For a recent project at one of our customers we needed to get data from a Db2 database into PostgreSQL. The first solution we thought of was the foreign data wrapper for Db2. This is usually easy to setup and configure and all you need are the client libraries (for Db2 in this case). But it turned out that db2_fdw is so old that it cannot be used against a recent version of PostgreSQL (we tested 15,16,17). We even fixed some of the code but it became clear very fast, that this is not the solution to go with. There is also db2topg but this is not as advanced as it’s brother ora2pg and we did not even consider trying that. Another tool you can use for such tasks is dtl (data load tool), and it turned out this is surprisingly easy to install, configure and use. You are not limited Db2 as a source, much more options are available.
As the customer is using Red Hat 8 for the PostgreSQL nodes, we start with a fresh Red Hat 8 installation as well:
postgres@rhel8:/u02/pgdata/17/ [PG1] cat /etc/os-release
NAME="Red Hat Enterprise Linux"
VERSION="8.10 (Ootpa)"
ID="rhel"
ID_LIKE="fedora"
VERSION_ID="8.10"
PLATFORM_ID="platform:el8"
PRETTY_NAME="Red Hat Enterprise Linux 8.10 (Ootpa)"
ANSI_COLOR="0;31"
CPE_NAME="cpe:/o:redhat:enterprise_linux:8::baseos"
HOME_URL="https://www.redhat.com/"
DOCUMENTATION_URL="https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8"
BUG_REPORT_URL="https://issues.redhat.com/"
REDHAT_BUGZILLA_PRODUCT="Red Hat Enterprise Linux 8"
REDHAT_BUGZILLA_PRODUCT_VERSION=8.10
REDHAT_SUPPORT_PRODUCT="Red Hat Enterprise Linux"
REDHAT_SUPPORT_PRODUCT_VERSION="8.10"
PostgreSQL 17 is already up and running:
postgres@rhel8:/u02/pgdata/17/ [PG1] psql -c "select version()"
version
----------------------------------------------------------------------------------------------------------------------------
PostgreSQL 17.5 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-26), 64-bit
(1 row)
For not messing up with the Python installation from the operating system, we’ll use a Python virtual environment for dlt and install libjpeg-turbo-devel and git as those are required later on:
postgres@rhel8:/home/postgres/ [PG1] sudo dnf install libjpeg-turbo-devel git
postgres@rhel8:/u02/pgdata/17/ [PG1] sudo dnf install python3-virtualenv -y
postgres@rhel8:/u02/pgdata/17/ [PG1] python3.12 -m venv .local
postgres@rhel8:/home/postgres/ [PG1] .local/bin/pip3 install --upgrade pip
postgres@rhel8:/u02/pgdata/17/ [PG1] . .local/bin/activate
Once we have the Python virtual environment ready and activated, the installation of dlt is just a matter of asking pip to install it for us (for this you need access to the internet, of course):
postgres@rhel8:/u02/pgdata/17/ [PG1] .local/bin/pip3 install -U "dlt[postgres]"
postgres@rhel8:/home/postgres/ [PG1] which dlt
~/.local/bin/dlt
Having that installed we can initialize a new pipeline based on the sql_database template and we want “postgres” as the destination:
postgres@rhel8:/home/postgres/ [PG1] mkdir db2_postgresql && cd $_
postgres@rhel8:/home/postgres/db2_postgresql/ [PG1] dlt init sql_database postgres
Creating a new pipeline with the dlt core source sql_database (Source that loads tables form any SQLAlchemy supported database, supports batching requests and incremental loads.)
NOTE: Beginning with dlt 1.0.0, the source sql_database will no longer be copied from the verified sources repo but imported from dlt.sources. You can provide the --eject flag to revert to the old behavior.
Do you want to proceed? [Y/n]: y
Your new pipeline sql_database is ready to be customized!
* Review and change how dlt loads your data in sql_database_pipeline.py
* Add credentials for postgres and other secrets to ./.dlt/secrets.toml
* requirements.txt was created. Install it with:
pip3 install -r requirements.txt
* Read https://dlthub.com/docs/walkthroughs/create-a-pipeline for more information
postgres@rhel8:/home/postgres/db2_postgresql/ [PG1] ls -l
total 20
-rw-r--r--. 1 postgres postgres 34 May 21 09:07 requirements.txt
-rw-r--r--. 1 postgres postgres 12834 May 21 09:07 sql_database_pipeline.py
As mentioned in the output above, additional dependencies need to be installed:
postgres@rhel8:/home/postgres/db2_postgresql/ [PG1] cat requirements.txt
dlt[postgres,sql-database]>=1.11.0(.local)
postgres@rhel8:/home/postgres/db2_postgresql/ [PG1] pip install -r requirements.txt
postgres@rhel8:/home/postgres/db2_postgresql/ [PG1] find .
.
./.dlt
./.dlt/config.toml
./.dlt/secrets.toml
./.gitignore
./sql_database_pipeline.py
./requirements.txt
postgres@rhel8:/home/postgres/db2_postgresql/ [PG1] pip install ibm-db-sa
Now is the time to configure the credentials and connection parameters for the source and destination databases, and this is done in the “secrets.toml” file:
postgres@rhel8:/home/postgres/db2_postgresql/ [PG1] cat .dlt/secrets.toml
[sources.sql_database.credentials]
drivername = "db2+ibm_db"
database = "db1"
password = "manager"
username = "db2inst1"
schema = "omrun"
host = "172.22.11.93"
port = 25010
[destination.postgres.credentials]
database = "postgres"
password = "postgres"
username = "postgres"
host = "192.168.122.60"
port = 5432
connect_timeout = 15
When we initialized the pipeline a template called “sql_database_pipeline.py” was created, and this is what we need to adjust now. There are several samples in that template, we’ve used the load_select_tables_from_database skeleton:
# flake8: noqa
import humanize
from typing import Any
import os
import dlt
from dlt.common import pendulum
from dlt.sources.credentials import ConnectionStringCredentials
from dlt.sources.sql_database import sql_database, sql_table, Table
from sqlalchemy.sql.sqltypes import TypeEngine
import sqlalchemy as sa
def load_select_tables_from_database() -> None:
"""Use the sql_database source to reflect an entire database schema and load select tables from it.
This example sources data from the public Rfam MySQL database.
"""
# Create a pipeline
pipeline = dlt.pipeline(pipeline_name="omrun", destination='postgres', dataset_name="omrun")
# This are the tables we want to load
source_1 = sql_database(schema="omrun").with_resources("loadcheck_a", "loadcheck_b")
# Run the pipeline. The merge write disposition merges existing rows in the destination by primary key
info = pipeline.run(source_1, write_disposition="replace")
print(info)
if __name__ == "__main__":
# Load selected tables with different settings
load_select_tables_from_database()
That’s all the code which is required for this simple use case. We’ve specified the database schema (omrun) and the two tables we want to load the data from (“loadcheck_a”, “loadcheck_b”). In addition we want the data to be replaced on the target (there is also merge and append).
This is how it looks like in Db2 for the first table:
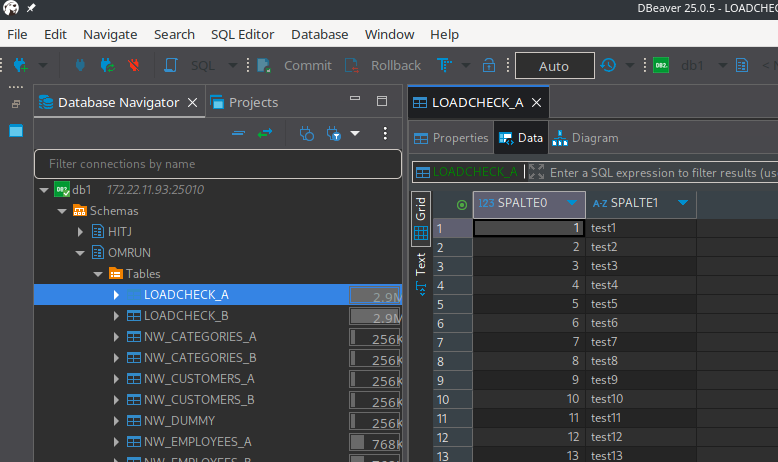
Ready to run the pipeline:
postgres@rhel8:/home/postgres/db2_postgresql/ [PG1] python sql_database_pipeline.py
Pipeline omrun load step completed in 0.73 seconds
1 load package(s) were loaded to destination postgres and into dataset omrun
The postgres destination used postgresql://postgres:***@192.168.122.60:5432/postgres location to store data
Load package 1747817065.3199458 is LOADED and contains no failed jobs
Everything seems to be OK, let’s check in PostgreSQL. The schema “omrun” was created automatically:
postgres@rhel8:/home/postgres/db2_postgresql/ [PG1] psql -c "\dn"
List of schemas
Name | Owner
---------------+-------------------
omrun | postgres
omrun_staging | postgres
public | pg_database_owner
(3 rows)
Looking at the tables in that schema, both tables are there and contain the data:
postgres@rhel8:/home/postgres/db2_postgresql/ [PG1] psql -c "set search_path='omrun'" -c "\d"
SET
List of relations
Schema | Name | Type | Owner
--------+---------------------+-------+----------
omrun | _dlt_loads | table | postgres
omrun | _dlt_pipeline_state | table | postgres
omrun | _dlt_version | table | postgres
omrun | loadcheck_a | table | postgres
omrun | loadcheck_b | table | postgres
(5 rows)
postgres@rhel8:/home/postgres/db2_postgresql/ [PG1] psql -c "select count(*) from omrun.loadcheck_a"
count
--------
102401
(1 row)
postgres@rhel8:/home/postgres/db2_postgresql/ [PG1] psql -c "select * from omrun.loadcheck_a limit 5"
spalte0 | spalte1 | _dlt_load_id | _dlt_id
---------+---------+--------------------+----------------
1 | test1 | 1747817065.3199458 | tmQTbuEnpjoJ8Q
2 | test2 | 1747817065.3199458 | Y5D4aEbyZmaDVw
3 | test3 | 1747817065.3199458 | RxcyPugGndIRQA
4 | test4 | 1747817065.3199458 | YHcJLkKML48/8g
5 | test5 | 1747817065.3199458 | ywNZhazXRAlFnQ
(5 rows)
Two additional columns have been added to the tables. “_dlt_load_id” and “_dlt_id” are not there in Db2, but get added automatically by dlt for internal purposes. The same is true for the “omrun_staging” schema.
Inspecting the pipeline can be done with the “info” command:
postgres@rhel8:/home/postgres/db2_postgresql/ [PG1] dlt pipeline omrun info
Found pipeline omrun in /home/postgres/.dlt/pipelines
Synchronized state:
_state_version: 2
_state_engine_version: 4
dataset_name: omrun
schema_names: ['sql_database']
pipeline_name: omrun
default_schema_name: sql_database
destination_type: dlt.destinations.postgres
destination_name: None
_version_hash: e/mg52/UONZ79Z5wrl8THEl8LeuKw+xQlA8FqYvgdaU=
sources:
Add -v option to see sources state. Note that it could be large.
Local state:
first_run: False
initial_cwd: /home/postgres/db2_postgresql
_last_extracted_at: 2025-05-21 07:52:50.530143+00:00
_last_extracted_hash: e/mg52/UONZ79Z5wrl8THEl8LeuKw+xQlA8FqYvgdaU=
Resources in schema: sql_database
loadcheck_a with 1 table(s) and 0 resource state slot(s)
loadcheck_b with 1 table(s) and 0 resource state slot(s)
Working dir content:
Has 6 completed load packages with following load ids:
1747813450.4990926
1747813500.9859562
1747813559.5663254
1747813855.3201842
1747813968.0540593
1747817065.3199458
Pipeline has last run trace. Use 'dlt pipeline omrun trace' to inspect
If you install the “streamlit” package, you can even bring up a website and inspect your data using the browser:
postgres@rhel8:/home/postgres/db2_postgresql/ [PG1] pip install streamlit
postgres@rhel8:/home/postgres/db2_postgresql/ [PG1] dlt pipeline omrun show
Found pipeline omrun in /home/postgres/.dlt/pipelines
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to false.
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.122.60:8501
External URL: http://146.4.101.46:8501
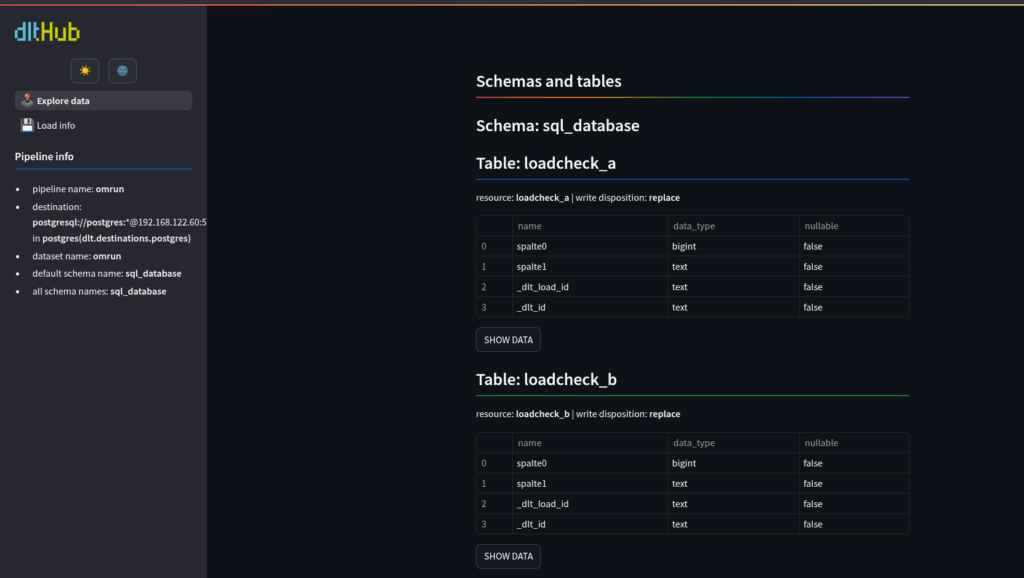
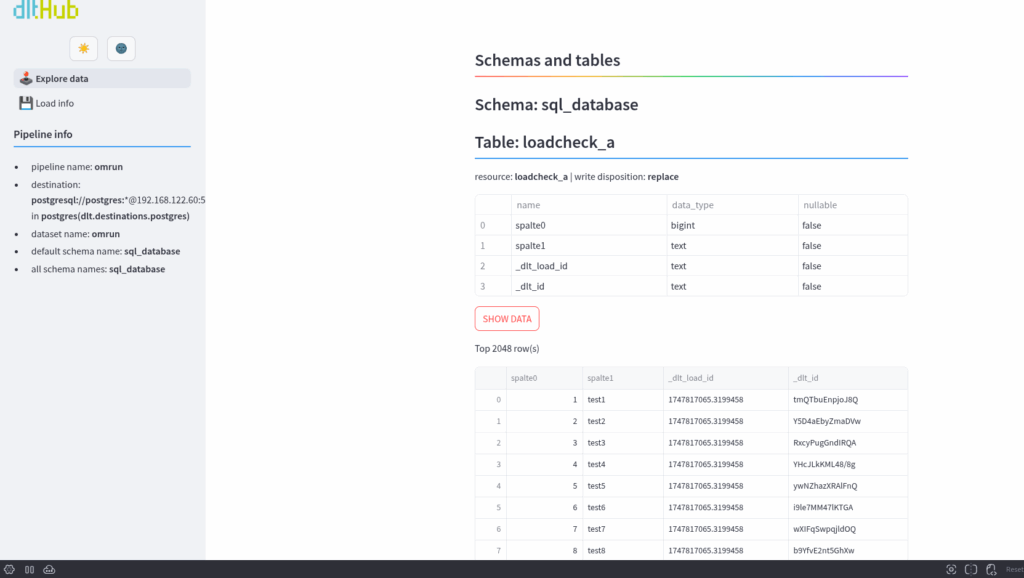
Really nice.
This was a very simple example, there is much more can do with dlt. Check the documentation for further details.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)