
Buffer pool extension (aka BPE) is an interesting feature of SQL Server 2014. Database administrators already know that memory is one of the key assets available for SQL Server. This is especially true for buffer pool memory, which plays an important role in storing data page and reducing the I/O demand. Nowadays, even if the memory has become cheaper, we are often facing limitations such as mid-size hardware configurations and increasing memory. All this can become difficult and may require a hardware upgrade that can be expensive. In the same time, increasing the disk capacity is no longer a challenge and can be handled more flexibly. Furthermore, solid-state drive technology has become relatively affordable over time. In short, adding disks to a server potentially becomes more cost-effective than adding memory for the mid-size hardware configurations. BPE was designed to address this issue by using the non-volatile memory to extend the buffer pool.
As mentioned by Microsoft the buffer pool extension provides benefits for specific cases:
- Increased random I/O throughput. Indeed, flash-based storage performs well with random IO but sequential IO can be less efficient than using a disk-based storage
- Reduced I/O latency by using a smart L1 and L2 caches with the buffer manager. Pages are moved between the L2 cache (SSD) and L1 cache (memory) by the buffer manager before it has to fetch the page from the disk with generally more latency.
- Only clean pages are written to the BPE. This ensures no data loss.
When I investigated this feature in more detail, I had the opportunity to read the official documentation and blog posts already published by Microsoft and the very interesting article Turbocharging DBMS Buffer Pool Using SSDs written by Do, J., Zhang, D., Patel, J., DeWitt, D., Naughton, J., and A. Halverson. I also listened to one of the interview of Evgeny Krivosheev (SQL Server Program Manager) about the buffer pool extension feature. I would like to precise that there are still blog posts on the web which claim some workloads work better with the buffer pool extension feature. Of course, the quick answer is yes for the reasons described above and this is not my goal here. This post is just an opportunity to share with you some of my investigations – but before, I have to warn you: We are still talking about CTP2 of SQL Server 2014 and some of the tools I used do not work perfectly. We will see this later in the post.
The first thing I noticed is the decision made to store data in SSD at the granularity level of pages rather than tables or files. This point is important because we can retrieve different pages of a table either in the memory, or in the SSD, or in the disk. As mentioned above, only clean pages are written to the buffer pool extension. There is still an exception that consists of writing a modified page (dirty) both into the database mdf file and into the BPE. This is a kind of optimization called dual-write optimization.
Let’s start with my first test in which I used a custom AdventureWorks2012 database with two bigTransactionHistory tables. Here some details about the size and number of rows of each of those tables:
The bigTransactionHistory table contains 31 billion of rows for a size of 2 GB approximately (data and indexes).
![]()
![]()
In my test, the AdventureWorks2012 database is configured as follows:

The mdf and ldf files are stored both on a slow drive (E:) which is a WDC USB disk (5200 RPM) with SATA/300. This is not an optimal configuration but for this test it’s ok.
The buffer pool maximum size on my SQL Server instance is voluntarily fixed to 700 MB.
![]()
Finally, I set up the maximum size of the buffer pool extension to 2 GB:
![]()
The buffer pool extension file is stored on fast solid-state drive (C:) which is a Samsung SSD 840 EVO with a SATA/600
At this point, we can start the first test by loading the entire table bigTransationHistory_2 in the buffer pool with a cold cache. Actually, data pages are stored only on the volatile memory as expected after clearing the buffer cache.
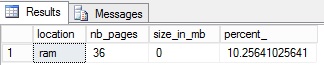
In the same time before the loading, I created an extended event session in order to track the page movement between the non-volatile memory (SSD) and the volatile memory (RAM) for the dynamic pool cache. During my test, I found out that some events are not tracked correctly (for example sqlserver.buffer_pool_extension_pages_read), probably because we are still in CTP2 of SQL Server 2014 …
After loading the bigTransactionHistory_2, there are data pages that exist both in the memory and buffer pool extension. The bigTransactionHistory_2 table doesn’t fit entirely in the allocated non-volatile memory. This is why we retrieve some pages (64% of the total pages) in the buffer pool extension. However, we notice that SQL Server didn’t allocate all the nonvolatile memory for the bigTransactionHistory_2 table before filling up in turn the buffer pool extension. The algorithm is smart enough to leave spaces in the non-volatile memory for future requests. Although the solid-state drive remains fast, non-volatile memory is faster (nanoseconds vs microseconds).

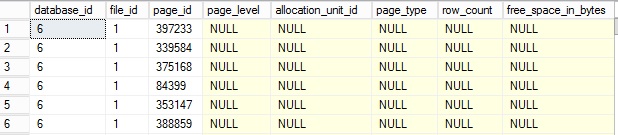
Then, if we take a look at the pages in the buffer pool extension in more details with the same dynamic management view sys.dm_os_buffer_descriptors, we retrieve some page information like page id and file id – but nothing more, maybe because we are still in the CTP version …
Don’t panic! We have others ways to find out what pages belong to the bigTransactionHistory_2 in the buffer pool extension. For example, we can correlate information from the new dynamic management function sys.dm_db_database_page_allocation() that replaces the undocumented but useful command DBCC IND since SQL Server 2012 with the information provided by the dynamic management view sys.dm_os_buffer_descriptors. First, I get the pages allocated to the bigTransactionHistory_2 into a tempdb table. Then we have to clear the buffer pool to avoid loading data pages into the buffer cache and evict others pages that are concerned by our first test.
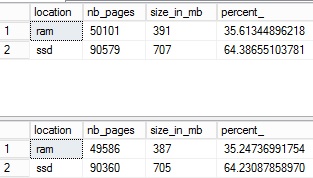
So, we can verify that the majority of data pages in the buffer pool and the buffer pool extension are concerned by the bigTransactionHistory_2. Now let’s take a look at the extended events session ring buffer target:
We can observe that during the load of the bigTransactionHistory_2 table, different data pages have been written into the buffer pool extension (event type = buffer_pool_exentesion_pages_written). Sometimes we have only one page or we have a bunch of pages written in one time.
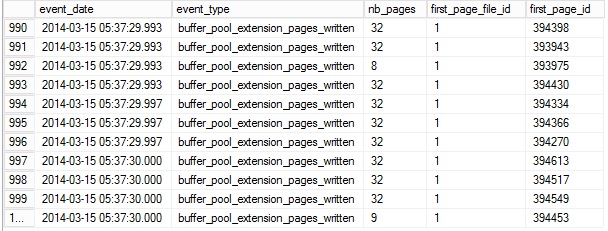
We can also check if the page with the id equal to 394453 in the first file of the database AdventureWorks2012 (file id = 1) belongs to the bigTransactionHistory_2 table :
![]()
After this first test we can push our thinking a little bit further by trying to find out if a second loading of the same table can trigger the reading of data pages from the buffer pool extension. I used the following useful perfmon counters:
- SQL Server:Buffer Manager:Extension page reads/sec
- SQL Server:Buffer Manager:Extension page writes/sec
- SQL Server:Buffer Manager:Page reads/sec
- SQL Server:Buffer Manager:Page writes/sec
- SQL Server:Readahead pages/sec
-> Reading the bigTransactionHistory_2 table with a cold cache:
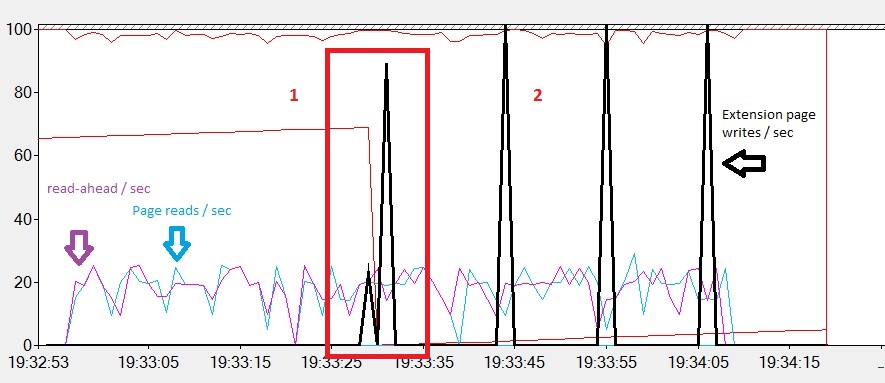
Phase 1: After starting the loading of our table in the buffer pool, we observe that SQL Server fetches a data page from the disk in the buffer cache. SQL Server also uses read-ahead mechanisms by using the index allocation map page of the bigTransactionHistory_2. This is why we notice a constant value of the buffer cache hit ratio (98%) during all the loading table time. At the end of the phase 1, the page life time expectancy counter comes down quickly because the buffer pool (in non-volatile memory) is full.
Phase 2: During this phase, the buffer pool cache extension takes over. Data pages are written into the file on the solid-state disk (Extension page writes / sec).
-> Reading the bigTransactionHistory_2 with a warm cache:
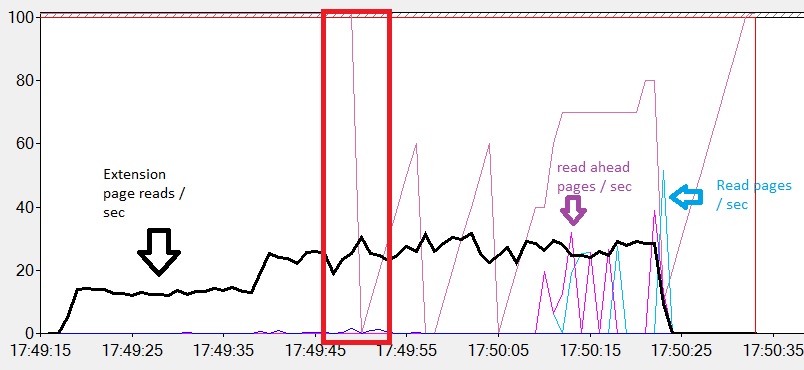
The buffer pool extension is used as expected when we read the bigTransactionHistory_2 table a second time. Data pages are already both in the buffer pool in the non-volatile memory and in the buffer pool extension in the solid-state drive. Furthermore, we have a few reads from the mdf file rather than the first reading of the bigTransactionhistory_2 with a cold cache. However, even if the buffer pool extension is used correctly, I notice that reading the bigTransactionHistory_2 table from a warm cache is longer than reading the same table from a cold cache (respectively 39 seconds versus 1 minute and 4 seconds). It’s a very strange result from my point of view even if we are using sequential IO in the both cases (scanning the bigTransactionHistory_2 table triggers read-ahead mechanism which uses itself sequential IO by design).
I decided to launch the same tests and to take a look at the resource monitor and disk usage from the sqlservr.exe. Here are the results:
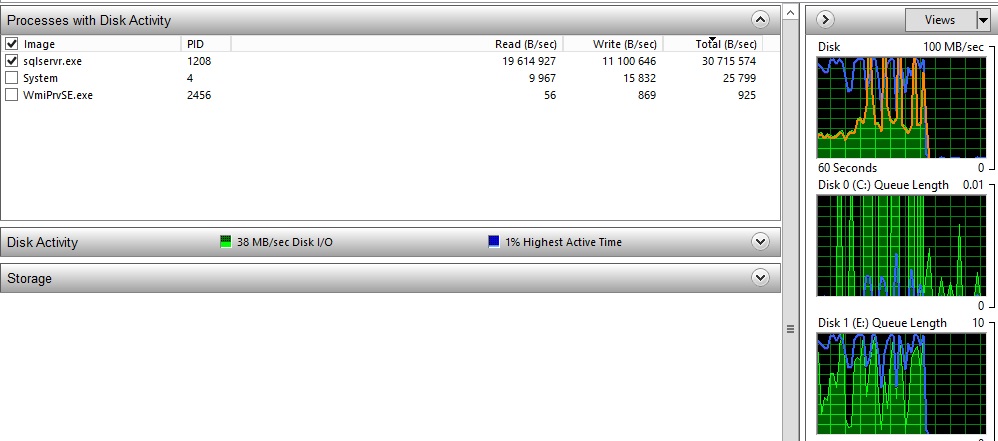
->With a cold cache (disk E: is used by SQL Server) :
The IO write throughput of the disk E is approximately 10 MB/s
->With a warm cache (disk C: is used by SQL Server) : The IO write throughput of the disk C: is approximately 7MB/s
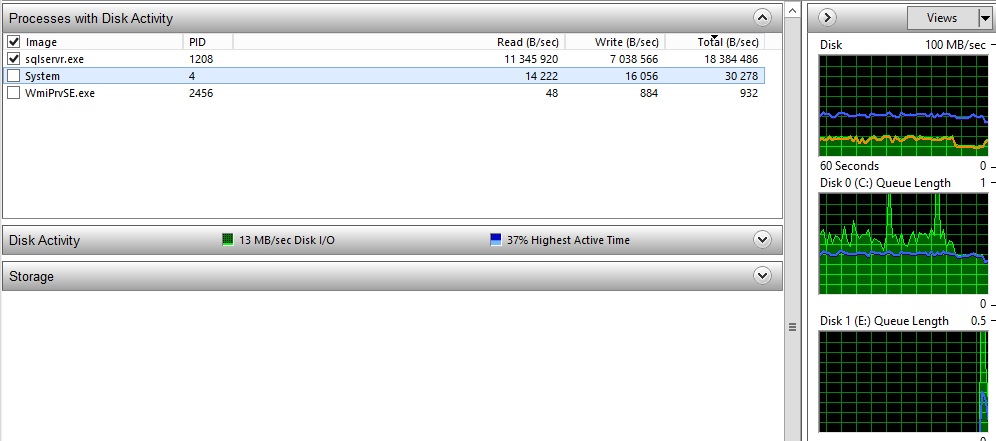
The IO write throughput of the disk C: is approximately 7MB/s. First, according to what we have seen, we can conclude that the duration of the second test with a warm cache is caused by the lower throughput of the solid-state drive C:. However, this throughput is relatively strange and I decided to verify if it’s really the maximum throughput we I can have with my solid state drive disk by using CrystalDiskMark.
-> Disk E: (disk-based storage) : 33 MB / s
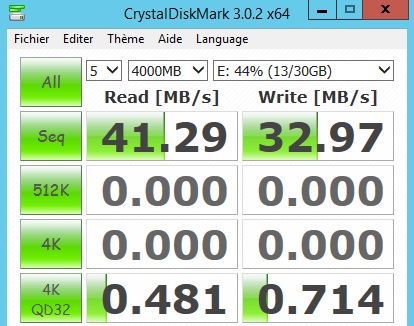
-> Disk C: (flash-based storage) : 308 MB / s
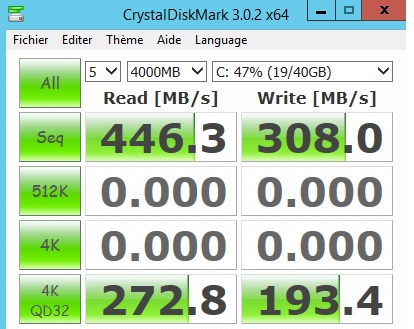
You can see that we are far from reaching the maximum throughput of the solid-state drive. A mystery to be solved with Microsoft … Finally, I decided to launch a last test by using both tables bigTransactionHistory and the bigTransactionHistory_2 this time. The total size of the two tables is bigger than the total size of the buffer pool and its extension (3 GB versus 2.7 GB approximately).
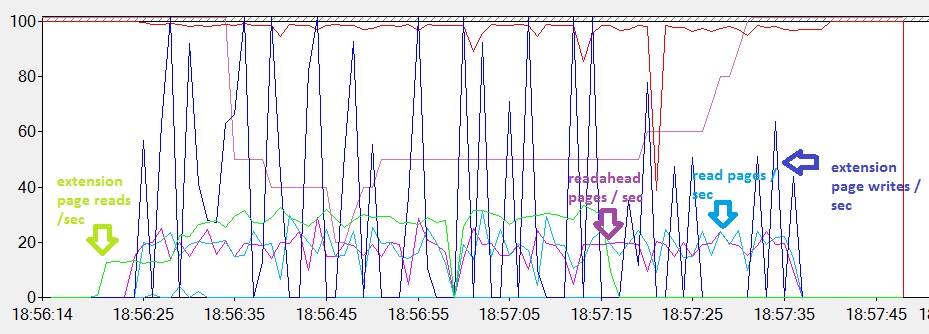
The buffer pool extension is also used as a warm cache (extension page reads / sec) in this case. However, the data pages are also written to the buffer pool extension (extension page written / sec) at the same time, because all data pages cannot be stored entirely in the buffer pool and the buffer pool extension. We can see that the data pages continue to be read from the mdf file during the test (readahead pages / sec and read pages / sec). According to the paper Turbocharging DBMS Buffer Pool Using SSDs, I guess SQL Server uses the LRU-2 algorithm to evict pages during the reading of both tables. If we take a closer look at the result of the extended event target, we can see a new event triggered during the test: buffer_pool_eviction_thresholds_recalculated.

When the buffer pool extension begins to fill itself up, SQL Server decides which pages will be evicted by dynamically calculating two thresholds. Those thresholds determine the movement of the data pages between the buffer pool (non-volatile memory), the buffer pool extension (solid-state drive) and the database data file (disk-based storage). As you can imagine, the location of a data page depends on its “temperature”. During my test, I noticed that the buffer_pool_eviction_thresholds_recalculated event does not provide all sets of action values like number_evictions_to_bpool_extension or page_not_on_LRU that could be very useful for troubleshooting or to understand how eviction occurs. Again, I guess maybe this is due to the CTP2 of SQL Server … Please feel free to share your experience about testing buffer pool extension!
By David Barbarin
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/microsoft-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/FRJ_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/01/HME_web.jpg)