Some time ago, I had to deal with a new partitioning scenario that included sliding windows stuff for mainly archiving purpose. Regarding the customer context, I used some management scripts that include this time dropping oldest partition. We didn’t care about data oldest than 2 years. Usually in this case, I use a method that consists in dropping data by switching first the oldest partition to a staging table and then truncate it. Finally we may safely merge oldest partitions and avoid any data movement. At a first glance, it seems to be a complex process for dropping data but until SQL Server 2014 there is no way to do better in order to minimize operation logging.

This week, I had the opportunity to work with SQL Server 2016 to learn about new partition improvements. By the way, the only thing I could find out from my different internet researches concerned the new command TRUNCATE TABLE WITH PARTITIONS.
My first feeling was it is not a very exciting feature in contrast to previous versions that provided a mixture of both performance and maintenance improvements in this field. But after investigating further, I was able to point out some advantages to use this command. Let’s go back to my sliding windows scenario. In order to drop data from my oldest partition I have to:
- Switch the oldest partition to a staging table
- Drop data from this staging table with TRUNCATE command in order to minimize transaction logging
- Execute MERGE command in order to slide all partitions to the left side
What about introducing the new TRUNCATE TABLE command in this scenario?
In fact, it will simplify the above process by replacing step 1 and step 2 by the TRUNCATE command at the partition level. The new scenario becomes:
- TRUNCATE TABLE at the corresponding partition
- Execute MERGE command in order to slide all partitions to the left
The only instruction I need to use is as follows:
TRUNCATE TABLE [dbo].[FactOnlineSales] WITH ( PARTITIONS (2) );
What about locking?
As expected, SQL Server will use a lock granularity hierarchy with a mixture of Sch-S, Sch-M and X locks regarding the corresponding locked resource. You may see two allocation units in my case because I’m using a partitioned clustered columnstore index in this demo. As a reminder, compressed columnstore segments are stored in LOB.
| Object | Resource type | Resource subtype | Resource description | Associated entity | Lock request mode |
| OBJECT | FactOnlineSales | Sch-M | |||
| METADATA | DATA_SPACE | data_space_id = 3 | Columnstore2007 (filegroup that relies on partition nb 2) | Sch-M | |
| HOBT | Partition nb 2 | Sch-M | |||
| ALLOCATION_UNIT | Related to data_space_id = 3 with state = DROPPED (LOB_DATA) | X | |||
| ALLOCATION_UNIT | Related to data_space_id = 3 (IN_ROW_DATA) | X | |||
| KEY | Records in the partition 2 | X |
What about logging?
Well, if I refer to the corresponding records into the transaction log file, TRUNCATE partition command seems to act as a normal TRUNCATE operation. Firstly, we may notice few records generated related to marking the concerned structures to drop and then the deferred drop mechanism comes into play by deallocating them.
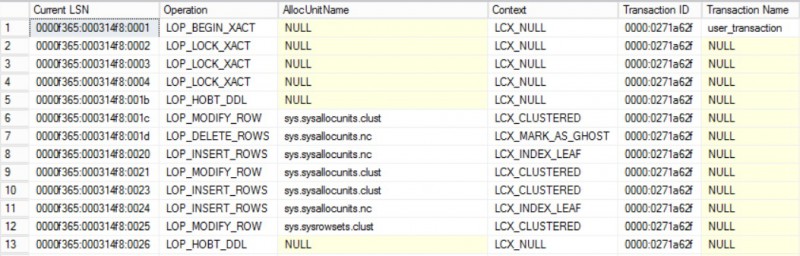
…

…

…

Happy partitioning!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/05/martin_bracher_2048x1536.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/DWE_web-min-scaled.jpg)