Have you ever attempted to bulk import a SQL Server error log in order to use the information inside a report for example? If yes, you have probably wondered how to keep data in the correct order in a query because you cannot refer to any column from the table. In such case you can notice that you may have many records with the same date. Of course, there exists some workarounds but this is not the subject of this blog. Instead, I would like to share with you an interesting discussion I had with a forum member about the guarantee to get the SQL Server error log data in order with a simple SELECT statement without an ORDER BY clause.
Let’s begin with the following script which bulk import data from a SQL Server error log file inside a table:
You may notice that we use FIRSTROW hint to begin from the 6th line and skip information as follows:
In addition, using DATAFILETYPE = ‘widechar’ is mandatory in order to bulk import Unicode data.
Let’s continue and after bulking import data let’s take a look at the data itself inside the table. You will probably get the same kind of sample information as follows:
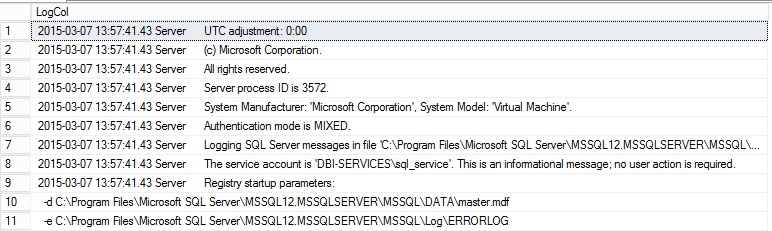
Comparing records order between the SQL Server error log file and the table tends to state that the order is the same. At this point, we may wonder how to number the records inside the table without affecting the table order. Indeed, numbering records in the table will allow to control the order of data by using the ORDER BY clause. So go ahead and let’s using the ROW_NUMBER() function in order to meet our requirement. You may notice that I use an “artificial” ORDER BY clause inside the windows function to avoid to interfere with the original order of getting data in my table.
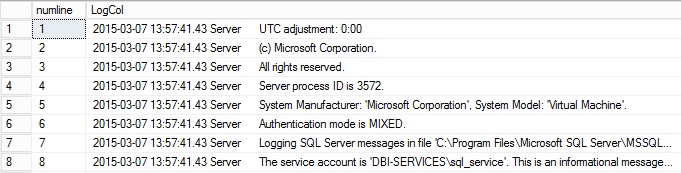
At this point, the forum member tells me that we cannot guarantee the order of data without using an order by clause but once again, it seems that we get the same order that the previous query but can I trust it? I completely agree with this forum member and I tend to advice the same thing. However in this specific case the order seems to be correct but why?
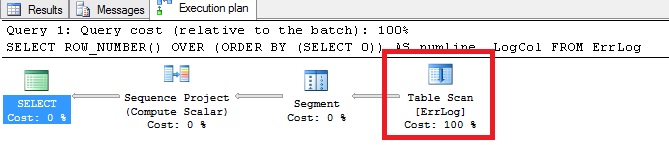
If you take a look at the first script, the first operation consisted in creating a heap table. This detail is very important. Then, the bulk insert operation reads sequentially the file and insert the data in the allocation order of pages. It means that data insertion order is tied to the allocation order of the pages specifying in the IAM page. So when we perform a table scan operation to number each row in the table (see the execution plan below), in fact this operation will be performed by scanning the IAM page to find the extents that are holding pages.
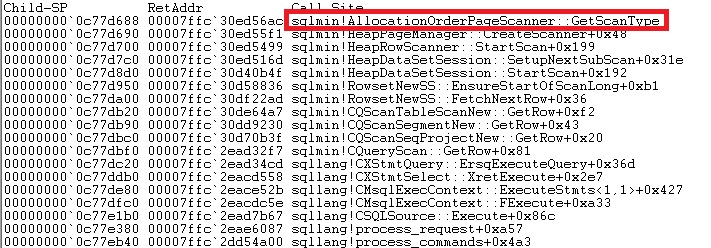
As you know, IAM represents extents in the same order that they exist in the data files, so in our case table scan is performed by using the same allocation page order. We can check it by catching the call stack of our query. We may see that the query optimizer uses a particular function called AllocationOrderPageScanner for our heap table.
So, that we are agreed, I don’t claim that in all cases we may trust blindly the data order without specifying the ORDER BY clause. In fact, I’m sure you will have to process differently most of the time depending on your context and different factors that will not guarantee the order of data without specifying the ORDER BY CLAUSE (bulking import data from multiple files in parallel, reading data from table with b-tree structure in particular condition etc…)
Enjoy!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/FRJ_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/01/HME_web.jpg)