When performing search operations on large datasets, performance is a key consideration for ensuring that an application remains efficient and user-friendly. This consideration equally applies when working with embedded data. That’s why in this blog post we’ll explore the different possibilities for vector search and show how to leverage the latest features of SQL Server 2025 Preview to accelerate your semantic search workloads.
Exact and Approximate Search:
First, let’s talk about the different functions available in SQL-Server 2025 Preview and the concepts behind them.
If you read my last blog post, you may remember that we used the VECTOR_DISTANCE() function to search for black pants I might wear during my summer vacation. This function calculates the Exact Nearest Neighbors (ENN) for the vector of the search text. In practice, it calculates the vector distance between the given vector and all other vectors, then sorts the results and returns the top (K-) Nearest Neighbors (NN). In the context of OLTP systems and B-tree indexes, you can compare this process to an index scan operation with additional sorting and computation overhead. As you can already anticipate, calculating the Exact Nearest Neighbors can be quite resource-intensive depending on the amount of data. In the Microsoft documentation, the general recommendation is to perform an exact search when you have fewer than 50’000 vectors – noting that you can also prefilter the number of vectors using predicates.
When working with large vector datasets the VECTOR_SEARCH() function comes into play. Instead of scanning the entire dataset and calculating the distance for each vector, the VECTOR_SEARCH() function approximates the nearest neighbors (ANN) for a given vector using vector index structures. While ANN requires far fewer resources than exact K-NN, it comes with a trade-off in terms of accuracy.
This trade-off in accuracy is measured by the recall value. Recall represents the overlap between the approximate neighbors found and the true K-NN set. For example, if we search for the 10 nearest neighbors of a vector and ANN returns 7 results that are also in the exact K-NN set, the recall would be 0.7 (7 /10 = 0.9). The closer the recall is to 1, the more accurate the ANN results are.
In SQL-Server 2025 Preview, a vector index is required to perform ANN searches with the VECTOR_SEARCH() function. SQL-Server 2025 Preview uses the DiskANN algorithm to create these graph-based vector indexes. DiskANN is designed to leverage SSDs and minimal memory resources for storing and handling graph indexes, while still maintaining high accuracy with a recall of around 0.95.
Note: While the VECTOR_DISTANCE function is available in SQL-Server 2025 preview and Azure SQL, the VECTOR_SEARCH function is currently only available in SQL-Server 2025 Preview.
You can get more information’s from Microsoft’s documentation.
Let’s take a practical look at the features:
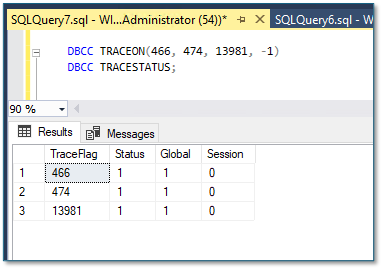
First of all we have to enable some trace flags to be able to use the preview features:
DBCC TRACEON(466, 474, 13981, -1);
DBCC TRACESTATUS;
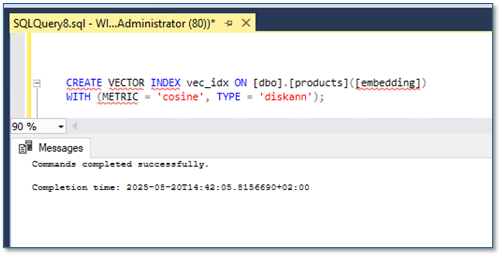
Then I’m creating a vector index on my “embedding” column in my “dbo.products” table. I’m using the DiskANN algorithm which is currently the only one which is supported. Further I’m using the “cosine” metric for the similarity calculation. You can also use “Euclidean Distance” or “Dot Product” as similarity metrics.
CREATE VECTOR INDEX vec_idx ON [dbo].[products]([embedding])
WITH (METRIC = 'cosine', TYPE = 'diskann');
Then we are ready to go and we can test the VECTOR_SEARCH function with the query below:
--Test Approximate Search
DECLARE @SemanticSearchText Nvarchar(max) = 'Im looking for black pants for men which I can wear during my summer vacation.'
DECLARE @qv VECTOR(1536) = AI_GENERATE_EMBEDDINGS(@SemanticSearchText USE MODEL OpenAITextEmbedding3Small);
SELECT
product_id,
product_name,
Description,
price,
s.season,
g.gender
FROM
VECTOR_SEARCH(
TABLE = [dbo].[products] AS p,
COLUMN = [embedding],
SIMILAR_TO = @qv,
METRIC = 'cosine',
TOP_N = 10
) AS vs
inner join dbo.season s on p.season_id = s.season_id
inner join dbo.gender g on p.gender_id = g.gender_id
ORDER BY vs.distance
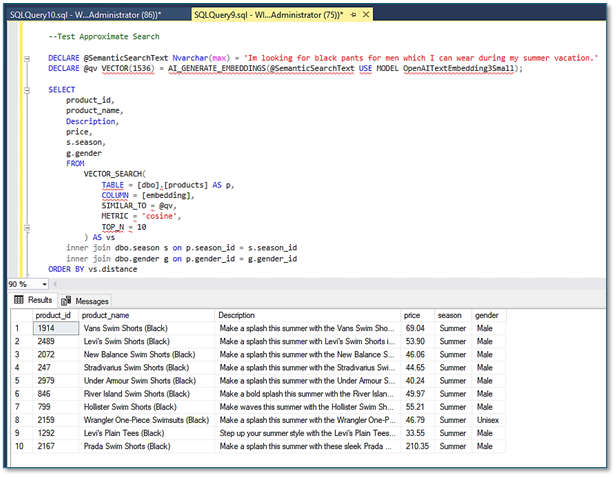
As you can see we are getting a pretty accurate result. Lets compare the results of the exact search using the VECTOR_DISTANCE function and the approximate search using the VECTOR_SEARCH function with the code below:
DECLARE @SemanticSearchText Nvarchar(max) = 'Im looking for black pants for men which I can wear during my summer vacation.'
DECLARE @qv VECTOR(1536) = AI_GENERATE_EMBEDDINGS(@SemanticSearchText USE MODEL OpenAITextEmbedding3Small);
--Exact Search
SELECT TOP(10)
product_id as ENN_product_id,
product_name as ENN_product_name,
Description as ENN_description,
price as ENN_price,
s.season as ENN_price,
g.gender as ENN_gender,
VECTOR_DISTANCE('cosine', @qv, embedding) AS distance
FROM dbo.products p
inner join dbo.season s on p.season_id = s.season_id
inner join dbo.gender g on p.gender_id = g.gender_id
ORDER BY distance;
--Approximate Search
SELECT
product_id as ANN_product_id,
product_name as ANN_product_name,
Description as ANN_Description,
price as ANN_price,
s.season as ANN_season,
g.gender as ANN_gender
FROM
VECTOR_SEARCH(
TABLE = [dbo].[products] AS p,
COLUMN = [embedding],
SIMILAR_TO = @qv,
METRIC = 'cosine',
TOP_N = 10
) AS vs
inner join dbo.season s on p.season_id = s.season_id
inner join dbo.gender g on p.gender_id = g.gender_id
ORDER BY vs.distance
As you can see, we are getting a fairly accurate ANN result. This corresponds to a recall of 0.8, since only the products with IDs 1292 and 2167 are missing from the exact search result set:
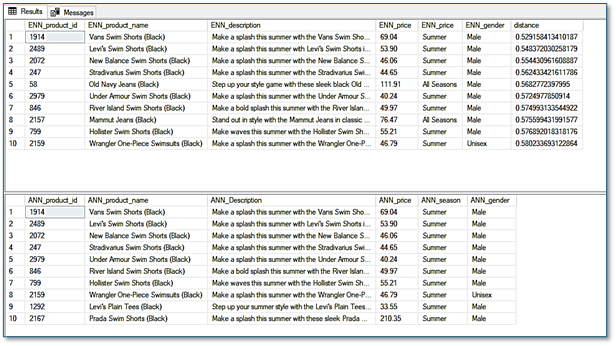
Of course, in this example we only have 3’000 products in our database, so the savings in resource consumption when using ANN are not very significant. However, when processing much larger datasets, using ANN becomes highly relevant.
Limitations with Vector indexes – in SQL-Server 2025 Preview
Interesting to know is that tables with a vector index are read only in the preview edition so you can’t manipulate data at the moment:
update dbo.products
set price = price * 0.8
where product_id = 13
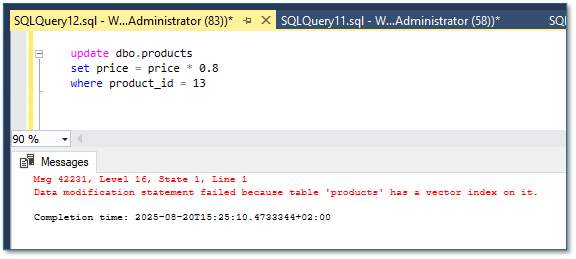
In addition to support a vector index, the table must have a clustered index defined on a single column that is a primary key with the integer data type. In the preview edition, vector indexes do also not support partitioning and are not replicated to subscribers when using replication. According to Microsoft, these limitations apply to the current preview edition of SQL Server 2025. I’m excited to see if these limitations will be removed in the GA release.
Let me know your thoughts in the comment section below and thanks for reading!
Hocine
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2024/01/HME_web.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/03/AHI_web.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2023/09/SGR_web-2.jpg)