Today, no keynote, we went directly to the sessions. Therefore I have scheduled my day around 3 goals: SQL Server 2012 and Windows Server 2012 and Parallel Datawarehouse, with the new features in the release AU3.
SQL Server AlwaysOn: HA & DR Design Patterns, Architectures and Best Practices
A session about SQL Server 2012, in which I was looking for an architect point on HA and DR.
Not to be confused:
- AlwaysOn is not equals to Availability Groups (AG). It’s SQL Server Failover Cluster Instances + AG
- Availability Group is not the same as Database Mirroring.
Three design patterns were presented.
-
Multi-site Failover Cluster Instance
It’s the most common in Europe with this solution characteristics:
- Shared Storage solution
- Instance level HA (auomatic)
- Instance Level DR (automatic)
- Uses storage replication
Note: Storage Validation on KB 943984
Be carefull, Tempdb must be on Local Disk:
- Not specific to “multi-site” FCIs
- Enables use of local storage for Tempdb
- Saves money on storage replication lisencing
-
Avalibility Groups for HA
The solution Characteristics are:
- Non-Shared Storage Solution
- Group of Database Level HA(automatic)
- Group of Database level DR(manual)
DR replica can be Active Secondary2 considerations for replacing Log Shipping:
- No delayed apply on the secondary
- Removing log shipping means the regular log backup job is removed (need to re-establish periodic log backup)
-
Failover Cluster Instance for HA and Availability Group for DR
It’s the combination of the 2 above and its solution characteristic is:
- Combined Shared storage and non-shared Storage
- Instance Level HA automatic)
- Group of Database Level DR (manual)
- DR replica can be Active secondary
- Asymmetric storage is the key to this solution
Quorum
All solutions use Windows Server Failover Clustering and must be have a Quorum.
Two steps:
- Node votes:First decide which nodes should have a node. By default every node as a vote but may not be ideal for your specific HA/DR goals
- Quorum model: Then choose the appropriate quorum model between the 4 models
Before, you need KB 2494036 to configure Clusters Nodes.
To deactive or change a node vote use Cluster.exe or PowerShell.
Hre under an example of PowerShell command to change the vote (sample from msdn):
Import-Module FailoverClusters $node = “AlwaysOnSrv1” (Get-ClusterNode $node).NodeWeight = 0 $cluster = (Get-ClusterNode $node).Cluster $nodes = Get-ClusterNode -Cluster $cluster $nodes | Format-Table -property NodeName, State, NodeWeight
A Deep Dive into Spatial Indexing
As a diver, no choice, I have to attend to such a session…
This was all about troubleshooting for SQL Server Spatial Query Performance (in another term, use correctly the spatial index).
What are Spatial Database and Spatial Query?
Extract from Wiki:
“A spatial database is a database that is optimized to store and query data that is related to objects in space, including points, lines and polygons”
“A spatial query is a special type of database query supported by geodatabases and spatial databases”
Since SQL 2008, you can use database as spatial database.
The real question of the session is “Why is my Spatial Query so slow?”
Usually because the index isn’t being used…
You can see it through the Query plan, if you have a warning of a “Clustered Index Seek (Spatial)”
![]()
The thing is that Spatial indexes can be forced if needed with the option WITH in a SELECT like: “Select * from T WITH(INDEX(xx))”
A little reminder on SQL Server Spatial Index history to begin:
- Planar Index (Requires bounding box, only one grid)
- Geographic Index (no bounding box, two top-level projection grids)
- Multi-Level Grid (much more flexible, Hilbert numbering, modified adaptable QuadTree)
- Grid Index features(4 levels,customizable grid subdivision, customizable maximum number of cell per object(default is 16))
New in SQL Server 2012: New default tessellation with 8 levels
For more information about Spatial Index, see the overview here
The command is:
CREATE SPATIAL INDEX xx ON Table(column)
The index has 4 columns : Prim_key, cell_id, srid and cell_attr (very important)
Cell_attr column can have 3 states:
0: Cell at least touches the object
1: Guarantees that object partially covers cell
2: Object covers cell
New Spatial index Tessellations:
- When you create your index, specify in your query the USING command with
- Geometry_auto_grid
- Geography_auto_grid
- Uses 8 Grid levels
- No GRIDS parameter needed
New Spatial queries supported by index in SQL Server 2012:
- Geometry:
- Nearest Neighbor
- Geography:
- STOverlaps() = 1
- STWithin() = 1
- STContains() = 1
- Nearest Neighbor
Error 8635:
The query processor could not produce a query plan for a query with a spatial index hint.
The possible reasons are:
- The spatial index is disabled or offline
- The spatial object is not defined in the scope of the predicate
- Spatial indexes do not support the comparand supplied in the predicate
- Spatial indexes do not support the comparator supplied in the predicate
- Spatial indexes do not support the method name supplied in the predicate
- The comparand references a column that is defined below the predicate
- The comparand in the comparison predicate is not deterministic
- The spatial parameter references a column that is defined below the predicate
- Could not find required binary spatial method in a condition
- Could not find required comparison predicate
Guidance for the spatial query performance:
- Make sure you are running SQL Server 2008 SP1, 2008 R2 or 2012
- Check query plan for use of index
- Make sure it is a supported operation
- Hint the index (and/or a different join type)
- Do not use a spatial index when there is a highly selective non-spatial predicate
- Run above index support procedure
Building the Fastest Microsoft SQL Servers
This session was presented by Brent Ozar. I recommend you to take a tour on his website.
It was a very interesting presentation on building a database solution in SQL Server.
How to find the best harddrive for the 2 common SQL use Patterns (OLTP & DW)?
The right Harddrive for faster OLTP:
- Instant queries = cache all data in memory => Memory = DB size
The right Harddrive for faster DW:
- Instant queries = we can’t cache all data in memory => Use Fast Track Data Warehouse
For Fast Track DW architecture, see the excellent documentation on msdn here.
I discovered a great tool for disk benchmark: CrystalDiskMark.
Configuration recommended for your benchmark: 5 tests with test file size of 4000MB
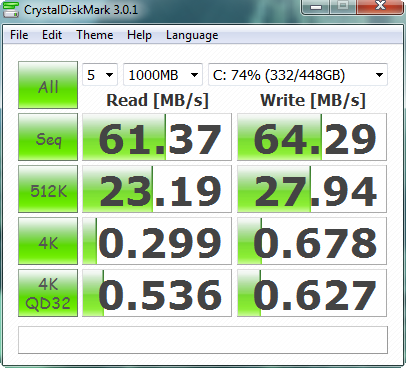
You can download it here.
Hot new features for Widows Server 2012
Notes :
“Start menu” doen’t exist?… go to the bottom-left corner… and surprise!
Use PowerShell, PowerShell and PowerShell… You have a history of all PowerShell command you used on the server, which can easily be reused.
There are many new hot features. However I’m going to focus to brief overview on: DirectAccess, Compound Identity and Dynamic Access.
What are these 3 features?
- DirectAccess:
Introduced in Windows Server 2008 R2 and Windows 7 Client computers, DirectAccess is a technology that you can be permanently connected to the corporate network when the computer has internet access and without user intervention.
Some enhancements introduced in Windows Server 2012: UAG no more required, Multi-domain support, multiple entry-points with automatic failover, RRAS & DA coexist, etc…
Supported for Windows 8 and Windows Server 2012, the wizard to deploy is quick and easy: ”Just 3-clicks”.
In the firewall, you can see in the “Connection Security Rules”, all DirectAccess rules.
- Compound Identity:
Fisrt, you have most Kerberos enhancements like PAC group compression, Warning event for large token size, increance loggins
Compound Identity is PAC contains a user’s group and claims information add to device information
Note: a usefully PowerShell Commands: whoiam /claims
- Dynamic Access Control can:
- Identify data by using automatic and manual classification of files.
- Control access to files by applying safety-net policies that use central access policies.
- Audit access to files by using central audit policies for compliance reporting and forensic analysis.
- Apply Rights Management Services (RMS) protection by using automatic RMS encryption for sensitive Microsoft Office documents.
Huge topics! 🙄
Building BI solution with Parallel Data Warehouse (PDW) release AU3
PDW is SQL Server Data Warehousing in an Appliance Model

What’s new on PWD AU3?
Release Themes:
- SQL Server Compatibility
- Performance At Scale
- BI, Analytics, & ETL Integration
In details:
- Cost based optimizer
- Native SQL Server drivers, including JDBC
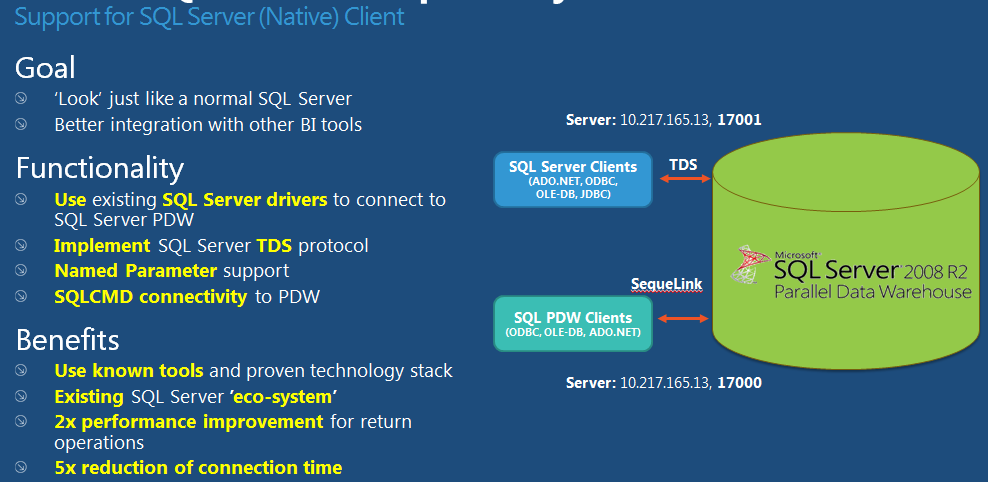
- Collations

- More expressive query language
- Data Movement Services performance
- SCOM pack
- Stored procedures (subset)
- Half-rack
- New connectors: HADOOP, Informatica & Business Objects
And the next update?
- Columnar store index
- Stored procedures
- Integrated Authentication
- PowerView integration
- Workload management
- LZ/BU redundancy
- Windows 8
- SQL Server 2012
- Hardware refresh
Conclusion
One more interesting day with pretty good sessions. Tomorrow is the last day( ) with special “Certification” sessions…
) with special “Certification” sessions…
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)