By Mouhamadou Diaw
A few time ago my colleague Daniel did a blog about POWA. In a nice article he shown how this tool can be used to monitor our PostgreSQL.
In this present article I am going to show how this powerful tool can help by suggesting indexes which can optimize our queries.
I am using postgeSQL 9.6
[root@pgservertools extension]# yum install postgresql96-server.x86_64
[root@pgservertools extension]# yum install postgresql96-contrib.x86_64
And Then I initialize a cluster
[root@pgservertools extension]# /usr/pgsql-9.6/bin/postgresql96-setup initdb
Initializing database ... OK
POWA require following extensions:
pg_qualstats: gathers statistics on predicates found in WHERE statements and JOIN clauses
pg_stat_kcache : gathers statistics about real reads and writes done by the filesystem layer
hypopg : extension adding hypothetical indexes in PostgreSQL. This extension can be used to see if PostgreSQL will use the index or no
btree_gist : provides GiST index operator classes that implement B-tree equivalent behavior for various data types
powa_web : will provide access to powa via a navigator
Just we will note that following packages are installed to resolve some dependencies during the installation of these extensions.
yum install python-backports-ssl_match_hostname.noarch
rpm -ivh python-tornado-2.2.1-8.el7.noarch.rpm
rpm -ivh python-tornado-2.2.1-8.el7.noarch.rpm
And then extensions are installed using yum
yum install powa_96.x86_64 pg_qualstats96.x86_64 pg_stat_kcache96.x86_64 hypopg_96.x86_64 powa_96-web.x86_64
After the installation the postgresql.conf is modified to load the extensions
[root@pgservertools data]# grep shared_preload_libraries postgresql.conf | grep -v ^#
shared_preload_libraries = 'pg_stat_statements,powa,pg_stat_kcache,pg_qualstats' # (change requires restart)
[root@pgservertools data]#
And then restart the PostgreSQL
[root@pgservertools data]# systemctl restart postgresql-9.6.service
For POWA configuration, the first step is to create a user for powa
postgres=# CREATE ROLE powa SUPERUSER LOGIN PASSWORD 'root';
CREATE ROLE
and the repository database we will use.
postgres=# create database powa;
CREATE DATABASE
The extensions must be created in the repository database and in all databases we want to monitor
postgres=#\c powa
powa=# CREATE EXTENSION pg_stat_statements;
CREATE EXTENSION
powa=# CREATE EXTENSION btree_gist;
CREATE EXTENSION
powa=# CREATE EXTENSION powa;
CREATE EXTENSION
powa=# CREATE EXTENSION pg_qualstats;
CREATE EXTENSION
powa=# CREATE EXTENSION pg_stat_kcache;
CREATE EXTENSION
powa=# CREATE EXTENSION hypopg;
CREATE EXTENSION
We can verify that extensions are loaded in the database using
powa=# \dx
List of installed extensions
Name | Version | Schema | Description
--------------------+---------+------------+-----------------------------------------------------------
btree_gist | 1.2 | public | support for indexing common datatypes in GiST
hypopg | 1.1.0 | public | Hypothetical indexes for PostgreSQL
pg_qualstats | 1.0.2 | public | An extension collecting statistics about quals
pg_stat_kcache | 2.0.3 | public | Kernel statistics gathering
pg_stat_statements | 1.4 | public | track execution statistics of all SQL statements executed
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
powa | 3.1.1 | public | PostgreSQL Workload Analyser-core
(7 rows)
powa=#
Now let’s create a database named mydb for our tests and let’s create all extensions inside the database.
[postgres@pgservertools ~]$ psql
psql (9.6.5)
Type "help" for help.
postgres=# create database mydb;
CREATE DATABASE
postgres=#
Let’s again verify extensions into the database mydb
mydb=# \dx
List of installed extensions
Name | Version | Schema | Description
--------------------+---------+------------+-----------------------------------------------------------
btree_gist | 1.2 | public | support for indexing common datatypes in GiST
hypopg | 1.1.0 | public | Hypothetical indexes for PostgreSQL
pg_qualstats | 1.0.2 | public | An extension collecting statistics about quals
pg_stat_kcache | 2.0.3 | public | Kernel statistics gathering
pg_stat_statements | 1.4 | public | track execution statistics of all SQL statements executed
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
powa | 3.1.1 | public | PostgreSQL Workload Analyser-core
(7 rows)
mydb=#
In mydb database we create a table mytab and insert in it some rows
mydb=# \d mytab
Table "public.mytab"
Column | Type | Modifiers
--------+---------+-----------
id | integer |
val | text |
.
mydb=# select count(*) from mytab;
count
-----------
100000000
(1 row)
The last step is to configure the powa-web configuration file. Below is our file
[root@pgservertools etc]# pwd
/etc
[root@pgservertools etc]# cat powa-web.conf
servers={
'main': {
'host': 'localhost',
'port': '5432',
'database': 'powa',
'query': {'client_encoding': 'utf8'}
}
}
cookie_secret="secret"
[root@pgservertools etc]#
And then powa-beb can be started by following command
[root@pgservertools etc]# powa-web &
[1] 5600
[root@pgservertools etc]# [I 171006 13:54:42 powa-web:12] Starting powa-web on http://0.0.0.0:8888
We can now log with the user powa we created at http://localhost:8888/
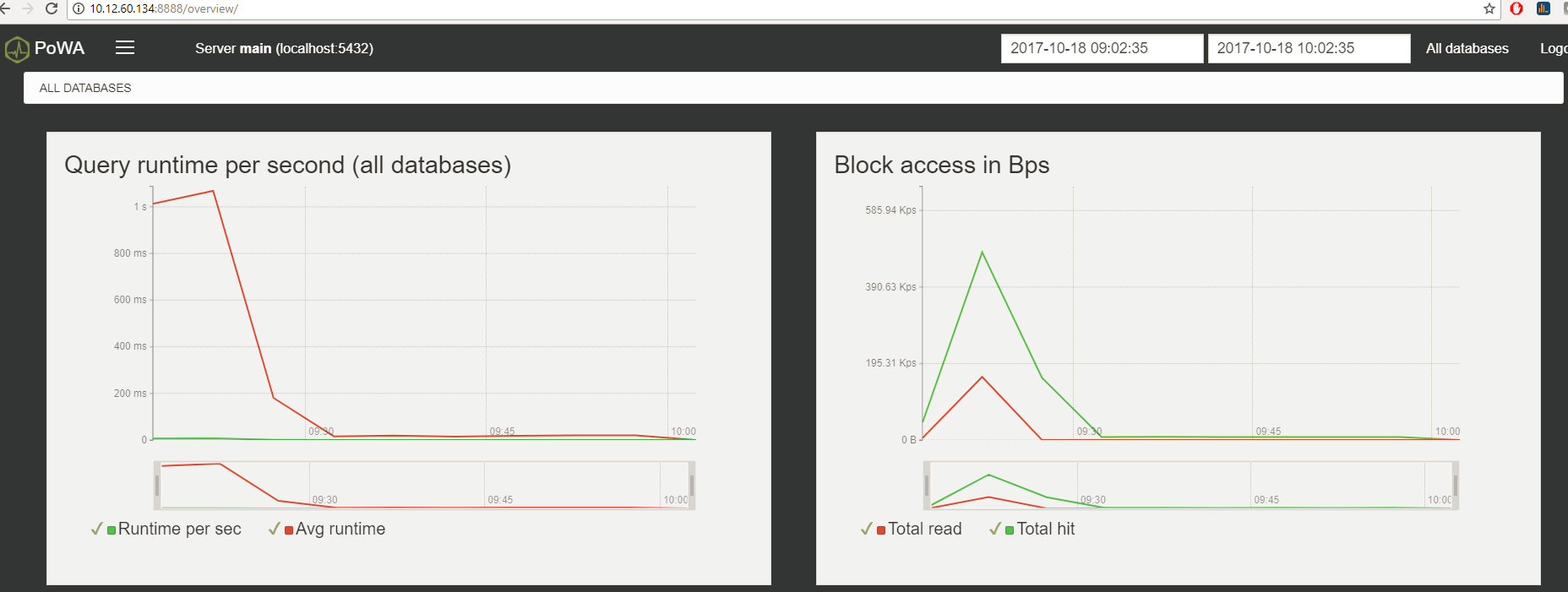
And then we can choose mydb database to monitor it
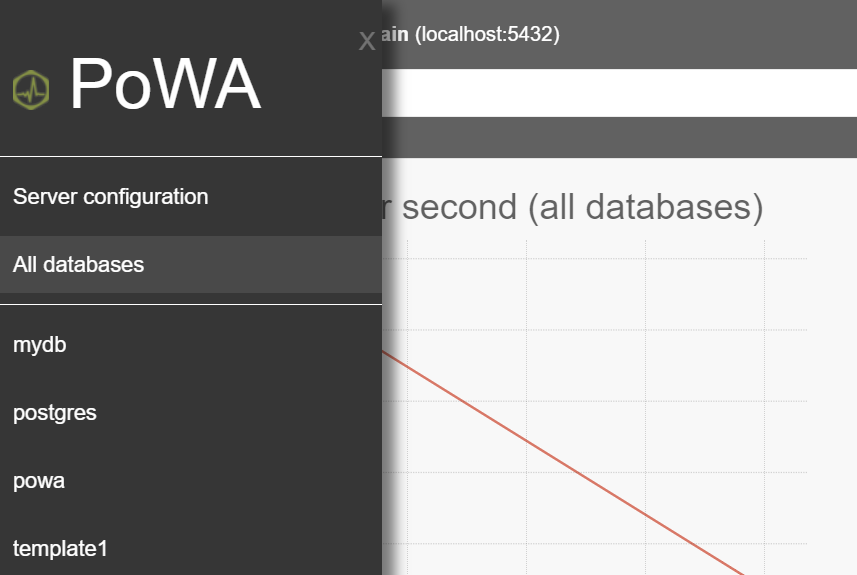
Now let’s run some queries. As my load is very low I set my pg_qualstats.sample_rate=1 in the postgresql.conf file (thanks to Julien Rouhaud)
[postgres@pgservertools data]$ grep pg_qualstats.sample_rate postgresql.conf
pg_qualstats.sample_rate = 1
mydb=# select * from mytab where id in (75,25,2014,589);
id | val
------+-----------
25 | line 25
75 | line 75
589 | line 589
2014 | line 2014
(4 rows)
Time: 9472.525 ms
mydb=#
Using the tab Index suggestions, we click on Optimize the database. We can see that an index creation is recommended with the potential gain.
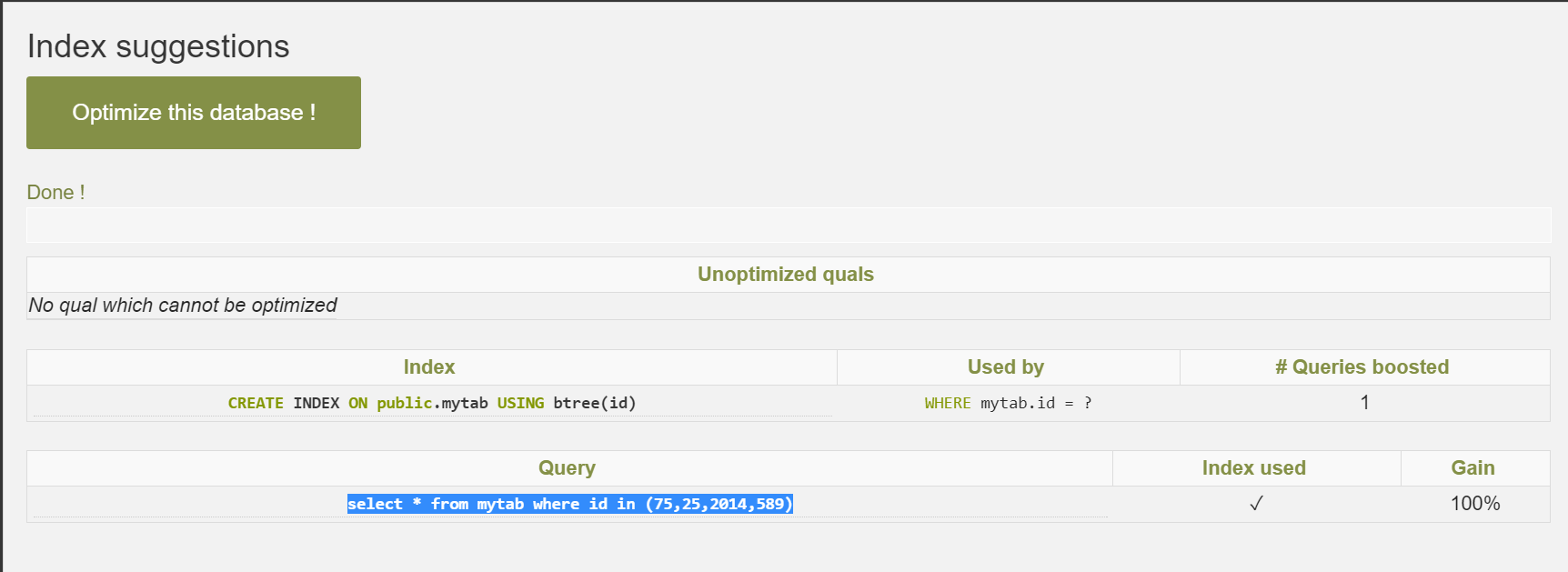
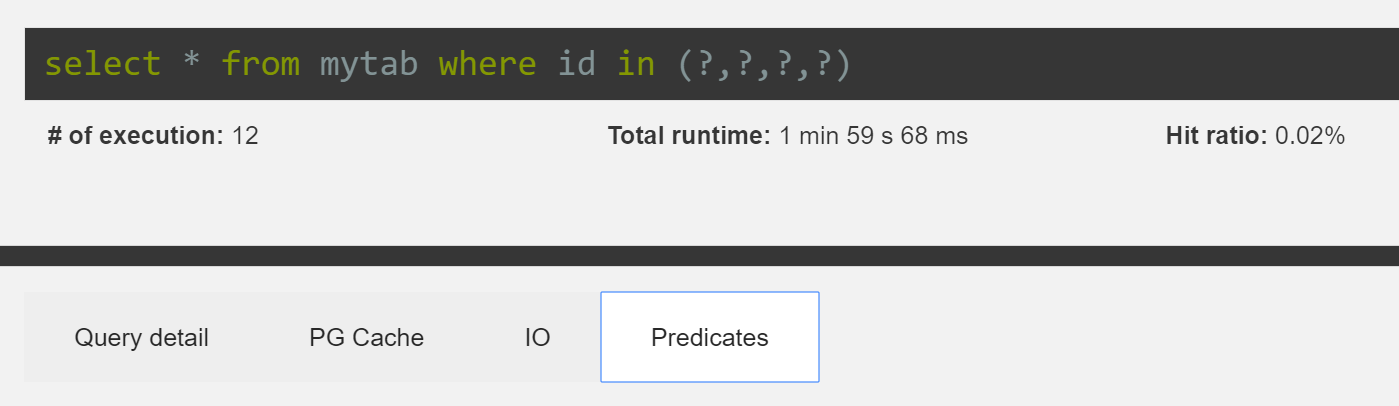

We will just note that PostgreSQL uses the extension hypopg to see if the index will be used or no. Let’s see how this extension works. Hypothetical indexes are useful to know if specific indexes can increase performance of a query. They do not cost CPU as they don’t exist.
Let’s create a virtual index in mydb database
mydb=# select * from hypopg_create_index('create index on mytab (id)');
indexrelid | indexname
------------+-----------------------
55799 | btree_mytab_id
(1 row)
mydb=#
We can verify the existence of the virtual index by
mydb=# SELECT * FROM hypopg_list_indexes();
indexrelid | indexname | nspname | relname | amname
------------+-----------------------+---------+---------+--------
55799 | btree_mytab_id | public | mytab | btree
(1 row)
Using explain, we can see that PostgreSQL will use the index.
mydb=# explain select * from mytab where id in (75,25,2014,589);
QUERY PLAN
-------------------------------------------------------------------------------------
Index Scan using btree_mytab_id on mytab (cost=0.07..20.34 rows=4 width=17)
Index Cond: (id = ANY ('{75,25,2014,589}'::integer[]))
(2 rows)
Just not that explain analyze will not use the virtual index
Conclusion
In this article we see how POWA can help for optimizing our PostgreSQL database.
References: https://pgxn.org/dist/hypopg/; http://powa.readthedocs.io/en/latest/
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/oracle-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/10/STS_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/09/SNA_web-min-scaled.jpg)