Introduction
Introduction
This morning I attended the first part of the pre-conf of the Data Platform Virtual Summit 2022 titled “Analytics at scale with Power BI and Azure Synapse” presented by Dave Ruijter.

Working a lot with Power BI and gathering experience with Azure Synapse Analytics , I was looking forward to have Dave’s point of view and experience on this combination of technologies.
It is always good to stay open minded and learn from other expertise and opinion.
We have seen first what are the challenges faced with Power BI and then Dave’s architecture proposal using Azure Synapse Analytics data lake to workaround these challenges.
Power BI Challenges
The 2 main challenges with Power BI is the volume of data that you can handle with it and the second is to show near real-time data.
To bypass the data volume issue you can use the DirectQuery mode instead of importing the data in Power BI. This way you will avoid loading data into Power BI and saving a lot of time to get data accessible in your Power BI report
But the DirecQuery mode has its limitation too. That what starts to be interesting during this session, is how to find solution to minimize these limitations.
The main issue with the DirectQuery mode is the slower performances to gather data and show it to the end user, the report becomes less attractive for the Power BI user experience and the dynamic aspect of the report is fading.
One simple possibility is to apply the query reduction within your report, avoiding to run queries each time the user applies a filter, and you will have to refresh the data manually when you are done with the filter you want to apply.
Azure Synapse Analytics
To increase user experience and bring better performance showing near-real time data with acceptable performance a possible solution is to use Azure Synapse Analytics.
Synapse has been developed a lot since the last couple of years and you have possibility to collect your data from your source system using the API. There are different ways to do it, but the combined use of pipelines and Spark Notebooks is a Dave’s recommendation as they are well integrated into the Synapse Analysis Studio.
Notebooks can be very practical when you have complex scenario to integrate your data. You can developed it using different programming languages within the same notebook and it’s easy to document it within the coding.
Dave’s proposal to to store the data is a Azure Synapse Analytics delta lake using the Bronze, Silver, Gold layers approach. That sound a very good option too.
The delta lake is coming on top of classical data lakes. They provide ACID transactions and will help you to build-up your data sets and history it easily and efficiently.
- Bronze layer is used to acquire the original raw data and keep the its history.
- Silver layer serves to cleanse, refine, filter and format the data.
- Gold layer is finally where you have you will prepare your data to consume it in your reporting system. It must be then fitting your needs by transforming, merging, aggregating, and modelling it, using star schema.
In order to access the data you can use Synapse serverless SQL pools.
For the serverless SQL pools there are also some information to know and best practices to follow:
- Serverless SQL pools must be warmed up. After a idle moment it goes in sleeping mode and it will take some time to wake it up again.
- Performances can be improved by
- Using the appropriate authentication method
- Locate them in the same region as your Power BI and your end users
- Privilege the parquet file format or data tables as they provide better performance
- Consider storing files with size between 100MG and 10GB to avoid to many costly i/o
- Use appropriate datatype
- Create partition and use filename and filepath function to target them
So your final architecture could be like this one.
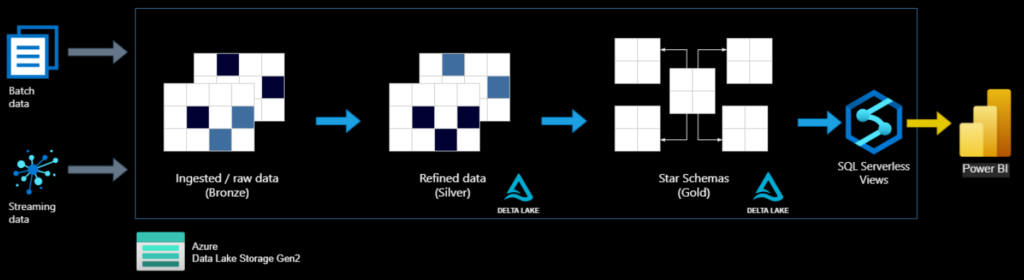
And if you still need improvement
Having the solution in place, you can face potential performance issues.
They are some tools to consider to analyze what happen before making changes.
Interesting was the demo using Power BI Performance Analyzer. You can copy the DAX Query directly from the Power BI Performance Analyzer and paste it in the DAX studio for further analysis with the Server Timing option.
VertiPaq Analyzer will give you a good understanding about the data volume you are dealing with in your Power BI report.
With this tools you will be able to know where the bottlenecks are and take action accordingly to optimize the response time of your Power BI report.
After having identified the potential problem you have several possibilities to improve your report:
- Make changes in your data model
- -Using query folding when possible with your source system
- Defining aggregation tables from your detailed info
- Adapt the storage mode
- Using Hybrid tables
- Incremental refresh
Be careful when using the incremental refresh you won’t be able to download the PBIX file from Power BI Service.
So backup your PBIX file versions in safe locations.
Monitoring and Cost control
You can now as well send information from the Power BI to Azure Log Analytics as well, but this feature is still not completely functional
You can find as well a Power BI report template on GitHub to analyze your Power BI platform activities
You can put alert on the log analytics to be warned when some events arise. You can use KQL (Kusto Query Language) to set it up.
It sis recommended to set data consumption limits per day, week and month on your Synapse Analytics. When you use DirectQuery a lot of transactions will run over your SQL serverless pools, they can treat a high volume of data and therefore high costs. This will help you to control your costs on handled by SQL serverless pool.
It is as well recommended to set budget on your subscriptions and resource groups level
Conclusion
It was an interesting session, I could grab some very good information and ideas.
Using delta lake as a data source for Power BI report is something I will definitely test and evaluate.
I could only regret that the demos were not really functioning as expected or not illustrating enough the subject.
But overall it was a great session with lot of valuable information and hints.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/09/CHC_web-min-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/10/STS_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/03/AHI_web.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/07/ALK_MIN.jpeg)