SQL Server’s FileTable feature provides the integration of the SQL Server database engine with the file system. It lets you store files and documents in special tables called FileTables within SQL Server, while still maintaining Windows file namespace semantics.
However, when it comes to SQL Server Availability Groups (AG), there are specificities you need to be aware of.
1. Why use FileTables?
FileTables can be incredibly useful because:
- They bridge the gap between traditional relational data and unstructured files.
- Allow for complex queries that combine structured and unstructured data.
- Files can be accessed and managed using regular Windows APIs or T-SQL.
2. Basic Availability Groups and FileTables
Basic Availability Groups (available in SQL Server Standard Edition) offer a reduced set of features in comparison to Advanced Availability Groups. One of the limitations is that they support only one database per group. When using FileTables in the context of Basic AGs, you need to be sure that all FileTable data is contained within a single database.
FileTable Compatibility with Other SQL Server Features | Microsoft Learn
3. LAB DEMO
3.1 Setup
In the following demo we will work on a 2 nodes (nodeA and NodeB) server configuration of SQL Server Always with an AG named “AG1” and a listener named “aglist”.
The database AdventureWorks2022 is part of this AG.
Those servers will not be using a share in order to host the data, both nodes will have independent local storage for the FileTable.
In order to create a FileTable we need to first activate FILESTREAMING on both nodes as such ( a restart of the service is required, good thing that we are doing that on an AlwaysOn!)
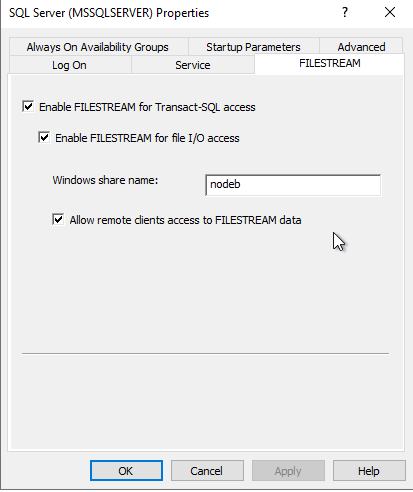
Then we can run the following code :
USE AdventureWorks2022
GO
USE [master]
GO
ALTER DATABASE [AdventureWorks2022] ADD FILEGROUP [FileTableFG] CONTAINS FILESTREAM
GO
USE [AdventureWorks2022]
GO
IF NOT EXISTS (SELECT name FROM sys.filegroups WHERE is_default=1 AND name = N'FileTableFG') ALTER DATABASE [AdventureWorks2022] MODIFY FILEGROUP [FileTableFG] DEFAULT
ALTER DATABASE [AdventureWorks2022] ADD FILE ( NAME = N'FT', FILENAME = N'F:\data\FT' ) TO FILEGROUP [FileTableFG]
GO
use [master];
GO
ALTER DATABASE [AdventureWorks2022] SET FILESTREAM( DIRECTORY_NAME = N'FTdirectory' ) WITH NO_WAIT
GO
USE AdventureWorks2022
go
CREATE TABLE demo AS FILETABLE
WITH
(
FILETABLE_DIRECTORY = 'FTdirectory',
FILETABLE_COLLATE_FILENAME = database_default
)
GOThen we also can activate the database option FULL Non-Transacted Access for FILESTREAM :
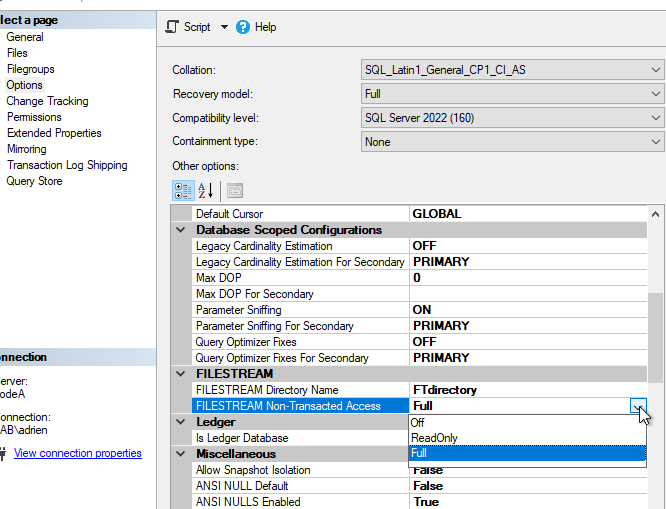
This will require an exclusive lock on the DB and allow us to use the filesystem in addition to T-SQL queries to alter the files.
3.2 Inserting files using T-SQL
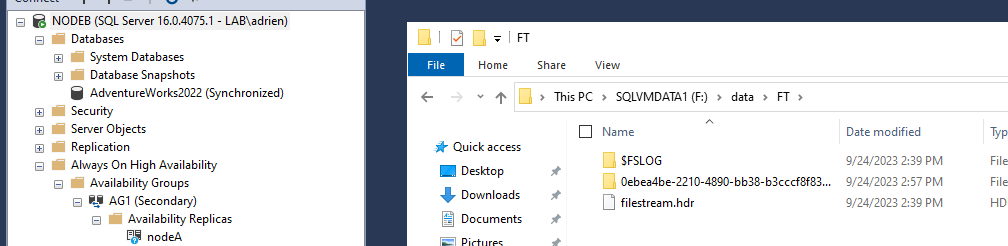
We can see on both nodes that a folder has been created to host the incoming files :
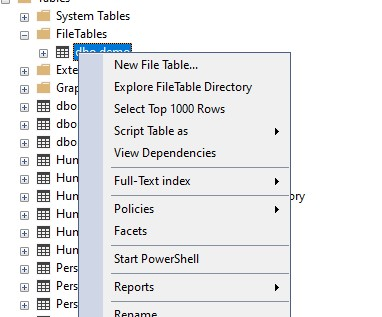
We can then also browse the data by using the “Explore FileTable Directory” option on the table in SSMS.
Let’s insert a file :
USE AdventureWorks2022
INSERT INTO demo (name, file_stream) SELECT 'document.txt', * FROM OPENROWSET(BULK N'F:\data\FT\document.txt', SINGLE_BLOB) as FileData;
-- get the fullpath of the file
USE AdventureWorks2022;
DECLARE @root nvarchar(100);
DECLARE @fullpath nvarchar(1000);
SELECT @root = FileTableRootPath();
SELECT @fullpath = @root + file_stream.GetFileNamespacePath()
FROM demo
WHERE name = N'document.txt';
PRINT @fullpath;
GO Here the full path will be :
\\aglist\nodeA\FTdirectory\FTdirectory\document.txt
In this case the document.txt was only 64KB.
Let’s push the system a bit by creating and inserting a 10GB file :

During this insert, NodeA is working hard on CPU and IO :
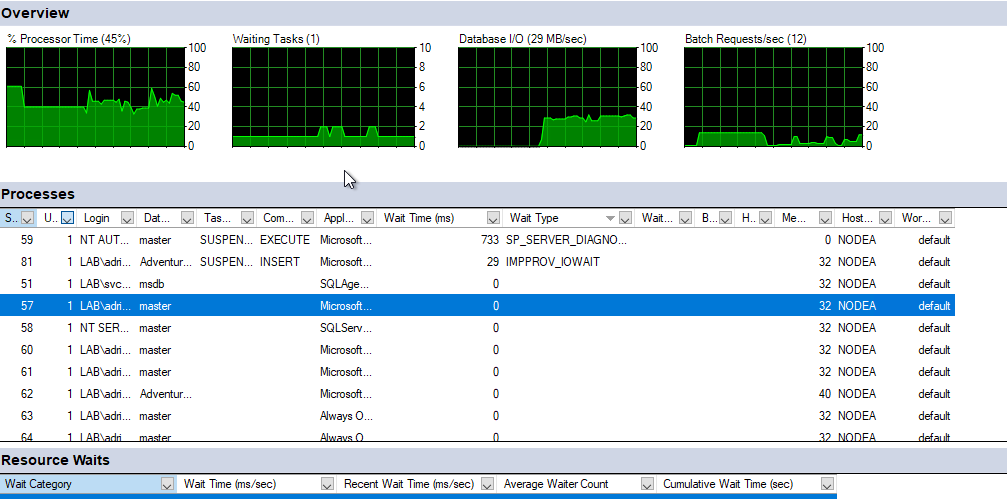
While NodeB is barely working :
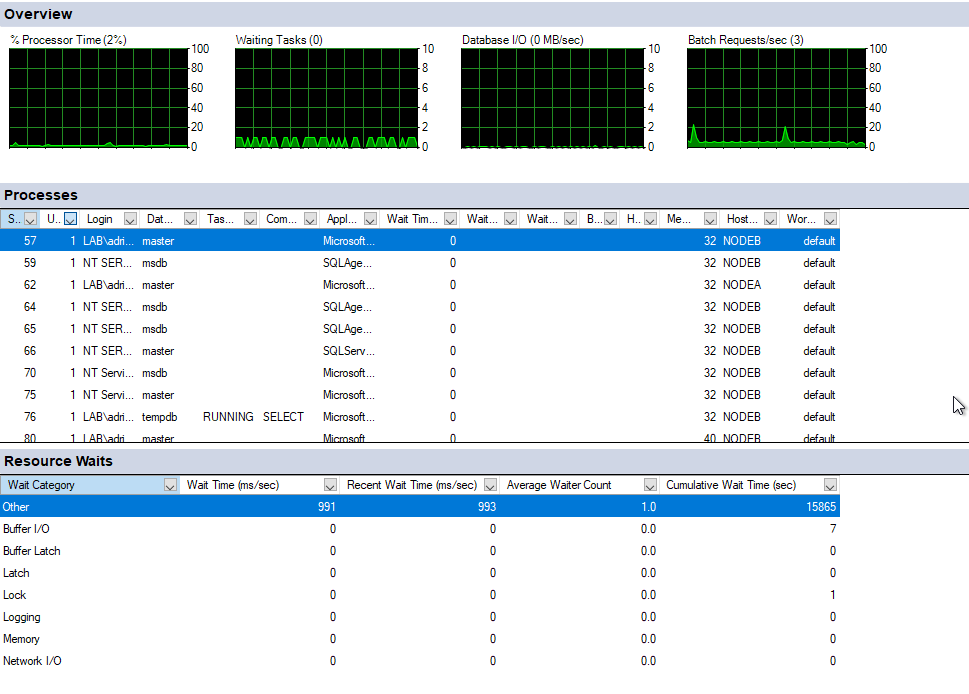
The resource usage on nodeA seems to impact the select statement on the table (24s for a simple select):
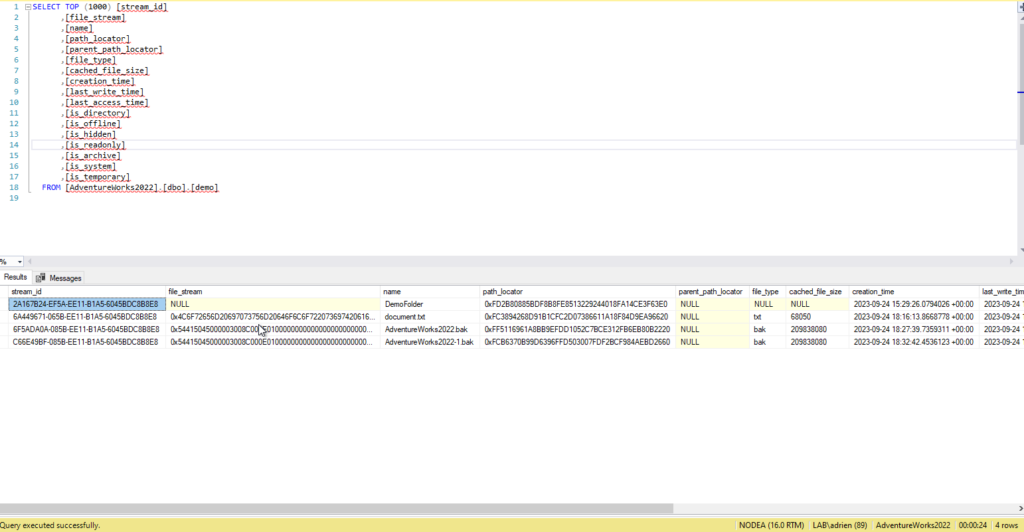
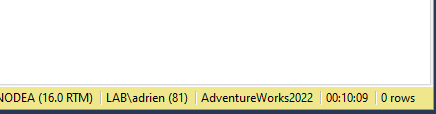
In total in took 10min to insert this file using a SQL Statement :
After this insert we have both files present on both nodes and if we failover it is working as expected.
3.3 Inserting file using the File System
What about the file system performance?
If we copy the 10GB file directly in Explorer the bandwidth seems bigger, but the last 5s last for another 4min in full Windows fashion 🙂
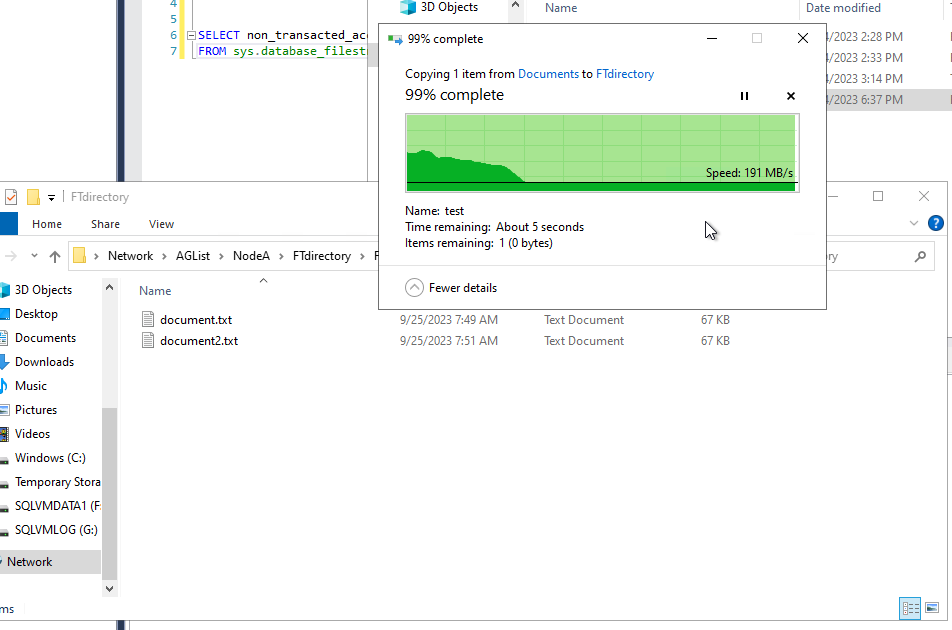
The reason for that is the same as in T-SQL, the data has to be copied on the replica as well although using the file system in that case is faster. If we had used a single shared folder it would have been even faster.
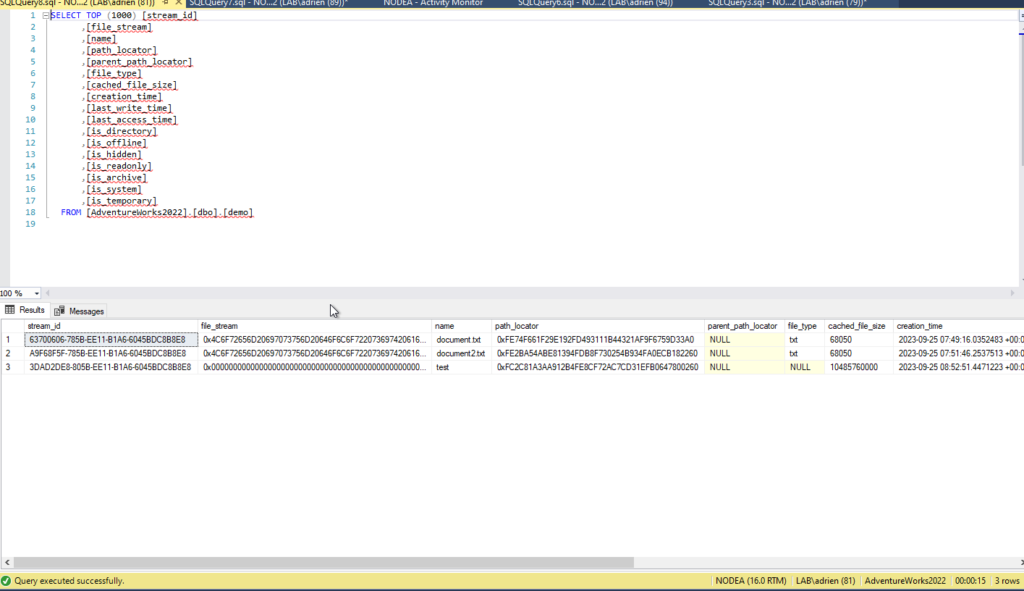
But now my select statements on the table are really slow, I only have 3 rows in it… why?
What is the execution plan saying?
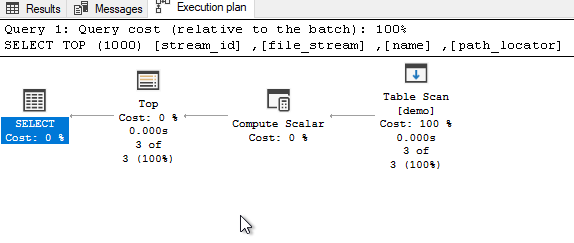
Nothing wrong with this plan. Stats?
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(3 rows affected)
Table 'demo'. Scan count 1, logical reads 1, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(1 row affected)
SQL Server Execution Times:
CPU time = 2219 ms, elapsed time = 13262 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
So the estimation is correct, the indexes created by the system are working, it is only the CPU time that seems high but why?
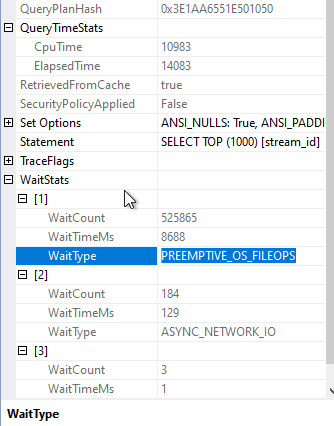
PREEMPTIVE_OS_FILEOPS Wait is related to the fact that SQL Server is waiting for OS file system to complete a task. In my case, I am using Azure HDD, so the performance is off in an extreme way but it shows how the size of a file can impact SQL Queries. Whenever it is possible in your design, choose a filesystem over any SQL Server or any database feature, file systems are much faster because they are created to store… FILES 🙂
Another point is that the SQL Server license is quite expensive compared to a free file system that can do the job faster in a more scalable way.
I am not saying that it is not a nice feature and that it should never be used, I am saying that it will never scale.
4. Conclusion
In the case of a Basic Availability Group (BAG) without a shared folder, the data integrity is handled by FILESTREAM and FILETABLE features. The data is safe thanks to BAG but the insert update time will suffer. If we use large files (compared to the system capabilities) this has an impact on transaction logs, redo and also on the failover time, which in all can lead to data corruption. Here my transaction lasted for several minutes, which means that a rollback of that redo in case of failover, might not really be “AlwaysOn like” for the users. Failure of the system during an undo-redo time frame will increase the risk of data corruption.
With the use of big files, the system tends to use streaming instead of buffering to minimize memory consumption. If there is a failure during the streaming process, it can also result in data corruption. Additionally and lastly, concurrency on the Filetable between non-transactional through the file system and Filetable feature can create data inconsistencies.
BAG also has the inconvenience of not allowing Read-Only replicas. This means that in my case I need to failover to one node to have access to the data of that node and that I cannot scale the reads by using multiple file systems.
The use of a shared folder can avoid those issues but create additional complexities such as network latency and increased management. In that case, having a single point of failure in an AG means that you have to rely on filesystem replication such as DFS or SAN-level redundancy
In conclusion, FileTables in SQL Server Availability Groups work in much the same way as other tables during a failover. However, due to their integration with the file system, there are a few additional considerations to keep in mind to ensure smooth operations during and after the failover. Always ensure to test the failover process thoroughly in a non-production environment before implementing it in a live environment.
Combining FileTable with AlwaysOn Availability Groups can offer a robust solution for storing non-relational data within SQL Server while benefiting from high availability. However, it requires diligent monitoring ( IO, network glitches, transaction durations…) and management to ensure optimal operation and avoid time windows where the system is more likely to produce data corruption.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2025/03/OBA_web-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2023/01/APY_web-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/11/LTO_WEB.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/01/HME_web.jpg)