This is the last post in this little series about migrating on Oracle instance to AWS Aurora with PostgreSQL compatibility. For the previous one you can check here, here and here. In this post we’ll look at how you can configure change data capture so that changes on the source Oracle instance are automatically replicated to the target Aurora instance. In a real life migration this is what you probably need as long down times are usually not acceptable. We’ll be starting from exactly the same state we left of in the previous post.
We’ve initially loaded the source “SH” schema from Oracle to AWS Aurora and now we want to replicate all the changes that are happening on the source to the target as well. Remember that AWS DMS sits between the source and the target and the we need a source end point and a target end point:
We can use exactly the same end points as in the previous post (nothing to add or modify here):

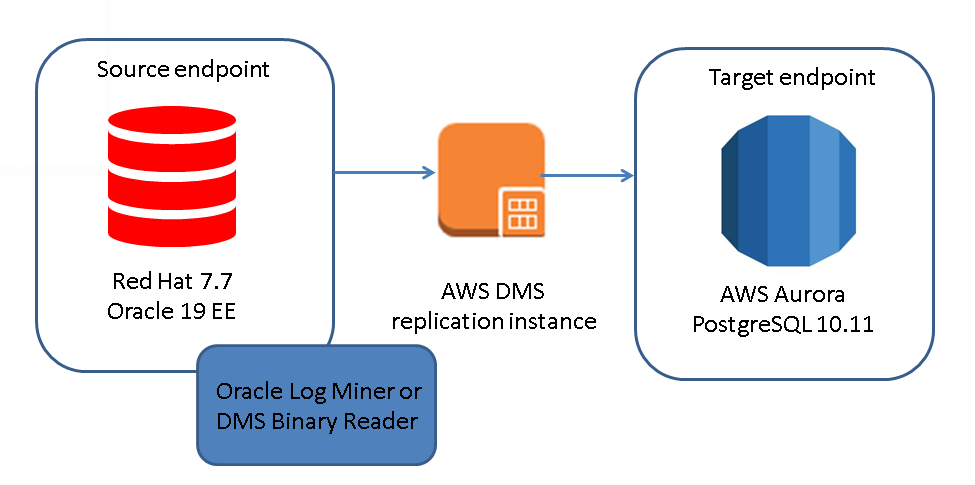
What we need to configure is a new database migration task. We still have the task we used to do the initial loading which could be modified but I prefer to keep it separated and will go ahead with a new task:

We’ll be using the same replication instance and the same end points but “Migration type” will be “Replicate data changes only”. We already enabled “supplemental logging” in the last post so the warning can be ignored:
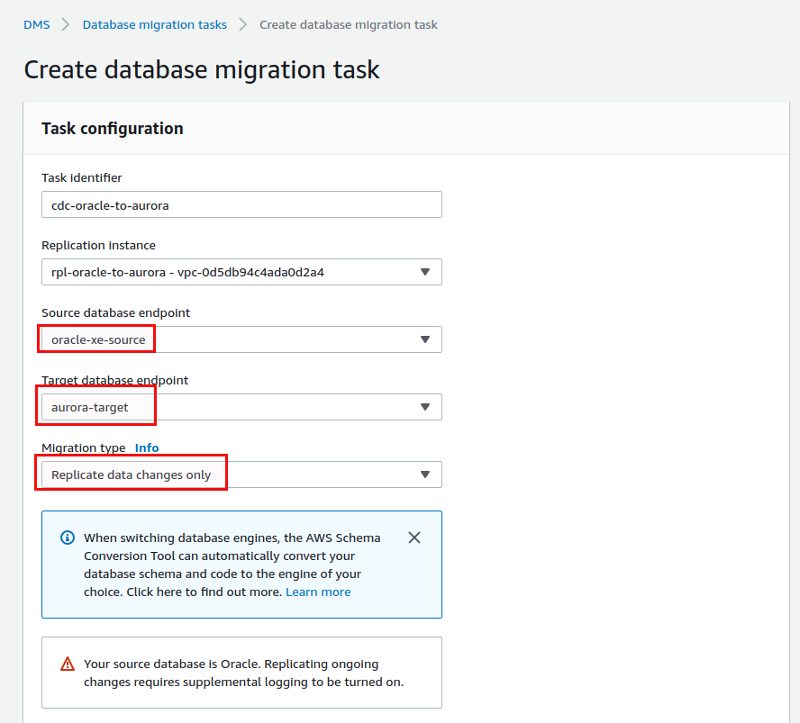
We’ll go with the default task settings:
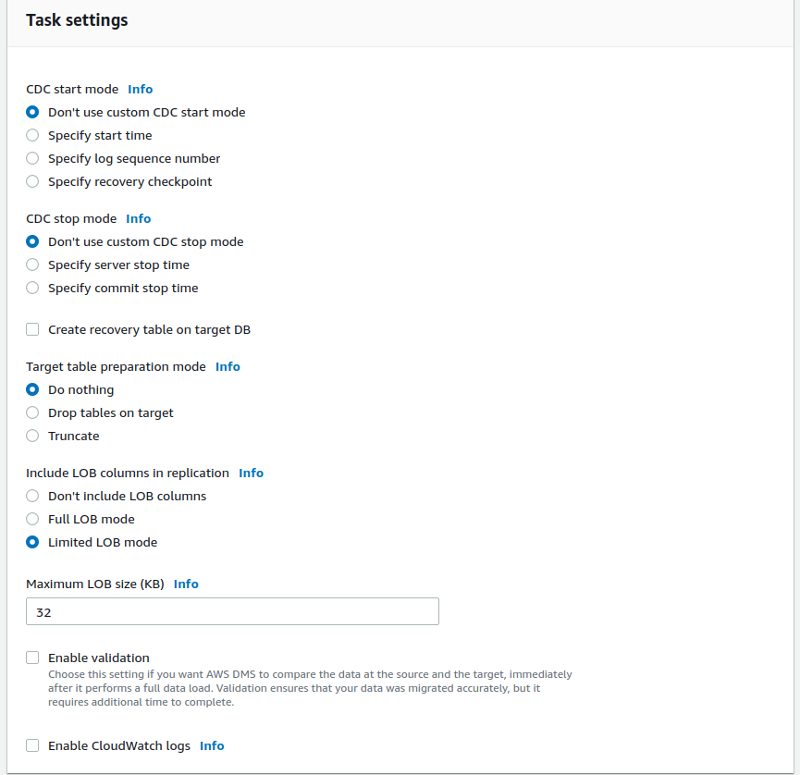
As I know that nothing happened on the source I do not need to specify a specific start point for the replication. The same is true for the tables on the target: I already know that the tables are there and that the content of the tables on the target is the same as on the source. For the LOB stuff I’ll go with the defaults as well.
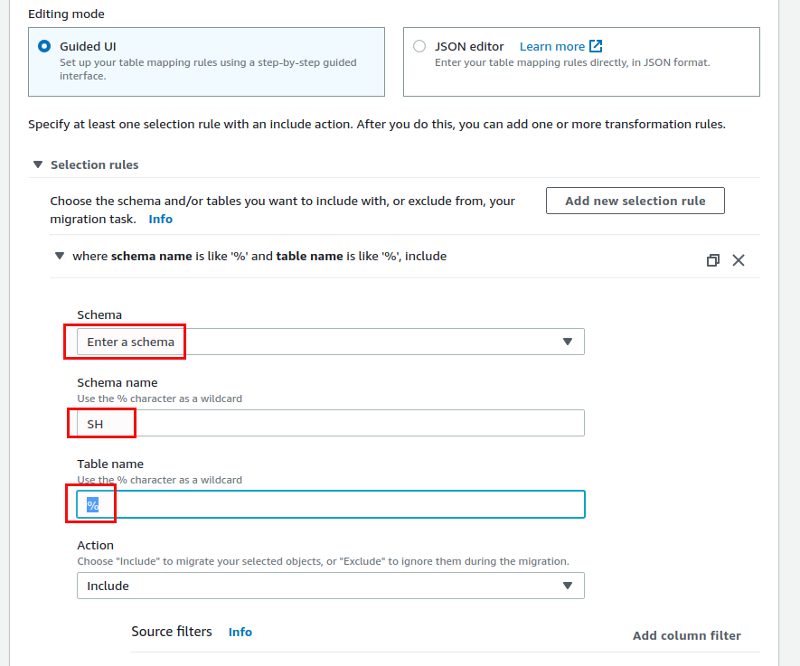
The table mappings section is configured the same as we did it for the initial load previously. We want to replicate all tables in the “SH” schema:
Finally all the defaults for the remaining parameters of the task:
While the task is creating:
… you’ll see that LogMiner is starting on the source Oracle instance:
2020-03-23T08:44:08.261039+01:00 Thread 1 advanced to log sequence 39 (LGWR switch) Current log# 3 seq# 39 mem# 0: /u03/oradata/DB19/redog3m1DB19.dbf Current log# 3 seq# 39 mem# 1: /u04/oradata/DB19/redog3m2DB19.dbf 2020-03-23T08:44:08.398220+01:00 ARC2 (PID:4670): Archived Log entry 15 added for T-1.S-38 ID 0x2c7a7c94 LAD:1 2020-03-23T08:54:41.598409+01:00 LOGMINER: summary for session# = 2147484673 LOGMINER: StartScn: 1084978 (0x0000000000108e32) LOGMINER: EndScn: 1085221 (0x0000000000108f25) LOGMINER: HighConsumedScn: 0 LOGMINER: PSR flags: 0x0 LOGMINER: Session Flags: 0x4000441 LOGMINER: Session Flags2: 0x0 LOGMINER: Read buffers: 4 LOGMINER: Region Queue size: 256 LOGMINER: Redo Queue size: 4096 LOGMINER: Memory LWM: limit 10M, LWM 12M, 80% LOGMINER: Memory Release Limit: 0M LOGMINER: Max Decomp Region Memory: 1M LOGMINER: Transaction Queue Size: 1024 2020-03-23T08:54:41.627157+01:00 LOGMINER: Begin mining logfile for session -2147482623 thread 1 sequence 39, /u03/oradata/DB19/redog3m1DB19.dbf 2020-03-23T08:54:46.780204+01:00 LOGMINER: summary for session# = 2147485697 LOGMINER: StartScn: 1085020 (0x0000000000108e5c) LOGMINER: EndScn: 1085288 (0x0000000000108f68) LOGMINER: HighConsumedScn: 0 LOGMINER: PSR flags: 0x0 LOGMINER: Session Flags: 0x4000441 LOGMINER: Session Flags2: 0x0 LOGMINER: Read buffers: 4 LOGMINER: Region Queue size: 256 LOGMINER: Redo Queue size: 4096 LOGMINER: Memory LWM: limit 10M, LWM 12M, 80% LOGMINER: Memory Release Limit: 0M LOGMINER: Max Decomp Region Memory: 1M LOGMINER: Transaction Queue Size: 1024 2020-03-23T08:54:46.788212+01:00 LOGMINER: Begin mining logfile for session -2147481599 thread 1 sequence 39, /u03/oradata/DB19/redog3m1DB19.dbf 2020-03-23T08:54:51.861617+01:00 LOGMINER: summary for session# = 2147486721 LOGMINER: StartScn: 1085087 (0x0000000000108e9f) LOGMINER: EndScn: 1085362 (0x0000000000108fb2) LOGMINER: HighConsumedScn: 0 LOGMINER: PSR flags: 0x0 LOGMINER: Session Flags: 0x4000441 LOGMINER: Session Flags2: 0x0 LOGMINER: Read buffers: 4 LOGMINER: Region Queue size: 256 LOGMINER: Redo Queue size: 4096 LOGMINER: Memory LWM: limit 10M, LWM 12M, 80% LOGMINER: Memory Release Limit: 0M LOGMINER: Max Decomp Region Memory: 1M LOGMINER: Transaction Queue Size: 1024 2020-03-23T08:54:51.868450+01:00 LOGMINER: Begin mining logfile for session -2147480575 thread 1 sequence 39, /u03/oradata/DB19/redog3m1DB19.dbf
The task itself will report it’s status as “Replication ongoing” a few moments later:
Having a look at the table statistics section of the tasks of course all is reported as zero at the moment:
Time to do some changes in Oracle and check if these changes will be properly replicated to the Aurora target instance. Let’s create a new table on the Oracle side:
SQL> create table sh.test ( a number ); Table created.
This table will show up in the AWS DMS console quite fast:
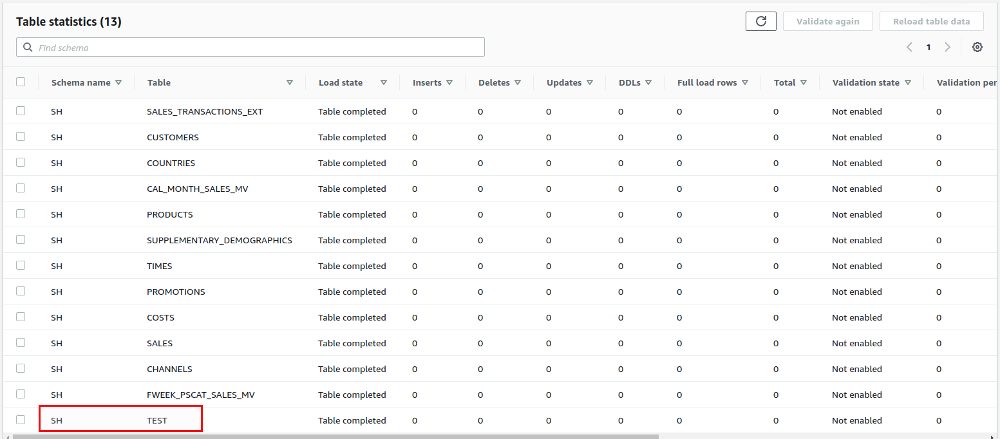
… and is also available on the target Aurora side:
postgres=> \d "SH"."TEST"
Table "SH.TEST"
Column | Type | Modifiers
--------+----------------+-----------
A | numeric(38,10) |
postgres=> select * from "SH"."TEST";
A
---
(0 rows)
Inserting data on the source:
SQL> insert into sh.test values(1); 1 row created. SQL> commit; Commit complete.
… and nothing happens on the target side. Why does DDL succeed but DML not? Well, first of all it takes some time for the changes to show up in the console. Doing some more inserts on the source and waiting some time:
SQL> insert into sh.test values(2); 1 row created. SQL> commit; Commit complete. SQL> insert into sh.test values(3); 1 row created. SQL> commit; Commit complete.
… the changes are actually recorded:
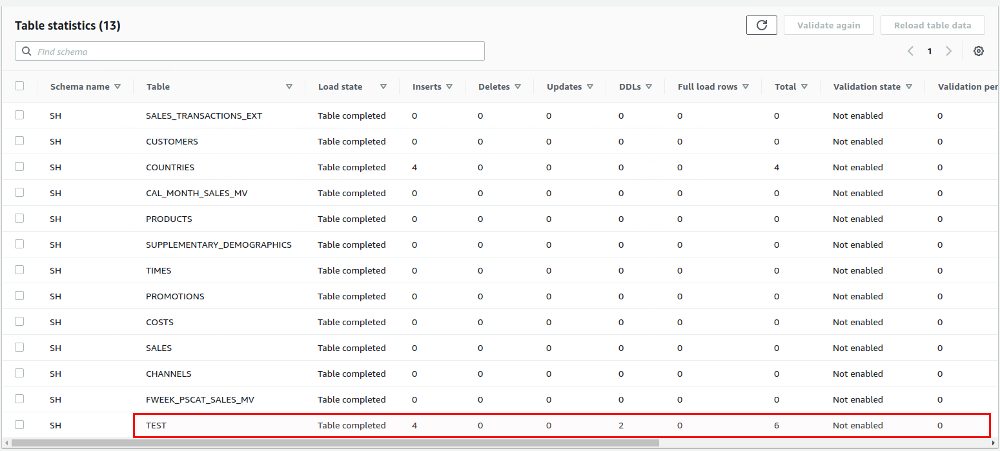
… but nothing arrives on the target:
postgres=> select * from "SH"."TEST"; A --- (0 rows)
Why that? Let’s do some more inserts:
SQL> insert into sh.test select -1 from dba_objects; 23522 rows created. SQL> commit; Commit complete.
This is reported as “1” insert in the console as the number of inserts switched from 6 to 7:
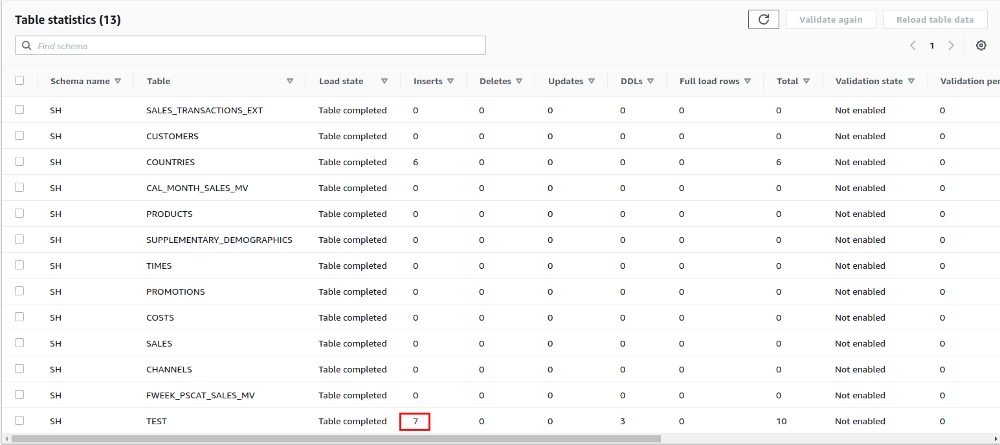
Some picture, nothing there on the target. The issues was, that supplemental logging needs to be enabled for each table or on the database level, and this is what I did:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
Re-creating the table on Oracle side:
SQL> drop table sh.test; Table dropped. SQL> create table sh.test ( a number primary key ); Table created. SQL> insert into sh.test values(1); 1 row created. SQL> insert into sh.test values(2); 1 row created. SQL> commit; Commit complete. SQL>
From now on new data is showing up in the target Aurora instance:
postgres=> select * from "SH"."TEST";
A
--------------
1.0000000000
2.0000000000
(2 rows)
postgres=>
So, again, quite easy to setup. Of course the usual bits apply as for every logical replication: You should have primary keys or at least unique keys on the source tables for the replication to run performant and smooth. Another point to add here: When you check the settings of the replication task there is one important parameter that should be enabled (you need to stop the task, otherwise it can not be modified):
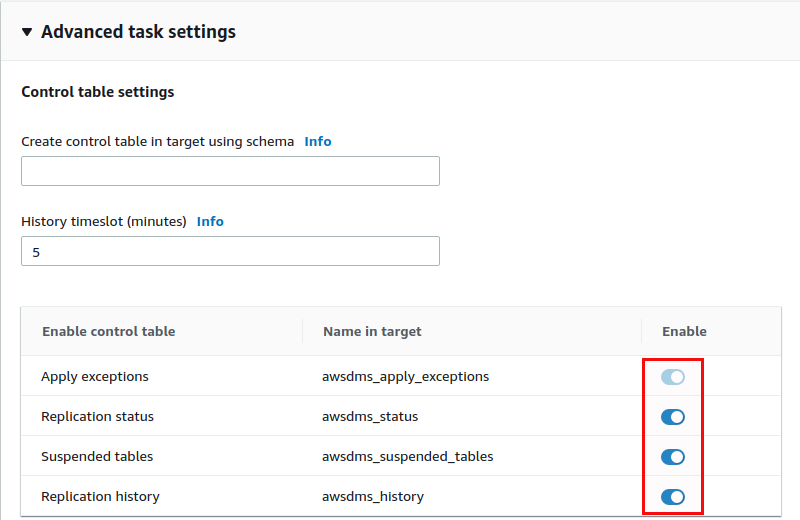
Enabling this will create additional tables in the target Aurora instance and these give you more information on what is going on with the replication:
postgres=> select * from pg_tables where tablename like 'awsdms%'; schemaname | tablename | tableowner | tablespace | hasindexes | hasrules | hastriggers | rowsecurity -------------+-------------------------+------------+------------+------------+----------+-------------+------------- public | awsdms_apply_exceptions | postgres | | f | f | f | f aws_postgis | awsdms_apply_exceptions | postgres | | f | f | f | f public | awsdms_history | postgres | | t | f | f | f public | awsdms_status | postgres | | t | f | f | f public | awsdms_suspended_tables | postgres | | t | f | f | f (5 rows)
Here is an example of the replication history:
postgres=> select * from awsdms_history;
server_name | task_name | timeslot_type | timeslot | timeslot_duration | timeslot_latency | timeslot_records | timeslot_volume
-----------------------+----------------------------+-------------------+---------------------+-------------------+------------------+------------------+-----------------
localhost.localdomain | XEBQFBY6EH6SQNN6CBBMO25364 | CHANGE PROCESSING | 2020-03-23 09:42:29 | 0 | 0 | 0 | 0
localhost.localdomain | XEBQFBY6EH6SQNN6CBBMO25364 | CHANGE PROCESSING | 2020-03-23 09:47:29 | 5 | 0 | 70592 | 28
localhost.localdomain | XEBQFBY6EH6SQNN6CBBMO25364 | CHANGE PROCESSING | 2020-03-23 09:52:29 | 5 | 0 | 6 | 0
localhost.localdomain | XEBQFBY6EH6SQNN6CBBMO25364 | CHANGE PROCESSING | 2020-03-23 09:57:30 | 5 | 0 | 0 | 0
localhost.localdomain | XEBQFBY6EH6SQNN6CBBMO25364 | CHANGE PROCESSING | 2020-03-23 10:02:31 | 5 | 0 | 0 | 0
localhost.localdomain | XEBQFBY6EH6SQNN6CBBMO25364 | CHANGE PROCESSING | 2020-03-23 10:07:31 | 5 | 0 | 0 | 0
localhost.localdomain | XEBQFBY6EH6SQNN6CBBMO25364 | CHANGE PROCESSING | 2020-03-23 10:12:32 | 5 | 0 | 0 | 0
localhost.localdomain | XEBQFBY6EH6SQNN6CBBMO25364 | CHANGE PROCESSING | 2020-03-23 10:17:32 | 5 | 0 | 0 | 0
localhost.localdomain | XEBQFBY6EH6SQNN6CBBMO25364 | CHANGE PROCESSING | 2020-03-23 10:22:39 | 0 | 0 | 0 | 0
(9 rows)
These tables can be used to monitor the replication, especially the apply exceptions.
To conclude this final post: The AWS Schema Conversion Tool is a great help for converting the schema and even comes with some Oracle compatibility. Use it, it saves a lot of manual work. AWS DMS on the other side is really easy to implement, the initial load is really easy to setup and change data capture works as expected. Of course this was only a playground and real issues will pop up when you do a real migration, especially when you have to migrate business logic inside the database.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2023/01/APY_web-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/FRJ_web-min-scaled.jpg)