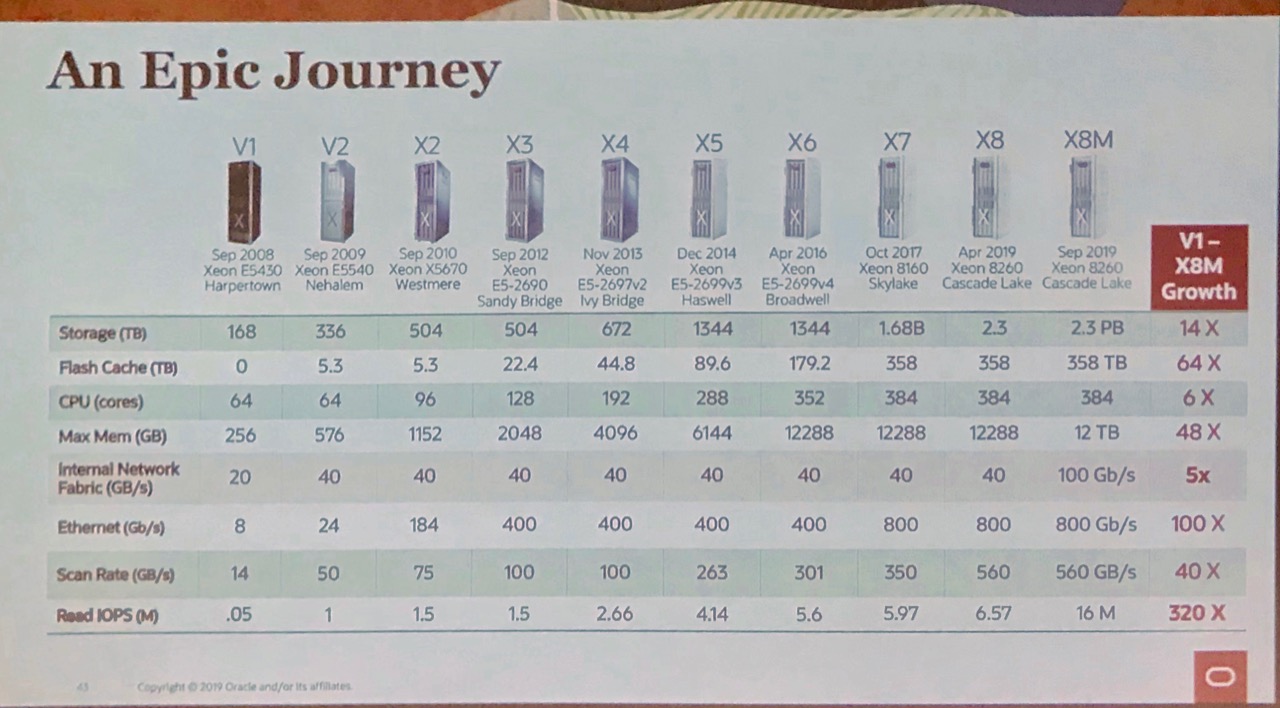
Todays fastest possible interface for flash storage in terms of bandwidth and latency are DRAM sockets. Exadata X8M is the first Oracle engineered system using this technology that, according to first measurements taken by Oracle corporation, result in 200% read IO increase compared to Exadata X8. Summary from a presentation by Gavin Parish held at DOAG 2019 conference with a comment by Michael Wirz.
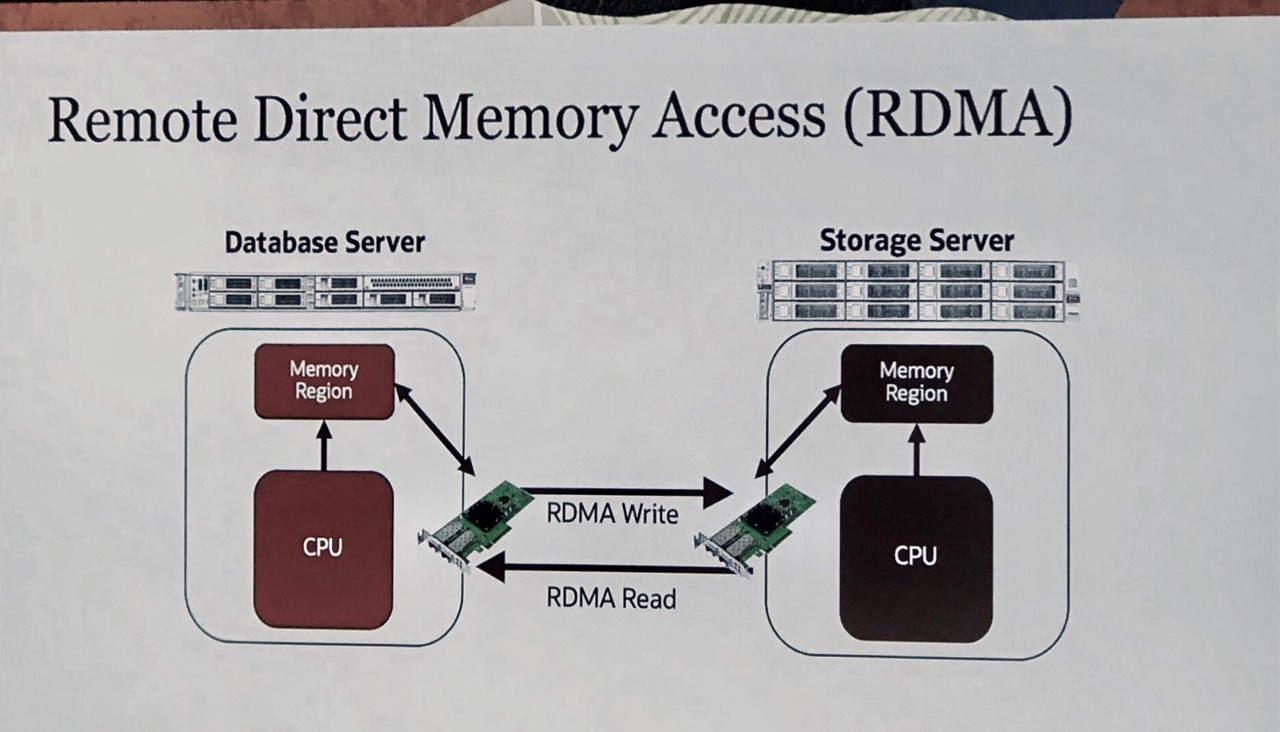
A DB node is writing and reading IO using RoCE PCIe network cards. RoCE stands for Remote Direct Memory Acess Protocoll over Converged Ethernet. According to first measurements done by Oracle, this leads to impressive 16 million 8K IOs with a latency of under 19 microseconds. It has to be mentioned that this number is only possible with a special setup: RAC Database using 11 DB servers connected to 11 storage servers.
RoCE adapters bypass the OS kernel which leads to factor 5 reduced latency. To avoid data loss in the situation one storage server dies, data is beeing written simultaneously to persistent memory (PMEM) on two storage servers. After receiving write acknowledge from one of these storage servers, the compute server would continue to process data.
There are 1.5 Gbytes PMEM per storage server on X8M platform, and it’s used for
- Redo logs
Writing to redo logs is a prominent bottleneck in OLTP databases - Cache read IOs to the data files
This improves read IO performance in databases used for data warehouse applications
It would be interesting to see how PMEM would be used in future, not only on Exadata platform. As one can read on support.oracle.com (File Systems and Devices on Persistent Memory (PMEM) in Database Servers May Cause Database Corruption – Doc ID 2608116.1), it’s not just integrating new hardware to form a stable platform to run Oracle database. To avoid block corruption, storage software on storage servers had to be enhanced to support PMEM modules.
Chances for other vendors exist to develop platforms having IO costs optimised using massive sized, local NVMe storage. It’s no doubt Exadata seen as a full package, not only from performance capabilities, is an interesting platform mainly to house data warehouse databases. It remains a challenging task to correctly evaluate and define scope of application of each pre- or self-engineered platform.
Click here for implementation details of PMEM on Exadata.
Comment by Michael Wirz
The presented feature for writing the redo logs parallel on PMEM and on the normal (and slower) hard drive without slowing down the writing process is a clever solution. This is one of the feature I would love to see also on non Exadata version of Oracle database. As example, writing one member down to a local NVMe disk or PMEM and writing down the second member async on an external NFS share without slowing down the process. Of course it would not have the same level of security then writing it down in synchronous on two different locations, but would still provide a higher level of security then just writing it down of local disks. Such a solution could bring you significant advantages for a single database, then writing it just on local disks in case of an outage of the complete server.
As impressive the numbers are, please hold in mind, that 16 million IOPS is the performance on a optimised RAC application on an Exadata full rack. As mentioned in many discussions on Exadata, this is surely the best platform on the market to host a data-warehouse applications. For on OLTP application, especially on which is not optimised for RAC, my opinion is different. By using local NVMe storage in a single server you can get a similar number of IOPs out of a server as you can get from one node in an Exadata with a fraction of the cost and even can choose higher CPU clock speed. This boosts the response time for most OLTP application quite significantly. The smart scan technology as great it is for a data-warehouse, normally does not improve the performance of a common OLTP application. Compared with an Exadata the complexity of a single server with local storage is much lower by cutting out a lot of components as HBAs, storage Switches etc. Personally I like the fact, not sharing anything that is not necessary with other systems, making it much easier to predict the performance for a system.
As I will show soon in another blogpost, you can get over 1 million random IOPS out of a single 2HE server with NVMe @8KB block-size and even more then 25 GBytes of large IOPS @1MByte with such a setup. This is not fully comparable with the numbers Oracle provided, because they published performance data out of the Oracle database as SQL workload. I will try to do a similar test on a test server with local NVMe storage.
Stay tuned, my blogpost about local NVMe storage will be ready this month.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/oracle-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/11/LTO_WEB.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2023/01/APY_web-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/FRJ_web-min-scaled.jpg)