Did you ever consider an index seek as an issue? . Well, let’s talk about a story with one of my customers where the context is pretty simple: a particular query that is out of the range of the application’s performance requirements (roughly 200ms of execution time in average). The execution plan of the query was similar to what you may see in the picture below:

At first glance, no obvious way to improve the performance of the above query right? The query was similar to the following one (with some exceptions with the real context but it does not matter in our case):
DECLARE @id VARCHAR(10) = 'LPKL'; SELECT [Num_DUT], [Etat], [Description], Etape_Process FROM [dbo].[evenements] WHERE actif IS NULL AND [date] >= '20160101' AND SUBSTRING(DM_Param, 12, 4) = @id
Here the definition of the dbo.evenements table.
create table dbo.evenements ( [date] datetime, Actif BIT NULL, Etape_Process VARCHAR(50), DM_Param VARCHAR(50), Num_DUT INT, [Etat] VARCHAR(10), [Description] VARCHAR(50) )
Let’s set quickly the context. This table is constantly filled up by information from different sensors. The question that came in my mind at this moment was why an index seek is used here regarding the query predicate? After all, we may noticed a parallel execution plan (cost threshold for parallelism is by defaut) that leads to ask questions about the index seek’s behavior. The index used in this query was as follows:
CREATE NONCLUSTERED INDEX [idx_dbi_Evenements_actif] ON [dbo].[evenements] ( [Actif] ASC, [date] ASC, [Etape_Process] ASC, [DM_Param] ASC ) INCLUDE ( [Num_DUT], [Etat], [Description]) WHERE [date] >= '20160101'
Regarding the index definition, if we take a look closely at the WHERE clause of the query, we may assume that using a seek operator in the execution is a little bit tricky.
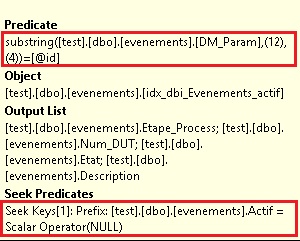
Indeed, predicting the selectivity of the SUBTRING part of the clause presents a big challenge for SQL Server in this case. The cardinality estimation seems to be wrong event after updating the dbo.evenements statistics.

So the next question that came in mind concerned the index seek operation itself. Is it really an index seek? I based my assumption upon the use of parallelism in the execution plan. Why using parallelism if I just have to get 2100 rows which represent only 0.2 % of all the data in my case? I remembered an old article written by Paul White in 2011 with the title When is a Seek not a Seek?
So referring to this article I moved directly on the output of the SET STATISTICS IO
Table ‘evenements’. Scan count 5, logical reads 10590, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Well, the situation is more obvious here if we take a look at the number of pages included to the nonclustered index.

In fact, each seek is a partial scan to search the corresponding values that satisfy SUBSTRING(DM_Param, 12, 4) predicate at the leaf level. Why 5 scans here? Well my assumption here is the SQL Engine is using 4 threads in parallel to perform a partial scan as shown below:
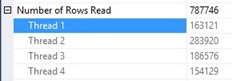
Let’s do some math here. Each thread fetches approximatively 2600 pages regardless all the details, so we are not so far from the total logical reads displayed by the SET STATISTISC IO previously (4 x 2600 = 10400).
That said, we identified the cause of the high query cost but we did not respond to the main question: Are we able to reduce it? Well, to answer the question, let’s come back to the query semantic. At this point, we get stuck by the current predicate. After some further discussions with the customer and the data semantic of the table dbo.evenements, we identified that the DM_Param column doesn’t meet to the first normal form because it does not contains atomic values (the sensor identifier + some additional parameters) making it non sargable.
Moreover, to introduce another difficultly the SUBSTRING() function arguments were purely dynamic in this and must be adjusted to extract the correct identifier value regarding the line record. Finally we decided to update the initial scheme to meet the normal form rules. Thus, we introduced an additional table to store sensors identifiers and we used a non-semantic primary key to join the dbo.evenements table as well. Of course the NUM_DT column values should be updated accordingly to the new scheme.
Better for performance? Let’s have a look at the new execution plan

The execution cost dropped under the threshold of parallelism value in such way that we were able to use a serializable plan.
What about IO statistics?
Table ‘evenements’. Scan count 1, logical reads 28, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘identifier’. Scan count 0, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
The above output is meaningful by itself. In the context of my customer we successfully reduced the execution time from 200 – 300s to 2-3ms on average. Of course a big improvement at the price of some changes from the application side that concern insert / update / delete operations. But once again we concluded after prototyping of new insert / update / delete operations that they were not really impacted in terms of performance.
Happy performance troubleshooting!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/11/LTO_WEB.jpg)