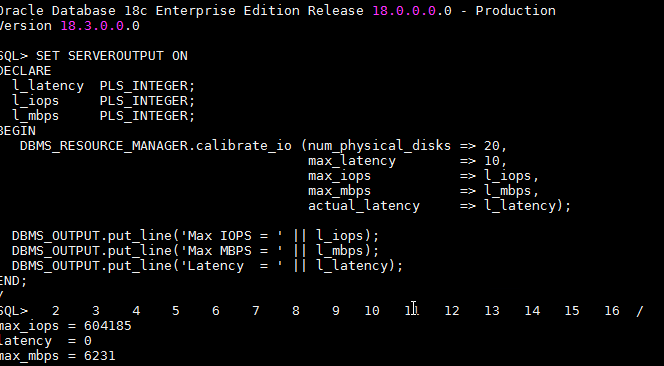
On large IO the measured 6231 IOPS by IO calibration is almost the same as measured by FIO (+/- 1%).
IO calibration measured 604K IOPS for small IO, which is significantly more than the +/- 340kw IOPS measured with FIO. This is explainable because IO calibration is working with the number of disks for the parallelity and I did this test with 20 disks instead. of 10. Sadly when I realized my mistake, I already had no more access to the system.
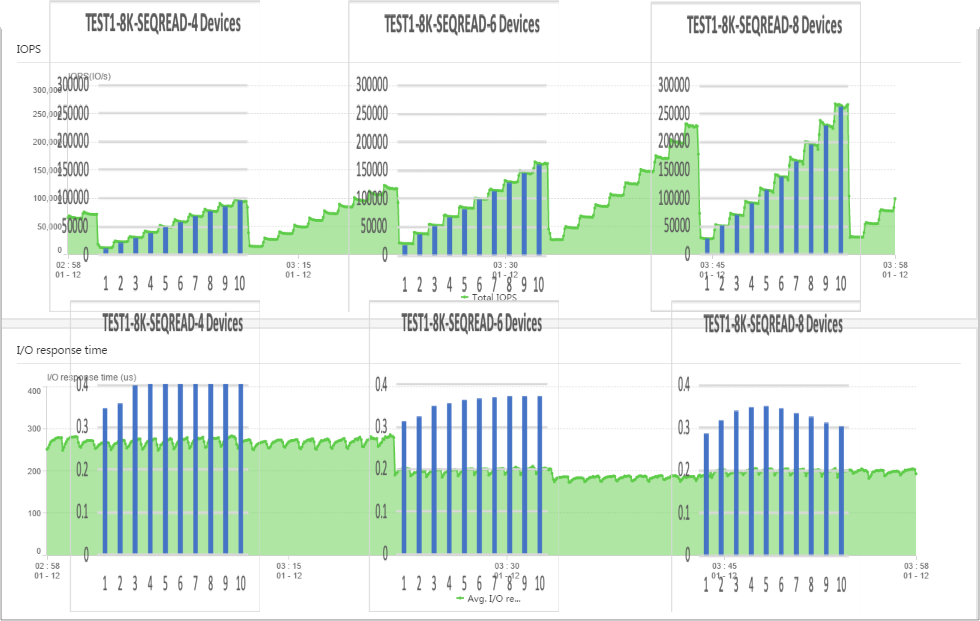
In the following pictures you see the performance view of the storage system with the data measured by FIO as an overlay. As we can see, the values for the IOPS matches perfectly.
The value for latency was lower on the storage part, which is explainable with the different points where we are measuring (once on the storage side, once on the server side).
All print screens of the live performance view of the storage can be found in the git repository. The values for Queue depth, throughput, and IOPS matched perfectly with the measured results.
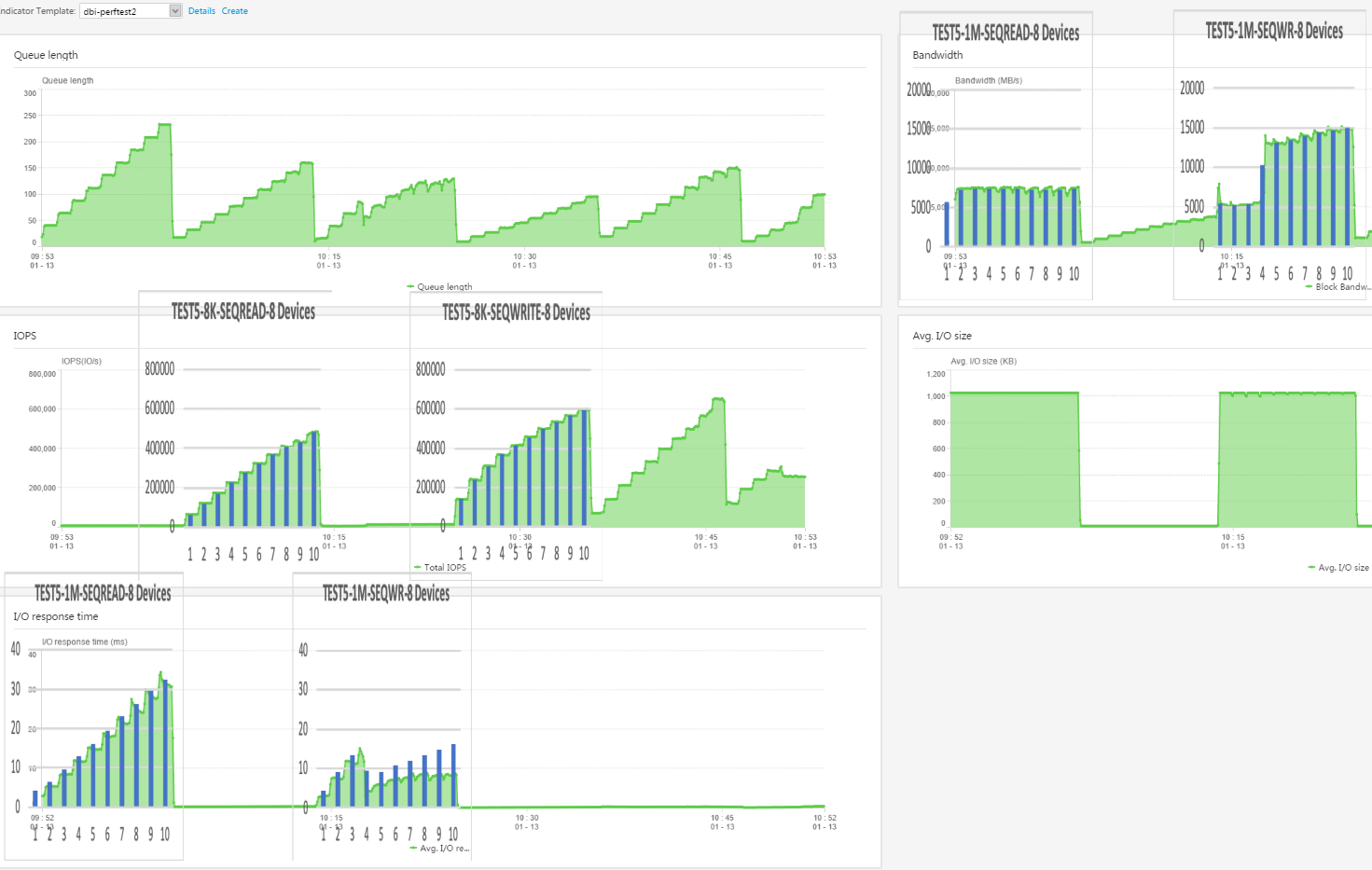
Multi-Server Results with compression
General
The tests for compressed and uncompressed devices were made with 3 parallel servers.
8 KByte block size
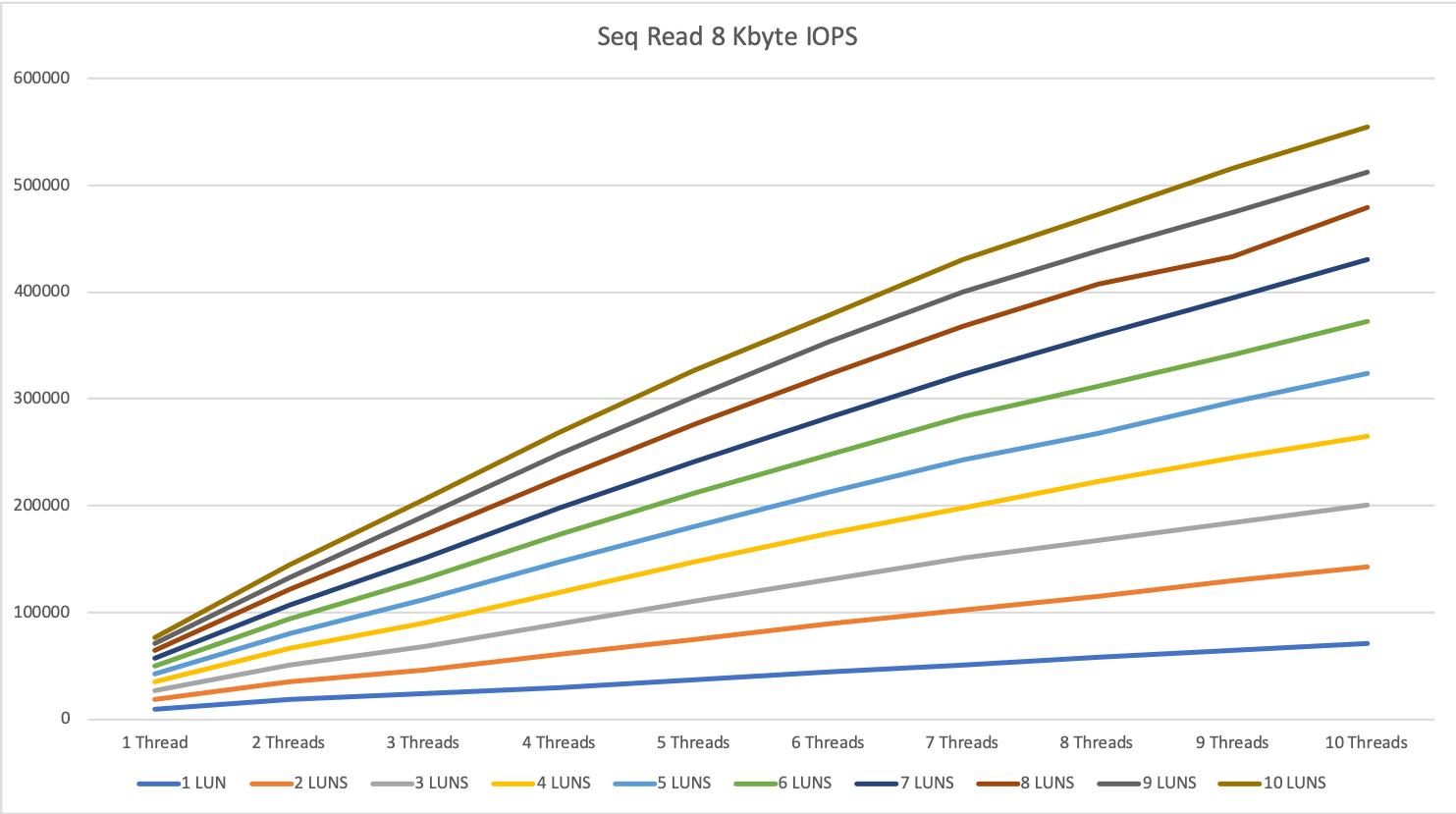
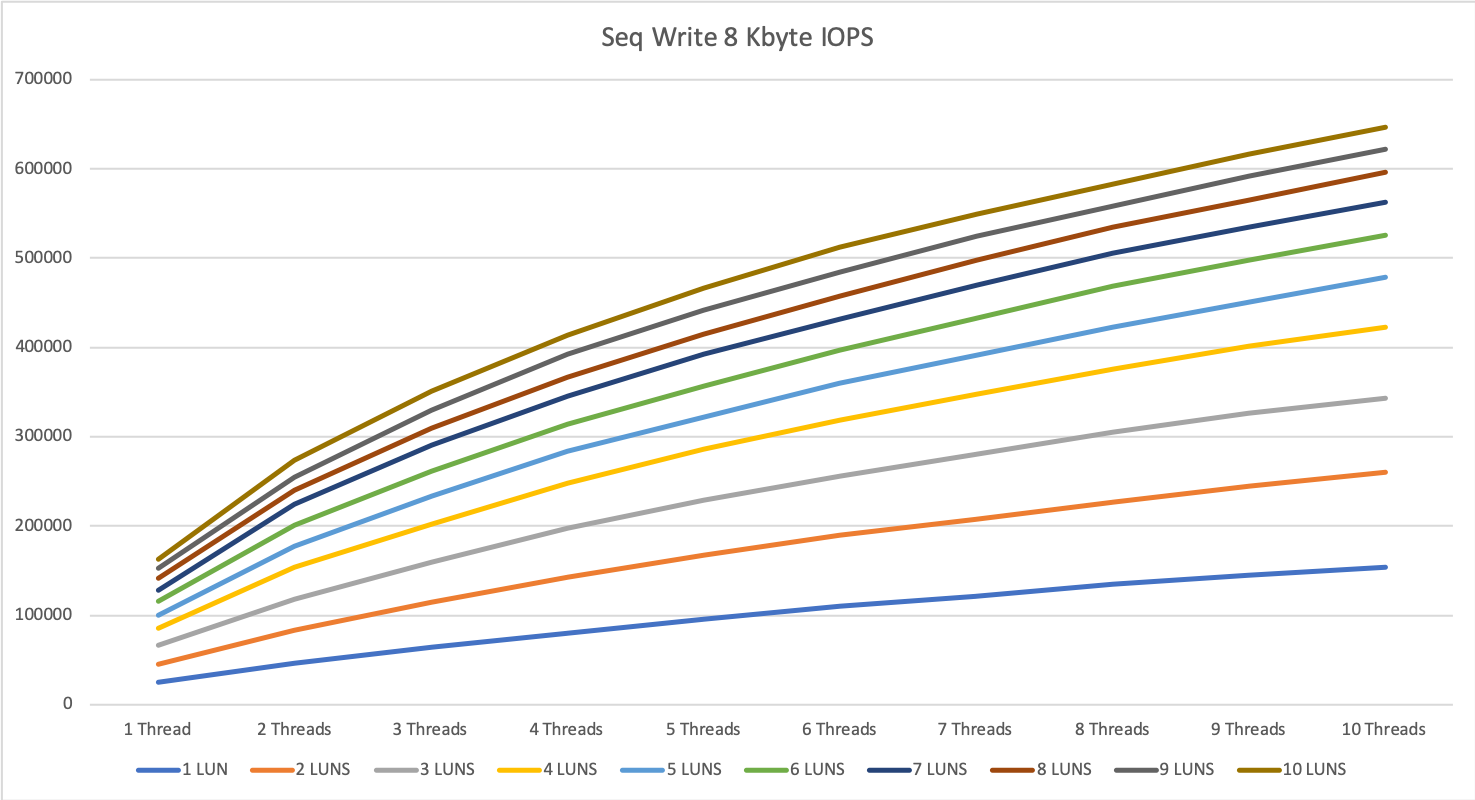
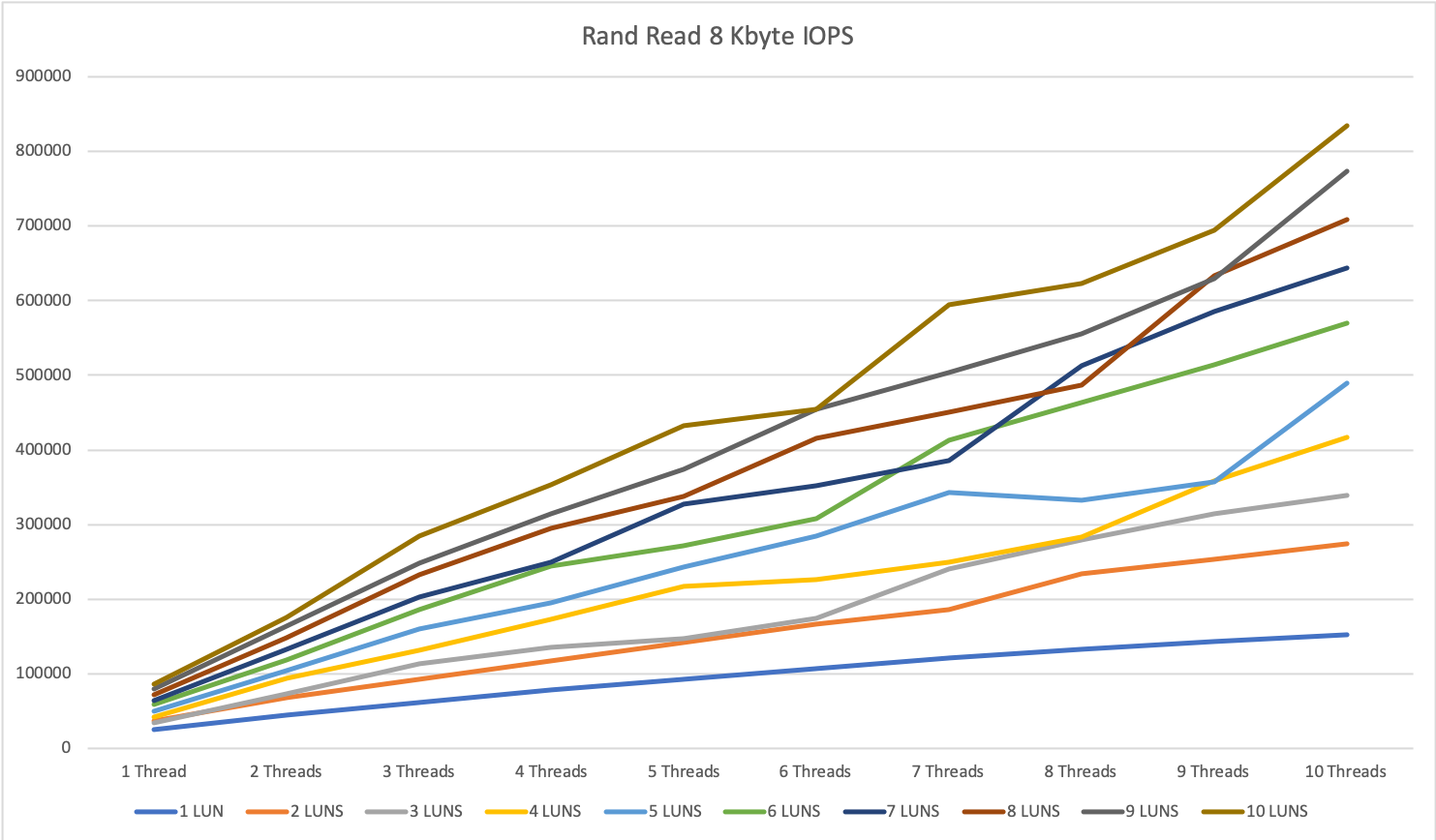
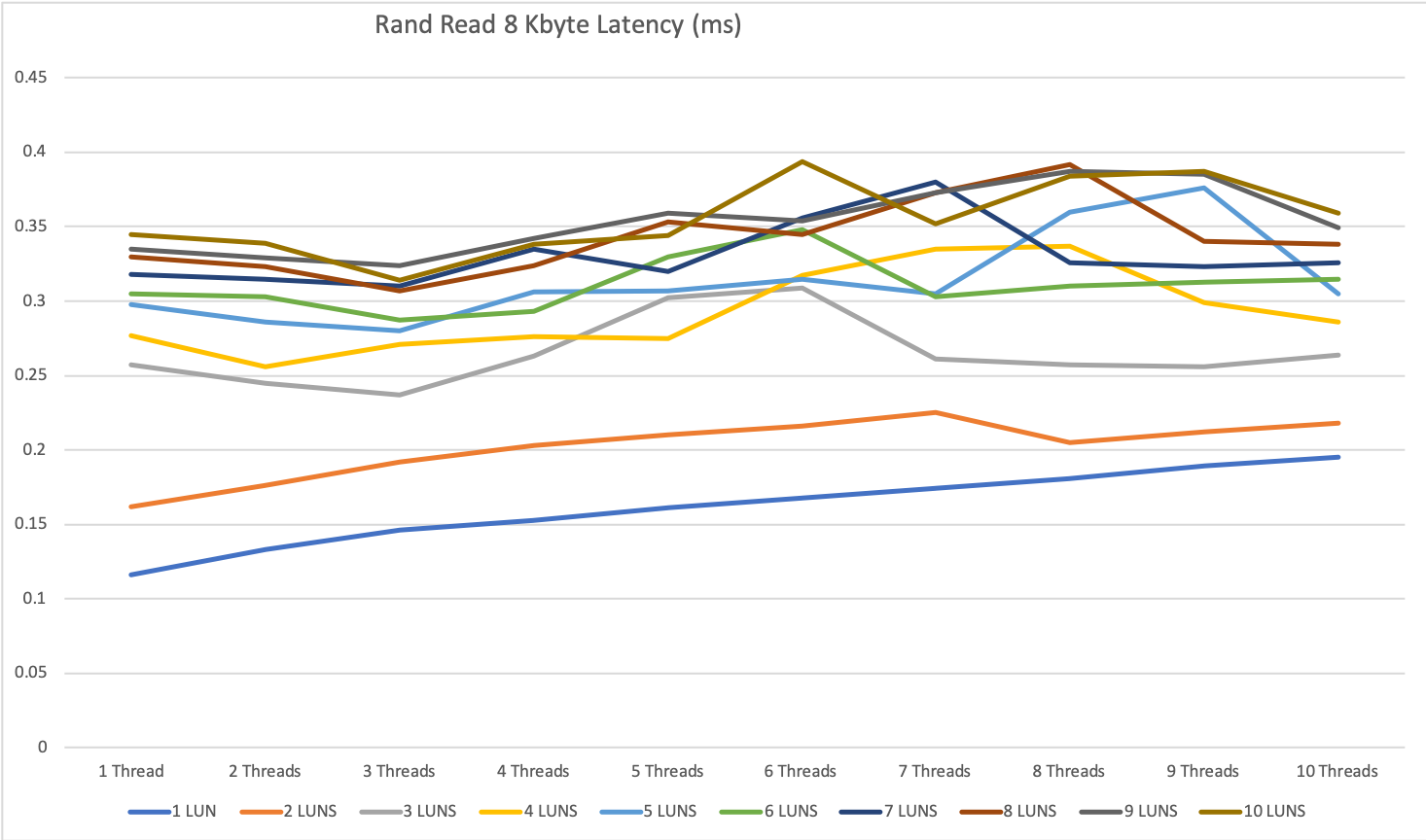
For random read with 8 KByte blocks, the IOPS increased almost linear from 1 to 3 nodes and we hit a peak of 655’000 IOPS with 10 devices / 10 threads. The answer time was between 0.3 and 0.45 ms.
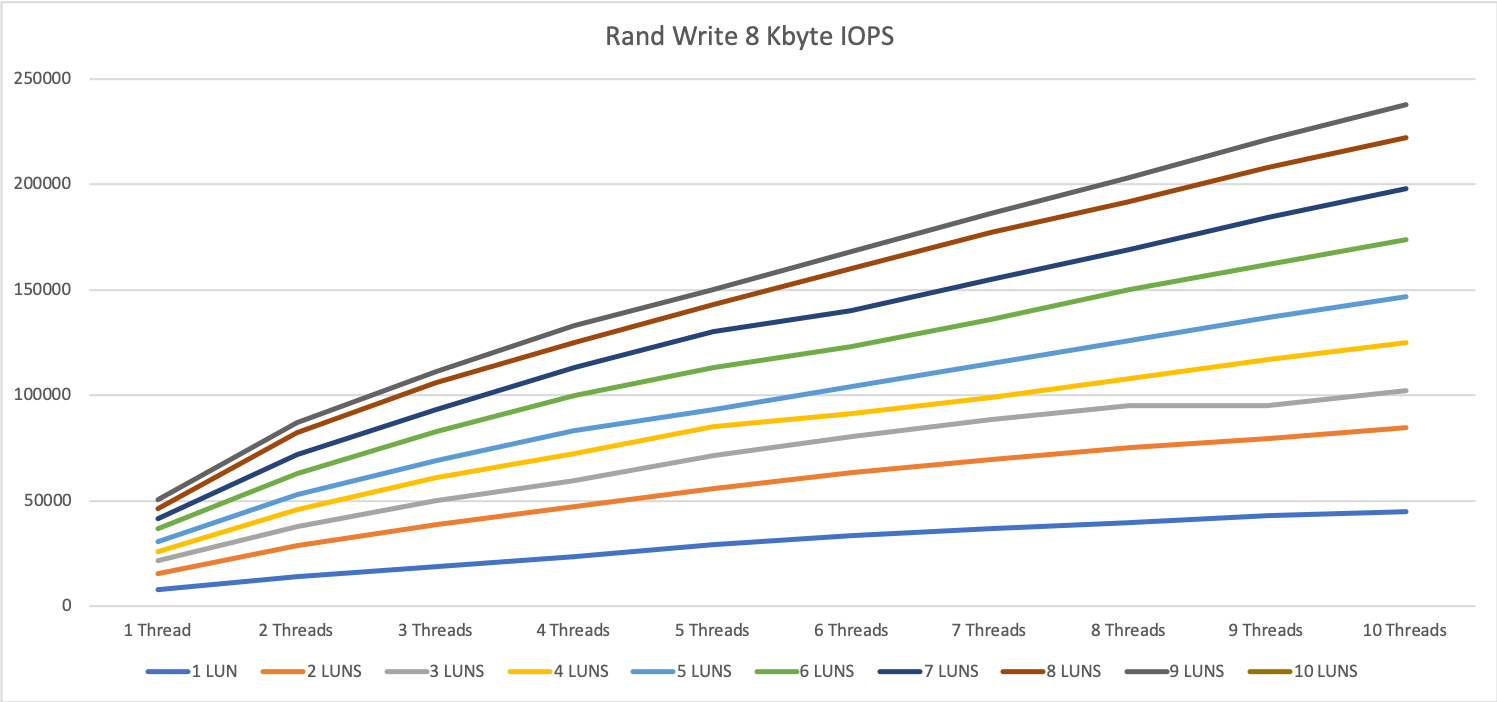
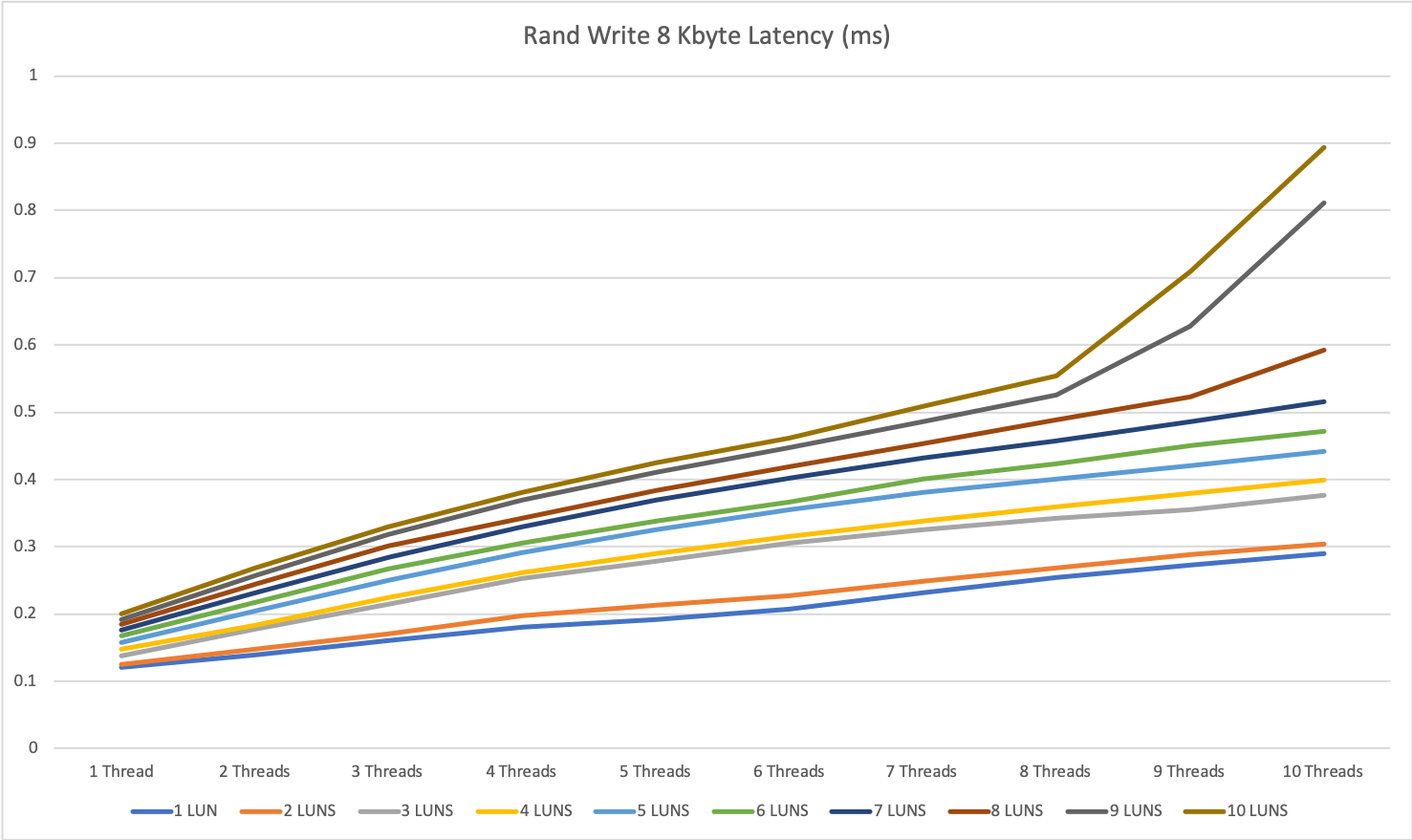
For random write, we hit some kind of limitation at around 250k IOPS. We could not get a higher value than that which was kind of surprising for me. I would have expected better results here.
From the point, where we hit the maximum number of IOPS we see the same behavior as with 1 MByte blocks: More threads does only increase the answer time but does not get you better performance.
So for random write with 8 KByte blocks, the maximum numbers are around 3 devices and 10 threads or 10 devices and 3 threads or a parallelity of 30.
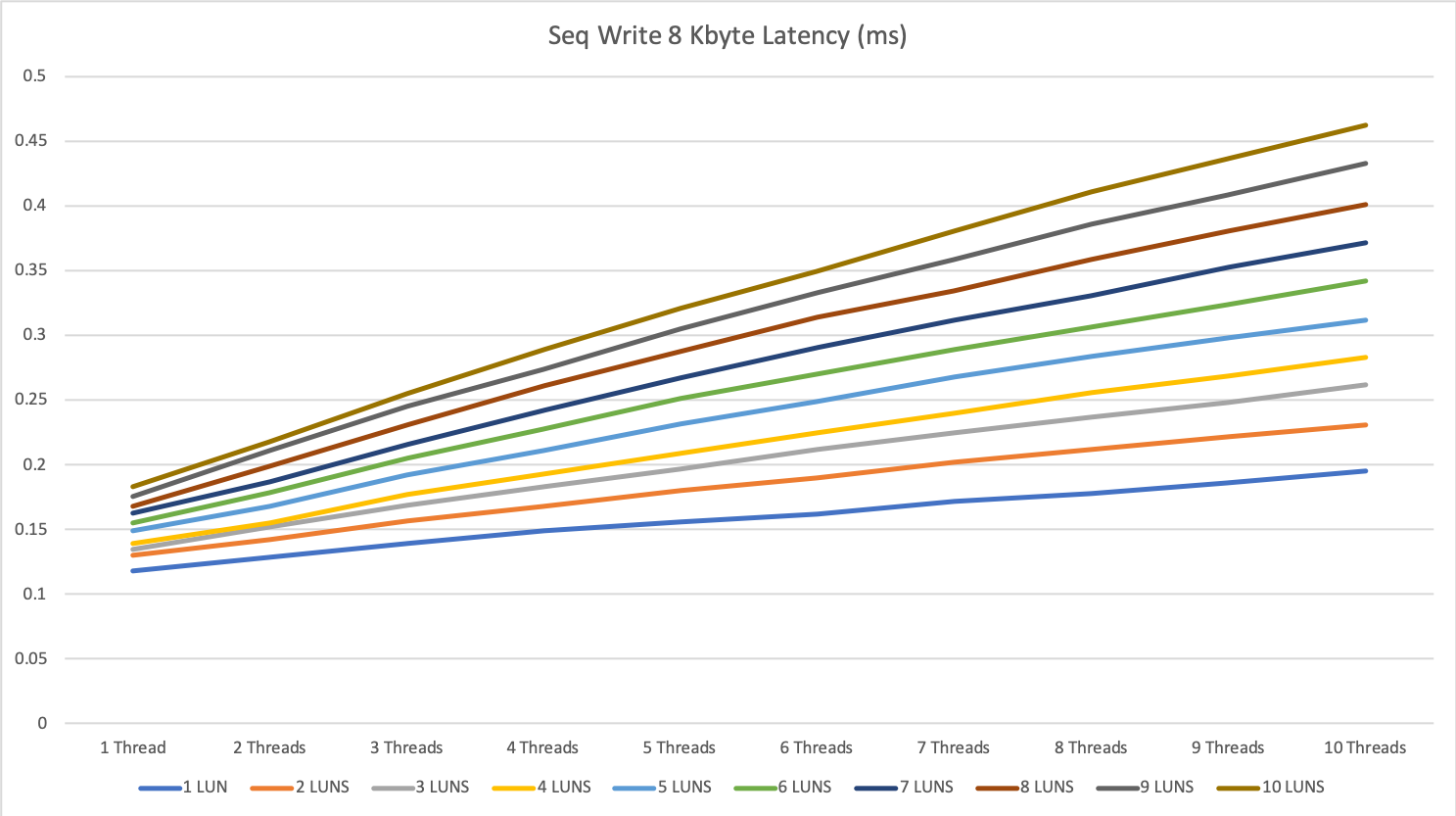
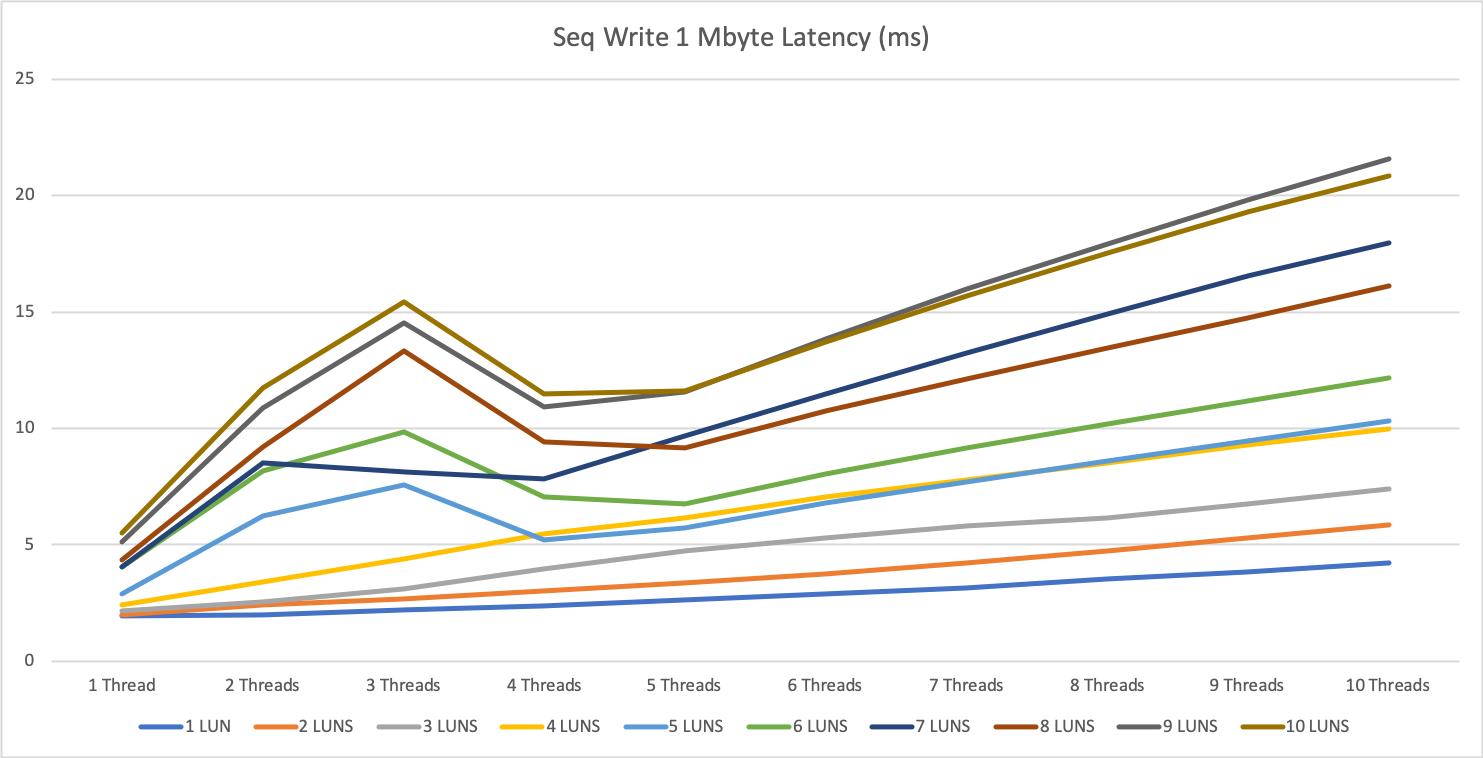
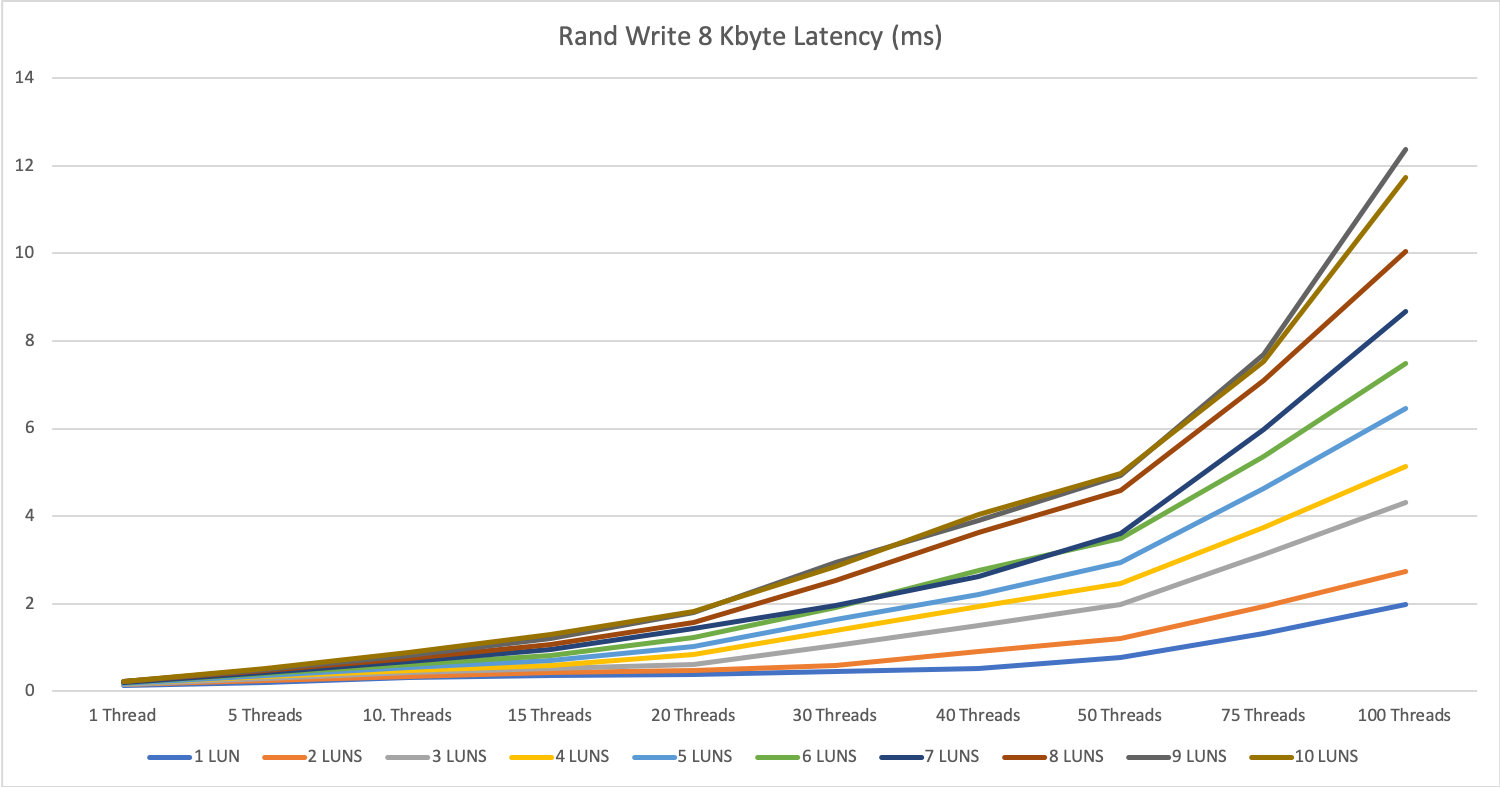
As long as we stay under this limit we see answer times between 0.15 and 0.5ms, over this limit the answer times can increase <10ms.


1 MByte block size
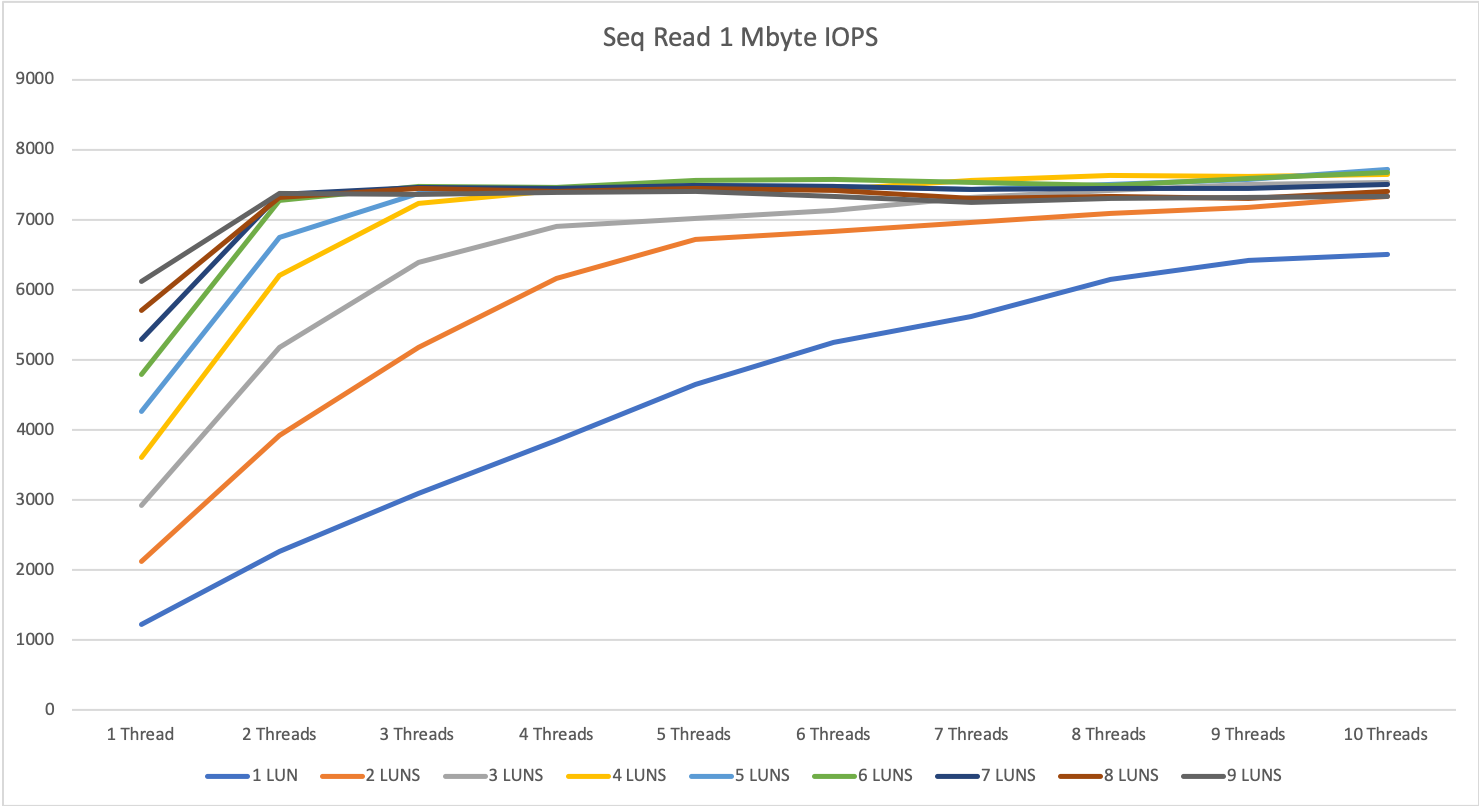
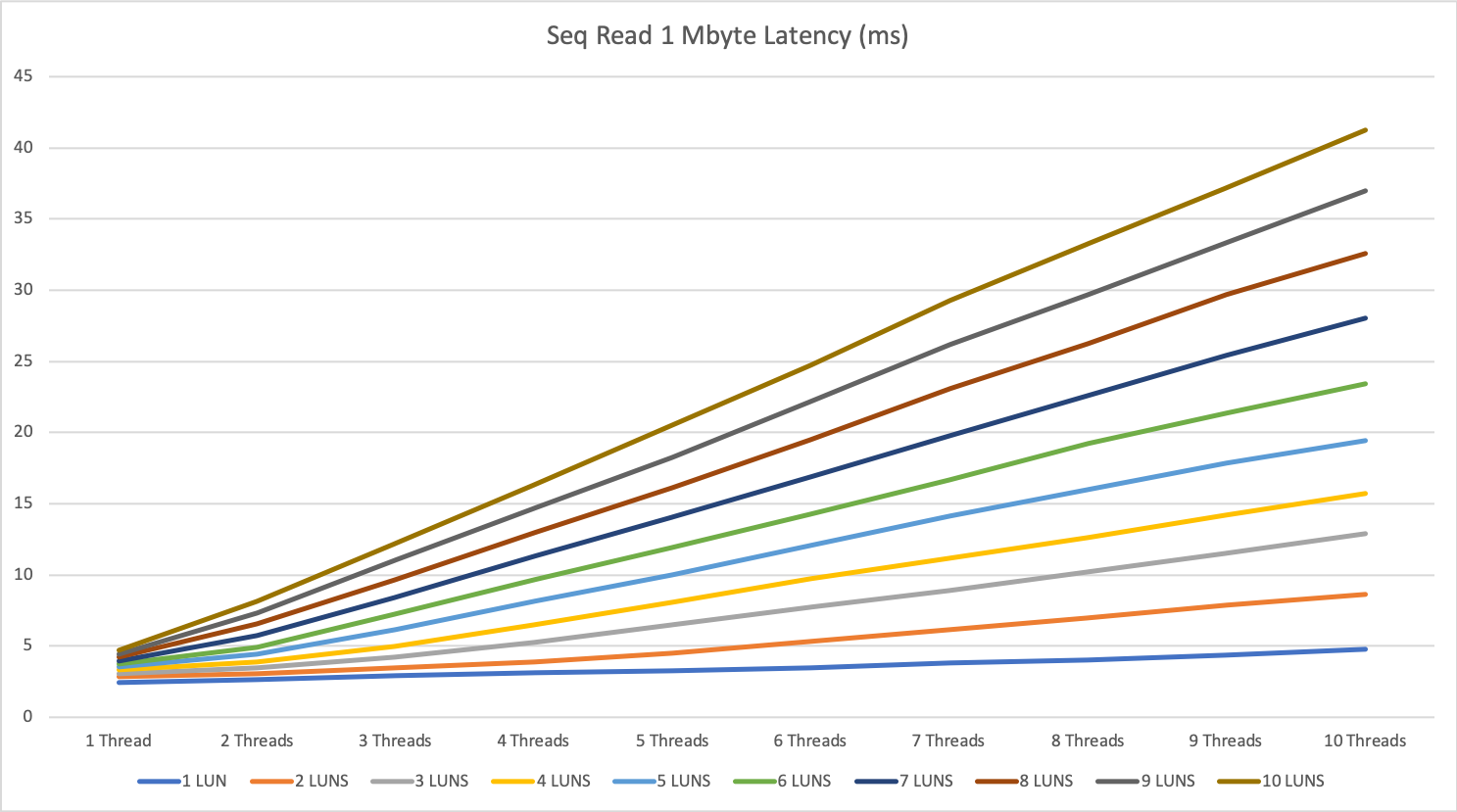
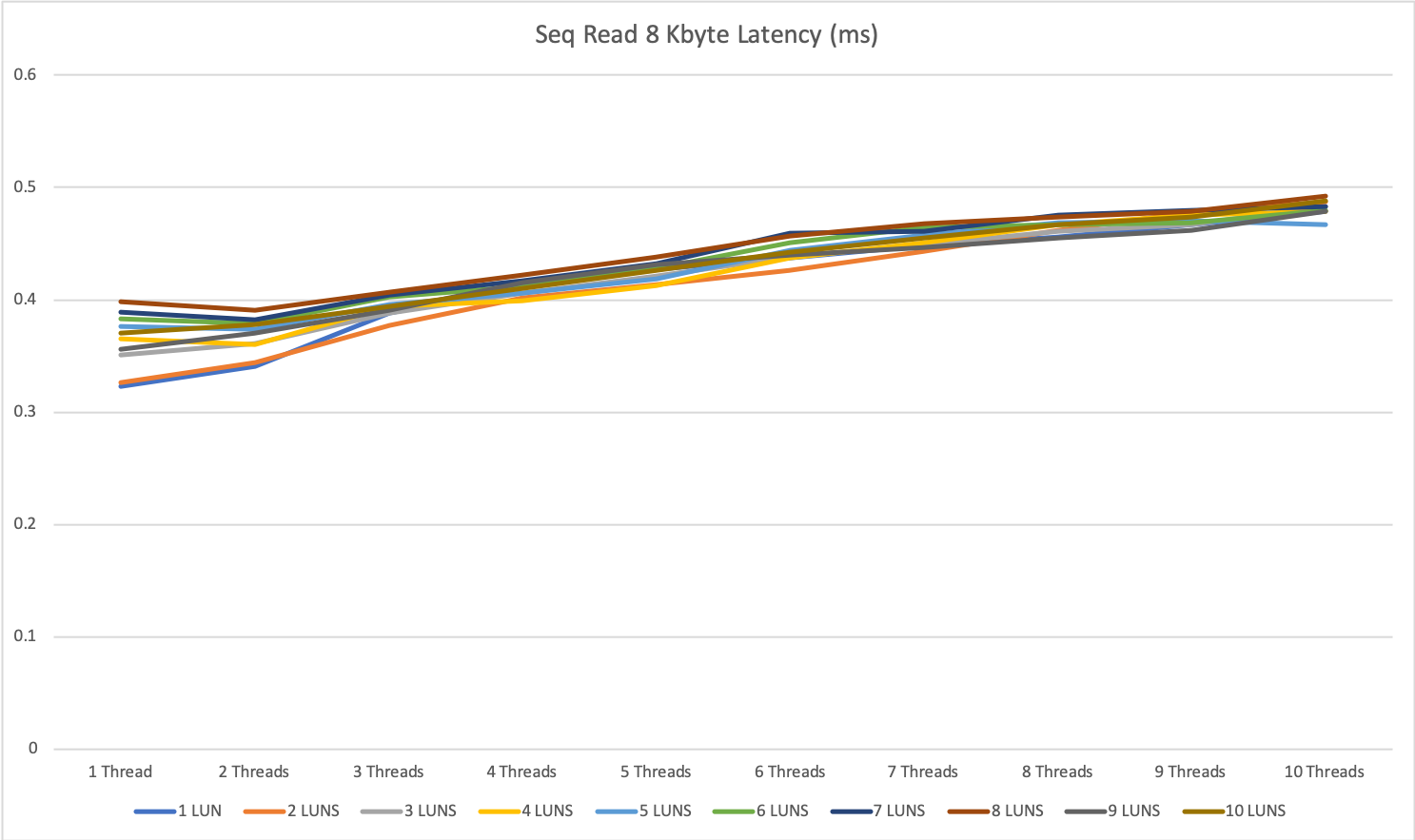
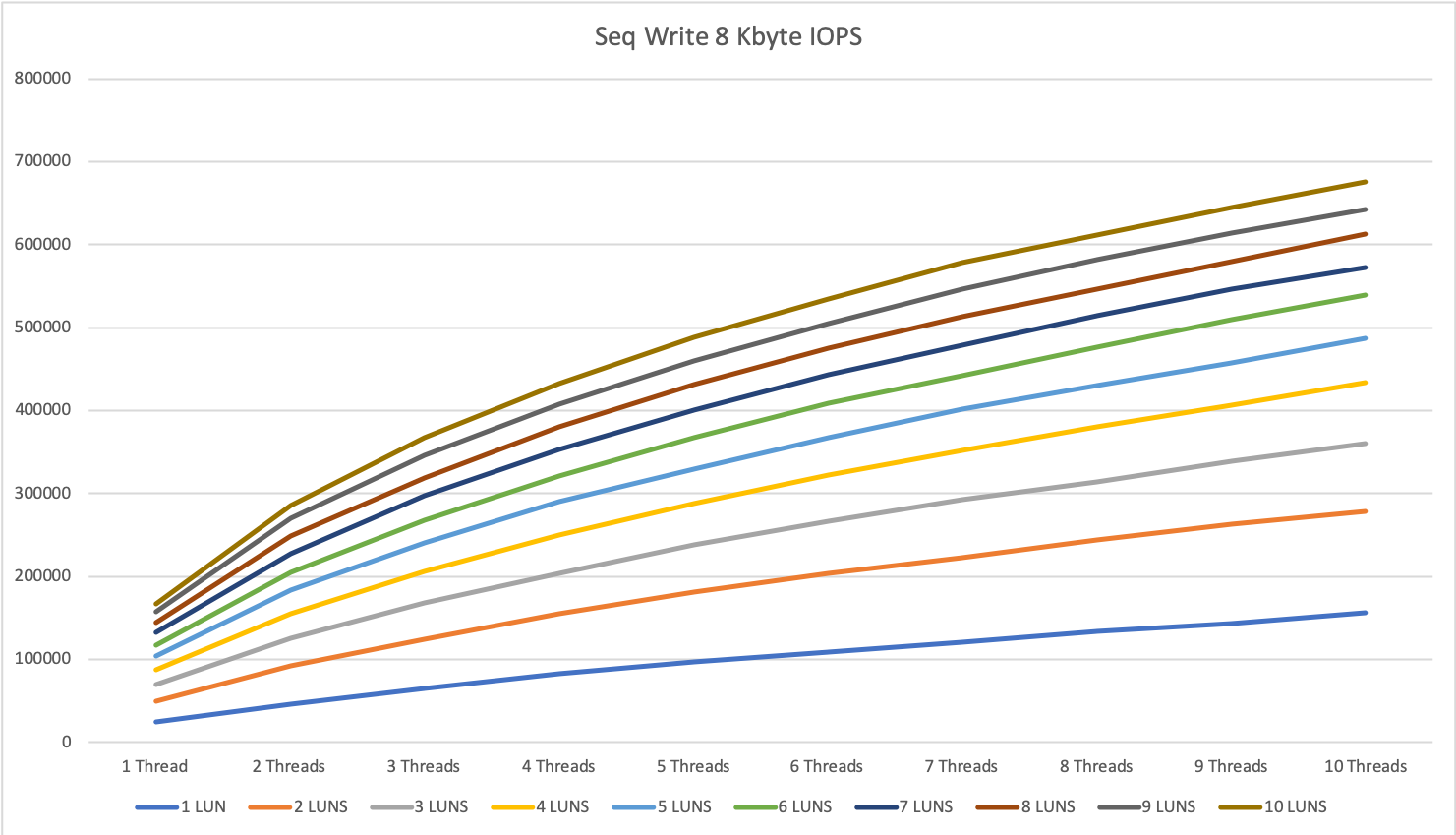
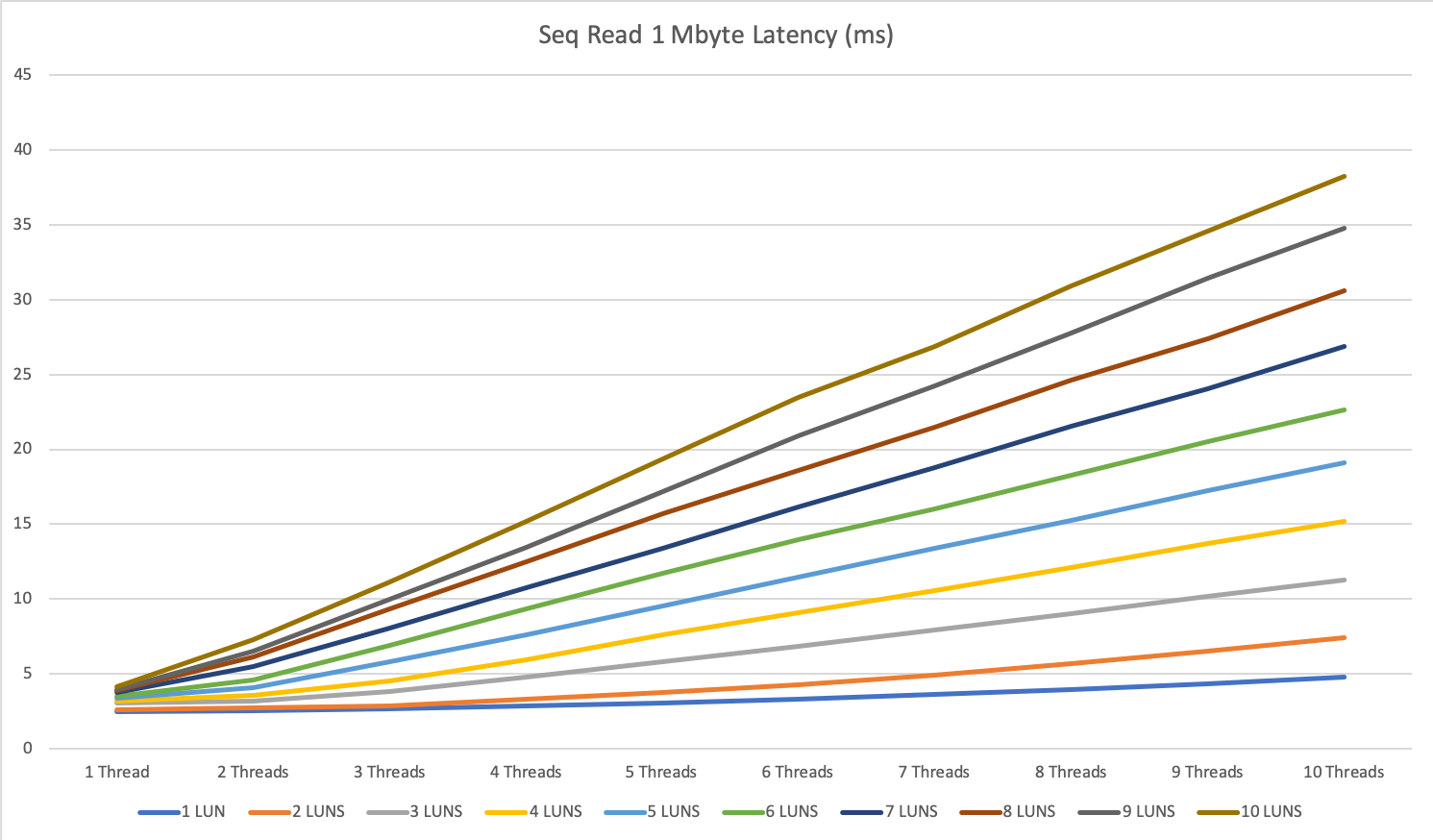
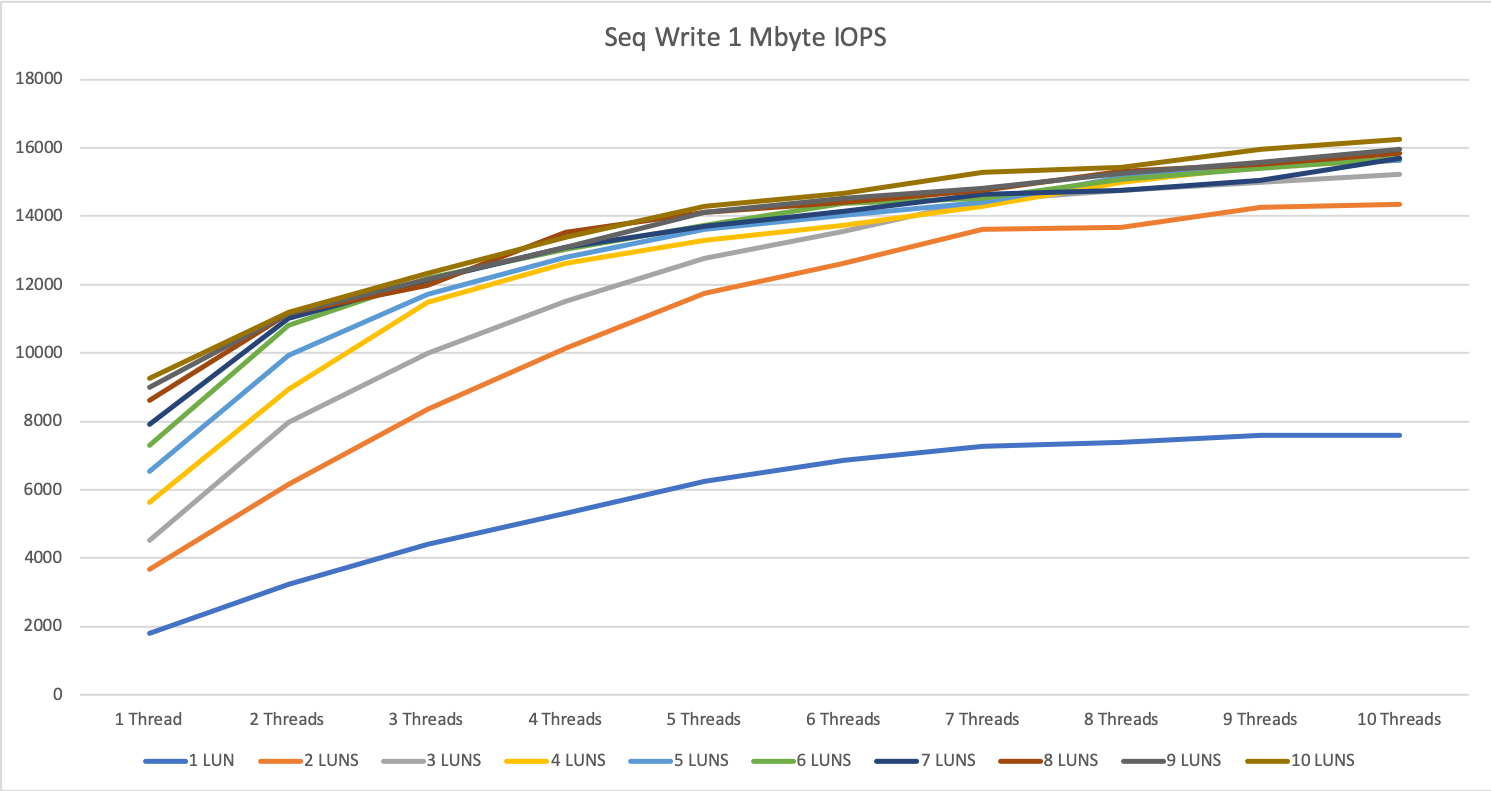
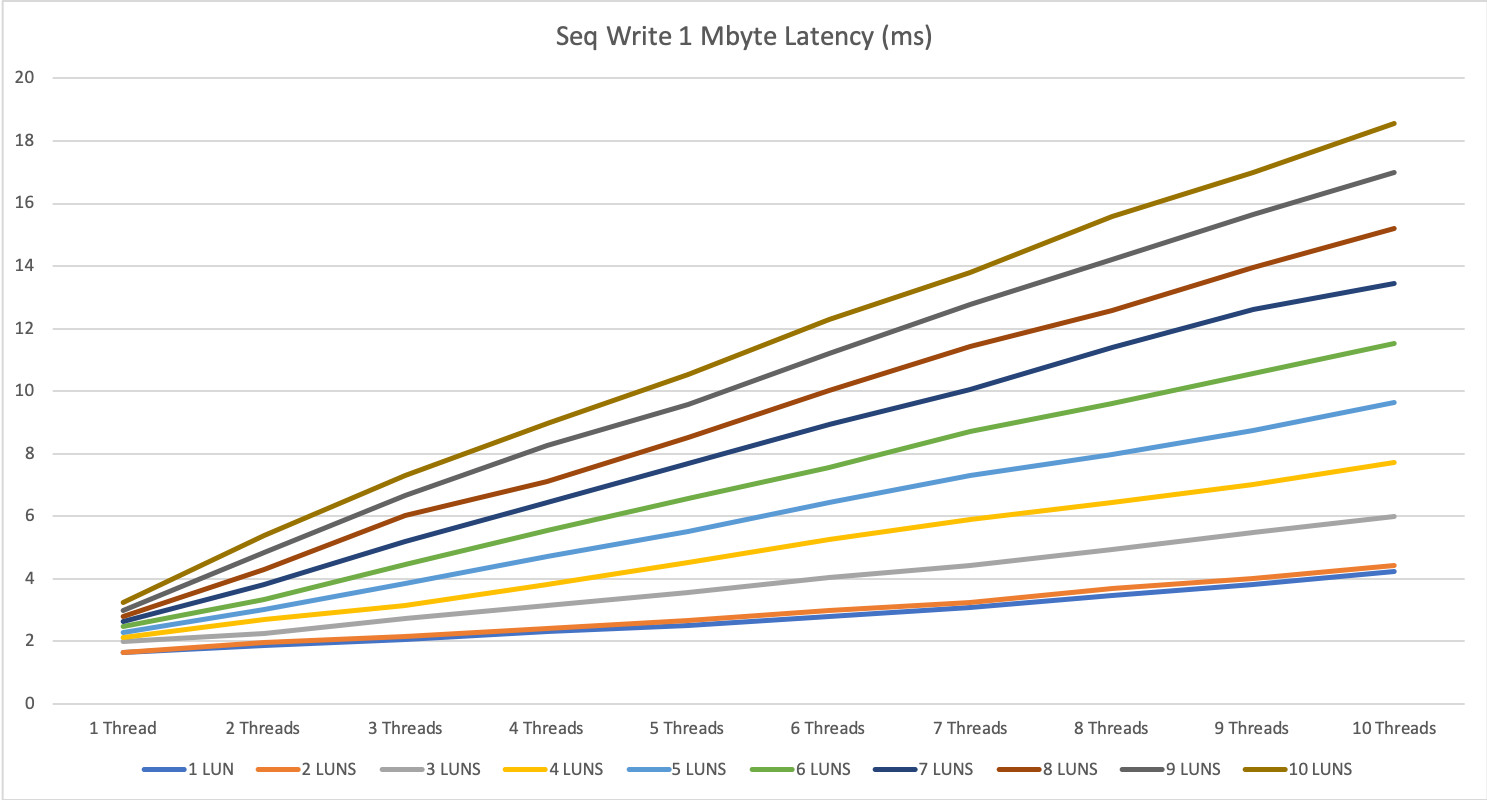
The multi-server tests show some interesting behavior with large reads on this storage system.
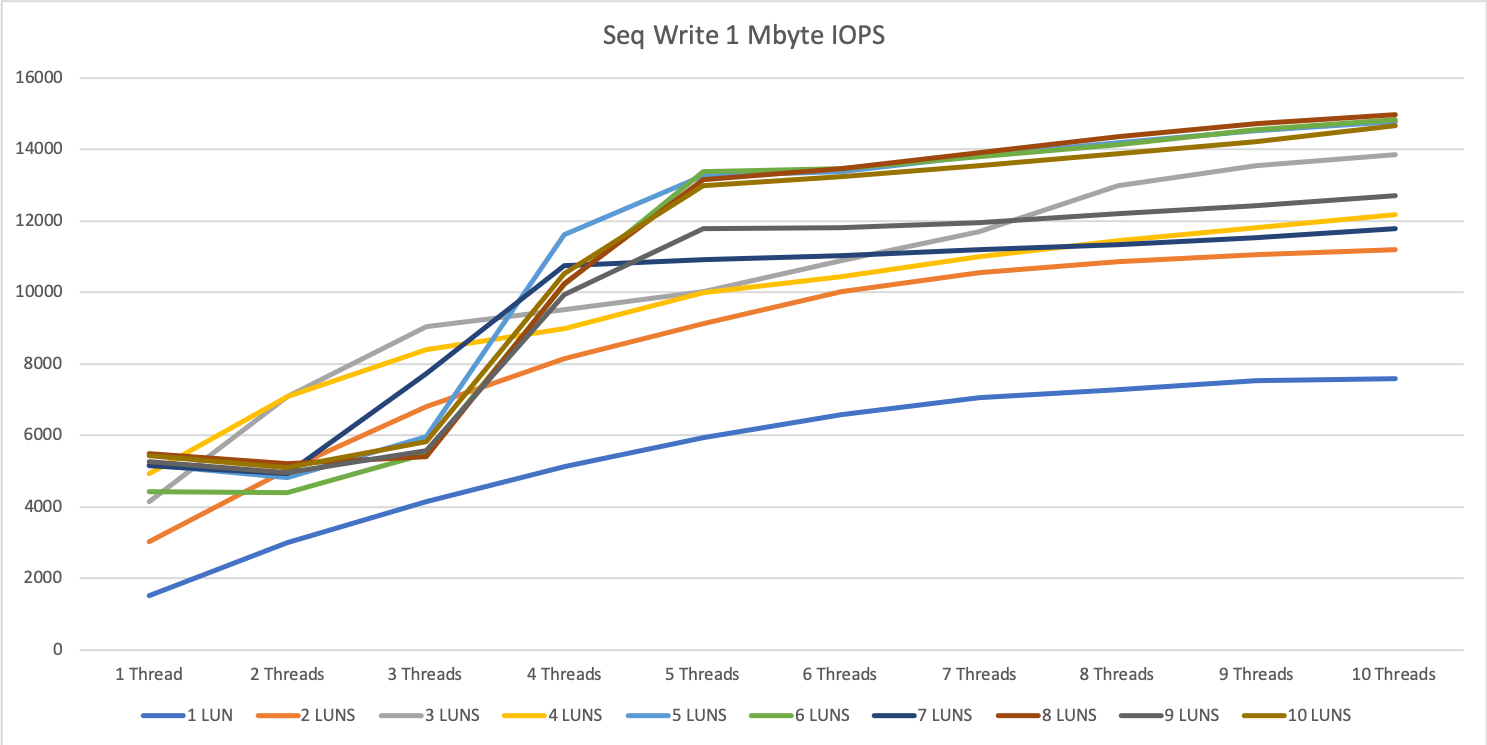
We hit a limitation at around 7500 to 7800 IOPS per second. For sequential write, we could achieve almost double this result with up to 14.5k IOPS.
Of course, I discussed all the results with Huawei to see their view on my tests.
The explanation for the way better performance on write then read was, with write we go straight to the 1 TByte big cache, for reading the system had to scratch everything from disk. This Beta-Firmware version did not have any read cache and that’s why the results were lower. All Firmwares starting from the end of February do have also read cache.
I go with this answer and hope to retest it in the future with the newest firmware, still thinking the 7500 IOPS is a little bit low even without read cache.
Multi-Server Results without compression
Comparing the results for compressed devices to uncompressed devices we see an increase of IOPS up to 30% and a decrease of latency at the same level for 8 KByte block size.
For 1 MByte sequential read, the difference was smaller with around 10%, for 1 MByte sequential write we could gain an increase of around 15-20%.




Multi-Server Results with high parallelity
General
Because the tests with 3 servers did no max out the storage on the 8 KByte block size, I decided to do a max test with 4 parallel servers and with a parallelity from 1-100 instead of 1-10.
The steps were 1,5,10,15,20,30,40,50,75 and 100.
These tests were only performed on uncompressed devices.
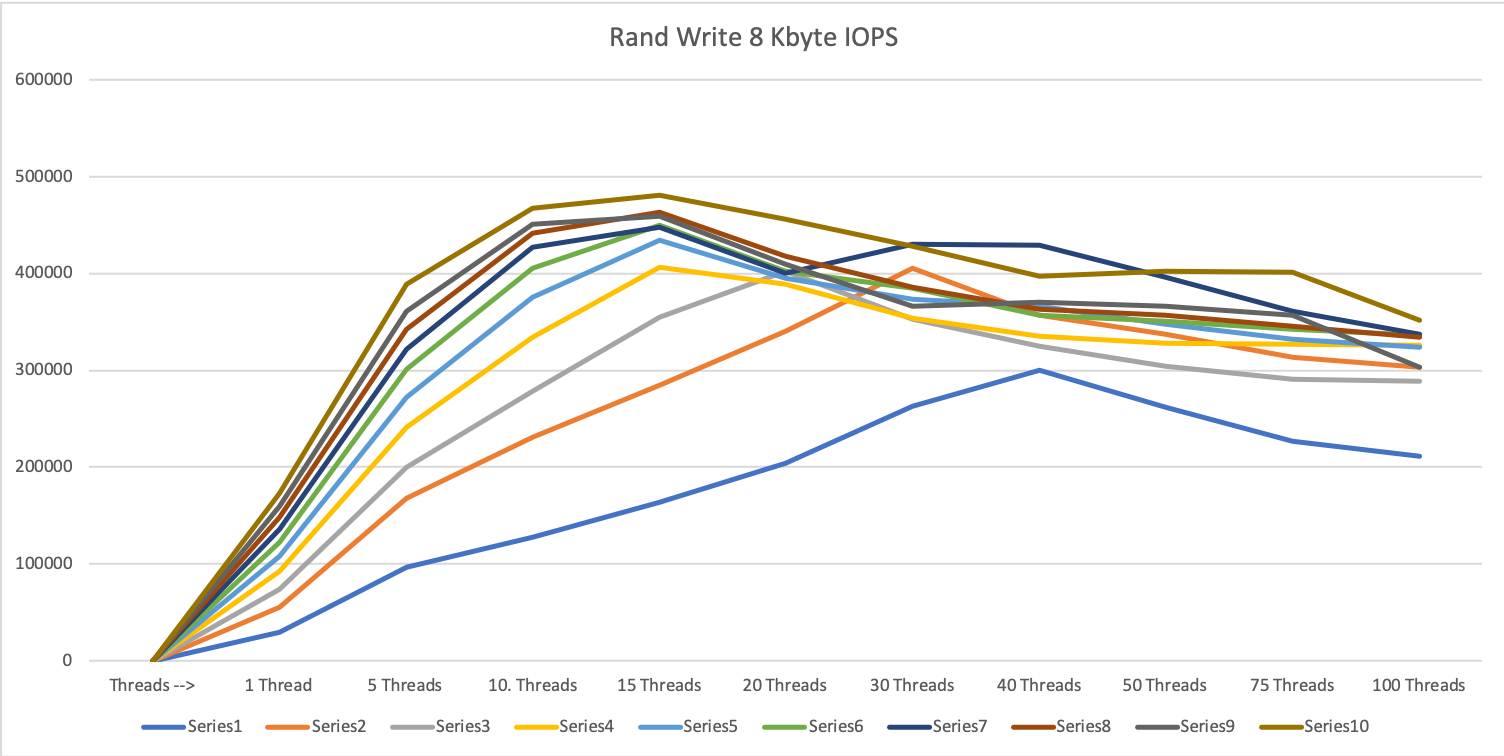
8 KByte block size
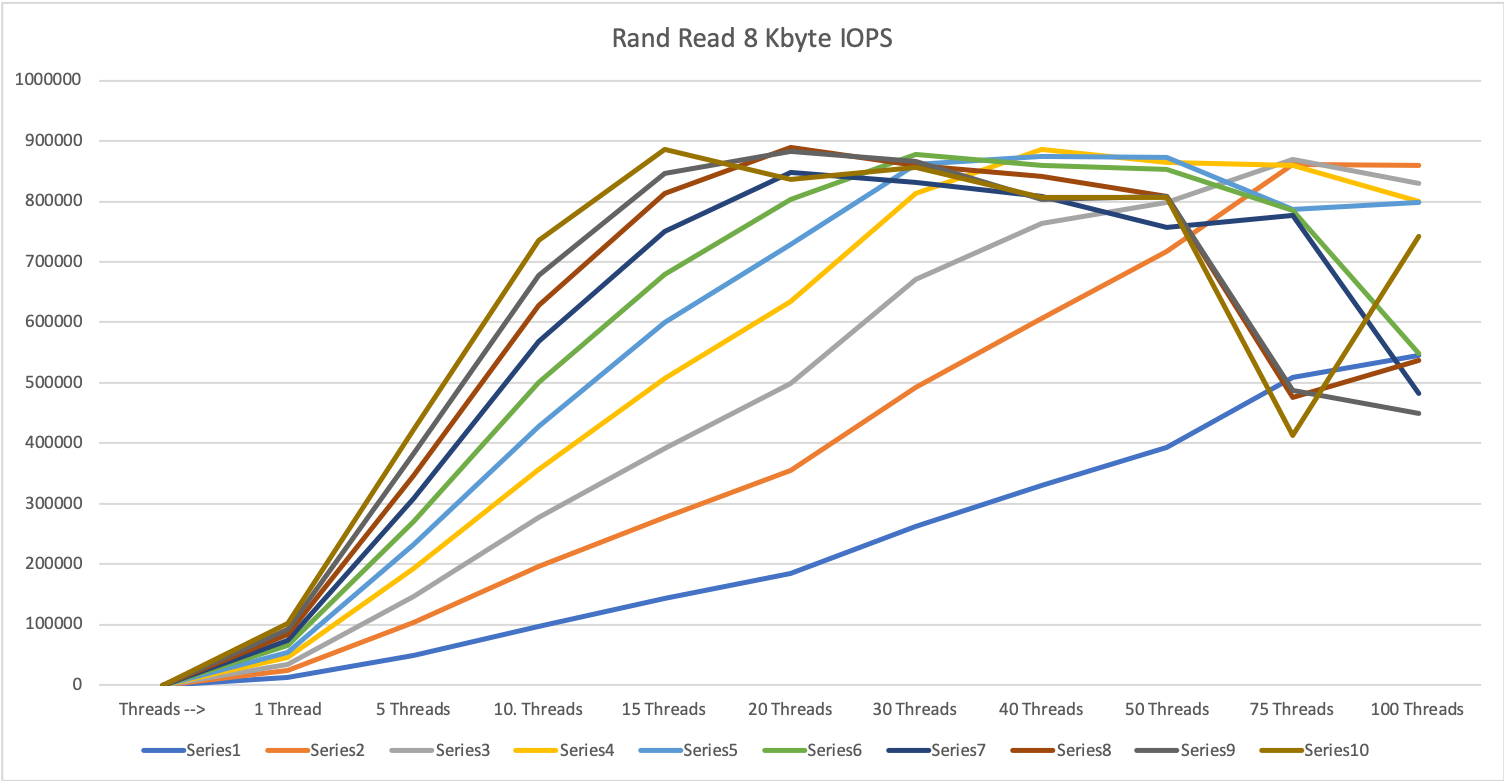
It took 15 threads (per server) with 10 devices: 60 processes in total to reach the peak performance of the Dorado 6000V3 systems.
At this point, we reached 8 KByte random read 940k IOPS @0.637 ms. Remembering the answer, that this Firmware version does not have any read cache, this performance is achieved completely from the SSDs and could theoretically be even better with enabled read cache
If we increase the parallelity further, we see the same effect as with 1 MByte blocks: the answer time is increasing (dramatically) and the throughput is decreasing.
Depending on the number of parallel devices, we need between 60 parallel processes (with 10 devices) up to 300 parallel processes (with 3 parallel devices).

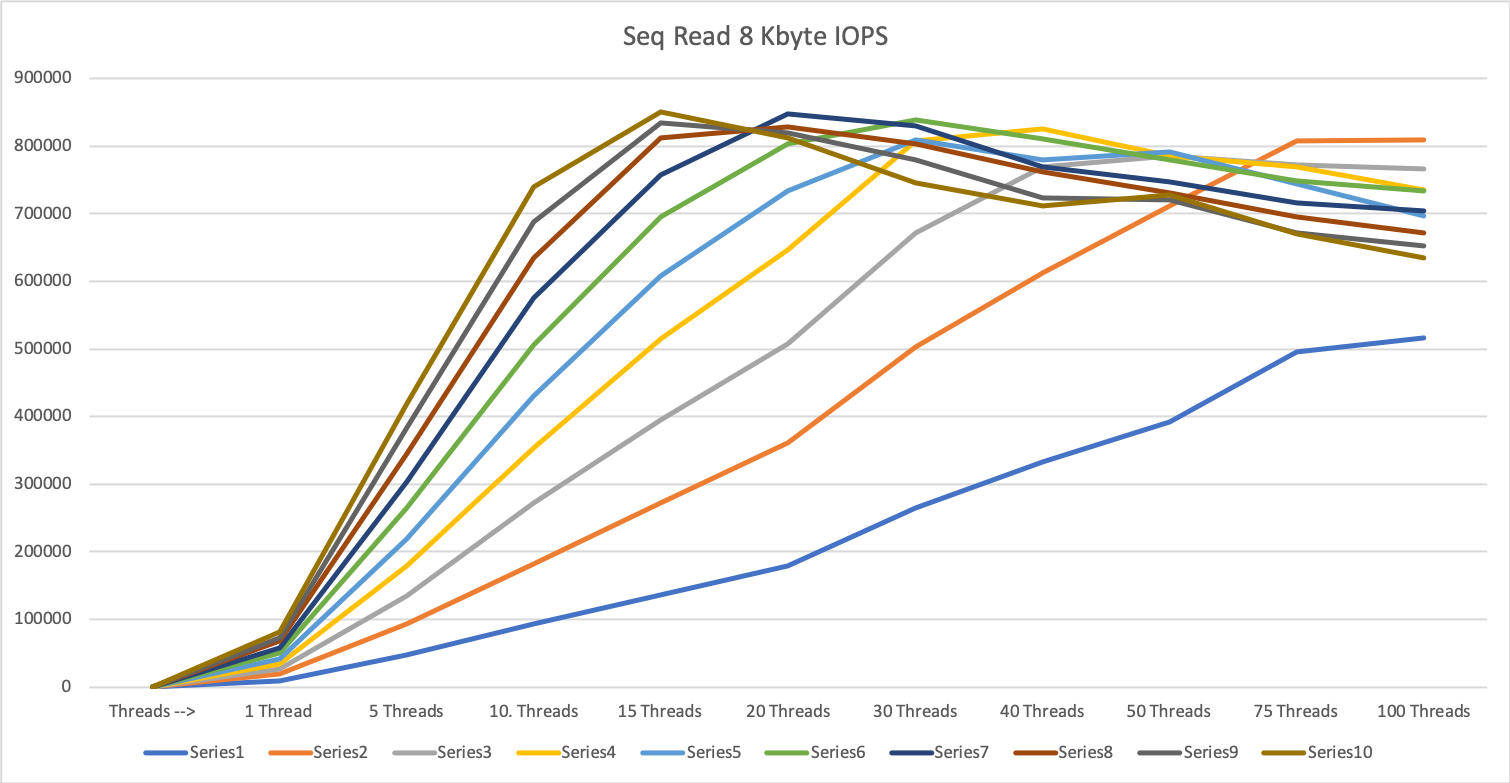

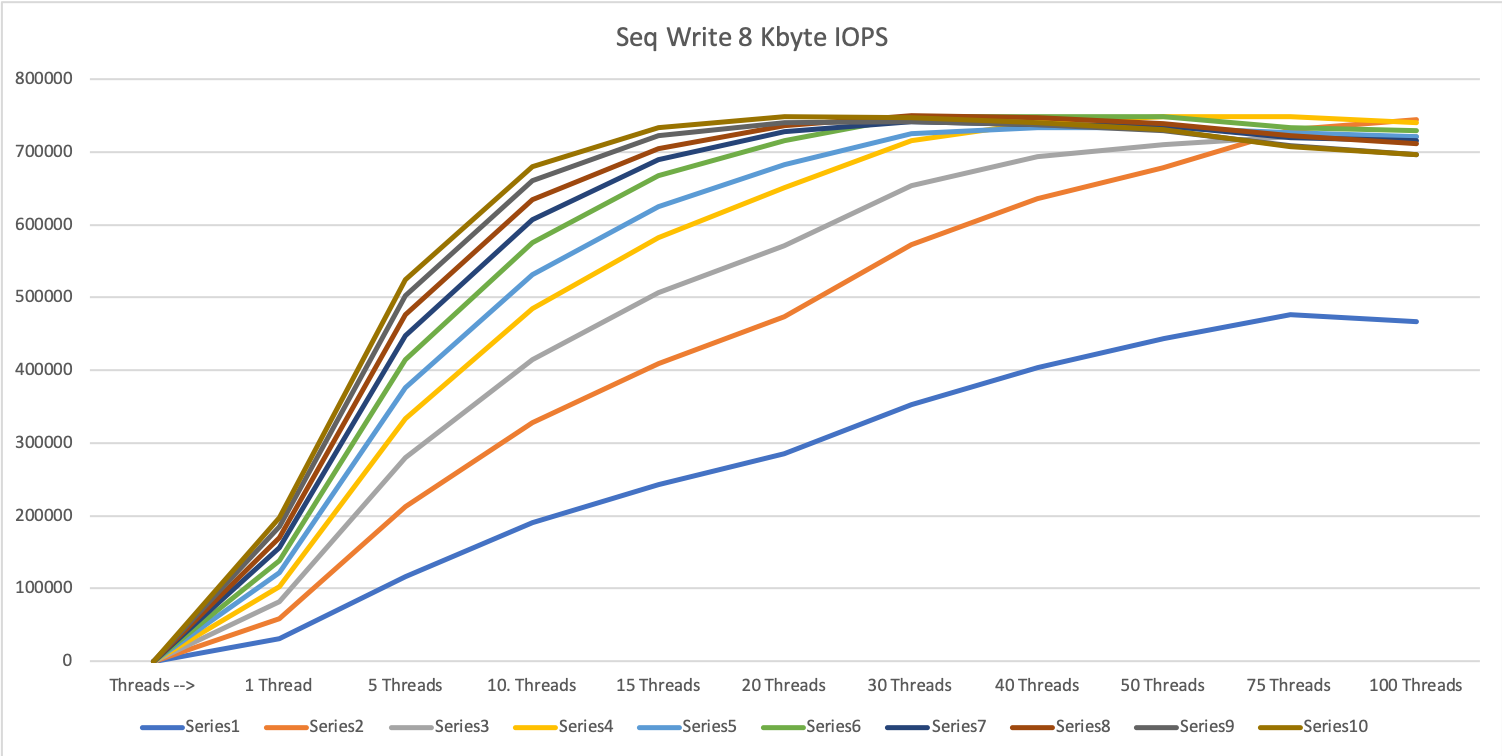
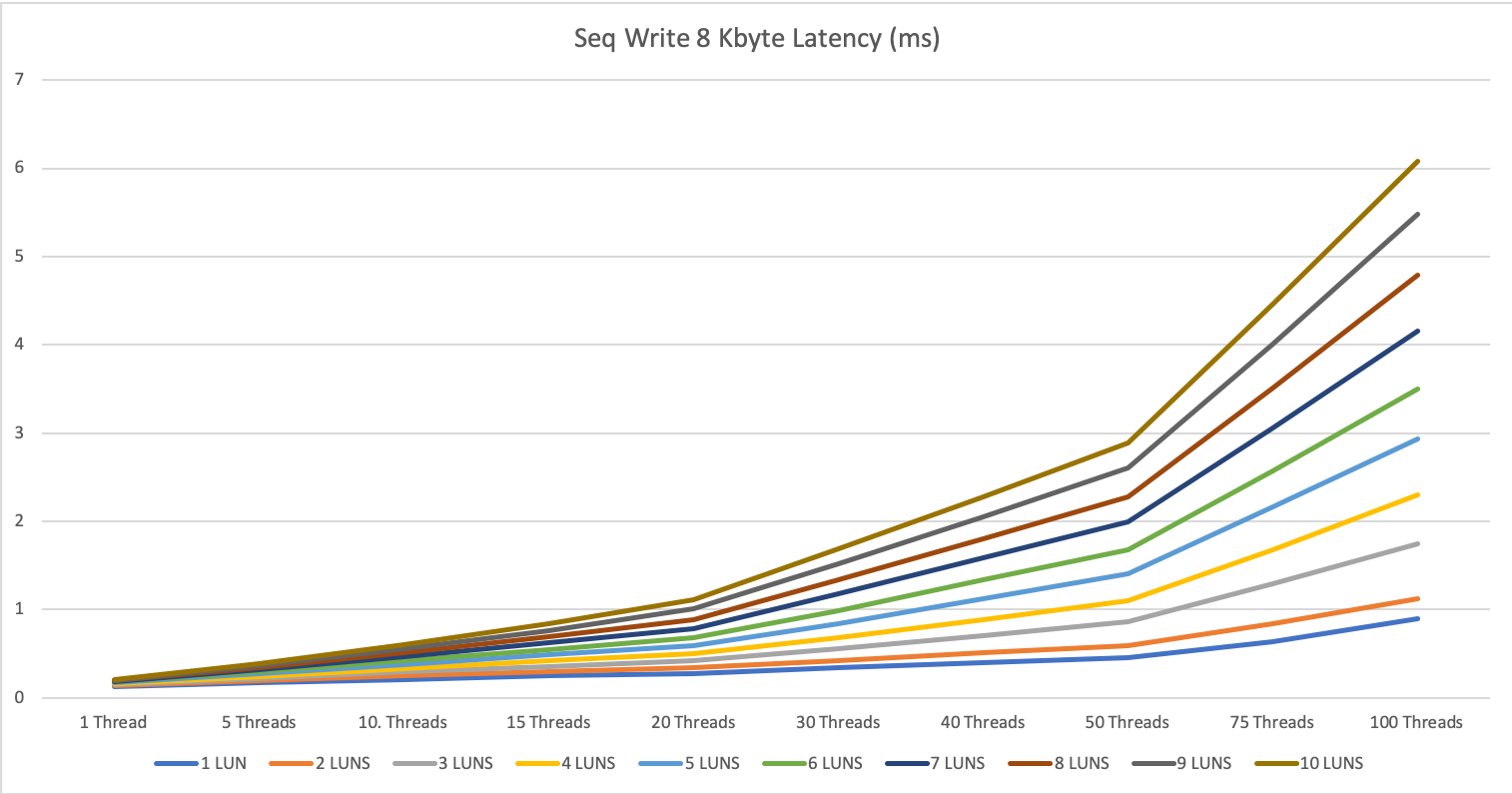
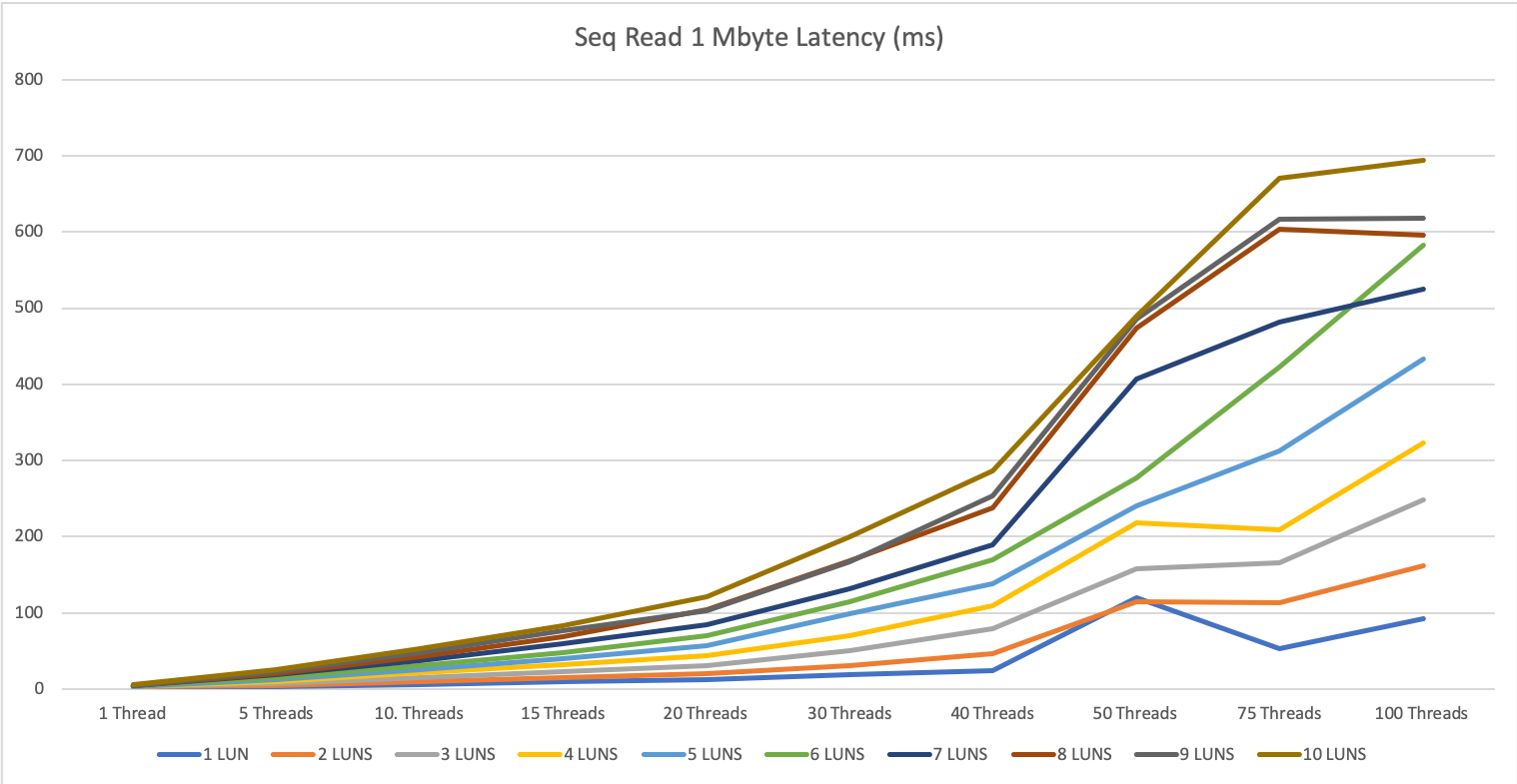
1 MByte block size
For the large IOs, we see the same picture as with 1 or 3 servers. A combined parallelity of 20-30 can max out the storage systems. So be very careful with your large IO tasks not to affect the other operations on the storage system.
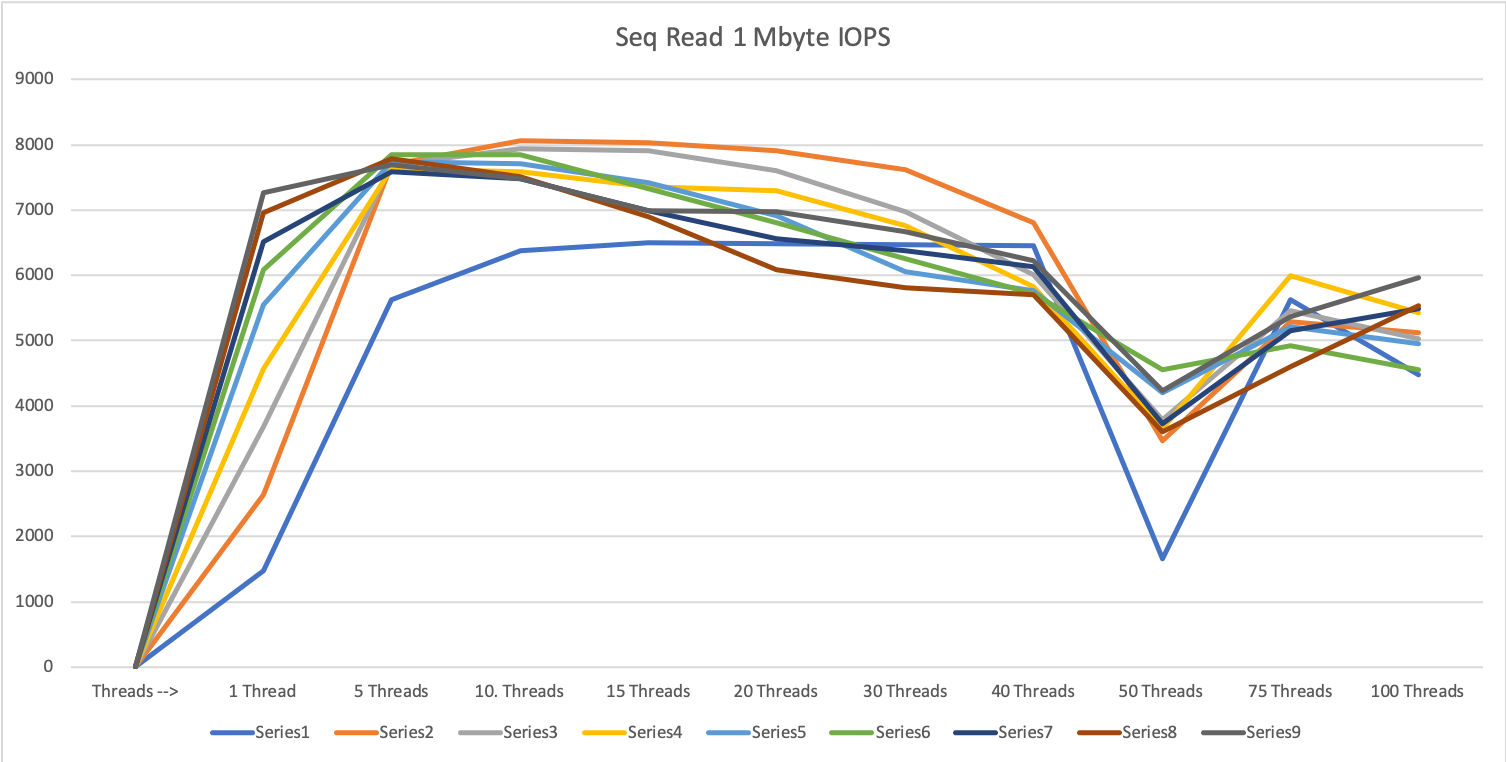
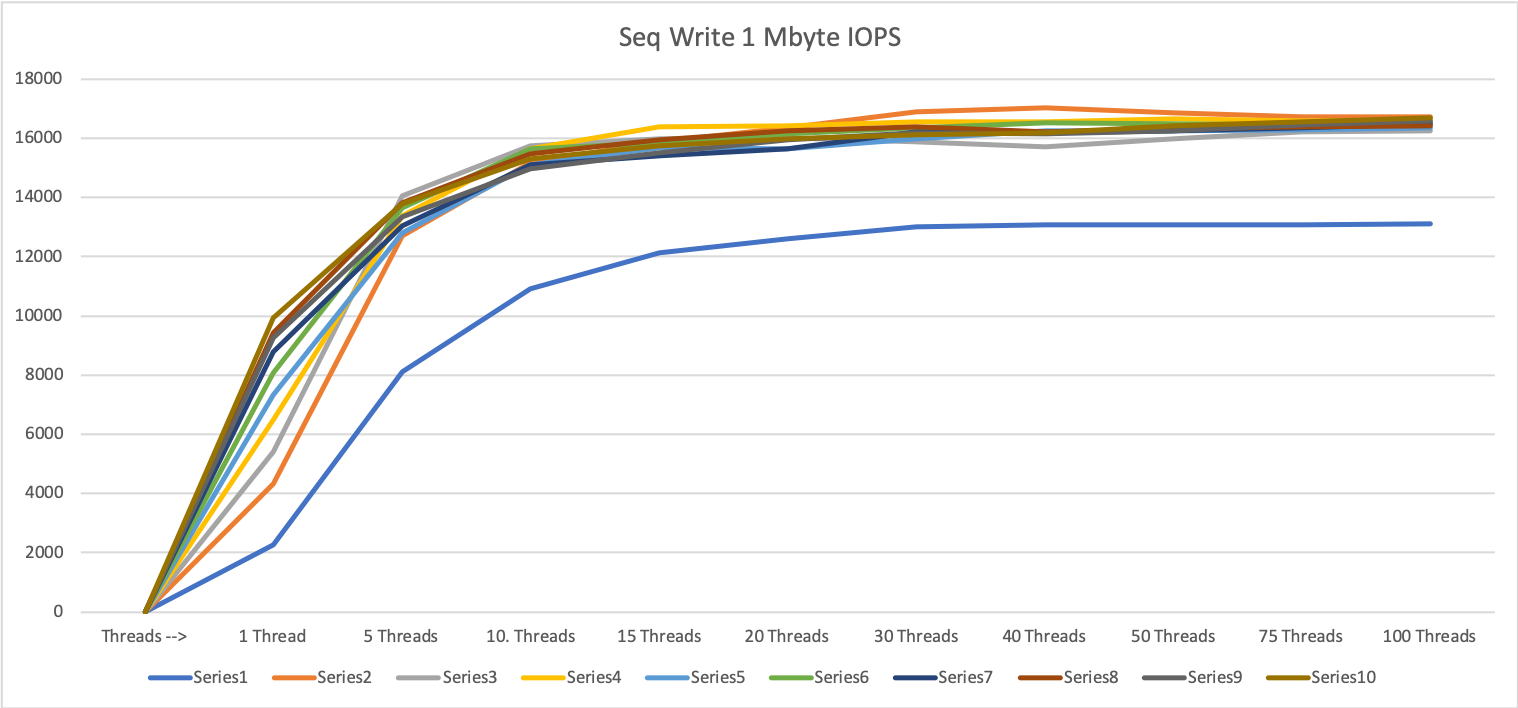
Mixed Workload
After these tests, we know, the upper limit for this storage in single case tests. In a normal workload, we will never see only one kind of IO: There will always be a mixture of 8 KByte read & write IOPS side by side with 1 MByte IO. To simulate this picture, we create two FIO files. One creates approx: 40k-50k IOPS with random read and random write in a 50/50 split.
This will be our baseline, then we add approx. 1000 1 MByte IOPS every 60 seconds and see how the answer time reacts.
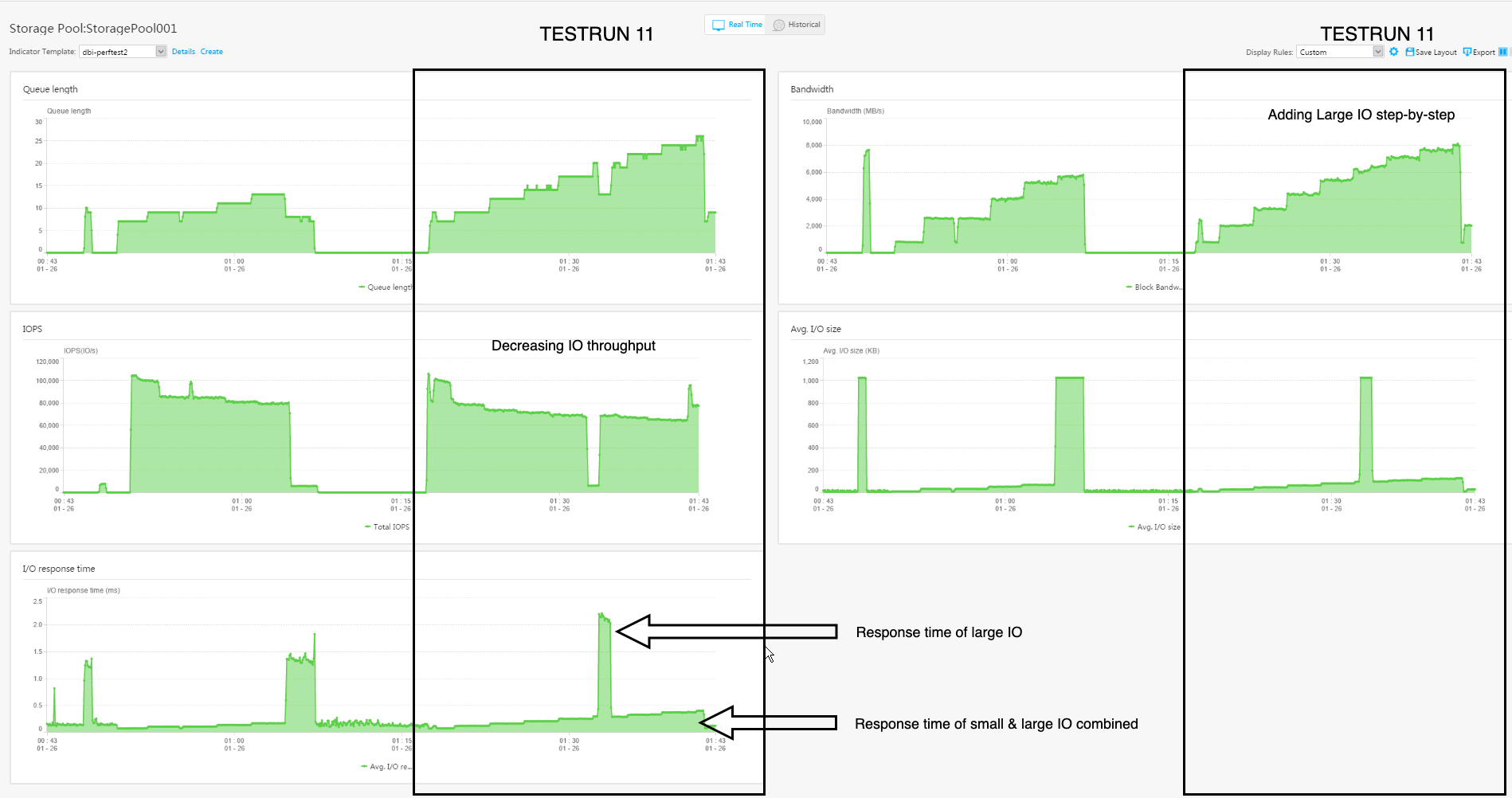
As seen in this picture from the performance monitor of the storage system the 1 MByte IOPS blocks had two effects on the smaller IOPS
The throughput of the small IOPS is decreasing
The latency is increasing.
In the middle of the test, we stop the small IOPS to see the latency of just the 1 MByte IOPS.
Both effects are expected and within the expected parameters: Test passed.
So with a base workload of 40k-50k IOPS, we can run e.g. backups in parallel with a bandwidth up to 5.5 GByte/s without interfering with the database work or we can do up to 5 active duplicates on the same storage without interfering with the other databases.
Summary
This storage system showed a fantastic performance at 8 KByte block size with very low latency. Especially the high number of parallel processes we can run against it before we hit the peak performance makes it a good choice to serving a large number of Oracle databases on it.
The large IO (1 MByte) performance for write operations was good but not that good compared with the excellent 8 KByte performance. The sequential read part is missing the read cache badly compared to the performance which is possible for writing. But even that is not on top of the line compared to other storage systems. Here I had seen other storage systems with a comparable configuration which were able to deliver up to 12k IOPS@1MByte.
Remember the questions from the first blog post:
-How many devices should I bundle into a diskgroup for best performance?
As many as possible.
-How many backups/duplicates can I run in parallel to my normal database workload without interfering with it?
You can run 5 parallel backup/duplicates with 1000 IOPS each without interferring a base line of 40-50k IOPS@8KByte
-What is the best rebalance power I can use on my system?
2-4 is absolutley enough for this system. More will slow down your other operations on the server.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/oracle-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/11/TBR-web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/11/LTO_WEB.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/MAW_web-min-scaled.jpg)