Your Patroni cluster does exactly what you built it to do. A node dies at 3 a.m., a new primary is elected in a few seconds, the application reconnects, and nobody gets paged. Your HA setup works.
And yet, somewhere downstream, your change-data-capture pipeline has just gone quiet. Debezium or Flink CDC was streaming every change out of that database into Kafka, into a data lake, into a search index. After the failover it stops. No crash, no alert, just a lag counter that climbs and a topic that never gets new records. By the time someone notices, you are missing hours of changes and the only honest fix is a full reseed.
This is one of my favourite operational traps, because it sits in the blind spot between two teams that both think they did their job. The DBA built a solid HA cluster. The data engineer built a solid CDC pipeline. Nobody owned the join between them, and the join is a logical replication slot.
From a DBA’s perspective this is a silent killer, and PostgreSQL 17 finally gave us a clean way to disarm it. Let me show you exactly why it breaks, what the old workarounds cost, and how native failover slots fix it, with a small Patroni lab you can run on Docker Desktop to see both the failure and the cure.
If you only run Debezium: your half is one line,
slot.failover=trueon the connector (Debezium ≥ 3.0.5 against a PostgreSQL 17+ primary). The other half is server-side, two settings and the failover wiring, and it is your DBA’s job; the rest of this post is what to ask them for.
Why the slot does not survive
A logical replication slot is a bookmark. It records how far a consumer has read the write-ahead log (the WAL is PostgreSQL’s running log of every change; an LSN is just a position in it, like a byte offset), and it keeps PostgreSQL from recycling WAL the consumer still needs. Debezium, a native CREATE SUBSCRIPTION, pg_recvlogical all rely on a named slot to guarantee they never miss a change and never have to replay from the beginning.
The issue is that a logical slot lives on only one instance, the one where it was created. Physical streaming replication, the mechanism Patroni uses to keep a standby in sync, copies the data blocks and the WAL. It does not copy the logical slots. For years that was a deliberate design decision, not a bug: a slot carries decoding state and a catalog_xmin (a do-not-garbage-collect marker for the old system-catalog rows it still needs to decode the WAL), and replaying that safely onto a standby is genuinely hard.
So the picture before failover looks healthy:
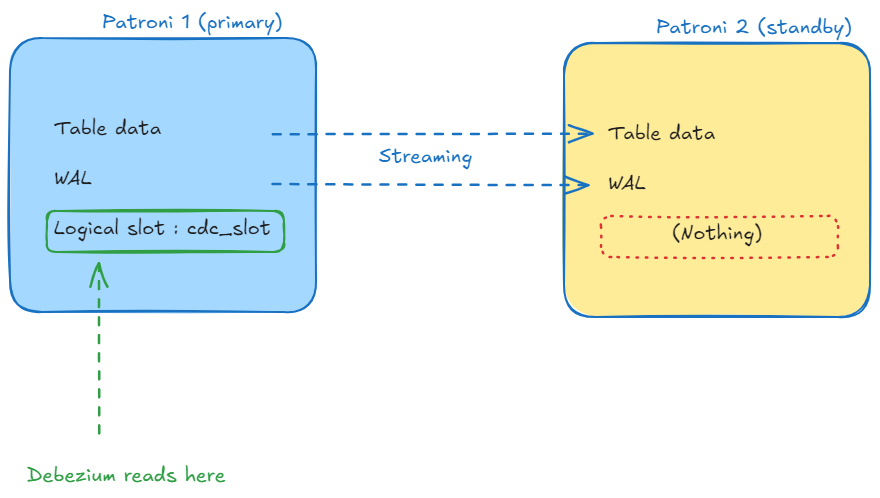
The slot exists only on the primary. Promote the standby, and the new primary has all your data and none of your slots. Debezium reconnects through your load balancer, asks for cdc_slot, and PostgreSQL answers, correctly, that no such slot exists. The pipeline is broken, and depending on how the connector is configured it either fails loudly or, worse, quietly recreates a fresh slot at the current position and skips everything in between.
Can’t my load balancer or VIP just handle this?
This is the first question I get, and it is a good one. The instinct is reasonable : I already have HAProxy in front of the cluster, or a VIP that floats with the leader on keepalived, or a cloud load balancer, so when the primary moves my consumer simply reconnects to the new one. Doesn’t that cover it?
It does not, and understanding why tells you what class of problem this really is.
A load balancer solves routing: how the consumer finds whoever is currently the primary. A floating VIP does the same thing one layer down. Both get the client to the right door, and you do need one of them (in the lab that is exactly HAProxy’s job). But the slot is not a routing concern, it is state. It is a file in the primary’s data directory. When the consumer reconnects through the VIP to the new primary and asks for cdc_slot, that instance still has to physically own the slot. The IP moving does not move the slot, because the new primary is a different PostgreSQL instance with its own pg_replslot directory. So whether HAProxy sits on the database nodes or on its own tier, and whether you use HAProxy or a VIP or a cloud LB, the effect on the slot is identical: none.
There is exactly one architecture where the slot survives without any slot synchronization at all, and it is a different design rather than a different load balancer: shared-storage failover. If your HA is built on a block volume that detaches from the failed node and reattaches to the new one (DRBD, a SAN, a cloud disk, a Kubernetes PVC), then failover moves the whole data directory, pg_replslot included, and the slot comes along because it never logically moved. That works, but it buys a different set of trade-offs (the storage becomes a hard dependency and a fencing problem, and you give up streaming read replicas off the same volume), and it is not what a streaming-replication cluster like Patroni does. On streaming replication the slot has to be synchronized deliberately, which is the rest of this post.
Why not just create the slot on every node?
The next idea people reach for is to pre-create the slot on every node, primary and standbys, and let the consumer use whichever one is currently primary. The intuition is right. In fact it is almost exactly what failover slots do, it just misses the one piece that makes it safe.
A slot is not only a name. It carries moving state: restart_lsn, confirmed_flush_lsn and catalog_xmin. If you create independent slots on each node, each one starts at that node’s position and then sits there, because nothing advances the standby’s copy as the consumer acknowledges changes on the primary. The names match, the positions drift.
That is worse than losing the slot, not better. After failover the consumer finds a slot called cdc_slot (so no loud error) and resumes from its stale position. If the copy is behind the consumer, you re-deliver changes it already processed, which is duplicates. If it is ahead, the consumer asks for an LSN the slot has already discarded, which is a gap or an error. You have turned a loud, obvious failure(“replication slot does not exist”, which at least pages someone) into a silent data-integrity problem, and for a pipeline feeding a data lake, silent is the worst outcome.
Two more walls. Before PostgreSQL 16 you cannot even create a logical slot on a standby (you get “logical decoding cannot be used while in recovery”); version 16 added logical decoding on standbys, and 17 added the synchronization that makes a standby slot actually track the primary. And idle slots are not free: every slot, active or not, pins WAL and holds back vacuum on its node, so leaving un-advanced slots on every node invites WAL growth.
So the correct version of “a slot on every node, one active and the rest idle” is precisely a failover slot: present on the standby, not consumable until promotion, with its position kept in lockstep with the primary. The synchronization is the whole feature.
The years before PostgreSQL 17
This problem is not new, and the community built two workarounds.
The first was the pg_failover_slots extension (from EDB), which runs on theprimary and copies logical slot positions out to physical standbys. It supportsPostgreSQL 11 and up, but from 17 on you would reach for the native feature instead,which is what EDB now recommends too. Either way it is an external extension you haveto install, load viashared_preload_libraries, and keep compatible with your major version.
The second, if you run Patroni, is built in. Patroni has its own concept of permanent replication slots. You declare a slot in the cluster configurationand Patroni makes sure it exists on every eligible node, copying the slot to thestandbys and advancing its position on a schedule. In Patroni terms it looks like this:
slots:
cdc_slot:
type: logical
database: cdcdemo
plugin: pgoutput
This genuinely survives a switchover, and for a lot of clusters it has been good enough for years. But notice the words “on a schedule”. Patroni advances the copy of the slot on the standby every loop_wait seconds, by default every 10 seconds. That periodic copy is the weak point. The standby’s idea of “how far the consumer has read” can lag the real primary by up to a loop interval, so a failover at the wrong moment can leave the new primary slightly behind what the consumer already acknowledged, which is exactly the window where you get duplicates or, with the wrong settings, a gap. It is a copy advanced on a timer, not a hard guarantee, so itis stale between refreshes and nothing stops the consumer from running ahead of it.
That is the gap PostgreSQL 17 closes.
PostgreSQL 17 failover slots
PostgreSQL 17 introduced native failover slots: logical slots that the database itself keeps synchronized to a physical standby as part of replication itself, with a guarantee that the consumer cannot read past what the standby has (the synchronized_standby_slots part below), rather than an external copy on a timer. (The feature landed in 17, so everything here applies to PostgreSQL 17 and later. I built the lab on PostgreSQL18, which adds a couple of conveniences I will mention at the end.)
There are three moving parts.
1. Mark the slot as a failover slot. pg_create_logical_replication_slot grew a fifth argument,failover:
SELECT * FROM pg_create_logical_replication_slot('cdc_slot', 'pgoutput',
false, false, true);
-- temporary --^ ^ ^
-- twophase ------+ |
-- failover -------------+
If you drive logical replication with a subscription, the same flag exists there, CREATE SUBSCRIPTION ... WITH (failover = true), and the slot and the subscription must agree. If you use Debezium 3.x, you set slot.failover = true and the connector creates the slot with the flag for you, as long as it is talking to a PostgreSQL 17+ primary.
2. Let the standby synchronize slots. On the standby you enable the slot sync worker (both are replication settings):
sync_replication_slots = on
hot_standby_feedback = on
hot_standby_feedback is not optional here. The standby has to tell the primary which catalog rows it still needs so the primary does not vacuum away rows the synchronized slot depends on.
3. Hold the logical slot back until the standby has the data. On the primary you set synchronized_standby_slots:
synchronized_standby_slots = 'physical_slot_of_the_standby'
This is the subtle, important one, a leash on the consumer. It tells the primary’s logical WAL senders never to hand a change to the CDC consumer until the physical standby has also received it, so the consumer can never get ahead of the standby. Without it, after failover the new primary cannot give the consumer what it already saw; with it, promotion is always safe.
With those in place, the slot is mirrored in real time. On the standby, pg_replication_slots shows it as synced, and it cannot be consumed until the standby is promoted:
slot_name | slot_type | active | failover | synced | confirmed_flush_lsn
-----------+-----------+--------+----------+--------+---------------------
cdc_slot | logical | f | t | t | 0/3A1240
failover = t, synced = t, active = f. That row is the whole point. When this standby becomes primary, cdc_slot is already there, at the right LSN, and the consumer reconnects as if nothing happened.
The gotcha that bites everyone, silently
There is a prerequisite that is easy to miss and fails in the quietest possible way: the standby’s primary_conninfo must contain a dbname (the logical replication failover docs call this out, but it is easy to skip past).
A physical replication connection does not need a database name, so historically nobody put one there. But the slot sync worker connects to the primary as a normal backend to read slot state, and it needs a database to connect to. If dbname is missing, the worker does not error in your face. It just does not sync anything. Your slots silently fail to appear on the standby, and you find out at failover, which is the worst possible time.
Recent Patroni adds dbname to primary_conninfo for you when it is managing logical slots, but I check it explicitly, every time, and so should you, on the standby:
SHOW primary_conninfo;
It must contain a dbname=… ; if not, slot sync is silently doing nothing
Seeing it break, then survive
Let me walk both cases on a small two-node Patroni cluster: PostgreSQL 18 nodespatroni1 and patroni2, a Debezium connector reading through HAProxy (so it always follows the current primary), and a tiny generator inserting rows with a strictly increasing counter n. The proof is simple: compare the n values that reached Kafka against the rows actually in the table. Every committed row should be in Kafka; duplicates are fine, because CDC delivery is at-least-once.
The commands below are the real thing, run them on your own cluster if you like. If you would rather watch it happen in a few minutes, there is a ready-to-run Docker version at the end of this post.
First, the break: a plain slot
A normal logical slot has failover off, the default. Debezium creates one for you when you register a connector with slot.failover=false; the bare SQL equivalent is:
SELECT pg_create_logical_replication_slot('dbz_slot', 'pgoutput');
It lives on the primary and nowhere else, because nothing mirrors it:
-- on the primary (patroni1)
SELECT slot_name, slot_type, active, failover, synced FROM pg_replication_slots;
slot_name | slot_type | active | failover | synced
-----------+-----------+--------+----------+--------
dbz_slot | logical | t | f | f
patroni2 | physical | t | f | f (the standby's streaming slot)
On the standby, dbz_slot is simply not there. Now fail over with patronictl:
patronictl -c /etc/patroni/patroni.yml switchover --leader patroni1 --candidate patroni2 --force cdc-demo
Successfully switched over to "patroni2"
The new primary never had the slot. The consumer reconnects through HAProxy and, here is the trap, stays perfectly green:
curl -s localhost:8083/connectors/orders-plain/status | jq '{state: .connector.state, task: .tasks[0].state}'
{ "state": "RUNNING", "task": "RUNNING" }
because Debezium found its slot missing and silently recreated it at the current LSN, straight from the Connect log:
Creating replication slot with command CREATE_REPLICATION_SLOT "dbz_slot" LOGICAL pgoutput
Everything committed between the switchover and that recreation is skipped. Draining the topic and comparing it to the source table shows the hole:
table rows: 255 distinct rows in Kafka: 250 missing: 5 (n = 100..104)
Five committed rows, gone, and nothing anywhere raised an error. Whether Debezium recreates the slot quietly (as here) or fails loudly is a matter of configuration; the lab shows the quiet case because it is the one that hurts. That is the silent version that costs you a reseed three days later when someone notices the warehouse is short.
Then, the cure: a failover slot
Same scenario, two changes. First, create the slot with failover on (or set Debezium’s slot.failover=true, which does it for you):
SELECT pg_create_logical_replication_slot('cdc_slot', 'pgoutput', false, false, true);
Second, turn on synchronization. On the standby:
sync_replication_slots = on
hot_standby_feedback = on
and on the primary, hold logical slots back until the standby has the data, naming the standby’s physical slot:
ALTER SYSTEM SET synchronized_standby_slots = 'patroni2';
SELECT pg_reload_conf();
Now the slot is mirrored to the standby. Look at it there:
-- on the standby (patroni2)
SELECT slot_name, active, failover, synced, temporary, confirmed_flush_lsn
FROM pg_replication_slots WHERE slot_name = 'cdc_slot';
slot_name | active | failover | synced | temporary | confirmed_flush_lsn
-----------+--------+----------+--------+-----------+---------------------
cdc_slot | t | t | t | f | 0/34B0A10
failover = t, synced = t. One gotcha worth watching: a freshly synced slot starts temporary = t and is dropped on promotion until it persists. The standby log shows the transition, a transient refusal (its catalog_xmin is briefly ahead of the primary slot’s) and then sync-ready:
LOG: could not synchronize replication slot "cdc_slot"
DETAIL: ... the remote slot needs catalog xmin 760, but the standby has xmin 761.
LOG: newly created replication slot "cdc_slot" is sync-ready now
Only once temporary = f is it safe to fail over. So do it:
patronictl -c /etc/patroni/patroni.yml switchover --leader patroni1 --candidate patroni2 --force cdc-demo
On the new primary the slot is already there and live, and the consumer resumes on its own. Re-point synchronized_standby_slots at the new standby (the correct value flips after a role change), then reconcile:
-- on the new primary
ALTER SYSTEM SET synchronized_standby_slots = 'patroni1';
SELECT pg_reload_conf();
table rows: 616 distinct rows in Kafka: 616 missing: 0 (74 duplicates)
Every committed row reached Kafka. Same cluster, same switchover, same consumer; the only difference is one boolean on the slot and the synchronization around it. The duplicates are at-least-once redelivery (you may see a handful or none on a given run), so the consumer must be idempotent either way, but not one committed row was lost. That boolean is the gap between “we lost four hours of CDC” and “nobody noticed”.
Patroni does its part, but not all of it
I want to be honest about the rough edges, because this is where the real-world write-ups tend to go quiet.
PostgreSQL 17 gives you the mechanism. Patroni, as of the 4.1 series I tested, does not yet fully wire it for you, and there are two manual pieces.
First, Patroni does not manage synchronized_standby_slots (this is tracked as Patroni issue #3431). You have to set it yourself, on the primary, to the physical slot name of the current standby. And in a two-node cluster that value is not symmetric: when patroni1 leads it must name patroni2‘s slot, and after a switchover to patroni2 it must name patroni1‘s slot. So you cannot just bake a single static value into the cluster config, you have to reset it after a role change. The lab’s enable-failover-config.sh is role-aware and does this, and the walkthrough deliberately runs it again after the switchover so you can see the value flip. In production you would automate it with a Patroni callback on role change.
Second, the dbname in primary_conninfo requirement I mentioned. Recent Patroni handles it, but it is exactly the kind of thing that is true on the version you tested and silently false on the version you deployed, so verify it rather than trust it.
Neither of these is a reason to avoid failover slots. They are a reason to treat “failover slots on Patroni” as a thing you configure and test deliberately, not a checkbox you assume.
The checklist
If you run logical replication or CDC on a Patroni cluster, here is what I would verify :
| Check | Where | Why |
|---|---|---|
wal_level = logical | all nodes | required for logical decoding at all |
slot created with failover = true | primary | the slot is eligible to be synchronized |
sync_replication_slots = on | standbys | the standby actually runs the sync worker |
hot_standby_feedback = on | standbys | protects the catalog rows the slot needs |
synchronized_standby_slots names the standby slot | primary | consumer never gets ahead of the standby |
dbname= present in primary_conninfo | standbys | without it, sync fails silently |
synced = t and temporary = f on the standby | standbys | mirrored and persisted: a still-temporary synced slot is dropped on promotion (“sync-ready now”) |
re-set synchronized_standby_slots after switchover | primary | the correct value flips in a 2-node cluster |
| your CDC tool sets the slot failover flag | consumer | e.g. Debezium slot.failover = true, needs ≥ 3.0.5 and PG 17+ |
Where this is going: PG18 today, PG19 next
The lab runs on PostgreSQL 18, which keeps the PG17 mechanism intact and adds a few conveniences around it: pg_recvlogical --enable-failover lets you create a failover slot straight from the command-line consumer, and --enable-two-phase (plus pg_createsubscriber --enable-two-phase) rounds out the tooling. The configuration is identical to 17, so everything above applies unchanged.
PostgreSQL 19 is in development as I write this, so treat this as a direction, not a promise (check the final release notes). The theme is telling: most of the 19 cycle’s work here makes the failure I hit easier to see rather than changing the mechanism, slot-sync skip counters in pg_stat_replication_slots, a pg_sync_replication_slots()that no longer fails silently, starting logical replication without a wal_level restart (a new effective_wal_level), and logical replication of sequences.
What 19 does not appear to change is the manual piece I complained about. synchronized_standby_slots still has to be set, and reset after a role change, by something outside PostgreSQL, and the Patroni side of that (issue #3431) is still open. So the checklist above does not get shorter in 19, it gets easier to debug.
Try it yourself
Everything above is in a lab attached to this post, worklab-patroni-failover-slots: a Docker Compose stack (etcd, two PostgreSQL 18 Patroni nodes, HAProxy, Kafka in KRaft mode, and a Debezium connector) plus a handful of helper scripts that wrap exactly the commands shown here.
We spend a lot of effort making the database survive a node failure, and then we quietly assume everything hanging off the database survives with it. Logical replication slots are the reminder that high availability is not only about the primary coming back, it is about everything that depends on the primary coming back too.
PostgreSQL 17 failover slots close the last real gap between PostgreSQL HA and the CDC pipelines we increasingly build on top of it. So don’t sleep too much on PG14 version (EOL November this year !). The mechanism is solid, the configuration is small, and the failure it prevents is the kind that is invisible until it is expensive. Clone the lab, break it once with a plain slot, fix it once with a failover slot, and you will never look at a Patroni switchover the same way again. When I started by DBA journey I have always been told that if you want to know how an RDBMS works playing around backups and restores would provide you deep insights into how they are running. I feel like today this is more true for replication.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2025/03/OBA_web-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/FRJ_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2023/01/APY_web-scaled.jpg)