How to migrate an environment that includes availability groups from one Windows Failover Cluster to another one? This scenario is definitely uncommon and requires a good preparation. How to achieve this task depends mainly of your context. Indeed, we may use a plenty of scenarios according to the architecture in-place as well as the customer constraints in terms of maximum downtime allowed for example. Among all possible scenarios, there is a process called “cross-cluster migration scenario” that involves two Windows Failover Clusters side by side. In this blog post, I would like to focus on it and I will then show improvements in this field with SQL Server 2016.
Just to be clear, for the first scenario my intention is not to detail all the steps required to achieve a cross-cluster migration. You may refer to the whitepaper written by Microsoft here. To be honest, my feeling is the documentation may be improved because it includes sometimes a lack of specificity but it has the great merit of being a reality. I remember to navigate through this document, go down and go up back to the beginning several times by using the bookmarks in order to be confident with my understanding of the whole process. Anyway, let’s apply this procedure to a real customer case.
In my experience, I may confirm we haven’t customers with only one availability group installed on their environment. Most of time, we encountered customer cases which include several SQL Server instances and replicas on the same cluster node. I will demonstrate it with the following infrastructure (similar to most customer shops):
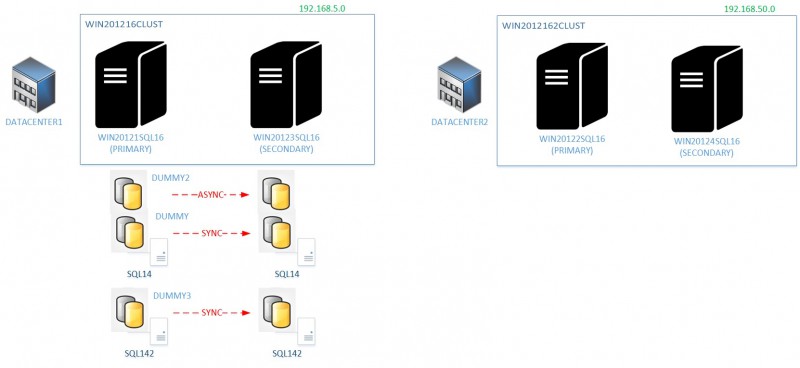
We have 3 availability groups with the first two ones hosted on the same SQL14 instance and the last one on the SQL142 instance. The availability group architecture runs on the top of a Windows failover cluster (WSFC) – WIN201216CLUST – that includes two cluster nodes and a file share witness (FSW) not reported in the above picture. So a pretty common scenario at customer shops as I said previously. Without going into details of customer cases, the idea was to migrate all the current physical environment from the first datacenter (subnet 192.168.5.0) to the second datacenter on a virtual environment (subnet 192.168.50.0). As an aside, note that my customer subnets are not exactly the same and he used a different set of IP ranges but anyway it will help to set the scene.
So basically, according to the Microsoft documentation the migration process is divided in 4 main steps:
- Preparation of the new WSFC environment (no downtime)
- Preparation of the migration plan (no downtime).
- Data migration (no downtime)
- Resource migration (downtime)
Probably, the main advantage of using this procedure is the short outage that will occur during the last step (resource migration). In this way, we are more comfortable with previous preparation steps because they do not require downtime. Generally migration of data between two replicas is an important part of the migration process in terms of time and we are able to prepare smoothly the migration stuff between the two WSFCs.
Preparation of the new WSFC
Further points in the process have brought my attention. The first one concerns the preparation of the new WSFC environment (first step). Basically, we have to prepare the target environment that will host our existing availability groups and Microsoft warned us about the number of nodes (temporary nodes or not) regarding the overlapping among availability groups section and migration batches. During this preparation step we have also to set the corresponding cluster registry permissions to allow correct switching of the cluster context from the new installed replicas on the remote WSFC. At the first glance, I wondered why we have to perform such operation but the response became obvious when I tried to do a switch of the cluster from my new SQL Server instance and I faced the following error message:
ALTER SERVER CONFIGURATION SET HADR CLUSTER CONTEXT = 'WIN201216CLUST.dbi-services.test'
Msg 19411, Level 16, State 1, Line 1
The specified Windows Server Failover Clustering (WSFC) cluster, ‘WIN201216CLUST.dbi-services.test’, is not ready to become the cluster context of AlwaysOn Availability Groups (Windows error code: 5).
The possible reason could be that the specified WSFC cluster is not up or that a security permissions issue was encountered. Fix the cause of the failure, and retry your ALTER SERVER CONFIGURATION SET HADR CLUSTER CONTEXT = ‘remote_wsfc_cluster_name’ command.
It seems that my SQL Server instance is trying unsuccessfully to get information from the registry hive of the remote WSFC in order to get a picture of the global configuration. As an aside, until the cluster context is not switched, we are not able to add the new replicas to the existing availability group. If we put a procmon trace (from sysinternals) on the primary cluster node, we may notice that executing the above command from the remote SQL Server instance implies the reading of the local HKLM\Cluster hive.
Well, after fixing the cluster permissions issues by using the PowerShell script provided by Microsoft, we may add the concerned replicas to our existing AG configuration. The operation must be applied on all the replicas from the same WSFC. According to the Microsoft documentation, I added then two replicas in synchronous replication and another one in asynchronous mode. A quick look at the concerned DMVs confirms that everything is ok
SELECT g.name as ag_name, r.replica_server_name as replica_name, rs.is_local, rs.role_desc AS [role], rs.connected_state_desc as connection_state, rs.synchronization_health_desc as sync_state FROM sys.dm_hadr_availability_replica_states as rs JOIN sys.availability_groups as g on g.group_id = rs.group_id JOIN sys.availability_replicas as r on r.replica_id = rs.replica_id

SELECT g.name as ag_name, r.replica_server_name as replica_name, DB_NAME(drs.database_id) AS [db_name], drs.database_state_desc as db_state, drs.is_primary_replica, drs.synchronization_health_desc as sync_health, drs.synchronization_state_desc as sync_state FROM sys.dm_hadr_database_replica_states as drs JOIN sys.availability_groups as g on g.group_id = drs.group_id JOIN sys.availability_replicas as r on r.replica_id = drs.replica_id ORDER BY r.replica_server_name

If you are curious like me you may wonder how SQL Server deals with the two remote replicas? A quick look at the registry doesn’t give us any clue. But what about getting registry changed values after adding new replicas? Regshot tool was a good tool to use in my case to track changes between two registry snapshots:

This is probably not an exhaustive list of added or modified keys but this output provides a lot of useful information to understand what’s happening to the cluster registry hive when adding remote replicas. The concerned resource is identified by the id 9bb8b518-2d1a-4705-a378-86f282d387da which corresponds to my DUMMY availability group. It makes sense to notice some changes at this level.
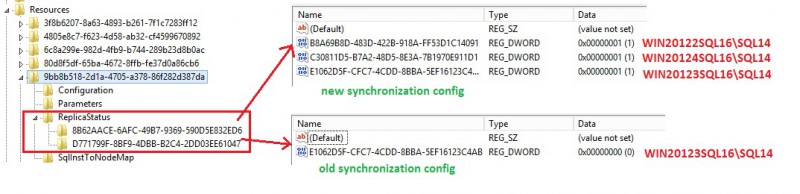
I may formulate some assumptions here. Those registry changes are necessary to represent the complete picture of the new configuration (with ID 8B62AACE-6AFC-49B7-9369-590D5E832ED6). If we refer to the SQL Server error log we may identify easily each replica server name by its corresponding hexadecimal value.
Resource migration
However, resource migration is a critical part of the migration process because it will introduce downtime. The downtime duration depends mainly on the number of items to migrate. Migrating availability group includes bringing offline each availability group as well as dropping each corresponding listener at the source and then recreating the availability group configuration at the target. In other words, the more you have items to migrate, the longer this migration step might be.
We are also concerned by the availability group’s topology and migration batches. Indeed, according to the Microsoft documentation, we may not change the HADR context of the targeted SQL Server instance until we have migrated all the related availability groups preventing using them as new functional replicas. To understand the importance of migration batches, think about the following scenario: the HADR context to the remote cluster is enabled and you have just finished to migrate the first availability group. You then switch back the HADR to the local context but you forget to migrate the second availability. At this point, reverting the HADR context to the remote cluster is not possible because the concerned replica is no longer eligible.
Assuming I used a minimal configuration that includes only two target replicas as shown in the first picture (WSFC at the destination), I have at least to group DUMMY and DUMMY2 availability groups in one batch. DUMMY3 availability group may be migrated as a separate batch.
So basically, steps to perform the resources migration are as follows:
- Stop application connectivity on each availability group
- Bring offline each availability group (ALTER AVAILABILTY GROUP OFFLINE) and drop the corresponding listener
- Set the HADR context to local for each cluster node
- Recreate each availability group and the corresponding listener with the new configuration
- Validate application connectivity
The migration script provided by Microsoft helps a lot in the generation of the availability group definition but we face some restrictions. Indeed, the script doesn’t retain the exact configuration of the old environment including the previous replication mode or the backup policy for example. This is an expected behavior and according to the Microsoft documentation it is up to you to maintain the existing configuration at the destination.
Finally after performing the last migration step here is the last configuration for my DUMMY availability group as follows:


So what about SQL Server 2016 in the context of cross-cluster migration?
By starting with SQL Server 2016, distributed availability groups are probably the way to go. I already introduced this feature in a previous blog and I would like to show you how interesting this feature is in this context. Well let’s first go back to the initial context. We basically have to perform the exact same steps compared to the first scenario but distributed availability groups may increase ? drastically the complexity of the entire process.
- Preparation of the new WSFC environment (no downtime) – We no longer need to grant access on the cluster registry hive permissions to the SQL Server service account as well as switching the HADR context to the remote cluster
- Preparation of the new availability groups on the destination WSFC including the corresponding listeners (no downtime) – We no longer need to take into account the migration batches in the migration plan
- Data migration between the availability groups (no downtime)
- Application redirection to the new availability groups (downtime) – We no longer need to switch back the HADR context to local nodes as well as recreating the different availability group’s configurations at this level.
In short, the migration of availability groups across WSFC with SQL Server 2016 requires less efforts and shorter downtime.
Here is the new scenario after preparing the new WSFC environment and applying data migration between availability groups in the both sides
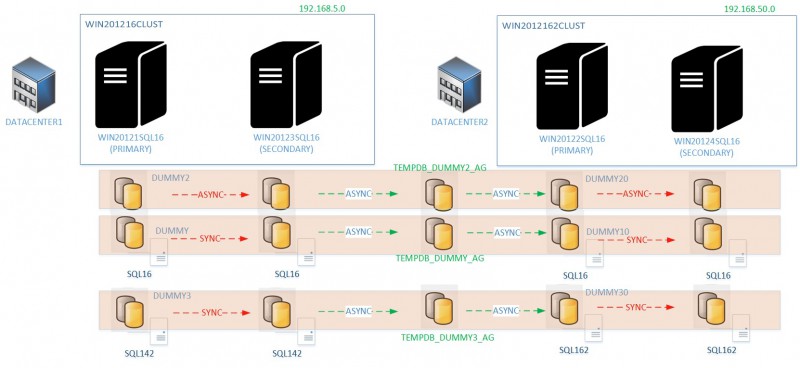
During the first phase, I prepared a new Windows Failover Cluster WIN2012162CLUST which will host empty availability groups DUMMY10, DUMMY20 and DUMMY30. Those availability groups will act as new containers when implementing distributed availability groups (respectively TEMPDB_DUMMY_AG, TEMPDB_DUMMY2AG and TEMPDB_DUMMY3AG). You may notice that I configured ASYNC replication mode between local and remote availability groups but regarding our context, synchronous replication mode remains a viable option.
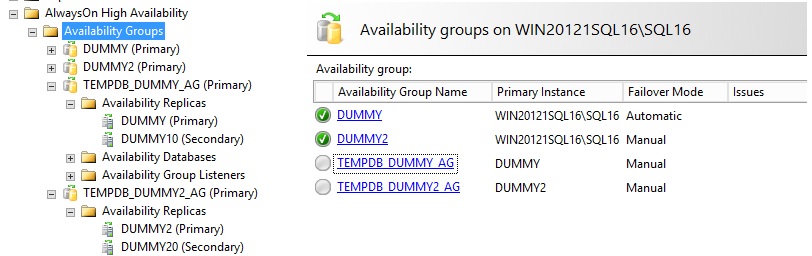
A quick look at the sys.dm_hadr_database_replica_states confirms all the distributed availability groups are working well. TEMPDB_DUMMY3_AG is not included in the picture below.
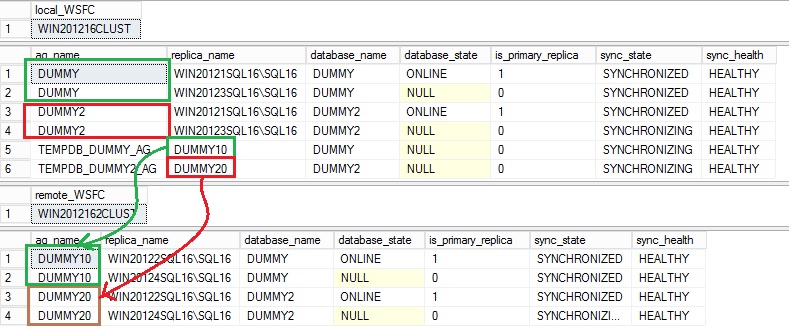
At this step, availability groups (DUMMY10 and DUMMY20) on the remote WSFC cannot be accessed and are used only as standby waiting to be switched as new primaries.
In the last step (resources migration) here the new steps we have to execute
- Failover all the availability groups context to the remote WSFC by using distributed availability group capabilities
- Redirect applications to point to the new listener
And that’s all!
In the respect of the last point, we may use different approaches and here is mine regarding the context. We don’t want to modify application connection strings that may lead to extra steps from the application side. Listeners previously created with remote availability groups may be considered as technical listeners in order to achieve cross-cluster migration through distributed availability groups. Once this operation is done, we may reuse old listeners in the new environment and achieve almost transparent application redirection in this way.
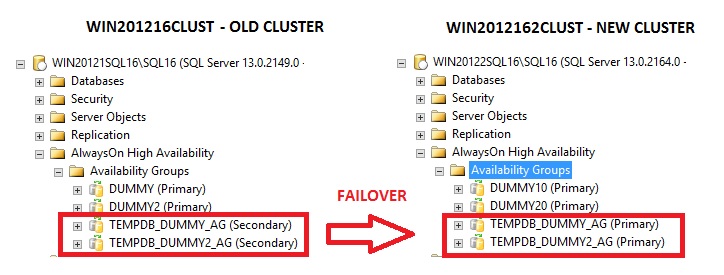
One another important thing I have to cover is the distributed availability group process behavior. After digging into several failover tests, I noticed triggering a failover event from a distributed availability group will move the primary replica of each secondary availability group to PRIMARY but unfortunately, it will not switch automatically the role of the primary of each primary availability group to SECONDARY as expected. This situation may lead to a split brain scenario in the worst case. The quick workaround consists in forcing the primary availability group to be SECONDARY before initiating the failover process. Let me demonstrate a little bit:
/* ========= 0- DEMOTE OLD LOCAL AGS TO SECONDARY TO AVOID UPDATE ACTIVITY ========= ========= FROM THE OLD PRIMARIES (SPLIT BRAIN SCENARIO ========= */ :CONNECT LST-DUMMY ALTER AVAILABILITY GROUP [TEMPDB_DUMMY_AG] SET (ROLE = SECONDARY); ALTER AVAILABILITY GROUP [TEMPDB_DUMMY2_AG] SET (ROLE = SECONDARY); GO /* ========= 1- FORCE FAILOVER DISTRIBUTED AVAILABILTY GROUPS ========= */ :CONNECT LST-DUMMY10 USE master; GO ALTER AVAILABILITY GROUP [TEMPDB_DUMMY_AG] FORCE_FAILOVER_ALLOW_DATA_LOSS; GO ALTER AVAILABILITY GROUP [TEMPDB_DUMMY2_AG] FORCE_FAILOVER_ALLOW_DATA_LOSS; GO
The new situation is as follows:
Let’s try to connect to the old primary availability group. Accessing the DUMMY database is no longer permitted as expected
Msg 976, Level 14, State 1, Line 1
The target database, ‘DUMMY’, is participating in an availability group and is currently
not accessible for queries. Either data movement is suspended or the availability replica is not
enabled for read access. To allow read-only access to this and other databases in the availability
group, enable read access to one or more secondary availability replicas in the group.
For more information, see the ALTER AVAILABILITY GROUP statement in SQL Server Books Online.
We now have to get back the old listener for the new primary availability groups. In my case, I decided to drop the old availability groups in order to completely remove the availability group configuration from the primary WSFC and to make the concerned databases definitely inaccessible as well (RESTORING STATE).
/* ========= 3- DROP LISTENERS FROM THE OLD AVAILABILITY GROUPS ========= */ :CONNECT WIN20121SQL16\SQL16 USE master; GO DROP AVAILABILITY GROUP [DUMMY]; GO DROP AVAILABILITY GROUP [DUMMY2]; GO
Finally I may drop technical listeners and recreate application listeners by using the following script:
/* ========= 4- DROP TECHNICAL LISTENERS FROM THE NEW AVAILABILITY GROUPS =========
========= ADD APPLICATION LISTENERS WITH NEW CONFIG ========= */
:CONNECT WIN20122SQL16\SQL16
USE master;
GO
ALTER AVAILABILITY GROUP [DUMMY10]
REMOVE LISTENER 'LST-DUMMY10';
GO
ALTER AVAILABILITY GROUP [DUMMY20]
REMOVE LISTENER 'LST-DUMMY20';
GO
ALTER AVAILABILITY GROUP [DUMMY10]
ADD LISTENER 'LST-DUMMY' (WITH IP ((N'192.168.50.35', N'255.255.255.0')), PORT=1433);
GO
ALTER AVAILABILITY GROUP [DUMMY20]
ADD LISTENER 'LST-DUMMY' (WITH IP ((N'192.168.50.36', N'255.255.255.0')), PORT=1433);
GO
Et voilà!
Final thoughts
Cross-cluster migration is definitly a complex process regardless SQL Server 2016 improvements. However as we’ve seen in this blog post, the last SQL Server version may reduce the overall complexity at the different migration steps. Personnally as a DBA, I don’t like to use custom registry modification stuff which may impact directly the WSFC level (required in the first migration model) because it may introduce some anxiousness and unexpected events. SQL Server 2016 provides a more secure way through distributed availability groups and includes all migration steps at the SQL Server level which make me more confident with the migration process.
Happy cross-cluster migration!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2023/01/APY_web-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/FRJ_web-min-scaled.jpg)