Would you like to quickly provide your engineering team with a real production environment database with updated data to develop new features? Does your operational team need a copy of the production database to test a new release or a new patch? “Easy” would you say. “Let’s do a clone and duplicate the production database with RMAN!”. Yes, but would you take the same direction if your production database size makes more than a few Terra Bytes? In this article, we will see what interesting added value offers the snapshot technology and compare the solutions available for Oracle Standard Edition SE2 : PDB snapshot, dbvisit snapshot and ACFS snapshot.
What is a snapshot?
A snapshot refers to a system’s state at a specific point in time. To do so, the snapshot will need to store the previous version of a modified block. The snapshot has a list of pointers and knows the location of each block.
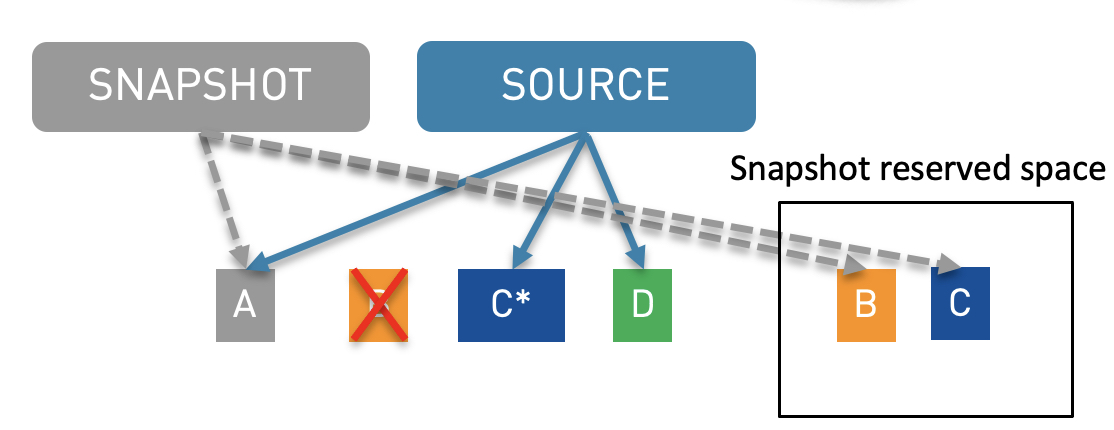
There are 2 well-known snapshot methods. The copy-on-write (CoW) method, mostly used, will copy the blocks that are modified. So only modified blocks will require additional storage on the disk. In the example (see following screenshot), a snapshot is created on the source file system having initially at snapshot creation A, B and C blocks. When the B block is deleted by the source, the B block will be copied in the snapshot reserved space in order to make the information still available for the snapshot. The B source block will be deleted. The same process will happen when the source will give an update on the C block. The old version will be copied in the snapshot reserved area. For new information created by the source, refer the D block, only the source will have access to it. For each modified block there will be 3 I/O : 1 read I/O and 2 writes I/O.
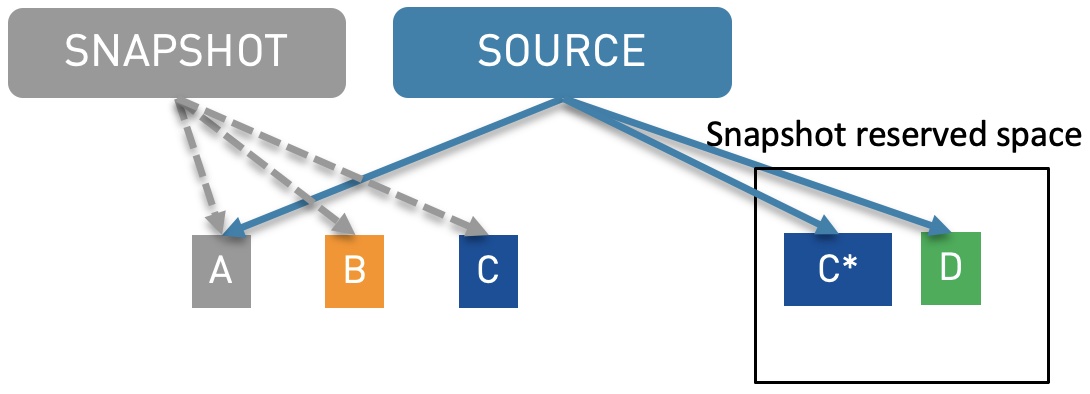
Another method called redirect-on-write (RoW) is also using pointers. The difference resides in the fact that for each block modification the new information is not updated in the current block but will be written in a new block and the pointer will be updated. So in case of write done by the source in the parent block, only 1 write I/O is needed. This might give an advantage to the previous CoW method. But several drawbacks will make this method more complex. The deletion of the snapshot implies the data from the snapshot storage to be reconciled back into the source volume adding some additional fragmentation problem. Also, the method will be more complicated to be handled if having several snapshots on the source data. This is described in the next example screenshot where the B block is deleted by the source but kept available for the snapshot and all updated information or new information on the parent block will be inserted in the new blocks made available to the source only.
What is a snapshot database for?
A snapshot database will be a point-in-time copy of a database. A snapshot database can be used in READ/ONLY mode and used to run any reporting application or other query execution, unloading the master production database. The snapshot database can also be opened in READ/WRITE mode. This will give the opportunity to test any new application version or patch, database upgrade or patching and providing a real copy of the database to the engineering team to create further developing. This will be possible without any impact and changes made on the production database. Finally, the snapshot could also be used to easily restore data on the source.
The snapshot database is instantaneously created and, knowing only the modified blocks are copied, will not take large amount of disk space. These two advantages, short time creation and few space requirement, make snapshot database a powerful tool. Snapshot databases are not intended to live forever. More modification on the source master database and/or on the snapshot will be done, more disk space will be required.
PDB snapshot
Multitenant architecture provides possibilities in the Enterprise Edition but also in the Standard Edition. We will be able to create and use PDB snapshots on Standard Edition SE2 in the limit of maximum 3 PDBs for Oracle 19c, including master PDB, cloned PDB and snapshot PDB. There are mainly two instance parameters we need to pay attention to.
The first one is the clonedb parameter. In case the database is deployed on a storage with specialized storage-based snapshot technology as SunZFS, NetApp or ACFS, the parameter needs to be set to false. The master PDB stays opened READ/WRITE. In case the database is deployed on simple and standard file systems, which might be most of the case, the clonedb parameter should be set with the true value. The source file system still needs to support sparseness. This would be the case for ext4 or xfs file system, but not the case for ext3 or ASM. The sparse file will contain all the changes made to the blocks when data are written to the snapshot database and will maintain a pointer to the parent file for accessing the unchanged data. Unfortunately, in this case, the source master PDB can only be opened READ/ONLY. Leaving the PDB1 opened read write for a multitenant database using a LVM xfs file system as database storage (clonedb=true) will result in an ORA-65081 error :
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ----------------------------- ---------- ----------
2 PDB$SEED READ ONLY NO
3 PDB1 READ WRITE NO
4 PDB2 READ WRITE NO
SQL> create pluggable database PDB1snap1 from PDB1 snapshot copy;
create pluggable database PDB1snap1 from PDB1 snapshot copy
*
ERROR at line 1:
ORA-65081: database or pluggable database is not open in read only mode
The other important parameter for PDB snapshot is the instance parameter clonedb_dir. This parameter came with Oracle R12.2 and will mention the directory where the bitmap file should be saved. By default, the bitmap file will be stored in $ORACLE_HOME/dbs. This bitmap file, also often called snapshot metadata file, will record the block pointers list.
Starting PDB1 in read only mode will make possible the creation of a PDB1snap1:
SQL> show parameter clone
NAME TYPE VALUE
------------------- ----------- ------------------------------
clonedb boolean TRUE
clonedb_dir string /u92/app/oracle/oradata/snap
SQL> alter pluggable database PDB1 close immediate;
Pluggable database altered.
SQL> alter pluggable database PDB1 open read only;
Pluggable database altered.
SQL> create pluggable database PDB1snap1 from PDB1 snapshot copy;
Pluggable database created.
SQL> alter pluggable database PDB1snap1 open;
Pluggable database altered.
SQL> select con_id, name, open_mode, total_size/1024/1024/1024 GB from v$pdbs;
CON_ID NAME OPEN_MODE GB
---------- ---------- ---------- ----------
2 PDB$SEED READ ONLY 1.00292969
3 PDB1 READ ONLY 1.05664063
4 PDB2 READ WRITE 1.05664063
5 PDB1SNAP1 READ WRITE 1.05664063
A bitmap file will be created :
SQL> ! ls -ltrh /u92/app/oracle/oradata/snap total 8.0K -rw-r-----. 1 oracle oinstall 2.1M Jul 12 09:03 CDB19CSE_3197379858_bitmap.dbf
We can see that the PDB source PDB1 have a size of 1.1 GB :
SQL> select 'du -ha /u02/app/oracle/oradata/cdb19cse/CDB19CSE_SITE1/' || GUID || '/datafile/' from dba_pdbs where pdb_name='PDB1'; du -ha /u02/app/oracle/oradata/cdb19cse/CDB19CSE_SITE1/BD987DE079D833A4E0537816A8C0DF5D/datafile/ SQL> !du -h /u02/app/oracle/oradata/cdb19cse/CDB19CSE_SITE1/BD987DE079D833A4E0537816A8C0DF5D/datafile/ 1.1G /u02/app/oracle/oradata/cdb19cse/CDB19CSE_SITE1/BD987DE079D833A4E0537816A8C0DF5D/datafile/
And the snapshot PDB, PDB1snap1, will take only 2.2 MB on the disk having a parse file for each parent file :
SQL> select 'du -ha /u02/app/oracle/oradata/cdb19cse/CDB19CSE_SITE1/' || GUID || '/datafile/' from dba_pdbs where pdb_name='PDB1SNAP1'; du -ha /u02/app/oracle/oradata/cdb19cse/CDB19CSE_SITE1/C6E8AD2215380DB2E0537816A8C04875/datafile/ SQL> !du -h /u02/app/oracle/oradata/cdb19cse/CDB19CSE_SITE1/C6E8AD2215380DB2E0537816A8C04875/datafile/ 2.2M /u02/app/oracle/oradata/cdb19cse/CDB19CSE_SITE1/C6E8AD2215380DB2E0537816A8C04875/datafile/ SQL> !du -ha /u02/app/oracle/oradata/cdb19cse/CDB19CSE_SITE1/C6E8AD2215380DB2E0537816A8C04875/datafile/ 16K /u02/app/oracle/oradata/cdb19cse/CDB19CSE_SITE1/C6E8AD2215380DB2E0537816A8C04875/datafile/o1_mf_users_jgqt9zf0_.dbf 676K /u02/app/oracle/oradata/cdb19cse/CDB19CSE_SITE1/C6E8AD2215380DB2E0537816A8C04875/datafile/o1_mf_undotbs1_jgqt9zf0_.dbf 1.3M /u02/app/oracle/oradata/cdb19cse/CDB19CSE_SITE1/C6E8AD2215380DB2E0537816A8C04875/datafile/o1_mf_system_jgqt9zdm_.dbf 220K /u02/app/oracle/oradata/cdb19cse/CDB19CSE_SITE1/C6E8AD2215380DB2E0537816A8C04875/datafile/o1_mf_sysaux_jgqt9zdz_.dbf 56K /u02/app/oracle/oradata/cdb19cse/CDB19CSE_SITE1/C6E8AD2215380DB2E0537816A8C04875/datafile/o1_mf_temp_jgqt9zf0_.dbf 2.2M /u02/app/oracle/oradata/cdb19cse/CDB19CSE_SITE1/C6E8AD2215380DB2E0537816A8C04875/datafile/
Creating the PDB snapshot took 1 second in the lab for a source PDB of 1 GB. This confirms one of the real advantages of using snapshot. We can then, of course, drop the PDB snapshot :
SQL> alter pluggable database PDB1snap1 close; Pluggable database altered. SQL> drop pluggable database PDB1snap1 including datafiles; Pluggable database dropped.
And we would need to follow Oracle Doc ID 2419236.1 (Unable to Open the ‘Source PDB’ in ‘READ WRITE’ Mode After Dropping its ‘Snapshot Copy PDB’. It fails with ORA-01114, ORA-01110 and ORA-27091) to reopen the source PDB, PDB1, in READ/WRITE mode. In case we would use a disaster recover solution as dbvisit, the PDB snapshot created on the primary database will induced a normal clone PDB to be created on the standby side.
We can then easily understand the pros and cons of using PDB snapshot :

dbvisit snapshot
dbvisit standby is a well-known disaster recovery solution for Oracle Standard Edition. The system is composed of a primary and at least one standby database. The changes are applied from the primary on the standby databases through the archived logs, offering possibilities for manual switchover (in case of planned maintenance operation) or failover (in case of disaster). The standby database is started in MOUNT mode and available for recovery only. We could start the standby database in READ/ONLY mode, be able to execute reporting query, but no new changes from the primary can be applied to it during that time. Here is where the new dbvisit snapshot feature, dbvisit snapshot, is going to provide much advantages. The dbvisit snapshot will be a copy of the standby database at a particular point in time, using CoW technology and based on LVM snapshots. The snapshot database can be opened READ/ONLY or READ/WRITE, and offers any reporting or application development possibility. Snapshot database can also be used to test a real failover without impacting the solution: testing a failover implies to back up the standby database first or to create it after wise (reinstate is not possible on a Standard Edition as flashback option is not available). This feature came with version dbvisit 9 as an additional option to pay and is now fully included in dbvisit 10 version. In case the standby database does not meet the requirement to create dbvisit snapshot or in order to offload the standby database, it is possible to use a cascaded standby database. The snapshot can be created from the console (GUI) or from command line (CLI), albeit dbvisit recommendation is to emphasize the console.
There are a few requirements using snapshot with dbvisit:
- Only linux is currently supported
- Database files needs to be located on a single LVM file system
- The server needs to have enough RAM to support the snapshot SGA
- Sudo needs to be configured for oracle user to have permissions to run root commands (lvcreate, lvremove, lvs and vgs)
- Enough space in DBVISIT_BASE home directory is needed to record the snapshot metadata
dbvisit offers 2 snapshot options: reporting replicas and test/dev snapshots. With reporting replicas feature, the user feels having a logical database been regularly updated. New READ/ONLY or READ/WRITE snapshots will be automatically created, providing frequent up to date copies of the primary database. We can configure a logical container with minimum 2 and maximal 4 snapshots. This solution will be mainly used for reporting.
In our example with a container of 2 snapshots, the standby database is updated every 10 minutes with the primary database :
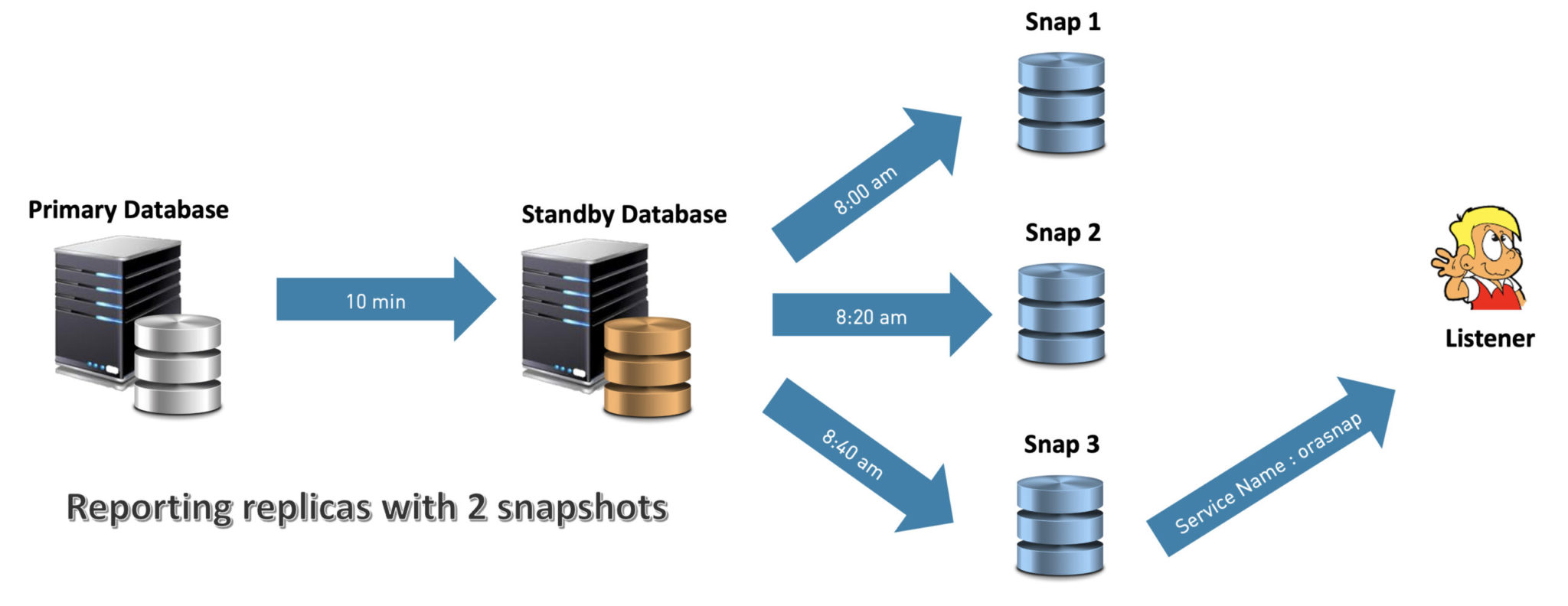
A new snapshot is created every 20 minutes on the standby database providing the latest transactions to the user. The newly created snapshot will be registered on the listener with a designed service name, in our example orasnap. All new connections using orasnap service name will go through the most recent snapshot. As we are using a container of 2 snapshots, the snap1 will be deleted as soon as the third snapshot will be created and made available. We will keep the 2 last more recent snapshots. The running connection using snap1 will be killed, giving here, 40 minutes for the query to run.
Following screenshot gives a real example, with a creation interval of 11 minutes and an Oracle Service Name orasnap. Pay attention of the output Total Current Snapshots. It will show a total from 3 of 2 because we are using a container of 2 snapshots and snap001 is in the process to be created.
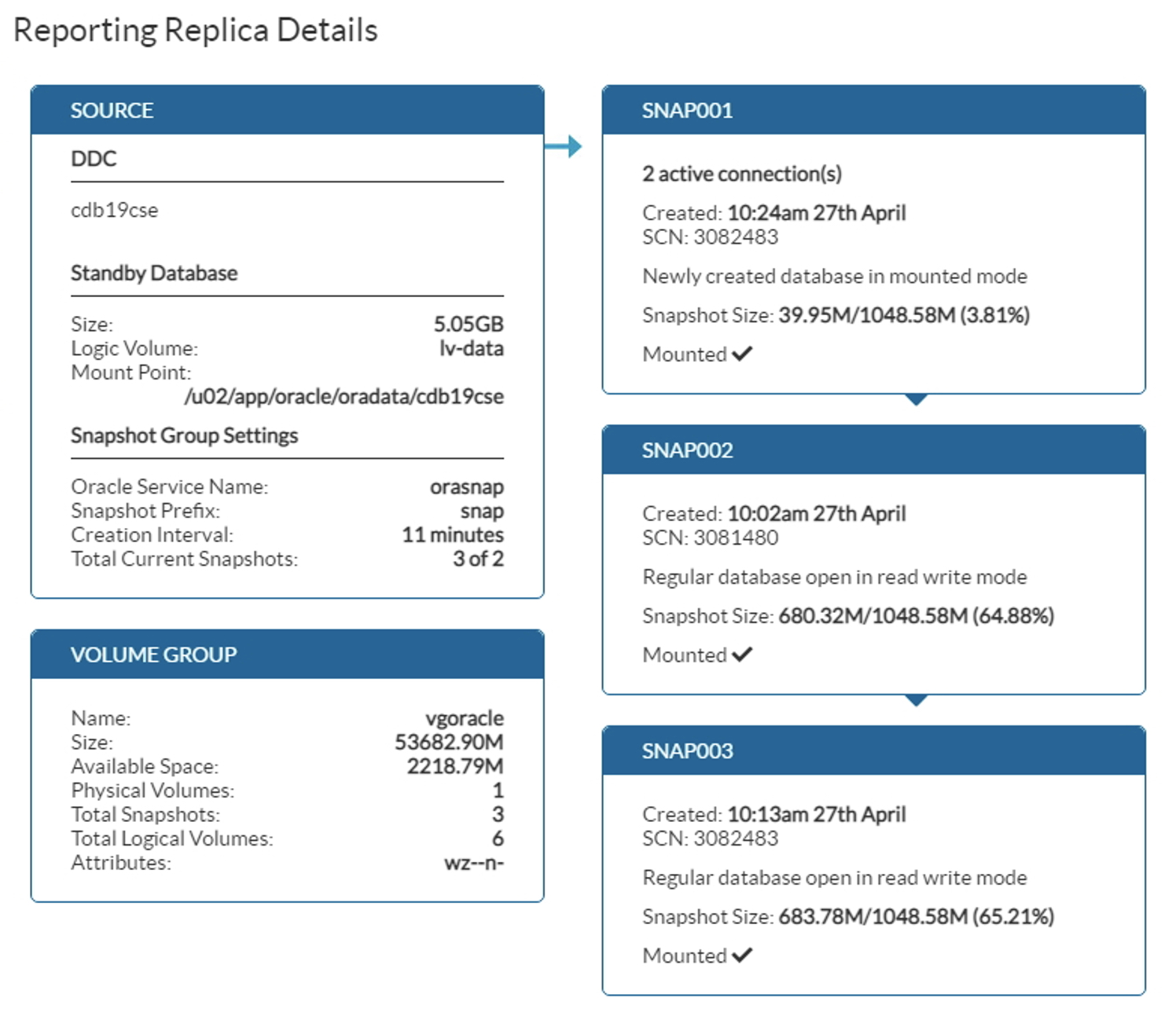
Once it is done, snap002 will be removed. There will be then 2 snapshots left available :
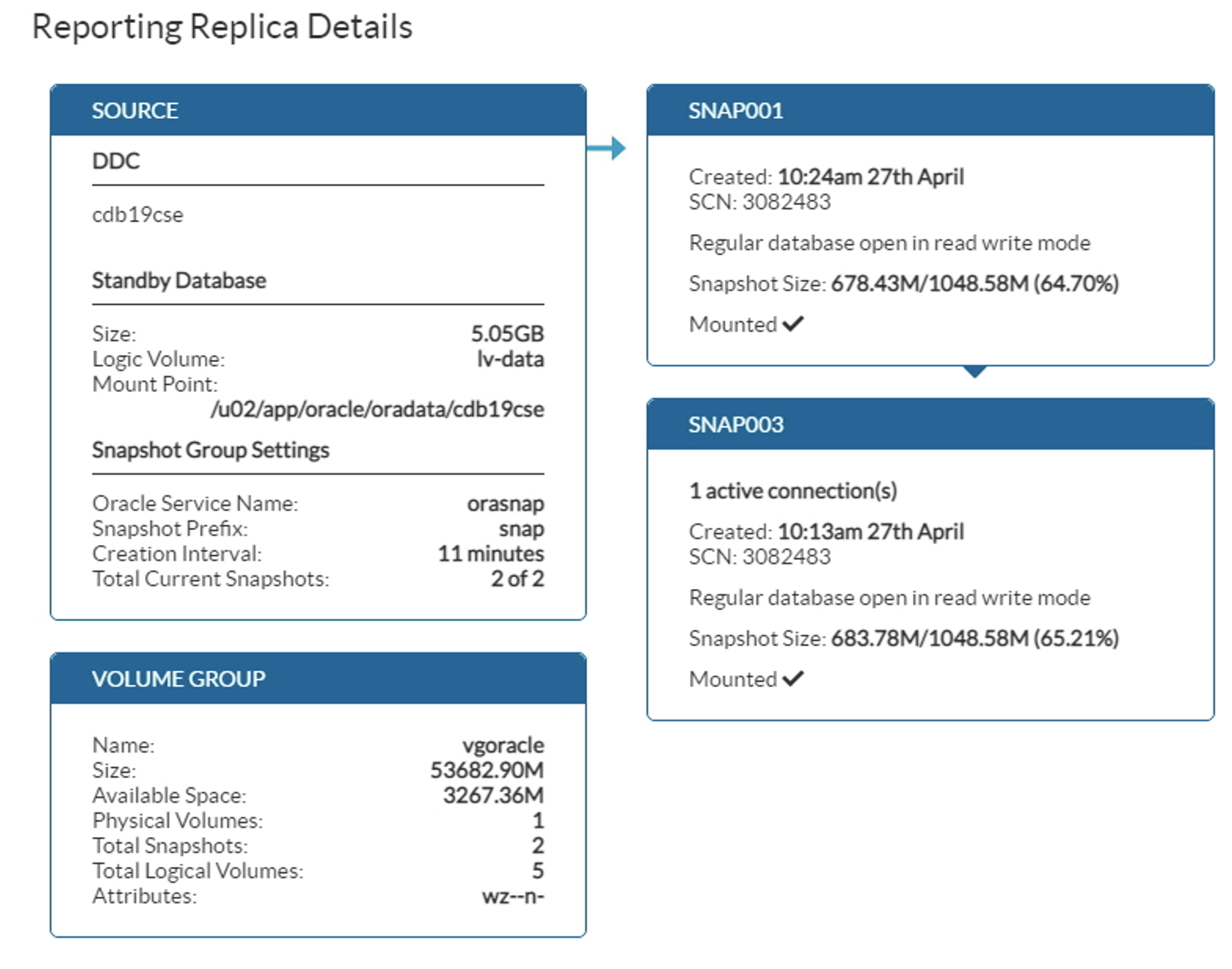
It is important to know that during the time the snapshot database is created, the standby database needs be opened in READ/ONLY mode, making no apply from the primary possible during that time. The other option available is to create manual snapshots. The creation of snap002 manual snapshots on cdb19cse_SITE2 standby database has taken no more than 2 minutes and 16 seconds on the same lab :
oracle@dbv2:/home/oracle/ [snap002 (CDB$ROOT)] cdb19cse
********* dbi services Ltd. *********
STATUS : MOUNTED
DB_UNIQUE_NAME : cdb19cse_SITE2
OPEN_MODE : MOUNTED
LOG_MODE : ARCHIVELOG
DATABASE_ROLE : PHYSICAL STANDBY
FLASHBACK_ON : NO
FORCE_LOGGING : YES
VERSION : 19.10.0.0.0
CDB Enabled : YES
List PDB(s) MOUNTED : PDB$SEED, PDB1, PDB2
*************************************
oracle@dbv2:/home/oracle/ [cdb19cse (CDB$ROOT)] snap002
********* dbi services Ltd. *********
STATUS : STOPPED
*************************************
oracle@dbv2:/home/oracle/ [snap002 (CDB$ROOT)] cat /u01/app/dbvisit/standby/conf/cdb19cse_snap002.json
{
"pfile" : {
"sga_target" : "650M"
},
"permission" : "w",
"ssize" : "1552M",
"retry_sec" : 60,
"activate" : "Y"
}
oracle@dbv2:/home/oracle/ [snap002 (CDB$ROOT)] /u01/app/dbvisit/standby/dbvsnap -d cdb19cse -csnap -sname snap002 -j cdb19cse_snap002.json
=============================================================
Dbvisit Standby Database Technology (10.0.0_1_g9b8b5f20) (pid 21359)
Dbvisit Snapshot (pid 21359)
DBVSNAP started on dbv2: Mon Jul 12 13:54:27 2021
=============================================================
Snapshot snap002 created
=============================================================
DBVSNAP ended on dbv2: Mon Jul 12 13:55:20 2021
=============================================================
oracle@dbv2:/home/oracle/ [snap002 (CDB$ROOT)] snap002
********* dbi services Ltd. *********
STATUS : OPEN
DB_UNIQUE_NAME : snap002
OPEN_MODE : READ WRITE
LOG_MODE : ARCHIVELOG
DATABASE_ROLE : PRIMARY
FLASHBACK_ON : NO
FORCE_LOGGING : NO
VERSION : 19.10.0.0.0
CDB Enabled : YES
List PDB(s) READ ONLY : PDB$SEED
List PDB(s) READ WRITE : PDB1, PDB2
*************************************
There are a few pros and cons using dbvisit snapshot as solution :

Using PDB snapshot with dbvisit snapshot
The idea would be to overlap both dbvisit snapshot solution with PDB snapshot. For situation where the master PDB needs to be started in READ/ONLY Mode, and to avoid cloning the master PDB (when the environment is on production, master PDB needs to be started in READ/WRITE mode), we could consider using a dbvisit snapshot as master READ/ONLY. This will have the main advantage not to impact the primary production database and also use few storage on disk. All PDBs from cdb19cse_SITE1 can stay opened READ/WRITE and we will use the PDB1 from the recent created snapshot, SNAP002, as master READ/ONLY in order to create a PDB snapshot.
oracle@dbv2:/home/oracle/ [snap002 (CDB$ROOT)] sqh
SQL> alter pluggable database PDB1 close immediate;
Pluggable database altered.
SQL> alter pluggable database PDB1 open read only;
Pluggable database altered.
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ----------------------------- ---------- ----------
2 PDB$SEED READ ONLY NO
3 PDB1 READ ONLY NO
4 PDB2 READ WRITE NO
SQL> create pluggable database PDB1snap1 from PDB1 snapshot copy;
Pluggable database created.
SQL> alter pluggable database PDB1snap1 open;
Pluggable database altered.
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ----------------------------- ---------- ----------
2 PDB$SEED READ ONLY NO
3 PDB1 READ ONLY NO
4 PDB2 READ WRITE NO
5 PDB1SNAP1 READ WRITE NO
If we compare the various sizing, we can see that dbvisit snapshot is only taking a few Mbytes, 1 MB :
oracle@dbv2:/home/oracle/ [snap002 (CDB$ROOT)] du -sh /u01/app/dbvisit/standby/snap/cdb19cse/snap002/SNAP002/BD987DE079D833A4E0537816A8C0DF5D/datafile/ 1.0M /u01/app/dbvisit/standby/snap/cdb19cse/snap002/SNAP002/BD987DE079D833A4E0537816A8C0DF5D/datafile/
On its side, the PDB snapshot will only take a few Kbytes, 164 KB :
oracle@dbv2:/home/oracle/ [snap002 (CDB$ROOT)] du -sh /u01/app/dbvisit/standby/snap/cdb19cse/snap002/SNAP002/C6ED67109F386285E0537916A8C0D80C/datafile/ 164K /u01/app/dbvisit/standby/snap/cdb19cse/snap002/SNAP002/C6ED67109F386285E0537916A8C0D80C/datafile/
When the PDB master size is 1.1 GB :
oracle@dbv2:/home/oracle/ [snap002 (CDB$ROOT)] du -sh /u01/app/dbvisit/standby/snap/cdb19cse/snap002/CDB19CSE_SITE2/BD987DE079D833A4E0537816A8C0DF5D/datafile/ 1.1G /u01/app/dbvisit/standby/snap/cdb19cse/snap002/CDB19CSE_SITE2/BD987DE079D833A4E0537816A8C0DF5D/datafile/
The pros and cons of using this overlapping solution is :

ACFS snapshot
With standard edition we can also use snapshot on ACFS File System available with Oracle Restart systems. These are online, READ/ONLY or READ/WRITE point in time copy of Oracle ACFS File System. This solution is using CoW technology. The snapshots are written in the .ACFS/snaps/ directory.
The command to create, query and delete ACFS snapshot are quite user friendly :
acfsutil snap create –r –w –p acfsutil snap info –t acfsutil snap delete
On the other side creating a snapshot database with ACFS might be a more complex process implying to generate the spfile and the control file, to adapt them, to create the ACFS snapshot after putting the master database in begin backup, to recover the database with last archived logs before finally registering the new snapshot database in the grid infrastructure. The pros and cons of using ACFS snapshot is :

![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/MAW_web-min-scaled.jpg)