Let’s continue with the new high available functionality shipped with the next Windows version. In my previous blog, I talked about the new site awareness feature that provides more flexibility to configure failover resources priorities and more granular heartbeat threshold as well by introducing the new site concept. This time, we’ll talk about stretch cluster. What’s that? Let’s introduce the concept with some customer experiences for which we introduced high availability with the implementation of Windows failover cluster architectures. In most cases, they included at least two cluster nodes and sometimes more. At some customer places, I saw different implementations where nodes were either located in one datacenter or spread across two or three data centers (the latter being more an exception in my area). Let’s focus on the customers where cluster nodes are located in one datacenter. Often, it was a financial choice because they didn’t have any replication stuff at the storage layer, so we were limited on the possible scenarios. So, what about disaster recovery scenarios? In some cases, we had to introduce another built-in technologies to meet the DR requirements in addition to the existing high available solution like log-shipping or mirroring. I already encountered customers who used other third-party software from big players on the market as SIOS or Vision solutions that provide SANless based solutions. I remember one of my customers where the Windows failover cluster ran on the top of double-take solution and I may confirm that it worked pretty well in his context.
Stretch cluster is a newbuilt-in capability shipped with Windows Server 2016 in order to respond to the scenario described above. It will extend a usual cluster scenario from being a high available solution, to also being a disaster recovery solution by stretching servers in separate locations in the same cluster. Storage replication stuff is carried out by the new Windows feature called storage replica (SR).
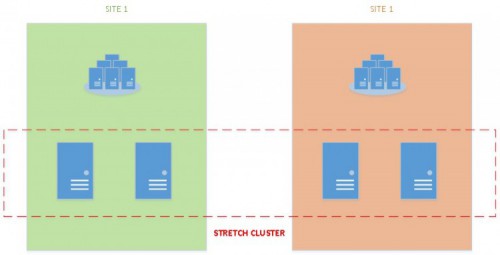
This is also a good opportunity to achieve lower RPO and RTO for disaster recovery solutions by using the same feature both for high availability and disaster recovery.
After talking about the concept, let’s demonstrate how it works by using my high available lab environment that includes:
- 1 domain controller (Windows Server 2012 R2)
- 2 Windows storage servers that use ISCSI initiators available only by one cluster node (Windows Server 2012 R2)
- 2 cluster nodes that rely on ISCSI storage (Windows Serer 2016 TP4)
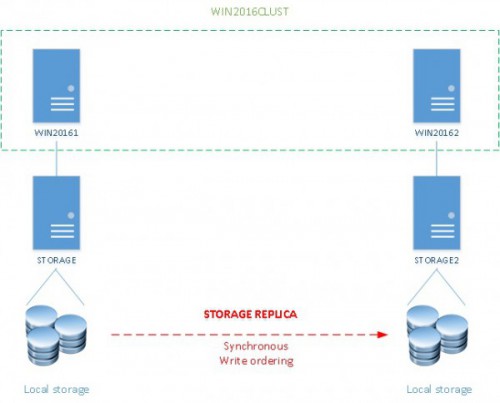
This is an infrastructure for testing purpose only. For example, I didn’t use any MPIO capability at the storage layer or I didn’t try to dedicate the replication workload to a specific network card (even if with the current TP we are able to restrict only the use of the SMB traffic to a specific network by using the New-SmbMultichannelConstraint cmdlet). In short, I just tried to simulate a very simple scenario where each cluster node is located on a different data center and on the same subnet. The main idea here is to configure a minimal SR configuration
Let’s begin by configuring storage replica. Microsoft provides a new Test-SRTopology cmdlet to test a specified topology as follows:
Test-SRTopology -SourceComputerName WIN20161 -SourceVolumeNames E: -SourceLogvolumnename G: -DestinationComputerName WIN20162 -DestinationVolumeNames E: -DestinationLogVolumeName G: -DurationInMinutes 30 -ResultatPath C:\Temp
This command checks if all prerequisites are met to achieve the replication stuff. Different configuration items and performance replication metrics are verified as you can see below. But we’ll talk about the prerequisites later in this blog post.

According to the Microsoft documentation, each enclosure must contain at least one volume for data and one log volume for replica stuff. Storage replica will use the dedicated log volume as a database transation-like log. We may find out similar behaviors where high availability architectures like mirroring or lately availability groups. Thus, when application performs an IO, log data is written to the local storage log and then replicated and finally hardened to the remote site. At the last step, an acknowledgment is sent from the remote site to the application. This ensures constant synchronization of the remote site with the source site. Furthermore, storage replica may act as a buffer cache where data may be aggregated before being flushed out to disk.
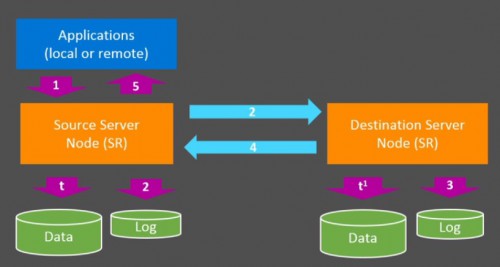
Picture from the Ignit session about stretch cluster with Elden Christensen & Ned Pyle
So in my case the E: drive is the data volume where I will put my SQL Server database data files and the G: drive will act as log for storage replication stuff in both sites.
Go ahead and let’s have a look at the report genetared by the Test-SRTopology cmdlet. The report is divided into several sections. The first section is an overview of the tested topology as shown below:

At the bottom we may find out a quick summary with eventually errors or warnings messages encountered during the testing process. In my case, the storage topology seems to meet all the storage replica prerequisites.
Next, let’s have a look at next section that concerns the requirements checked by the PowerShell cmdlet:

We may notice different categories of requirements which respond to the following questions:
- Are my partitions configured with GPT?
According to Ned Pyle, MBR disks are not intentionally supported because their own partition formats which are not predicted and data may go back to empty in some cases. GPT is more reliable and will be used for storage replica.
- Are my drives configured identically in both sides?
No matter if your disks are physically the same in terms of model or manufacturer but concerned data and log drives must be identical in terms of geometry that includes block format, sector size and identical filesystem as well. Storage replica is very flexible on this topic and this is a good news because it carries out any Windows volume, any fixed disk storage or any storage fabric.
- Have I provisioned enough free space for storage replication drive?
Microsoft recommends at least 8GB of free space in order to carry out your disaster but this is not mandatory. However, let’s say if you face a storage issue at the destination … in this case, you will probably have to answer to the following question: how long the destination may be turned off before the log would wrap?
- Is my network latency under to the recommended threshold for storage replication stuff?
Microsoft recommends to have less than 5ms round trip in average but lower latency you have, better performance you will get for sure. Generally speaking in my area, I often worked with customers where data centers are far from 50km and 300k. So getting low latency in this case is not much an issue.
- Is SMB connectivity enabled between the two SR nodes?
Storage replica runs on the top of SMB 3.1.1 transport protocol so checking if SMB connectivity is enabled does make sense here J
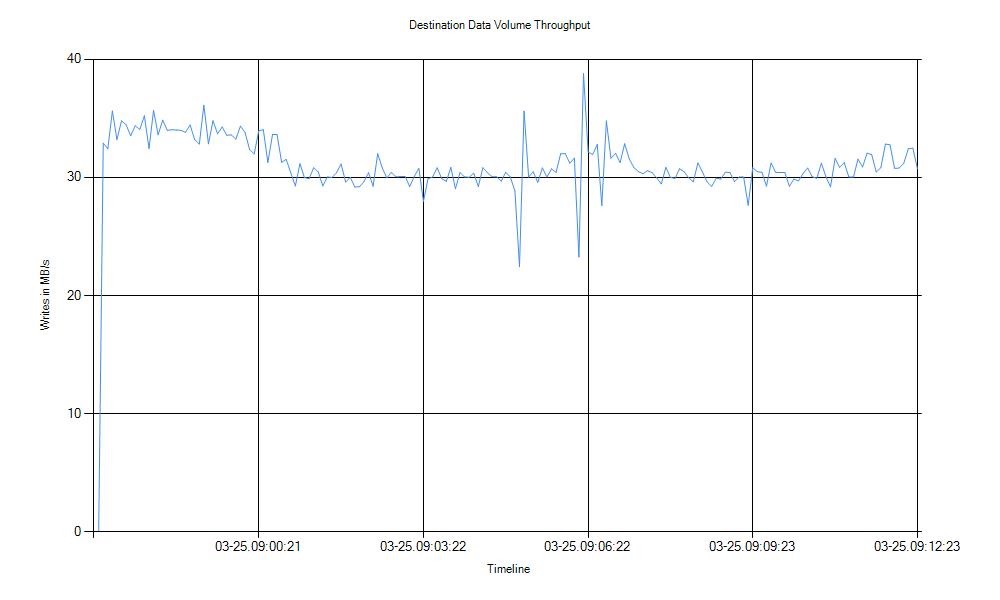
The other interesting section of the validation report concerns the initial synchronization performance where both disk throughput and disk latency are tested. In case, I got very satisfying results from my disks. In fact, I met the Microsoft recommendation by using my SSD disk.
 |
 |
Indeed, Microsoft recommends to use fast disks for storage replica logs (SSD or NVME technologies) to carry out the IO replication traffic.
In addition, SQL Server is generally an intensive IO based application, so bear in mind to have sufficient network bandwidth for your corresponding IO workload.
Ok at this point, my disk topology is ready to be part of my future storage replica configuration. The first step will consist in creating a simple Windows Failover cluster by using the following PowerShell command
New-Cluster -Name "CN=WIN2016CLUST, OU=Clusters, DC=dbi-services, DC=test" -Node WIN20161, WIN20162 -StaticAddrress 192.168.5.30
Next, I will include a File Share Witness to my quorum configuration
Set-ClusterQuorum -FileShareWitness \\DC\quorum\clust-
That’s all, my cluster is now ready to use storage replica! At this point, using PowerShell to configure replication is a possible way but let’s switch to the cluster manager GUI to continue configuring the replication storage stuff. Let’s say now a new menu is available and located to the Storage > Disks node as shown below:
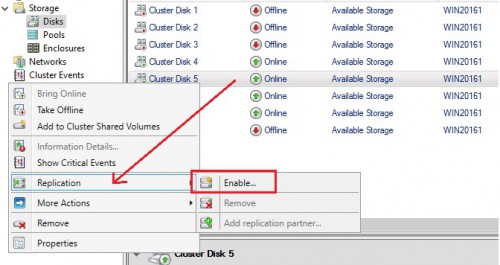
However enabling replication requires to provision a cluster shared volume as the first step. Otherwise, you will face the following information message:
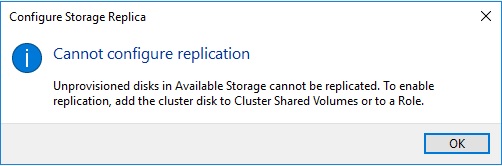
No problem provisioning a CSV is not a big deal …
![]()
So after provisioning the CSV from the concerned disk, let’s now configure SR by using the new wizard that is very intuitive. The deal here consists in choosing the destination data disk (E: drive in my case) and then enrolling the concerned disks for the storage replication stuff (G: drives)
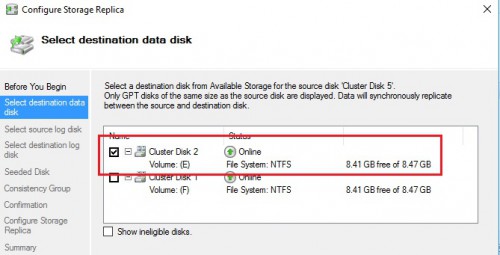
…
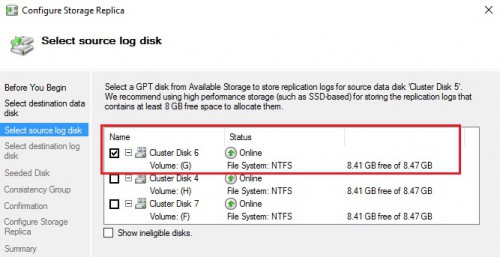
…
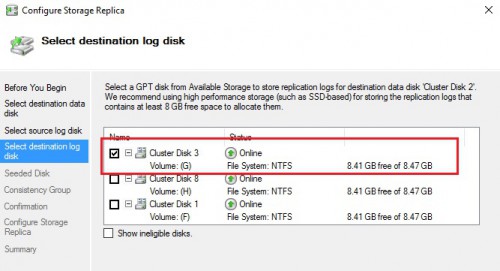
The next section concerns the seeded disk method. We have to choose between seeding or overwriting data at the destination regarding our specific context. In my case, the destination disk may be overwritten safely because it doesn’t contain any existing data to synchronize with the source.

Finally, the last important step of this wizard. You have to choose between prioritizing performance or enabling write ordering. Of course in our case, the second method must be chosen because we’ll run SQL Server on the top of the SR which must guarantee write ordering in order to meet the WAL protocol.

We are now ready to implement storage replica for the SQL Server data volume
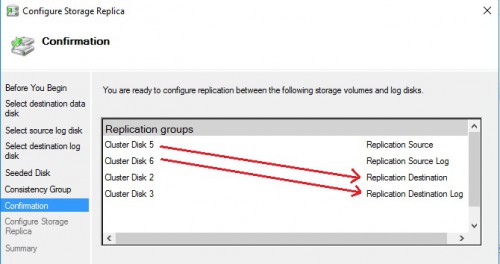
Then, I performed the same configuration steps for the SQL Server log volume. So, I enrolled four disks in my case. Here an overview of the final storage replication on my lab environment. You may notice a new column named “Replication role” with different values from the cluster manager GUI.
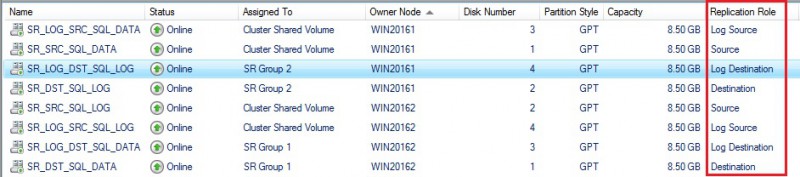
In short, I configured two SR groups that include each one data volume (for SQL Server data or SQL Server log files) and their respective storage replica log volume. We may get more details of each volume context from the new replication view at the bottom:
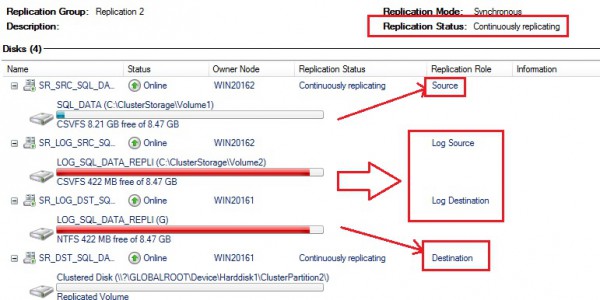
One important information here is the storage replication status available at the top with the specific value “Continuously replication” in my case. You may also notice all the disks concerned by the storage replica topology (both the source and destination data disks and the corresponding replica log disks as well).
The SR configuration stuff is now over and the next step will consist in installing a SQL Server failover cluster. This is a usual task performed by many database administrators and in this specific context, there is a particularity. Here my SQL Server FCI configuration:
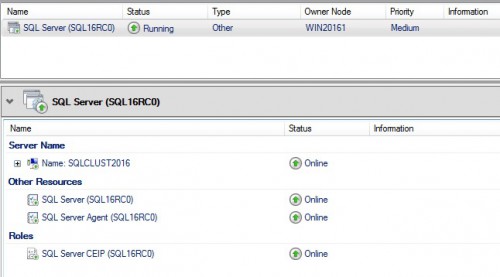
This is a classic configuration with usual cluster resources and dependencies for SQL Server in the clustering context. The last part of this blog is probably more interesting and will concern some tests performed against this new architecture.
My first test consisted in simulating a failure at the storage destination with a simple turn off and at the same time performing a data insert into a SQL table in my SQL Server FCI. As expected, the IO replication traffic was suspended because the destination was no longer available. So no big surprise here.
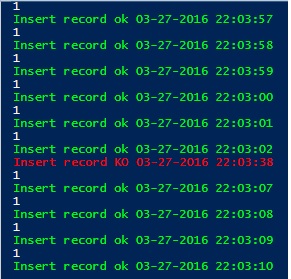
I decided to perform a more interesting second test that consisted in simulating failure of the source local storage while performing in the same time the insert data stuff into my SQL table. I wanted to see what happens in this case. Will the SR redirect the IO traffic to the destination transparently? Let’s verify … In fact, after simulating the storage failure, I experienced one SQL Server data insert failure at 22:03:38 and then the insert stuff has got back to normal as shown below (note that the insert operation occurred at 22:03:07 and the insert failure is related to timeout issue)
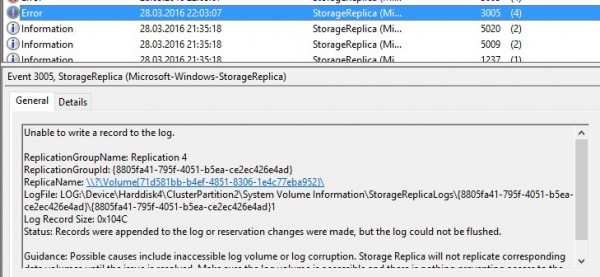
Let’s take a look at the event viewer directly on the Applications and Services \Microsoft \Windows \StorageReplica \Admin on the cluster node that relies on the source storage (WIN20161). We may notice some errors with event id = 3005 that correspond to the failure of the local storage and the inability of the storage replica to write record logs at this specific moment:
From the destination server (WIN20162):
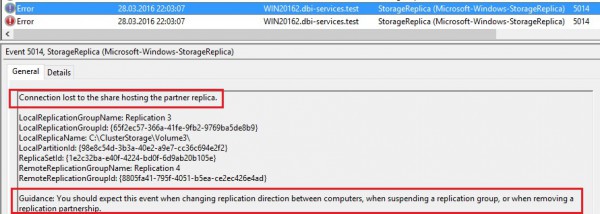
But after 30 seconds of failure, inserting records into the SQL table was not anymore an issue because the IO were redirected to the destination as a new source. We may find out this kind of message inside the event viewer:
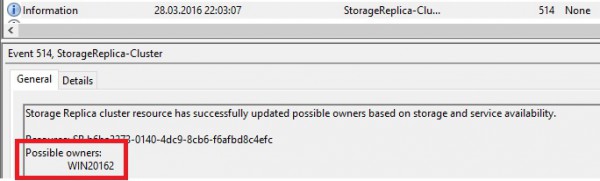
The new situation is as follows:
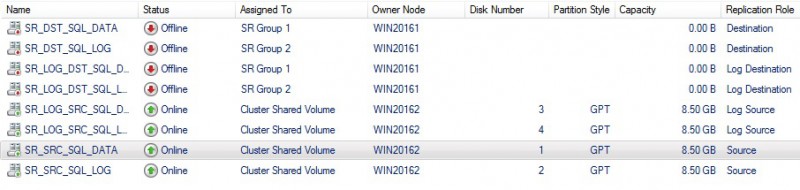
All of the destination disks are now offline and we may notice that the source has changed from WIN20161 to WIN20162 node. Of course, each synchronization status is suspended at this time. So this test tends to demonstrate that experiencing a failure at the storage layer is not as transparent as we may expect (I always have the dream to see transparent failover in the back of my mind) but I can’t blame because the final result is more than satisfying from my point of view.
Let’s bring online the local storage for the WIN20161 node and let’s see if everything comes back to a normal state. In fact, I noticed no changes from the storage replica view with the overall replication state that remains suspended and this is why I decided to check directly to the disks on the WIN2016 node. I was not surprised to see that they were reserved by the cluster itself but there was no way to bring online the corresponding resource from the cluster manager.
By taking a look at the event viewer on the WIN20161 node, I saw the following record related to my attempt to bring online the disk.
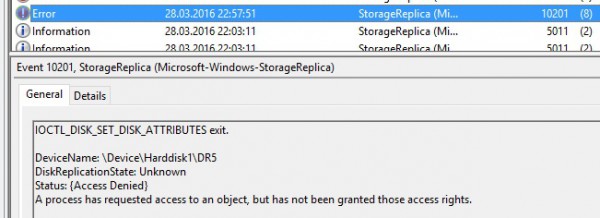
It seems that performing some changes on the disk attributes directly from the disk manage is not possible at this point. So after some investigations and some readings of the Microsoft article here, I decided to break the disk reservation by using the Clear-ClusterDiskReservation cmdlet to make them eligible to available storage for replication.
$disks = Get-Disk | Where-Object { $_.OperationalStatus -eq "Offline" }
$disks | ? Foreach
{
Clear-ClusterDiskReservation -Disk $_.Number
}
And this time I noticed my storage replication state changed successfully from the SR view:
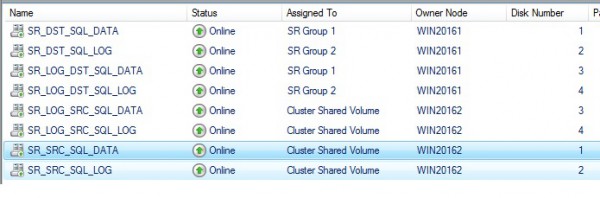
My guess is that it is a known issue as stated in the Microsoft documentation and it will be probably resolved in a next release of Windows Server 2016 (I hope before the RTM).
The bottom line
Stretch cluster will allow to extend some scenarios where we were limited so far. But, using storage replica comes with a lot of strong restrictions for the moment. Indeed, we must have a well sized and performing physical infrastructure and we also have to keep in mind that SR is shipped only with the datacenter edition feature. Implementing stretch cluster will probably not be as cheap as we may expect but we may oppose a strong argument here: what about the cost of such infrastructure with other replication providers either at the storage layer or with third party tools? Well, from my part I prefer to wait a more complete version of SR. Indeed, some improvements may be added to this new feature to address other requirements like adding performing storage replication in a transitive way and we you may get an idea of some trends here. I’m looking forward to make further tests with the future production release.
Happy clustering!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/03/AHI_web.jpg)