Today the Data Platform Virtual Summit begin at 06:00 am for us…
It’s in our time offset, this time better to wake up! 😉
My schedule for the day:
- D3B1 – KATMAI – SQL MI on Kubernetes – Intermediate – Dhananjay Mahajan
- D3B2 – KATMAI – Extent and Page Management in Microsoft SQL Server – Expert – Torsten Strauß
- D3B3 – SPHINX – SQL Server on Linux & Kubernetes! – From Zero to Hero – Intermediate – Tejas Shah & Amit Khandelwal
- D3B4 – SPHINX- How to model and partition data in Azure Cosmos DB to achieve cloud scale – Intermediate – Richa Gaur
- D3B5 – HYDRA- Deadlocks – Analysing, Preventing and Mitigating – Advanced – Erland Sommarskog
- D3B6 – SHILOH – Performance tuning for Azure Cosmos DB – Intermediate – Hasan Savran
- D3B7 – HYDRA – My Favourite New T-SQL in SQL Server 2022 – Intermediate – Edward Pollack
- D3B8 – KATMAI – Data Ingestion on Azure: Real-life scenarios and solutions – Intermediate – Dustin Vannoy
I will begin with the session SQL Server on Linux & Kubernetes! – From Zero to Hero from Tejas Shah & Amit Khandelwal because it’s not every day that we work on Linux with SQL Server. I good agenda in perspective:

We have in Azure already images to create our SQL Server on Linux in Azure:
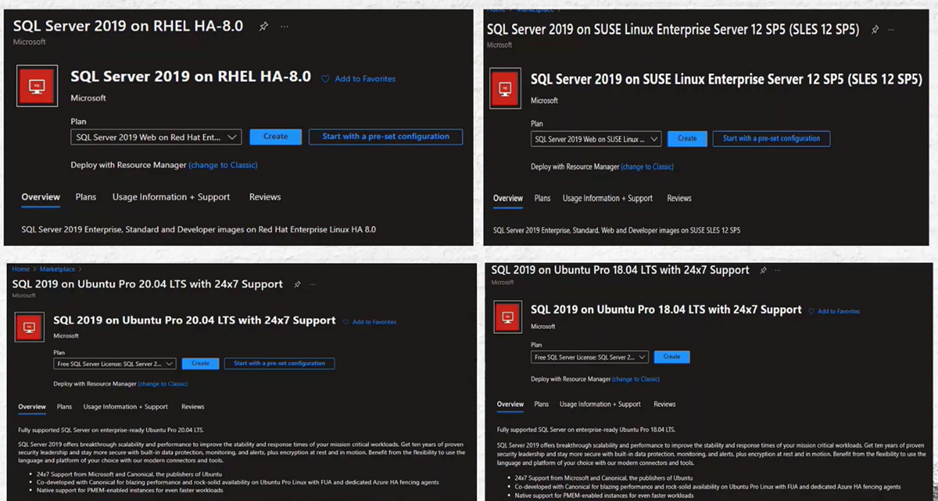
You don’t need to install SQL Server, it’s already there and created in few minutes…
It’s also good to see a remember of the Best Practice for SQL Server VMs:

Forced-Unit-Access is one of the most important configuration to keep in mind and to enable to have good performance.

A good summary to have good performance on Linux with SQL Server

After the presentation of the installation though Kubernetes, I great demo for the HA

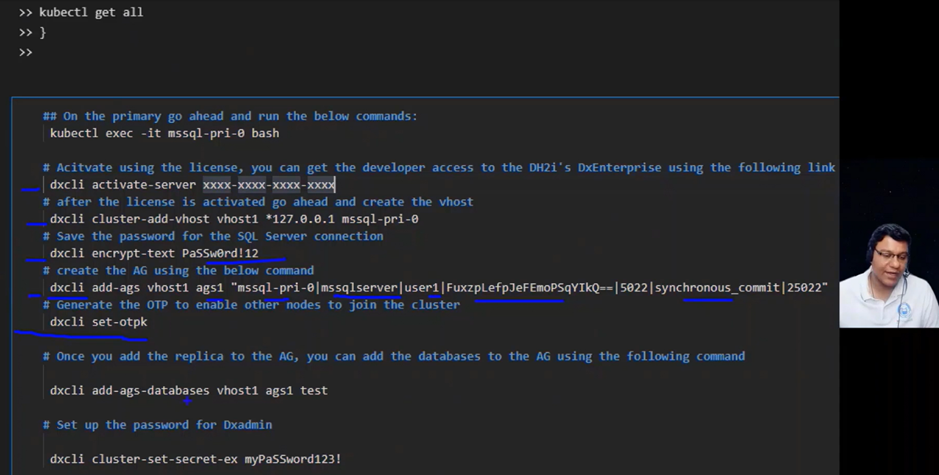
It was a very interesting session.
Now, go to the next one…
I follow the session of Edward Pollack named My Favourite New T-SQL in SQL Server
On this session I discover a lot of new T-SQL to have better quality of the code:
The first T-SQL is “IS DISTINCT FROM / IS NOT DISTINCT FROM” very useful to use and can replace = and <> but include null (this is the good point). I will write soon a blog on it.
The second is APPROX_PERCENTILE_xxx where is already used in SQL 2019 for APPROX_COUNT_DISTINCT but extend on SQL Server 2022

The next one is the DateTrunc() to rounds/truncates a date/datetime and can be use in order by and order by
Some new bit manipulation to be useful if you need to manipulate it

The Greatest() and the Least() return the largest or smallest value from any number of expressions.
A great demo to illustrate it with dates to find the first and the last date of modification:
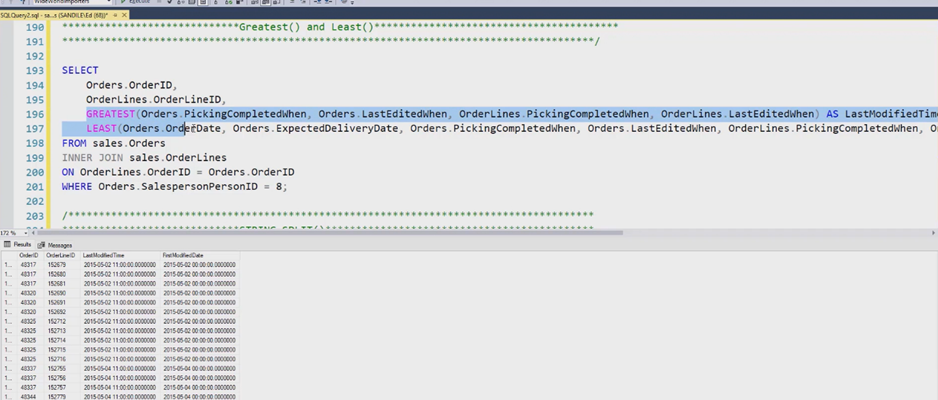
String_Split() to splits up a delimited string into its component elements.
Date_Bucket() returns a rounded date/time based on a given date part:
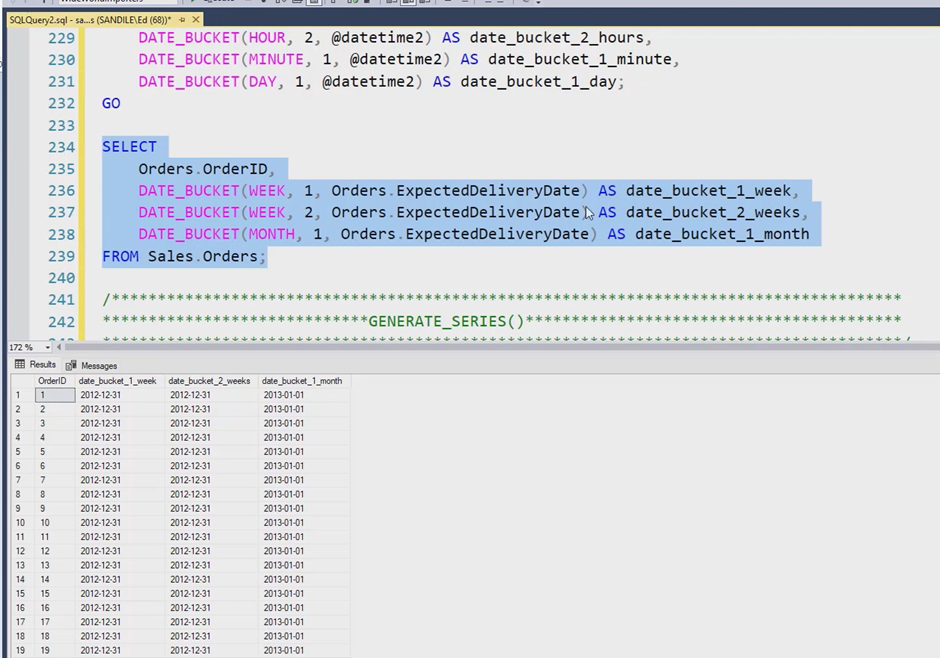
This can be very useful to use for date aggregation and group dates.
Generate_ series() builds a number series based on a set of parameters
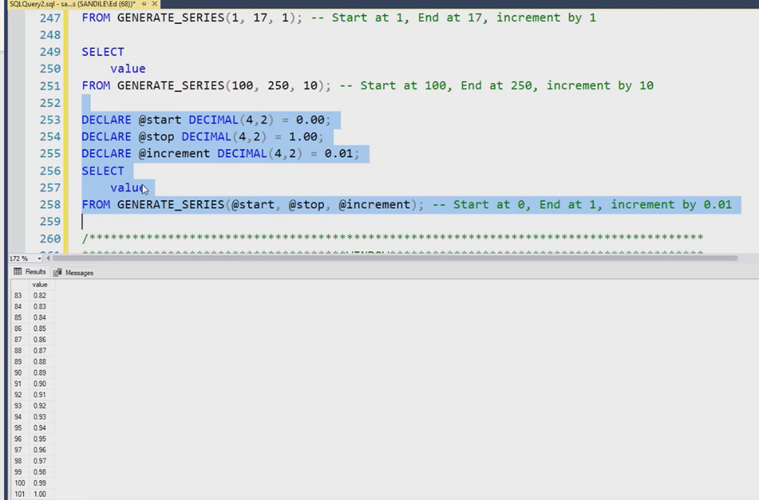
Window allows a window function over clause to be reuse and simplify the T-SQL code.
First_value() and Last_Value() are very useful and return the first or last value for a column over an ordered window
This last session gives me the desire to test some of this new T-SQL commands and blog about it! 😉
See you tomorrow again for this great event with a lot of interesting sessions
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/11/TBR-web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/11/LTO_WEB.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2023/01/APY_web-scaled.jpg)