A couple of days ago, I was in charge to install a new SQL Server AlwaysOn and availability group with one of my colleague Nathan Courtine. During the installation, we talked about testing a disaster recovery scenario where we have to restart the Windows Failover cluster in forced quorum mode.
Restarting a WSFC in such mode implies some internal stuff especially for the cluster database data synchronization between nodes. The WSFC uses internally the paxos algorithm to synchronize and guarantee consistency across distributed systems. But what is paxos concretely? To be honest, I already saw some records inside a generated cluster log but I never cared about it. But as usual my curiosity led me to investigate further and I learn some very interesting stuff from 2001 paper Paxos Made Simple and from other pointers on the internet. Just to be clear, I’m not claiming to master completely this protocol and this is simply my attempt to demystify the subject.
So let’s begin with the introduction of some important concepts to understand:
First of all, Paxos is an algorithm for agreeing a value (in other words a configuration change in our case) across a cluster using atomic broadcast. This is known as the consensus problem which is described in this Paxos Paper. In short, this algorithm lets a majority of nodes agree one value at a time.
According to this KB947713 we may read that the WSFC uses a paxos tag that consists of three numbers with the following format:
<NetxEpoch number>:<LastUpdateEpoch number>:<sequence number>.
Let’s have a focus on the last part. The KB947713 says:
Each time the configuration is changed every time that an update is made to the cluster configuration. The synchronization process in a cluster sends out a proposal to all the nodes in the cluster. The proposal consists of a sequence number and a proposal number.
Why a proposal number here? In the next part of this blog post I will discuss how important this concept may be but at the moment, let’s go back to the paxos algorithm protocol and let’s see how it works. In fact, we may identify two distinct phases in this protocol:
Phase 1:
A proposer will send a proposal (prepare message) to a set of acceptors in the form of a proposal {Sequence, Number}. The concerned acceptors acknowledge that they guarantee that once the proposal is accepted, they cannot accepted any more proposals numbered less than n.
Phase 2:
Once the proposer obtains the required consensus from the majority of nodes (we don’t need to get responses from all the nodes here), it will choose in turn a value (if no acceptors are already accept proposals with value) and will broadcast an accept message to the corresponding acceptors to commit the value. Finally, the acceptors acknowledge the leadership of the proposer. Note that in the cluster implementation a leader plays both the roles proposer and learner.
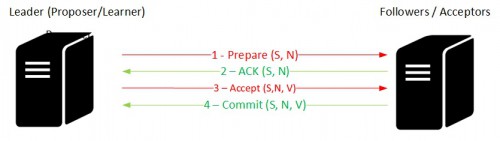
What about having two proposers at a time here? In fact, Paxos is designed to protect against this kind of scenario that may lead to a situation where each proposer keeps issuing a sequence of proposals with increasing numbers, none of them is ever chosen because, as you remember, the corresponding acceptors will refuse them (no promise or no accept acknowledgement because of a new higher proposal). It addresses this scenario by electing one distinguished proposer to communicate with a set of acceptors at a time.
Let’s now continue by introducing a little bit more complexity with a distributed scenario where failures may occur at different time of the paxos protocol. For those who work with distributed environments, failures may occur more than expected. For example, we may face disruptive network issues that lead to missing messages from nodes in the paxos phases or acceptors / proposers that fail. We may also have to deal with failover scenarios (either planned or unplanned).
So we need a protocol that is both fail-stop and fail-recover resilient algorithm. These scenarios are handle by the Paxos phases design. Indeed, in case of a leader failure, sending a prepare-to-commit request allows any participant to take over the role of the new leader and query the state from other nodes. If any acceptor reports to the new leader that it has not received the “prepare to commit” message, the latter knows that the transaction has not been committed at any acceptor. Now either the transaction can be pessimistically aborted, or the protocol instance can be re-run. In the same manner, if an acceptor that has committed the transaction crashes, we know that every other acceptors would have received and acknowledged the prepare-to-commit message since otherwise the coordinator would not have moved to the commit phase. So the coordinator can proceed with the last phase.
We should also take into account cluster network partition scenarios. Paxos is partition tolerant because it requires a consensus from a node majority. So a partition that cannot come to a consensus needs to accept value from other partitions when they merge back.
Behind the scene, Paxos will handle failures by implementing a machine state system where each component may play all roles (proposer, learner and acceptor). Multi-paxos protocol will be used across the system to guarantee that all server will execute the same sequence of the same machine. We may think this concept is similar to a database transaction log where operations are written sequentially and in order.
Let’s describe how Paxos deals with different kind of failures. In order to facilitate understanding the protocol, I voluntary simplified the process. For example, I always assume that the consensus is correctly made when a proposer send a proposal to a set of acceptors. In addition, I illustrate each scenario with only one leader and one proposer and I obviously image that the scenario is not as simple in all cases.
Firstly, let’s say an acceptor missed an accept message from the proposer caused by a network failure in my case.
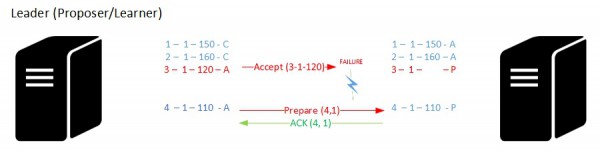
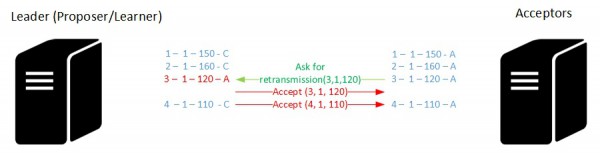
The acceptor may ask the retransmission of the concerned message to the leader for a particular sequence of the state machine. Optionally, the concerned acceptor may also request additional accept messages in the same time to keep it up-to-date.
Let’s now have a look at the failures about the leader. When a new leader is mandated, the system must firstly prevent the older leader (which may have recovered from failure and think it is still the leader) from disrupting consensus once it is reached. Remember that in this case the system guarantee that only one distinguish leader must propose values.
When a node is mandated as a new leader (which acts as a learner in all instances of the consensus algorithm) it should be aware of commands already committed from the older one as well as other uncommitted slots. The process may be different here regarding if the new leader is aware or not of uncommitted slots it has to fix. But let’s deal with the scenario where it is aware of uncommitted commands.

You may see an uncommitted command at slot 3. The consensus was made for the concerned proposal but old leader didn’t send the corresponding value (probably caused by a failure) leaving the command uncommitted. Then a new leader has been elected and it should fix all uncommitted slots from the old leader.
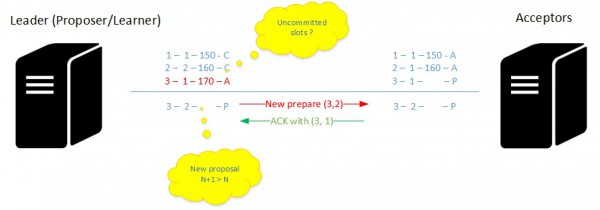
For that, it must send new fresh proposal to get info from the acceptors that will respond by sending the highest uncommitted proposal along the slot position.
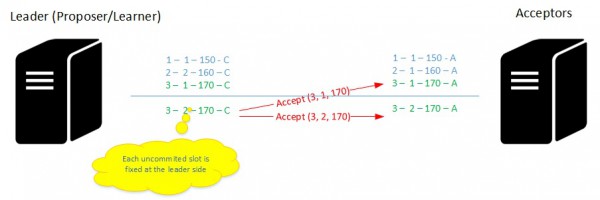
At this point, assuming the consensus was made for the set of acceptors, the proposer then broadcasts an accept message with the corresponding value and fix all the uncommitted proposals in the slot. Of course, the process is a little bit more complex with probably other many failure and recovery scenarios as well as some additional optimizations. But we get the basics here.
So now let’s go back to the WSFC. Several components are involved to manage the global cluster configuration. Firstly the database manager (DM) on each cluster node stores a local copy of the cluster configuration. Each configuration change is handled by the database manager that uses in turn the global update manager (GUM) to broadcast changes to other nodes. DM uses paxos tag to coordinate and guarantee the consistency of the cluster configuration across all the nodes. The GUM guarantees changes are mare atomically either all healthy nodes are updated, or none are updated.
So let me show you how the WSFC deals with a node join operation (WIN20121 is the existing cluster node and WIN20122 node is added in my case) by taking a look at the cluster log. I firstly changed the log level from 3 to 5 to add INFO and DEBUG messages. Indeed, such information is not recorded by default into the cluster.log.

Here the WIN20111 cluster node is the current the leader of the distributed topology. The current epoch number is 0 because this is the first time the cluster is formed.
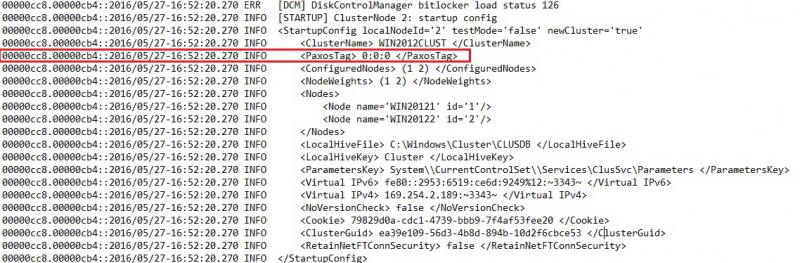
On the other side, WIN20122 starts up with an initial configuration that uses the same epoch number.

We may notice here the current paxos tag is 0:0:0 meaning that no changes occurred yet. A new transaction is then started by the database manager.


The paxos algorithm is in action here and we may notice the phase 2 of the protocol. The leader is sending an accept message for each proposal (P, V)

And finally we may see the paxos commit phase from the new joining node. The paxos tag value is incremented by 1 and new value is 0:0:1.
In this final section, I just want to cover briefly a misconception about file share witness (FSW). I often heard that the witness (regardless its type) stores the cluster configuration. This is true only when we talk about disk witness. However, file share witness stores only store the last paxos tag in the witness.log file.
Let’s take a look at the cluster.log when joining a new FSW.

…
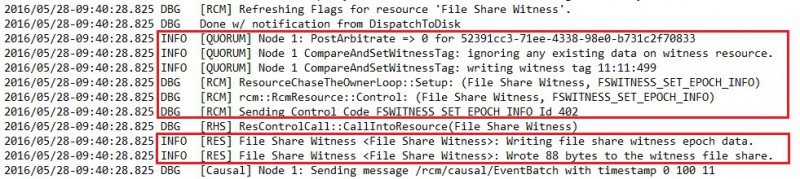
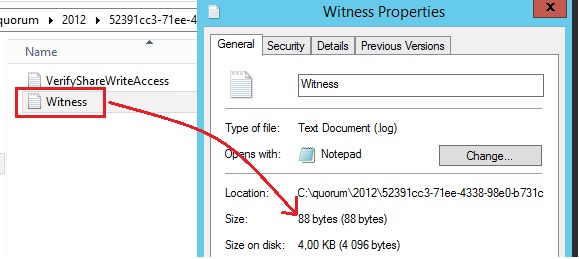
Firstly, the system must acquire a lock on the witness log. It then compares paxos tag between the leader and the FSW. In this case it writes the more recent paxos tag value into the witness file (FSWITNESS_SET_EPOCH_INFO) with a payload of 88 bytes. We may notice the size of the file witness.log corresponds to the payload size as shown below:
Hope this article will help to demystify the paxos basis. Happy clustering!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/03/AHI_web.jpg)