When it comes to designing a PostgreSQL architecture that fits your requirements there are a couple of things to think about: Do you need a HA setup? How shall backups and restores being done and how shall all of these components get monitored? Do you need vendor support for all the tools that make up the architecture? At dbi we have a reference architecture that we can apply to most of our projects. It is not a one size fits all architecture it is more a multi stage model. Each stage adds more redundancy, more control and more automation. In this post I’ll look at the various stages using the tools EnterpriseDB provides.
Lets start with the “minimal” configuration:
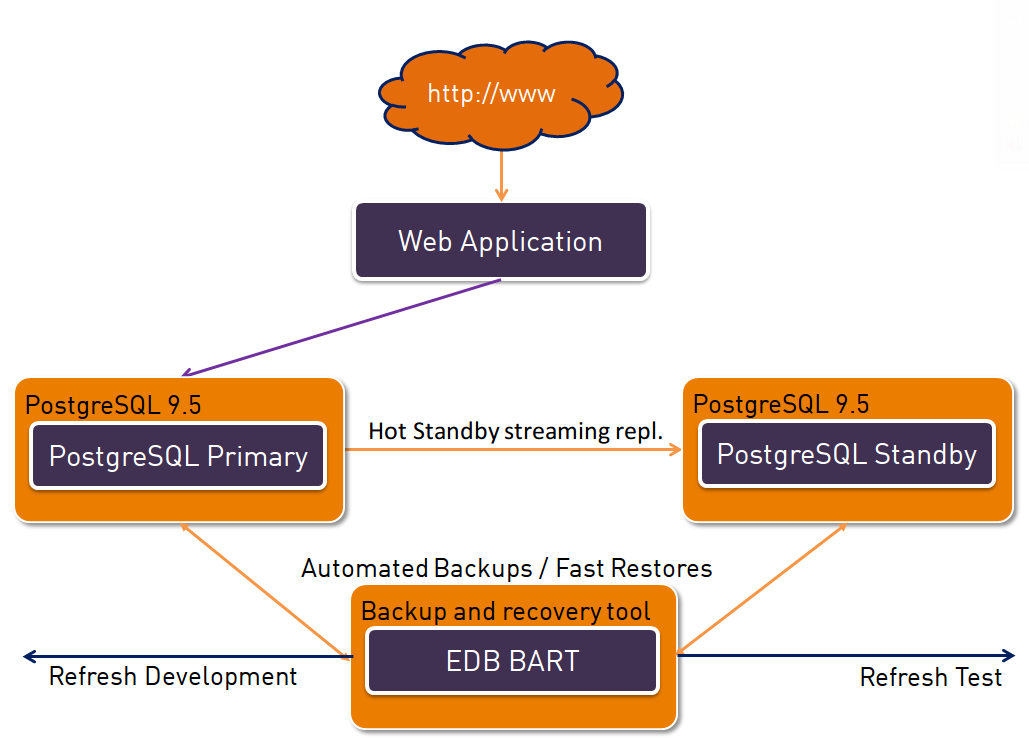
On the top there is the application (web based or not) which fires requests against the PostgreSQL master database. The master database streams all changes to a standby database (in another data center, if possible). At the bottom there is BART (which is the backup and recovery tool provided by EnterpriseDB) which performs automated backups. Retention policies ensure proper deletion of expired backups. Test and development databases might be refreshed from the BART host with minimal effort. The downsides with this architecture are:
- The application probably needs to be reconfigured to connect to the standby database in case the master goes down for any reason
- There is no integrated monitoring solution which alerts in case of issues. Sure, monitoring can be done by using scripts, check_postgres or other tools but it needs extra effort
This brings us to the extended stage:
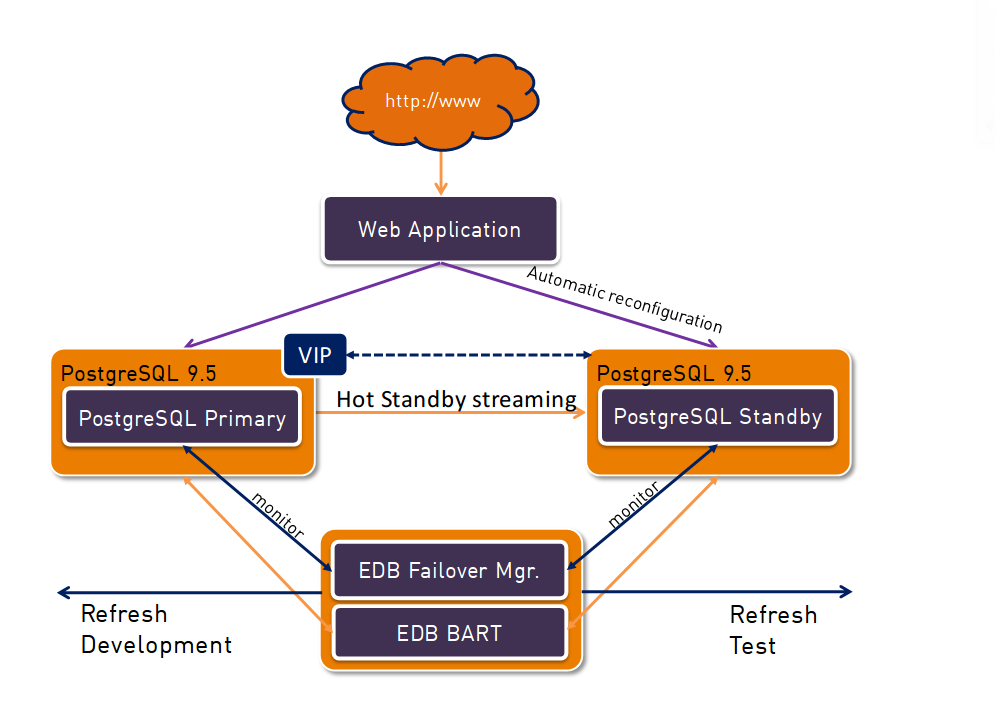
In addition, this stage adds the EDB failover manager which avoids the reconfiguration of the application in case the master goes down. This works by leveraging virtual IP addresses as you probably know it from other cluster solutions. When the master goes down the VIP is switched to the standby and the standby is opened for read/write automatically. The application can continue working without manual intervention. But there is still a downside with this solution: As with the minimal solution there is no integrated monitoring.
This is where the next stage comes into the game:
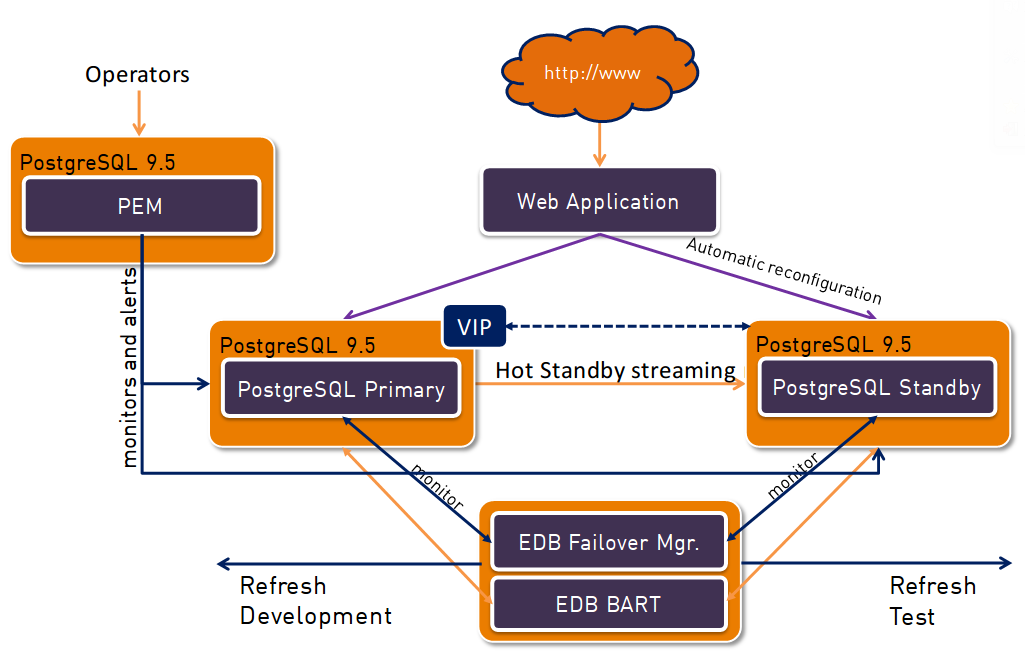
In addition to the extended stage PEM (Postgres Enterprise Manager) is added. This allows monitoring and alerting of the complete infrastructure. This can either be agent-less or agent based depending on how much information you want to get from the operating systems and how many tasks you want to have available from the PEM console (e.g. remote restarting of PostgreSQL instances). This architecture protects from failures, requires no manual intervention in case of disasters, provides easy and robust monitoring and is able to backup and restore the PostgreSQL instances to any other host for testing or development purposes.
But we can even do more by adding a second replica to offload reporting:
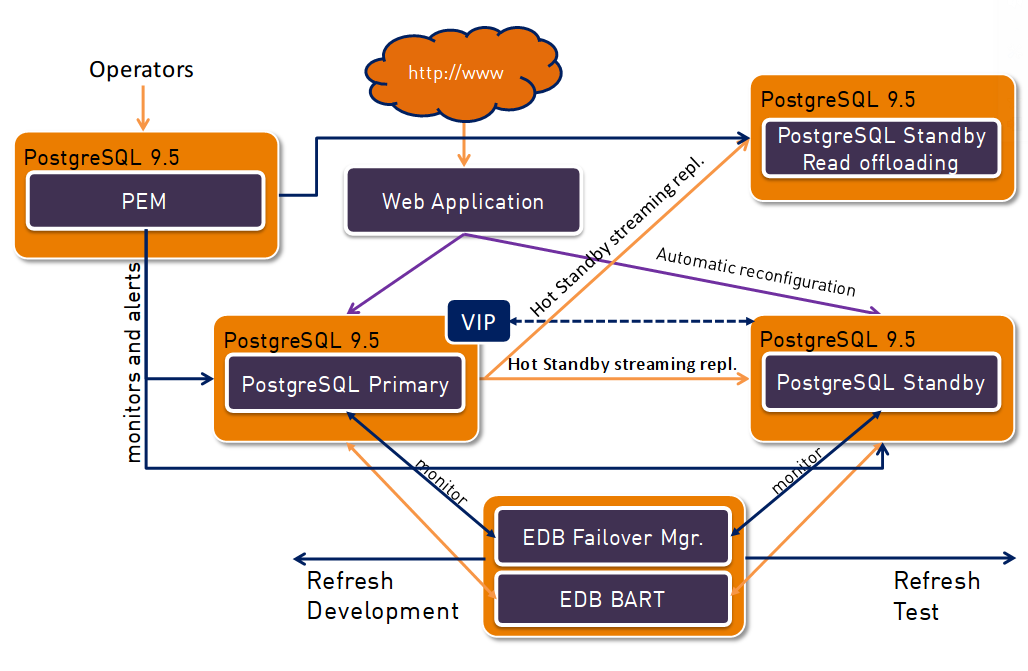
Adding a second replica for reporting purposes takes away load from the master and frees resources while leveraging the resources that are available on the host where the replica runs on.
Sure, this is not a complete picture but these 4 stages provide a minimal overview which helps customers to understand what is possible, where to look at and how they can scale. More replicas can easily be added (even cascading) and load balancers can be placed in front of the databases (e.g. pgpool-II) which strengthens the architecture even more. It all depends on the requirements and for sure there are use cases for every of these stages. In the end it is the customer who decides but at least we can give recommendations based on what we did in the past and what we believe is the best solution for the given requirements.
Of course, all of this can be backed by a SLA according to the customers needs. Interested? Let us know …
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/03/AHI_web.jpg)