After spending some times with Docker Swarm let’s introduce SQL Server on Kubernetes (aka K8s). Why another container orchestrator? Well, because Microsoft gives a strong focus on Kubernetes in their documentation and their events and because K8s is probably one of the most popular orchestration tools in the IT industry. By the way, I like to refer to the Portworx Annual Container Adoption Survey to get a picture of container trend over the years and we may notice there is no clear winner among orchestration tools yet between Swarm and K8s. By 2017, one another interesting point was persistent storage challenge that is the top 1 of the top list of adoption. I’m looking forward to see the next report about this point because you probably guessed, database containers rely mainly on it.
Anyway, as an IT services company, it appears justifiable to include K8s to our to-do list about container orchestrators 🙂

First of all, let’s say this blog post doesn’t aim to compare Docker Swarm and K8s. Each platform has pros and cons and you can read a lot on the internet. I will rather expose some thoughts about deploying our dbi services docker image on this platform. Indeed, since last year we mainly work on our SQL Server docker image based on Docker and Docker Swarm architectures and it may be interesting to see if we may go the same way with K8s.
But before deploying our custom image we need to install a K8s infrastructure. From an installation perspective K8s cluster is likely harder to use than Docker Swarm. This time rather than using my own lab environment, I will shift on both Azure container and Azure container registry services to provision an operational K8s service. I just want here to focus on deploying my image and get some experience feedbacks about interacting with K8s. The Microsoft procedure is well-documented so there is no really adding-value to duplicate the installation steps. Because we operate on Azure, I will use a lot of az cli and kubectl commands to deploy and to manage my K8s service. Here some important information concerning my infrastructure:
I first installed and configured a private registry through the Azure container registry service in order to push my custom docker image for SQL Server 2017 on Linux. Obviously, this step may be optional regarding your context. My custom image is named dbi_linux_sql2017.
[dab@DBI-LT-DAB:#]> az acr repository list --name dbik8registry --output table Result ------------------ dbi_linux_sql2017 mssql-server-linux
Then I installed my K8s service that includes 2 nodes. This is likely not a recommended scenario for production but it will fit with my need for the moment. I will probably scale my architecture for future tests.
[dab@DBI-LT-DAB:#]> kubectl cluster-info Kubernetes master is running at https://dbik8sclus-k8s-rg-913528-... Heapster is running at https://dbik8sclus-k8s-rg-913528-... KubeDNS is running at https://dbik8sclus-k8s-rg-913528-... kubernetes-dashboard is running at https://dbik8sclus-k8s-rg-913528-... …
[dab@DBI-LT-DAB:#]> kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: REDACTED
server: https://dbik8sclus-k8s-rg-913528-3eb7146d.hcp.westeurope.azmk8s.io:443
name: dbik8scluster
contexts:
- context:
cluster: dbik8scluster
user: clusterUser_k8s-rg_dbik8scluster
name: dbik8scluster
current-context: dbik8scluster
…
[dab@DBI-LT-DAB:#]> kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-nodepool1-78763348-0 Ready agent 6h v1.9.6
aks-nodepool1-78763348-1 Ready agent 6h v1.9.6
From an Azure perspective, my K8s cluster is composed of several resources in a dedicated resource group with virtual machines, disks, network interfaces, availability sets and a K8s load balancer reachable from a public IP address.
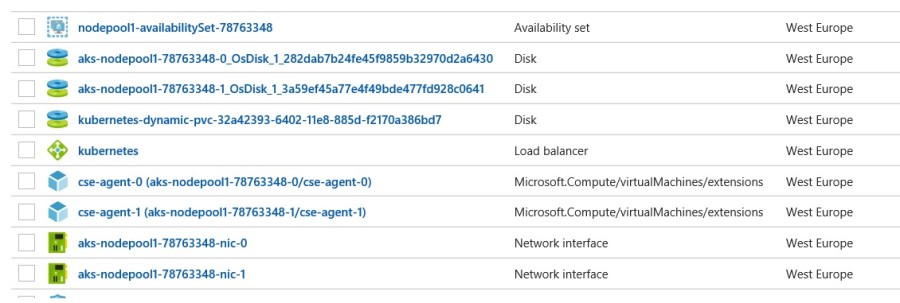
Finally, I granted to my K8s cluster sufficient permissions to access my private Docker registry (READ role).
[dab@DBI-LT-DAB:#]>$CLIENT_ID=(az aks show --resource-group k8s-rg --name dbik8scluster --query "servicePrincipalProfile.clientId" --output tsv) [dab@DBI-LT-DAB:#]>$ACR_ID=$(az acr show --name dbik8registry --resource-group k8s-rg --query "id" --output tsv) [dab@DBI-LT-DAB:#]>az role assignment create --assignee $CLIENT_ID --role Reader --scope $ACR_ID [dab@DBI-LT-DAB:#]> kubectl get secrets NAME TYPE DATA AGE default-token-s94vc kubernetes.io/service-account-token 3 6h
Similar to Docker Swarm, we may rely on secret capabilities to protect the SQL Server sa password. So, let’s take advantage of it!
[dab@DBI-LT-DAB:#]> kubectl create secret generic mssql --from-literal=SA_PASSWORD="xxxxx" [dab@DBI-LT-DAB:#]> kubectl get secrets NAME TYPE DATA AGE default-token-s94vc kubernetes.io/service-account-token 3 6h mssql Opaque 1 6h
At this stage before deploying my SQL Server application, let’s introduce some K8s important concepts we should be familiar as a database administrator.
- Pod
Referring to the K8s documentation, a pod is a logical concept that represents one or more application containers with some shared resources as shared storage, networking including unique cluster IP address and metadata about each container image such image version, exposed port etc ….
Each container in the same pod is always co-located and co-scheduled and run in shared context on the same node. Comparing to Docker Swarm, the latter doesn’t offer such capabilities because as far I as know by default, tasks are spread services across the cluster and there is no really easy way to achieve the same concept than K8s pod.
To simplify, a K8s pod is a group of containers that are deployed together on the same host. Referring to my SQL Server deployment with only one container, pod may be replaced by container here but in a real production scenario SQL Server will likely be one part of a K8s pod.
We may correlate what was said previously by using K8s related commands to pods. Here a status of the pod related to my SQL Server deployment.
[dab@DBI-LT-DAB:#]> kubectl get pods
NAME READY STATUS RESTARTS AGE
mssql-deployment-5845f974c6-xx9jv 1/1 Running 0 3h
[dab@DBI-LT-DAB:#]> kubectl describe pod mssql-deployment-5845f974c6-xx9jv
Name: mssql-deployment-5845f974c6-xx9jv
Namespace: default
Node: aks-nodepool1-78763348-0/10.240.0.4
Start Time: Wed, 30 May 2018 19:16:46 +0200
Labels: app=mssql
pod-template-hash=1401953072
Annotations: <none>
Status: Running
IP: 10.244.1.13
Controlled By: ReplicaSet/mssql-deployment-5845f974c6
Containers:
mssql:
Container ID: docker://b71ba9ac3c9fa324d8ff9ffa8ec24015a676a940f4d2b64cbb85b9de8ce1e227
Image: dbik8registry.azurecr.io/dbi_linux_sql2017:CU4
Image ID: docker-pullable://dbik8registry.azurecr.io/dbi_linux_sql2017@sha256:5b9035c51ae2fd4c665f957da2ab89432b255db0d60d5cf63d3405b22a36ebc1
Port: 1433/TCP
State: Running
Started: Wed, 30 May 2018 19:17:22 +0200
Ready: True
Restart Count: 0
Environment:
ACCEPT_EULA: Y
MSSQL_SA_PASSWORD: xxxxxx
DMK: Y
Mounts:
/var/opt/mssql from mssqldb (rw)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-s94vc (ro)
Conditions:
Type Status
Initialized True
Ready True
PodScheduled True
Volumes:
mssqldb:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: mssql-data
ReadOnly: false
….
- Replica set
A Replication set is a structure that enables you to easily create multiple pods, then make sure that that number of pods always exists. If a pod does crash, the Replication Controller replaces it. It also provides scale capabilities as we get also from Docker Swarm.
- Service
From K8s documentation a service is also an abstraction which defines a logical set of Pods and a policy by which to access them – sometimes called a micro-service. The set of Pods targeted by a service is (usually) determined by a Label Selector. While there are some differences under the hood, we retrieve the same concepts with Docker Swarm from a deployment perspective.
- Virtual IP and service proxies
Referring again to the K8s documentation, every node in a Kubernetes cluster runs a kube-proxy that is responsible for implementing a form of virtual IP for Services. It includes Ingress network that is also part of Docker Swarm architecture with overlay networks and routing mesh capabilities.
In my case, as described previously I used an external load balancer with an EXTERNAL-IP configured to access my SQL Server container from the internet (xx.xxx.xxx.xx is my masked public IP as you already guessed)
[dab@DBI-LT-DAB:#]> kubectl get services NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 7h mssql-deployment LoadBalancer 10.0.200.170 xx.xxx.xxx.xx 1433:30980/TCP 4h
From an Azure perspective the above output corresponds to what we may identify as my Kubernetes load balancer and public IP address resources as well.
![]()
![]()
Once again, my intention was not to compare Docker Swarm and K8s at all but just to highlight the fact if you’re already comfortable with Docker Swarm, the move on K8s is not as brutal as we may suppose from a high-level point of view.
Ok let’s start now the deployment phase. As said previously my private container registry already contains my custom SQL Server image. I just had to tag my image on my local machine and to push it the concerned registry as I might do with other remote Docker registries.
[dab@DBI-LT-DAB:#]> docker images REPOSITORY TAG IMAGE ID CREATED SIZE dbik8registry.azurecr.io/dbi_linux_sql2017 CU4 3c6bafb33a5c 17 hours ago 1.42GB dbi/dbi_linux_sql2017 CU4 3c6bafb33a5c 17 hours ago 1.42GB [dab@DBI-LT-DAB:#]> az acr repository list --name dbik8registry --output table Result ------------------ dbi_linux_sql2017 mssql-server-linux [dab@DBI-LT-DAB:#]> az acr repository show-tags --name dbik8registry --repository mssql-server-linux --output table Result -------- 2017-CU4
In addition, I used a persistent storage based on Azure managed disk in order to guarantee persistence for my SQL Server database files.
[dab@DBI-LT-DAB:#]> kubectl describe pvc mssql-data Name: mssql-data Namespace: default StorageClass: azure-disk Status: Bound Volume: pvc-32a42393-6402-11e8-885d-f2170a386bd7 …
Concerning the image itself we use some custom parameters to create both a dedicated user for applications that will run on the top of the SQL Server instance and to enable the installation of the DMK maintenance module for SQL Server at the container start up. We have other customization topics but for this blog post it will be sufficient to check what we want to test.
Here my deployment file. Comparing to Docker Swarm deployment file, I would say the manifest is more complex with K8s (that’s a least my feeling).
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: mssql-deployment
spec:
replicas: 1
template:
metadata:
labels:
app: mssql
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mssql
image: dbik8registry.azurecr.io/dbi_linux_sql2017:CU4
ports:
- containerPort: 1433
env:
- name: ACCEPT_EULA
value: "Y"
- name: MSSQL_SA_PASSWORD
valueFrom:
secretKeyRef:
name: mssql
key: SA_PASSWORD
- name: DMK
value: "Y"
volumeMounts:
- name: mssqldb
mountPath: /var/opt/mssql
volumes:
- name: mssqldb
persistentVolumeClaim:
claimName: mssql-data
---
apiVersion: v1
kind: Service
metadata:
name: mssql-deployment
spec:
selector:
app: mssql
ports:
- protocol: TCP
port: 1433
targetPort: 1433
type: LoadBalancer
Let’s deploy and let’s spin up our SQL Server application
[dab@DBI-LT-DAB:#]> kubectl apply -f T:\dbi_dbaas_azure\sqlk8sazuredeployment.yaml deployment "mssql-deployment" created service "mssql-deployment" created
Pod and services are created. Let’s take a look at some information about them. Deployment and pod are ok. The last command shows the associated internal IP to connect in order to the SQL Server pod as well as a external / public IP address that corresponds to the Ingress load-balancer to connect from outside Azure internal network. We also get a picture of exposed ports.
[dab@DBI-LT-DAB:#]> kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE mssql-deployment 1 1 1 1 7m [dab@DBI-LT-DAB:#]> kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE mssql-deployment-8c67fdccc-pbg6d 1/1 Running 0 12h 10.244.1.16 aks-nodepool1-78763348-0 [dab@DBI-LT-DAB:#]> kubectl get replicasets NAME DESIRED CURRENT READY AGE mssql-deployment-8c67fdccc 1 1 1 12h [dab@DBI-LT-DAB:#]> kubectl get services NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 9h mssql-deployment LoadBalancer 10.0.134.101 xxx.xxx.xxx.xxx 1433:31569/TCP 7m [dab@DBI-LT-DAB:#]> kubectl describe service mssql-deployment Name: mssql-deployment Namespace: default Labels: <none> … Selector: app=mssql Type: LoadBalancer IP: 10.0.134.101 LoadBalancer Ingress: xxx.xxx.xxx.xxx Port: <unset> 1433/TCP TargetPort: 1433/TCP NodePort: <unset> 31569/TCP Endpoints: 10.244.1.16:1433 Session Affinity: None External Traffic Policy: Cluster Events: <none>
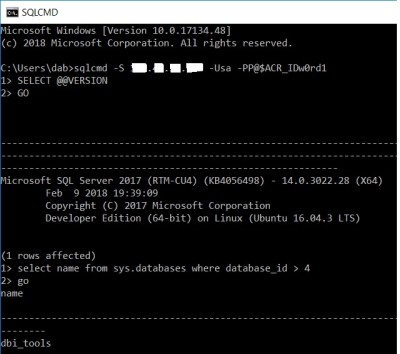
Let’s try now to connect to new fresh SQL Server instance from my remote laptop:
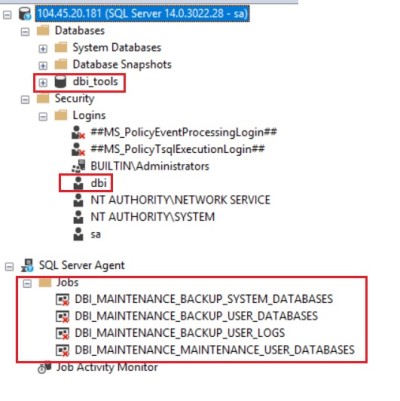
Great job! My container includes all my custom stuff as the dbi_tools database and dedicated maintenance jobs related to our DMK maintenance tool. We may also notice the dbi user created during the container start up.
Just out of curiosity, let’s have a look at the pod log or container log because there is only one in the pod in my case. The log includes SQL Server log startup and I put only some interesting samples here that identify custom actions we implemented during the container startup.
[dab@DBI-LT-DAB:#]> kubectl get po -a NAME READY STATUS RESTARTS AGE mssql-deployment-8c67fdccc-pk6sm 1/1 Running 0 21m [dab@DBI-LT-DAB:#]> kubectl logs mssql-deployment-8c67fdccc-pk6sm … ======= 2018-05-30 21:04:59 Creating /u00 folder hierarchy ======== cat: /config.log: No such file or directory ======= 2018-05-30 21:04:59 Creating /u01 folder hierarchy ======== ======= 2018-05-30 21:04:59 Creating /u02 folder hierarchy ======== ======= 2018-05-30 21:04:59 Creating /u03 folder hierarchy ======== ======= 2018-05-30 21:04:59 Creating /u98 folder hierarchy ======== ======= 2018-05-30 21:04:59 Linking binaries and configuration files to new FHS ======== ======= 2018-05-30 21:04:59 Creating MSFA OK ======= …. 2018-05-30 21:05:13.85 spid22s The default language (LCID 1033) has been set for engine and full-text services. ======= 2018-05-30 21:05:29 MSSQL SERVER STARTED ======== ======= 2018-05-30 21:05:29 Configuring tempdb database files placement ======= … 2018-05-30 21:06:05.16 spid51 Configuration option 'max server memory (MB)' changed from 2147483647 to 1500. Run the RECONFIGURE statement to install. Configuration option 'show advanced options' changed from 0 to 1. Run the RECONFIGURE statement to install. Configuration option 'max server memory (MB)' changed from 2147483647 to 1500. Run the RECONFIGURE statement to install. ======= 2018-05-30 21:06:05 Configuring max server memory OK ======= ======= 2018-05-30 21:06:05 Creating login dbi ======= ======= 2018-05-30 21:06:05 Creating login dbi OK ======= ======= 2018-05-30 21:06:05 Installing DMK ======= Changed database context to 'master'. Creating dbi_tools... 2018-05-30 21:06:12.47 spid51 Setting database option MULTI_USER to ON for database 'dbi_tools'. Update complete. Changed database context to 'dbi_tools'. (1 rows affected) (1 rows affected) ======= 2018-05-30 21:06:12 Installing DMK OK ======= ======= MSSQL CONFIG COMPLETED ======= 2018-05-30 21:10:09.20 spid51 Using 'dbghelp.dll' version '4.0.5' 2018-05-30 21:10:19.76 spid51 Attempting to load library 'xplog70.dll' into memory. This is an informational message only. No user action is required. 2018-05-30 21:10:19.87 spid51 Using 'xplog70.dll' version '2017.140.3022' to execute extended stored procedure 'xp_msver'. This is an informational message only; no user action is required.
To finish this blog post up properly, let’s simulate a pod failure to check the K8s behavior with our SQL Server container.
[dab@DBI-LT-DAB:#]> kubectl delete pod mssql-deployment-8c67fdccc-pk6sm pod "mssql-deployment-8c67fdccc-pk6sm" deleted [dab@DBI-LT-DAB:#]> kubectl get pods NAME READY STATUS RESTARTS AGE mssql-deployment-8c67fdccc-jrdgg 1/1 Running 0 5s mssql-deployment-8c67fdccc-pk6sm 1/1 Terminating 0 26m [dab@DBI-LT-DAB:#]> kubectl get pods NAME READY STATUS RESTARTS AGE mssql-deployment-8c67fdccc-jrdgg 1/1 Running 0 2m
As expected, the replica set is doing its job by re-creating the pod to recover my SQL Server instance, and by connecting to the persistent storage. We can check we can still connect on the instance from the load balancer IP address without running into any corruption issue.
To conclude, I would say that moving our custom SQL docker image was not as hard as I expected. Obviously, there are some difference between the both orchestrator products but from an application point of view it doesn’t make a big difference. In an administration perspective, I’m agree the story is probably not the same 🙂
What about K8s from a development perspective? You may say that you didn’t own such Azure environment but the good news is you can use Minikube which is the single node version of Kubernetes mainly designed for local development. I will probably blog about it in the future.
Stay tuned!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2023/01/APY_web-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/FRJ_web-min-scaled.jpg)