As a consultant at dbi services, I am lucky enough to have time dedicated to training and conferences. This week I have the chance to attend one of the most important conferences for Data professionals: SQLBits 2022.
The SQLBits conference is currently taking place at ExCel London and features over 300 sessions over 5 days.
Tuesday and Wednesday, the pre-conference, were dedicated to full-day training sessions. Wednesday to Thursday are the general sessions, the conference itself, the main formats being 50 minutes and 20 minutes. The Saturday is totally free to attend.
The entire conference can be followed in person in London or virtually at home. I am staying away this year and will attend the 5 days.
You can find the full agenda at https://arcade.sqlbits.com/sessions/ As I particularly like performance topics, I naturally chose the following two training sessions
As I particularly like performance topics, I naturally chose the following two training sessions
- Mastering Parameter Sniffing par Brent Ozar
- The Professional Performance Tuning Blueprint par Erik Darling
In this blog post, I will share a few tips and interesting Performance-related information I noticed during these training days.
Mastering Parameter Sniffing
I don’t need to introduce you to Brent Ozar. Brent delivered a high-quality session. He has so much knowledge and stories about SQL Server that we always have something to learn from listening to him.
Comment Injection
One very interesting technique Brent used to circumvent parameter sniffing is what he called “Comment Injection”.
The idea is very simple: SQL Server caches execution plan based on the query text.
When submitting the same query text twice SQL Server will reuse the plan stored in cache saving on compilation time.
Based on this observation, to correct a parameter sniffing problem on a query inside a stored procedure, it is possible to modify the query text according to the parameter used. Multiple query texts mean multiple execution plans.
Here is a screenshot of such an example: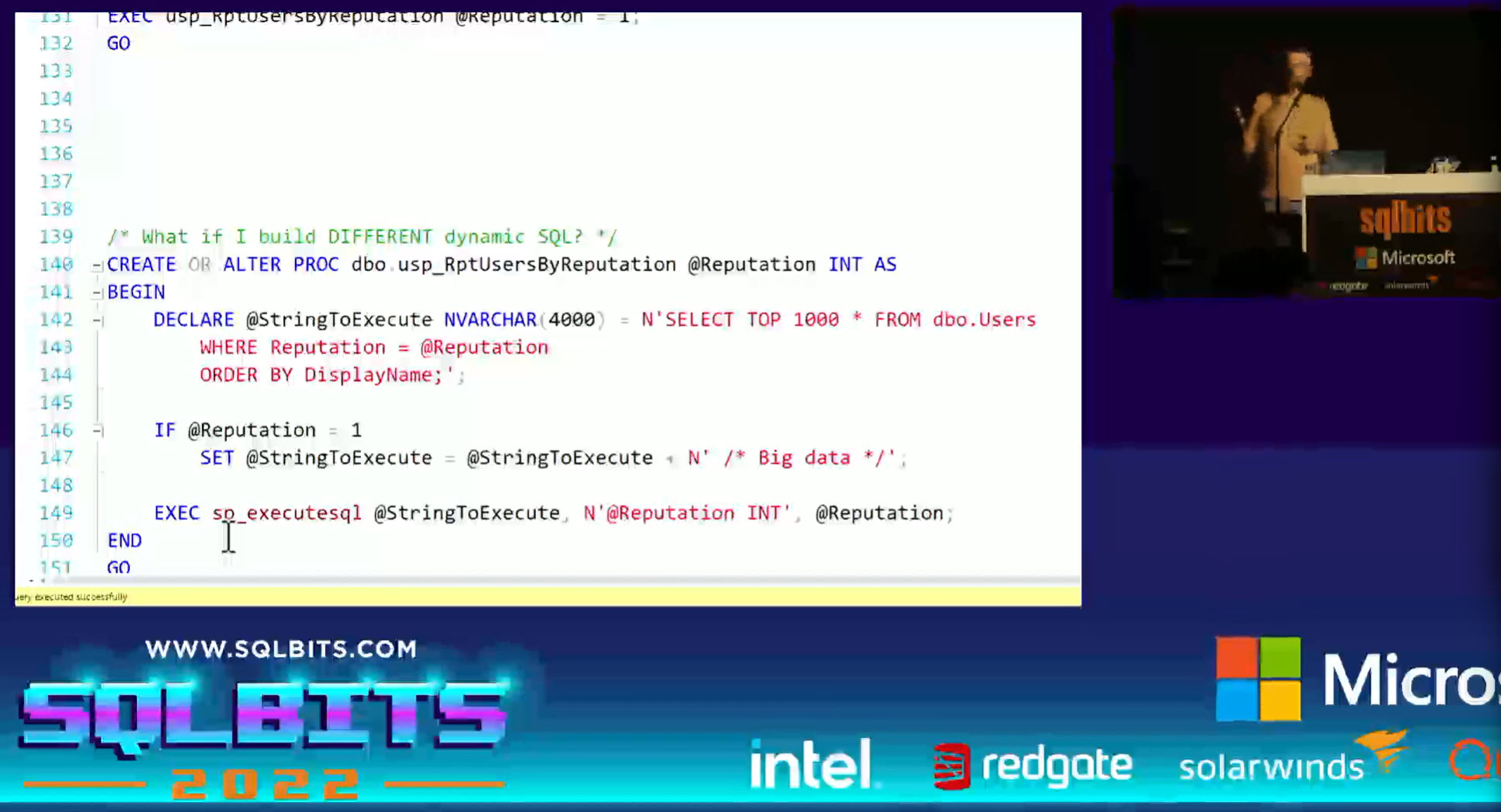 They are way more Users with Reputation value 1 than other values in the Stack Overflow database. The value 1 results in more data so it performs better with its own execution plan, unlike other values. Adding a comment in the query text we manage to cache 2 execution plans for the query. Pretty cool.
They are way more Users with Reputation value 1 than other values in the Stack Overflow database. The value 1 results in more data so it performs better with its own execution plan, unlike other values. Adding a comment in the query text we manage to cache 2 execution plans for the query. Pretty cool.
Memory Grant Feedback negative effect
Brent talked about Memory Grant Feedback (MGF) feature introduced with SQL Server 2019.
He went to demo how bad query performance can be when both MGF and parameter sniffing mess with the Memory Grant estimation at runtime.
This type of scenario can be identified by observing the minimum and maximum Memory Grant amounts from the cache plan.
For example with sp_BlitzCache.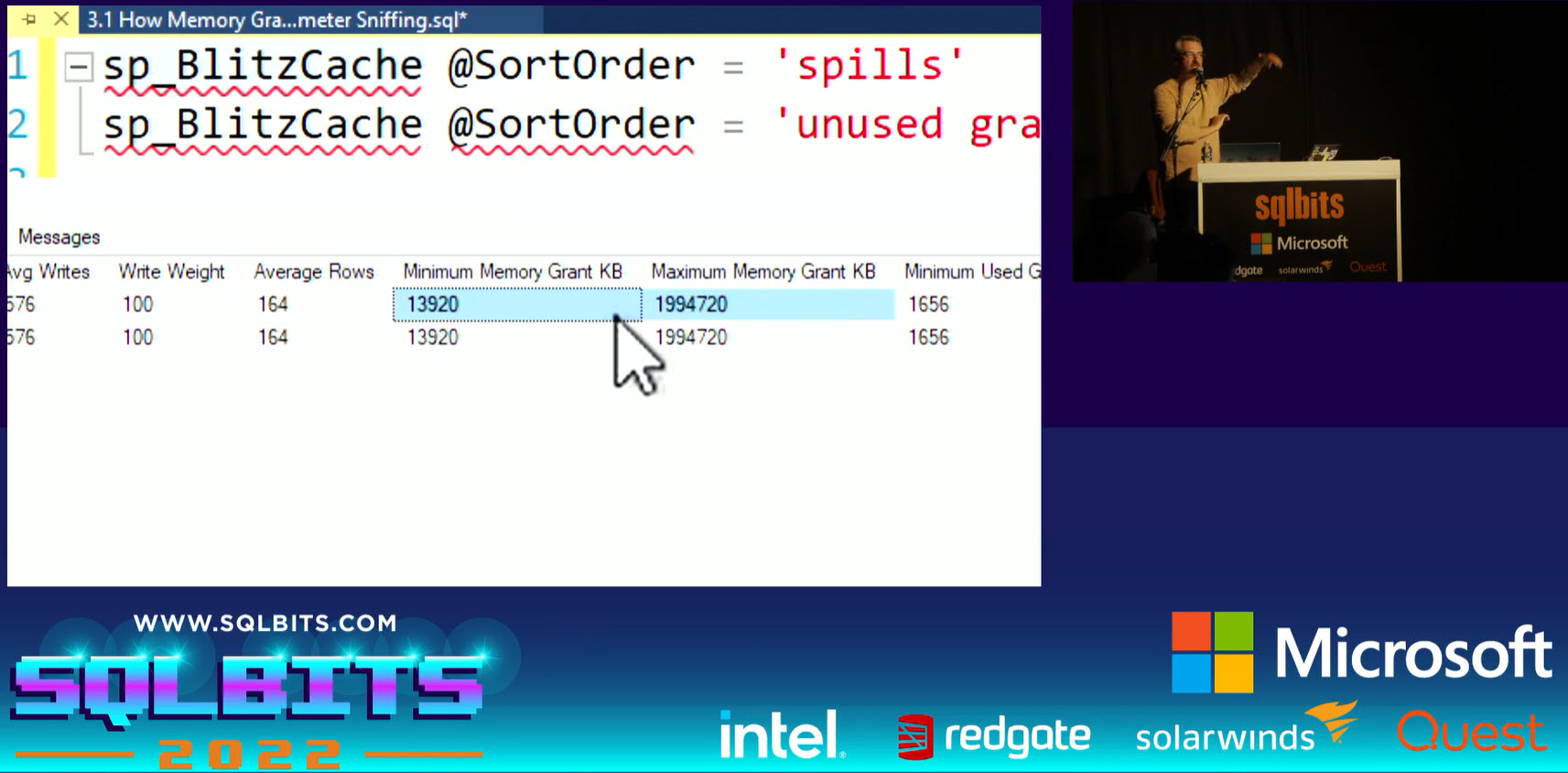 This should be improved with SQL Server 2022.
This should be improved with SQL Server 2022.
Compilation time overhead
When discussing Parameter Sniffing we have to talk about Query Hints such as OPTION(RECOMPILE).
One can wonder what is the CPU overhead of recompilation when a query is run dozens or hundreds of times per second on the server.
Brent did the demo using Erik Darling’s sp_HumanEvents to measure a Stored Procedure compilation time. It is impressively simple and effective. I’ll definitely add this tool to my troubleshooting toolbox.
EXEC dbo.sp_HumanEvents @event_type = 'recompilations', @seconds_sample = 30;
The maximum amount of Memory used by a query
Brent mentioned an interesting fact, namely that an SQL query can consume up to 25% of the “Max Server Memory” parameter.
I could not find a reference to this in the Microsoft docs but found an old article by the SQL Server Query Processor Team which is not online anymore but can be read from web.archive.org:
The server calculates the memory limit for one query. By default, this is 25% (20% on 32bit SQL 2005) of total query memory (which is set by memory broker as about 90% of server memory). This per-query limit helps to prevent one query from dominating the whole server.
When SQL Server grants too much memory for a query it can result in memory pressure on the buffer pool which can be seen looking at the famous “Page life expectancy” performance counter.
Memory grant Algorithm for SELECT TOP 100 vs SELECT TOP 101
Brent did a demo of a high variation in performance for a query with SELECT TOP 100 vs the same query with SELECT TOP 101.
The first one requested a Memory Grant of 5MB and the later 4GB.
He wrote a blog post about this one: https://www.brentozar.com/archive/2017/09/much-can-one-row-change-query-plan-part-2/
Reading Paul White on this topic it seems it is fixed with compatibility level 150 (SQL Server 2019): https://www.sql.kiwi/2010/08/sorting-row-goals-and-the-top-100-problem.html
The Professional Performance Tuning Blueprint
I was looking forward to this session with Erik Darling. Having already access to his training videos I know how the content he offers is of excellent quality.
Unfortunately being remote I was not lucky enough to get one of these great t-shirts. What a shame. Next time I will make sure to attend in person.
If you were thinking about coming to my @SQLBits precon but needed a bribe, how about a T-shirt? pic.twitter.com/Hj9VHK7PRq
— Darling Data (@erikdarlingdata) February 10, 2022
Here are a few interesting points I noted during this training session.
Query Optimizer “Cost” metric
The Query Optimizer used today in SQL Server was mostly developed for SQL Server 7.0 in the late 90s.
To compare different plan operators with each other, and choose the most profitable of them, a certain mechanism for assessing the cost of each operator was needed, some numbers.
The developer responsible for this (sources say his name was Nick) took as a basis the execution time of the operation on his own machine.
This is the machine we are talking about: Thus, a plan cost of 1 meant that the optimizer estimates the execution time of a request on Nick’s machine in 1 second.
Thus, a plan cost of 1 meant that the optimizer estimates the execution time of a request on Nick’s machine in 1 second.
Some constants also went from there, for example, random access is a constant (0.003125) which is still hardcoded inside the server and is used to estimate the cost of a random access operation.
Source: http://www.queryprocessor.ru/good-enough-plan/
Back in those days, they were no SSD, no Flash storage, maybe only 2GB of memory, etc… So random I/O was costed very highly in SQL Server because disks needed to spin, it’s an expensive thing.
The issue is that SQL Server is stuck on this stuff. it assumes only physical IO, no pages on the buffer pool.
That’s why the following execution plan shows a Clustered index scan for only 1600 rows instead of a Seek.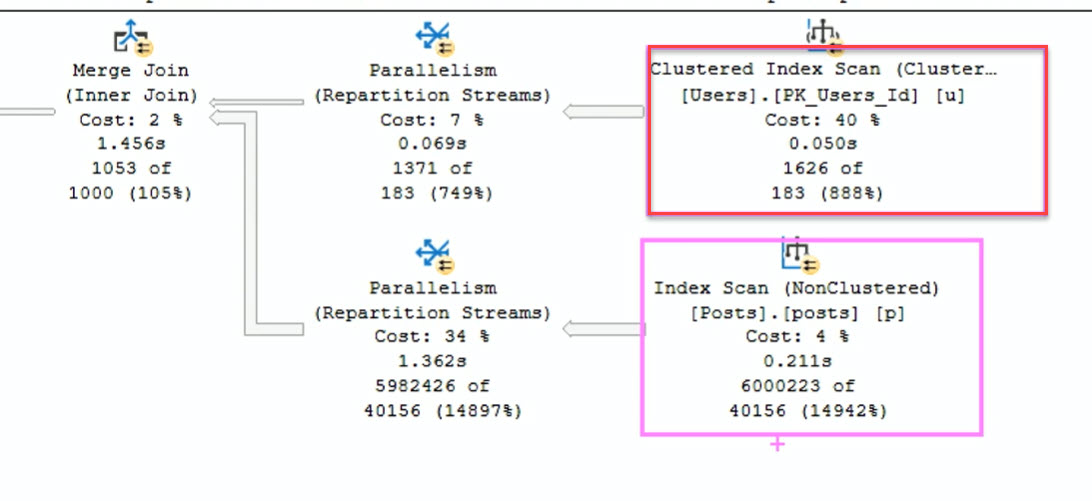
This is where the Query Tuning magic comes into play helping the Query Optimizer choose in this case a better nonclustered index.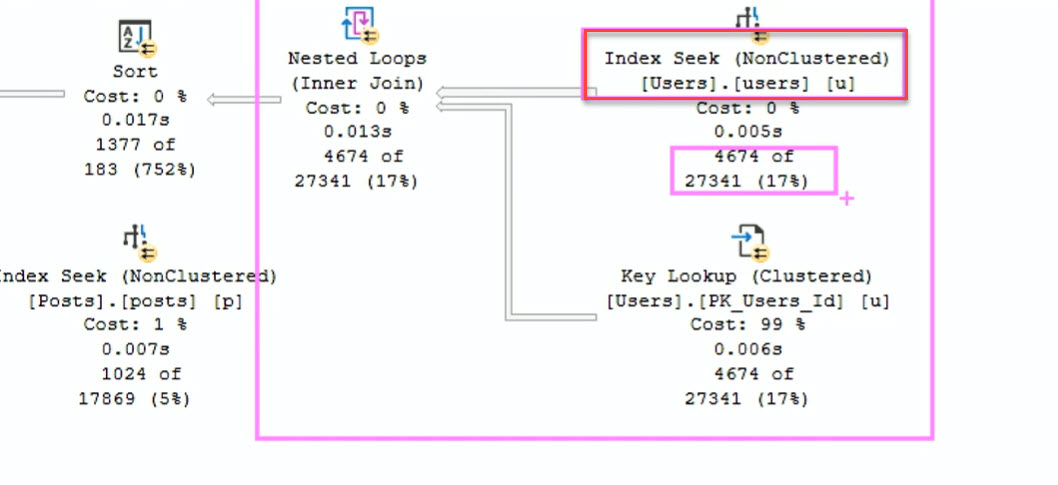
Cost should not be used to compare execution plan performance anymore. More on this below.
Operator Costs vs Operator time
Again, Erik said a few words about the operator’s costs and recommended that the operator’s time be used instead when tuning queries.
All “Costs” we see in Execution plans are estimates. Erik calls them “Query bucks”.
Don’t focus too much on Cost:
- You can have very high cost queries that finish very quickly.
- You can have a low cost query that is very slow (caused by parameter sniffing for example).
Stop looking at Cost. Start looking at Operator time.
Stop tuning queries on Estimated plans. Run the query, get the actual plan, look at the operator time.
Missing index recommendations
It’s always good to remind that missing index recommendations we can find in Execution plans should not be created blindly.
A recommendation with a “95% impact” on a query running in 10 milliseconds will not make much difference for users.
More on this topic here for example https://www.erikdarlingdata.com/sql-server/dealing-with-wide-missing-index-requests/
Query Store and plan forcing will fix all performance issues
Nope. We can force a specific plan for a query using the Query Store feature.
But, as Erik said: “..what if you don’t have a good plan to force ?”
You need to fix it yourself, with query tuning techniques.
Query rewriting
Erik demonstrated some really cool techniques of query tuning.
Rewriting parts of the code so SQL Server takes it as a cue to perform rows filtering early in the execution plan reducing the overall execution time of the query.
Here using a Self Join, the p1 alias does all the filtering, the p2 alias does the display :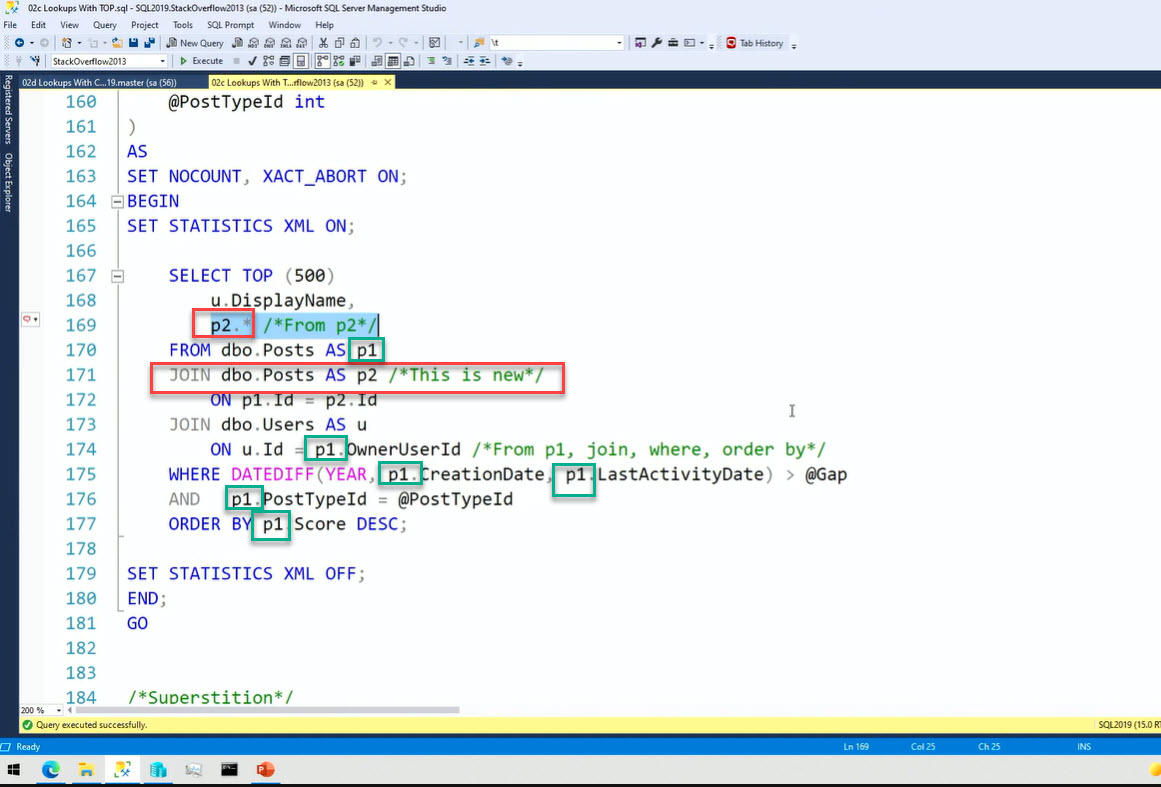
Or rewriting a query using a Function twice in the WHERE clause by using a CROSS APPLY. The function is then executed only once for the query instead of twice for every row.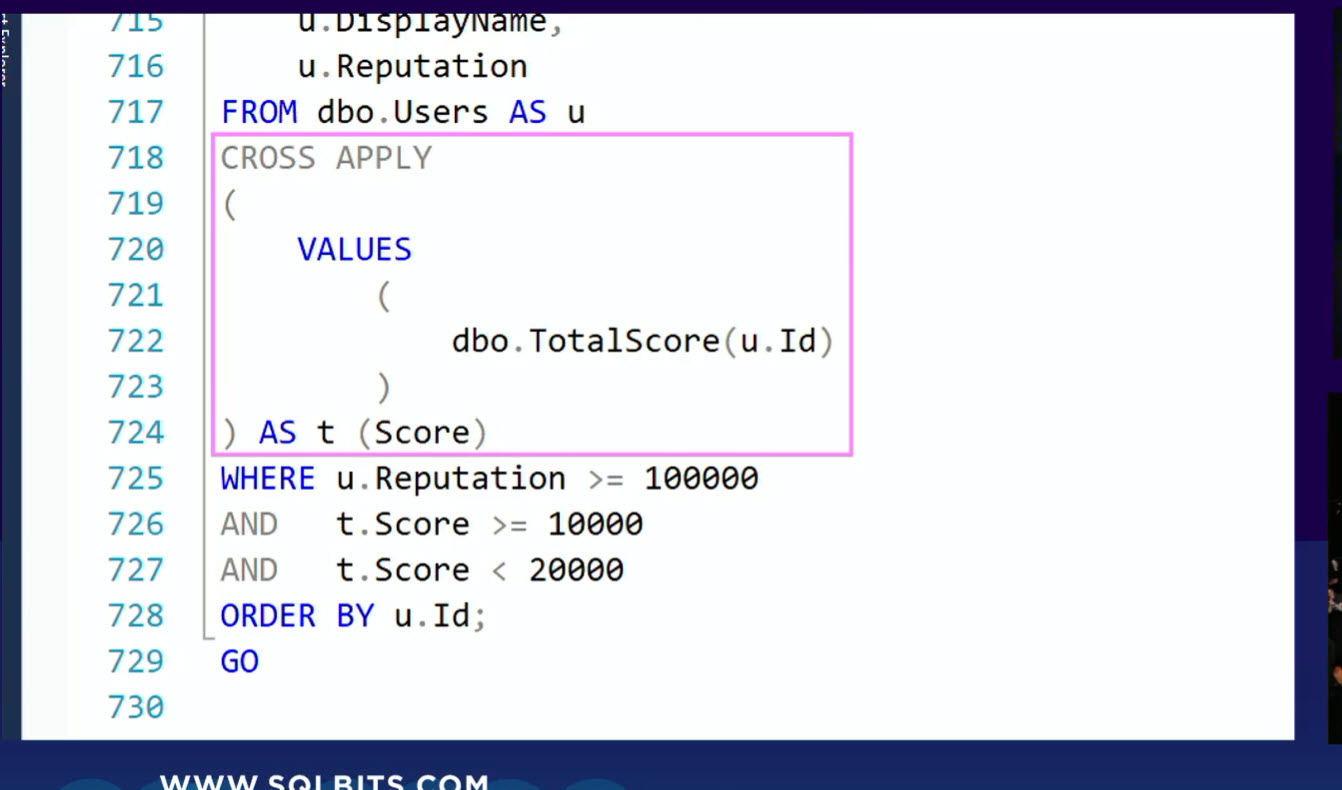
The whole session by Erik was full demos of very interesting techniques to improve query performance with topics like query rewrites, batch mode, how to design indexes, table variables, functions, CTE, etc.
We were provided with all the demonstration scripts. I will have to spend a couple of weeks working on that to fully understand it.
Conclusion
I already learned so many things in the first two days of SQLBits. It really is a must for Microsoft data professionals.
I recommend attending the full-day training sessions, you’ll learn new things from top experts.
If you didn’t register for the sessions today or on Friday, don’t miss out on the totally free Saturday.

Written by Steven Naudet
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2023/01/APY_web-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/11/LTO_WEB.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/01/HME_web.jpg)