Elasticsearch has few interesting features around Machine Learning. While I was looking for data to import into Elasticsearch, I found interesting data sets from Airbnb especially reviews. I noticed that it does not contain any rate, but only comments.
To have sentiment of the a review, I would rather have an opinion on that review like:
- Negative
- Positive
- Neutral
For that matter, I found the cardiffnlp/twitter-roberta-base-sentiment-latest to suite my needs for my tests.
Import Model
Elasticsearch provides the tool to import models from Hugging face into Elasticsearch itself: eland.
It is possible to install it or even use the pre-built docker image:
docker run -it --rm --network host docker.elastic.co/eland/eland
Let’s import the model:
eland_import_hub_model -u elastic -p 'password!' --hub-model-id cardiffnlp/twitter-roberta-base-sentiment-latest --task-type classification --url https://127.0.0.1:9200
After a minute, import completes:
2024-04-16 08:12:46,825 INFO : Model successfully imported with id 'cardiffnlp__twitter-roberta-base-sentiment-latest'
I can also check that it was imported successfully with the following API call:
GET _ml/trained_models/cardiffnlp__twitter-roberta-base-sentiment-latest
And result (extract):
{
"count": 1,
"trained_model_configs": [
{
"model_id": "cardiffnlp__twitter-roberta-base-sentiment-latest",
"model_type": "pytorch",
"created_by": "api_user",
"version": "12.0.0",
"create_time": 1713255117150,
...
"description": "Model cardiffnlp/twitter-roberta-base-sentiment-latest for task type 'text_classification'",
"tags": [],
...
},
"classification_labels": [
"negative",
"neutral",
"positive"
],
...
]
}
Next, model must be started:
POST _ml/trained_models/cardiffnlp__twitter-roberta-base-sentiment-latest/deployment/_start
This is subject to licensing. You might face this error “current license is non-compliant for [ml]“. For my tests, I used a trial.
Filebeat Configuration
I will use Filebeat to read review.csv file and ingest it into Elasticsearch. filebeat.yml looks like this:
filebeat.inputs:
- type: log
paths:
- 'C:\csv_inject\*.csv'
output.elasticsearch:
hosts: ["https://localhost:9200"]
protocol: "https"
username: "elastic"
password: "password!"
ssl:
ca_trusted_fingerprint: fakefp4076a4cf5c1111ac586bafa385exxxxfde0dfe3cd7771ed
indices:
- index: "csv"
pipeline: csv
So each time a new file gets into csv_inject folder, Filebeat will parse it and send it to my Elasticsearch setup within csv index.
Pipeline
Ingest pipeline can perform basic transformation to incoming data before being indexed.
Data transformation
First step consists of converting message field, which contains one line of data, into several target fields (ie. split csv). Next, remove message field. This looks like this in Processors section of the Ingest pipeline:
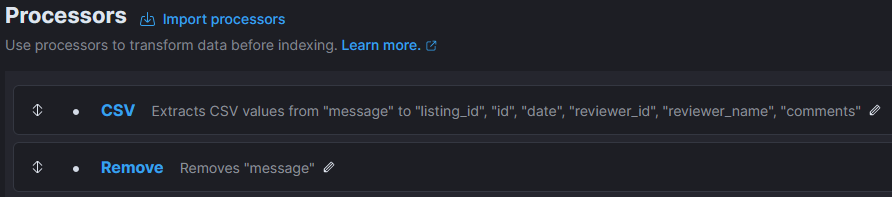
Next, I also want to replace the content of the default timestamp field (ie. @timestamp) with the timestamp of the review (and remove the date field after that):

Inference
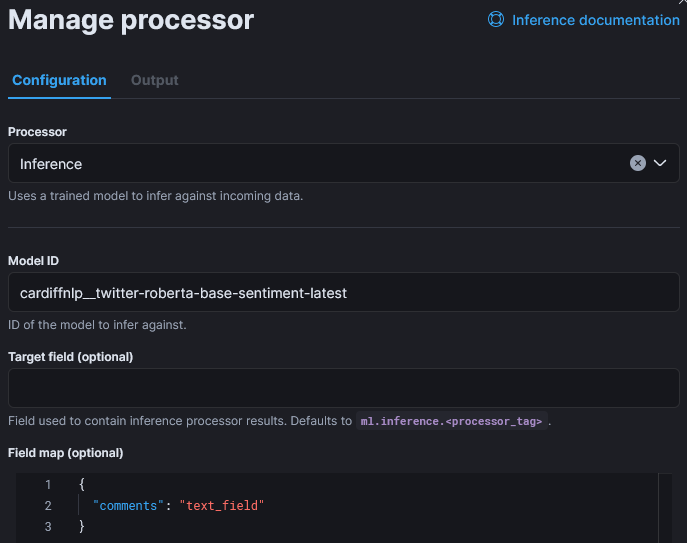
Now, I add the Inference step:

The only customization of that step is the field map as the default input field name is “text_field“, In the reviews, fields is named “comment“:
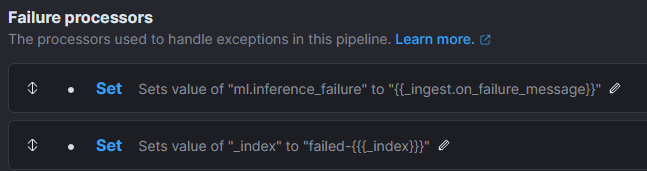
Optionally, but recommended, it is possible to add Failure processors which will set a field to keep track of the cause and will put them in a different index:
Ingest
Now, I can simply copy the review.csv into the watched directory and Filebeat will send lines to Elasticsearch. After few minutes, I can see the first results:

Or, a considered negative example with the associated prediction rate:

What Next?
Of course, we could try another model to compare results.
If you did not noticed, this was also a first step into Extract-transform-load topic (ETL).
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/OLS_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ENB_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/10/JPC_wev-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2023/03/KKE_web-min-scaled.jpg)