SQL Server 2022 introduced “CE Feedback“, a feature that adjusts some Cardinality Estimation model assumptions at a query level by applying Query Store hints.
In this blog post, I’ll use an example query from the CE Feedback documentation to look in more detail at how CE works. The goal is to better understand how SQL Server uses certain assumptions to estimate the number of rows to process based on statistics.
I will not give an introduction to cardinality estimation in this post. I will simply refer you to the documentation: Cardinality Estimation (SQL Server).
Let’s just say that Cardinality Estimation is how the Query Optimizer can estimate the number of rows processed by an execution plan. Cardinality estimation is derived primarily from statistics. With more accurate estimations, the Query Optimizer can usually do a better job of producing a good query plan.
SQL Server 2022 CE Feedback demo
The query that I will use for this blog post is provided in the CE feedback scenarios documentation and is also used by Bob Ward in his SQL Server 2022 demos. See Demo for CE Feedback for SQL Server 2022
Let’s quickly go through this demo.
First, restore the AdventureWorks2016_EXT database, clear the Query Store and set the compatibility level to 160 (2022);
USE AdventureWorks2016_EXT;
GO
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 160;
GO
ALTER DATABASE CURRENT SET QUERY_STORE CLEAR ALL;
GO
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;
GO
Create an index on the City column:
CREATE NONCLUSTERED INDEX [IX_Address_City] ON [Person].[Address]([City] ASC);
Run the SELECT query below 16 times. At the time of writing this post, the CE feedback feature will trigger feedback at the sixteenth execution of a query. This number may change in the future, with a cumulative update or a newer version.
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.Address
WHERE StateProvinceID = 79 AND City = N'Redmond';
GO 16
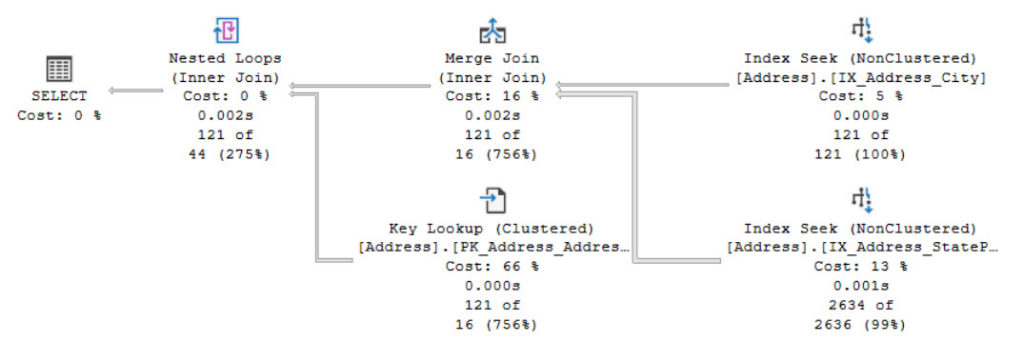
For now the Execution plan looks like this:
Then, if we run the query one more time, the CE feedback is applied, at the seventeenth execution.
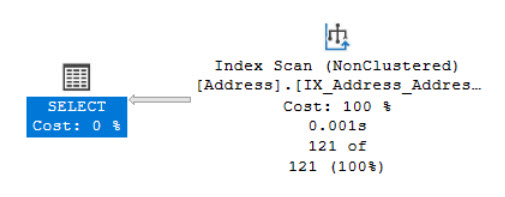
The execution plan now looks like that:
There are details on what query hint is used inside the Query Store:
SELECT * FROM sys.query_store_query_hints;
SELECT * FROM sys.query_store_plan_feedback;

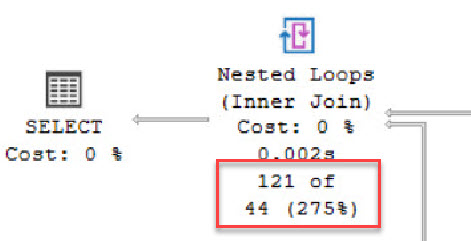
So what happens here is that by using the latest Cardinality Estimation model (we are in compatibility level 160) the estimated number of rows for this query is not so good. We estimated 44 rows but processed 121 at runtime.
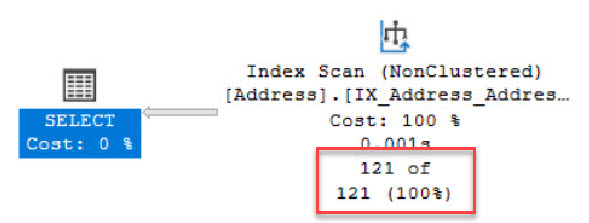
The CE Feedback feature applied the ASSUME_MIN_SELECTIVITY_FOR_FILTER_ESTIMATES query hint and we got a completely different execution plan with a better (perfect) estimation of the number of rows.
Explanations
Let’s try to understand why.
The description of the hint, which can be found under the USE HINT documentation, helps us understand that it affects the way SQL Server assumes the level of correlation between AND predicates.
ASSUME_MIN_SELECTIVITY_FOR_FILTER_ESTIMATES
Causes SQL Server to generate a plan using minimum selectivity when estimating AND predicates for filters to account for full correlation.
Additionally, there are two other related hints:
ASSUME_FULL_INDEPENDENCE_FOR_FILTER_ESTIMATES
Causes SQL Server to generate a plan using maximum selectivity when estimating AND predicates for filters to account for full independence. This hint name is the default behavior of the cardinality estimation model of SQL Server 2012 and earlier versions
ASSUME_PARTIAL_CORRELATION_FOR_FILTER_ESTIMATES
Causes SQL Server to generate a plan using most to least selectivity when estimating AND predicates for filters to account for partial correlation. This hint name is the default behavior of the cardinality estimation model of SQL Server 2014 or higher.
That is to say, they are 3 model assumptions to determine the selectivity of multiple predicates with an AND clause; full correlation, partial correlation, and full independence.
This is well described in this white paper: Optimizing Your Query Plans with the SQL Server 2014 Cardinality Estimator
Full independence
Under the model assumption of full independence, the selectivity of the individual predicates is multiplied together.
Let’s find the selectivity of the predicates.
The selectivity is the estimated number of rows with a value equal to the predicate divided by the total number of rows in the table.
The selectivity can be derived from the statistics’ histogram. This example uses values that are represented as RANGE_HI_KEY steps in the histograms, so it’s quite easy to get the selectivity.
For the selectivity of the “Redmond” city, we look at the stats histogram of the city column index.
With the following query, we get a selectivity of 0.006169063. 19614 is the number of rows in the Address table.
SELECT
h.step_number
, h.range_high_key
, h.range_rows
, h.equal_rows
, h.average_range_rows
, h.equal_rows/19614 AS predicate_selectivity
FROM sys.stats AS s
CROSS APPLY sys.dm_db_stats_histogram(s.[object_id], s.stats_id) AS h
WHERE s.[name] = 'IX_Address_City'
AND range_high_key = 'Redmond'

The Washington state (ID = 79) gets a selectivity of 0.1343938.

The number of rows estimated for the whole predicate under the Independence model assumption is 16.
SELECT 0.006169063 * 0.1343938 * 19614 -- 16.26165
We can verify this by using the query hint associated with the full independence model assumption:
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.Address
WHERE StateProvinceID = 79 AND City = N'Redmond'
OPTION(USE HINT('ASSUME_FULL_INDEPENDENCE_FOR_FILTER_ESTIMATES'), RECOMPILE)
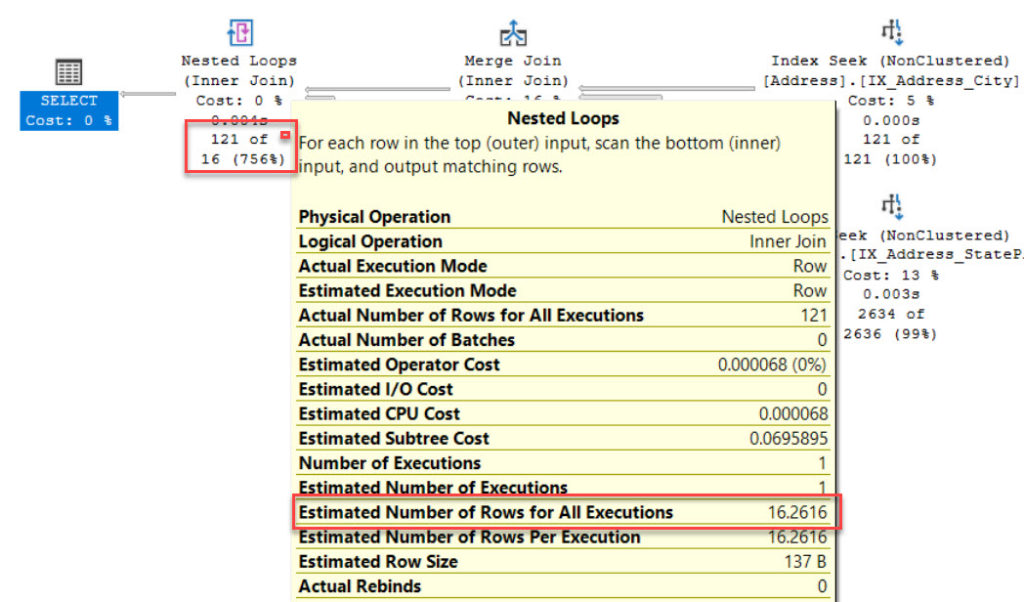
We get the exact number we just calculated of 16.2616 estimated rows.
Partial correlation
To assume some correlation, SQL Server uses the Partial correlation model which is based on an exponential backoff.
The predicates are sorted in ascending order of selectivity. SQL Server then “moderates” each successive predicate by taking larger square roots.
Let’s say we have 3 predicates; P1 to P3 sorted by selectivity, the row estimate formula would be:
SELECT P1 * SQRT(P2) * SQRT(SQRT(P3)) * TableRowCount
In our case, we get:
SELECT 0.006169063 * SQRT(0.1343938) * 19614 -- 44.3583
This is what we got before the CE feedback was triggered; it’s the default behavior since SQL Server 2014.
Full correlation
Under full correlation, SQL Server just takes the most selective predicate for the whole conjunction of predicates.
SELECT 0.006169063 * 19614 -- 121.00
We get 121 rows for Redmond as seen in the histogram earlier.
CE Feedback behavior
For this specific query, the CE Feedback feature did not just try to use the “legacy CE model” with the full independence assumption, it found that there is a strong correlation between both predicates and applied the full correlation assumption. This is very nice.
CE Feedback will look at the row estimates and tries to adjust. If the number of rows is overestimated it means that the predicates are more independent. If the estimation is too low there is more correlation than expected.
Conclusion
The following table summarizes the assumption models, hints, and the number of estimated rows for this query example.

I hope that this blog will help you understand a little bit more about how the Query Optimizer is working and what CE Feedback is doing in SQL Server 2022.
Remember that CE Feedback is not limited to this predicate correlation scenario, it will also affect “Join Containment”, and “Row Goal”.
In addition to all the links provided above I would also recommend reading Paul White’s answer to this StackExchange question: How does SQL Server know predicates are correlated?
Written by Steven Naudet
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2023/01/APY_web-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/11/LTO_WEB.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/01/HME_web.jpg)