By Franck Pachot
.
You don’t want to reload the datawarehouse database every night. And you may want to have it refreshed more often, in real-time during the day. There is another reason to capture all changes from the operational database: you want the history of all updates and not only the current value. This is why you use Change Data Capture (and Streams propagation is based on that), a feature available in Enterprise Edition with no need of any option. But when you look for in in the 12c documentation, you find it in the ‘deprecated features’ chapter. Then what to do?
The reason of deprecation is clear. Oracle has acquired Golden Gate and they don’t want to maintain two replication solution. All the features that can be done by Golden Gate are deprecated:
- Desupport of Change Data Capture
- Deprecation of Advanced Replication
- Deprecation of Oracle Streams
Ok. the idea is to replace them with Golden Gate. But Gloden Gate is another product and is not included in Oracle Database licences.
| Trigger based replication | Redo based replication |
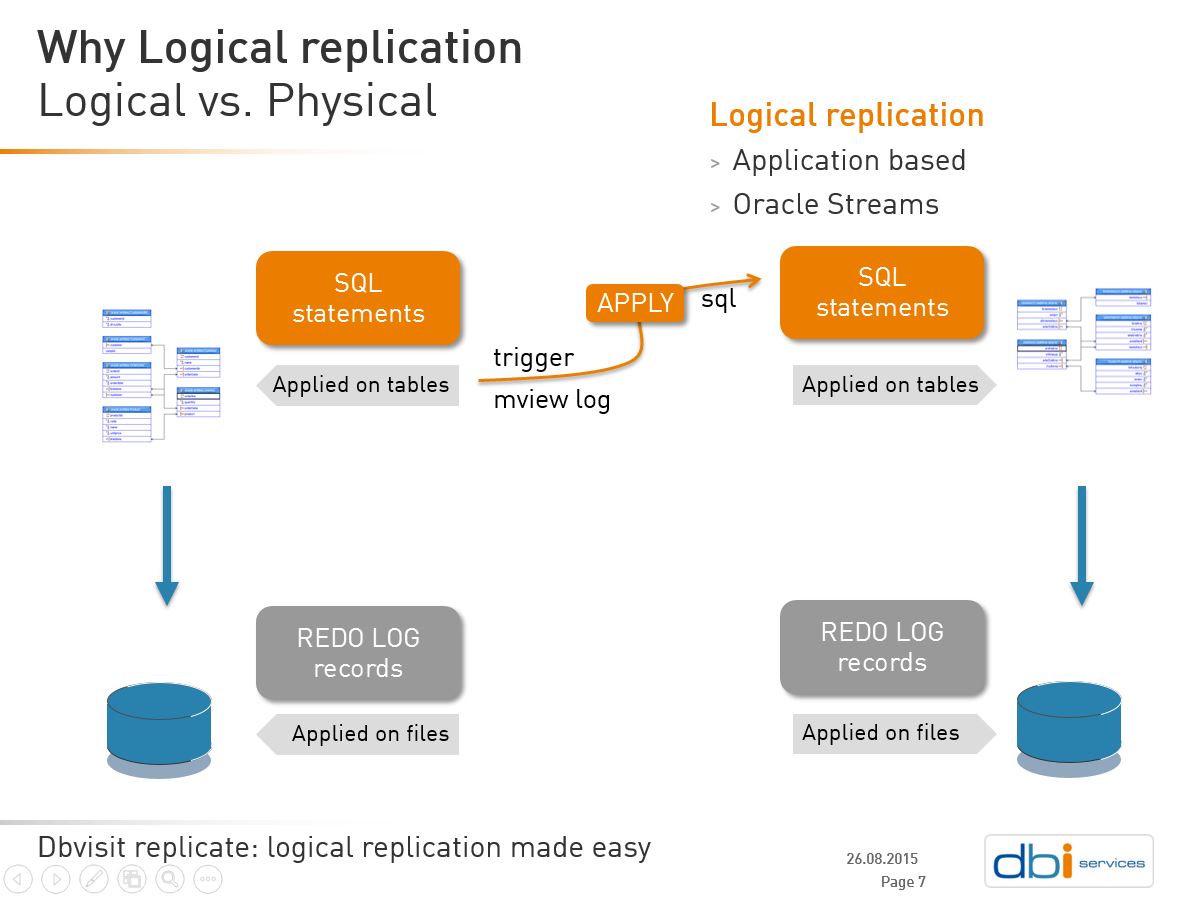 |
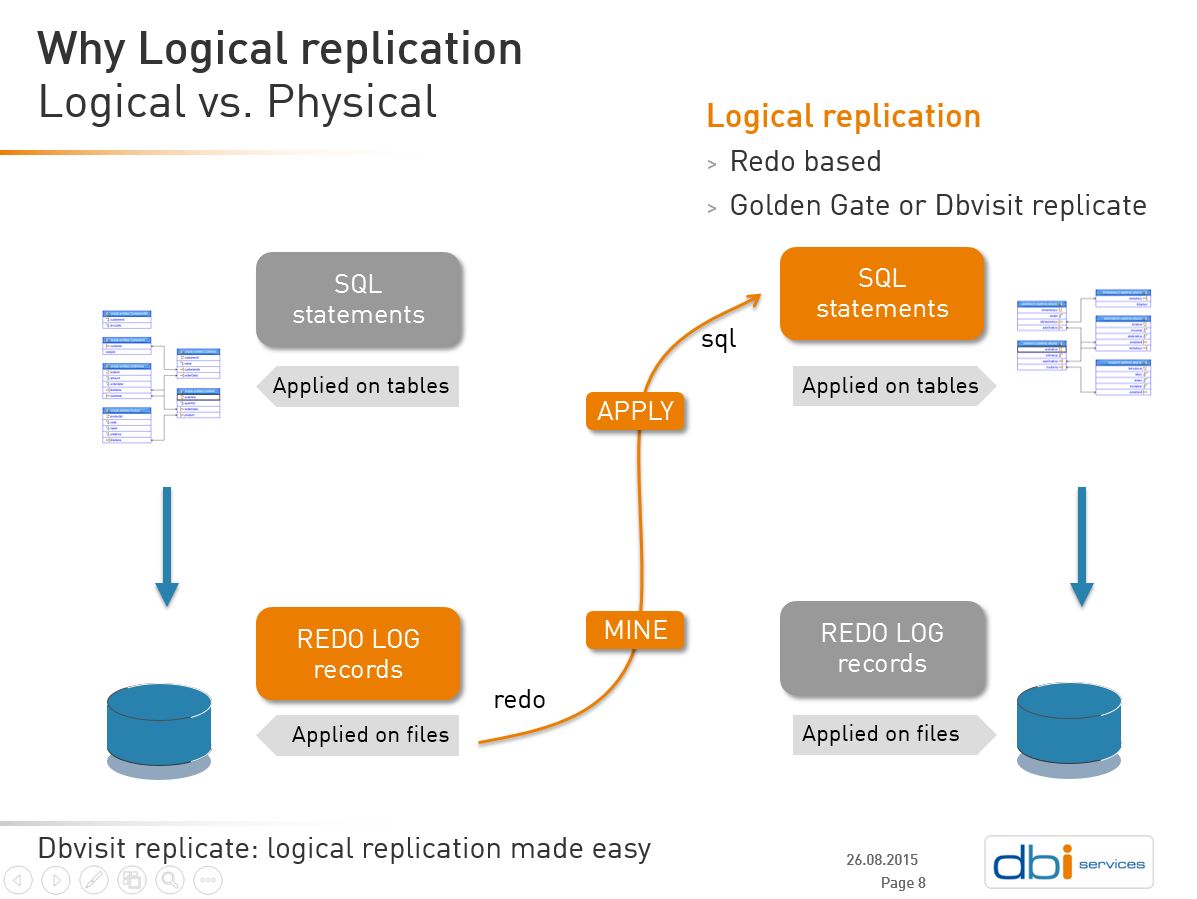 |
| source: http://www.soug.ch/fileadmin/user_upload/SIGs/SIG_141106_R_Lausanne/Pachot_Dbvisit-replicate.pdf | |
Logical replication
Triggers
There are two ways to capture changes. The first one you can think of is to put triggers on the source tables. Each change is logged, with additional information about the change (operation, timestamp, old and new values). But this is not a good design for our case: propagate changes to datawarehouse.
The first reason is that we don’t want the overhead on the source. But there is more: how do you propagate the incremental changes? The basic idea is to use the timestamp: propagate all changes that happened since previous run. But this is a wrong approach. Changes that were done before the point-in-time to consider, by a transaction that has commited after that point-in-time, will not be propagated because of transaction isolation: you don’t see uncommited changes. And the next run could see them, but the timestamp being before the last run, they will not be considered.
There are no good solution for that. You need to check when the long transactions have started, you need to managed possible doublons, etc.
Commit SCN
Ok, there is a solution that oracle uses internally. There is a way to get the commit SCN in each row. But this is undocumented, and has a lot of side effects. I show it, play with it and you will see the limits:
19:23:38 SQL> create table DEMO (id number, update_scn number, commit_scn number);
Table created.
19:23:49 SQL> select dbms_flashback.get_system_change_number from dual;
GET_SYSTEM_CHANGE_NUMBER
------------------------
3523159
19:24:29 SQL> insert into DEMO values (1,dbms_flashback.get_system_change_number,userenv('commitscn'));
1 row created.
19:24:49 SQL> select * from DEMO;
ID UPDATE_SCN COMMIT_SCN
---------- ---------- ----------
1 3523526 3523526
19:24:57 SQL> select dbms_flashback.get_system_change_number from dual;
GET_SYSTEM_CHANGE_NUMBER
------------------------
3523700
19:25:11 SQL> commit;
Commit complete.
19:25:14 SQL> select * from DEMO;
ID UPDATE_SCN COMMIT_SCN
---------- ---------- ----------
1 3523526 3523718
You see: the commit is not supposed to change the data. but it did. I let you imagine all the consequences with that.
redo mining
The right solution is asynchronous change data capture from the redo logs. You only have to add supplemental logging and you have everything you need in the redo stream. This is what is used by most lof logical replication software. I know 3 alternatives for it:
- Do it yourself: use Log Miner to get the change, build the SQL to apply, and order them to folloy the commit sequence.
- Golden Gate: this is the solution that is proposed by Oracle. It’s a big project to replace your existing replication with it (new product, new skills, new configuration) but it’s robust and scalable.
- Dbvisit replicate, the ‘smart alternative’ do not have all Golden Gate features, but is easy to setup with its setup wizard, and easy to maintain with its amazing support.
I will take an exemple here with Dbvisit replicate because it has a feature that fit exacly the need of a near real-time BI. The solution is described on Dbvisit documentation.
Dbvisit replicate CDC/Audit
Dbvisit replicate default replication mode is to maintain a copy of the source tables. A first copy is done (with a ‘AS OF SCN’ datapump for example) and then the replication will apply the change that occured since this SCN. Whith that kind of replication, you can maintain a datawarehouse in real-time, but there are a few drawbacks.
Audit all changes
If the operational application stores only the final state (an inventory for example) but you need to rebuild all the facts (the stock movements in that example), then the simple replication is not sufficient. The Dbvisit replicate CDC/Audit mode is the solution to store all changes, with old and new values and change timestamps.
Bitmap indexes and compression
The datawarehouse fact tables are probably compressed and have bitmap indexes. When you load them in bulk, there is no problem. But applying real-time row-by-row on them is not optimal. First, except if you have the Advanced Compression Option, the updates will decompress them. And bitmap indexes wil degenerate. Which means that you have to reorg/rebuild them frequently. In addition to that, for performance and scalability reason, you probably want to apply the changes in parallel. Bitmap indexes don’t lock at row level, so you may have your replication stuck because they touch the same range of rowid. On Exadata, HCC compression locks at compression unit level, which has similar consequence.
Then, in order to keep the datawarehouse tables optimal (compressed for query, pctfree 0, bitmap index), you need to to it in bulk. You replicate in real time into a staging area, with logical replication. And you have a job, maybe every 10 minutes, that propagates the changes with bulk operations (pl/sql forall, insert append). This is the right way to keep a near-real-time datawarehouse optimized for queries.
But you don’t want all data in that staging area. You want only the changes since the last bulk operation. This is where you used the CDC/Audit:
- You setup Dbvisit replicate to replicate all changes with commit timestamp
- You develop the propagation scripts which are simple deletes and insert append using the timestamp to get new changes since last run
- If for whatever reason the replication is interrupted, you don’t have to copy all data again. Just restart the replication from the latest SCN that has been replication up to the end
change auditing / real-time BI
here is how to configure it:
Configure change data capture for change auditing or real-time BI? (NO/YES) [NO] YES
Capture DELETE operations? (YES/NO) [YES]
Capture UPDATE operations - old values? (YES/NO) [YES]
Capture UPDATE operations - new values? (YES/NO) [YES]
Capture INSERT operations? (YES/NO) [YES]
Prefix for columns with OLD values: [] OLD$
Prefix for columns with NEW values: [] NEW$
Add basic additional information about the changes? (SCN, time, operation type) (YES/NO) [YES]
Add more transactional information? (transaction id, commit time) (YES/NO) [NO] YES
Add auditing columns? (login user, machine, OS user...) (YES/NO) [NO]
This does not generate a DataPump script but a sql script to create the staging tables:
set define off
DROP TABLE "DEMO"."DEMO$AUDIT" cascade constraints;
CREATE TABLE "DEMO"."DEMO$AUDIT" (
OLD$ID NUMBER,
NEW$ID NUMBER,
OLD$TEXT VARCHAR2(10),
NEW$TEXT VARCHAR2(10),
OPERATION CHAR,
XID VARCHAR2(30),
CHANGE DATE,
COMMIT DATE,
SCN NUMBER);
grant select, update, insert, delete on "DEMO"."DEMO$AUDIT" to dbvrep;
My DEMO table has only two columns (ID, TEXT) and the audit table has columns for their old and new values, as well as the change and transaction information I selected.
Example of insert
Then replication starts as usual with Dbvisit replicate. When it runs, I insert a row into my DEMO table:
21:42:32 SQL> insert into DEMO(text) select to_char(sysdate,'hh24:mi:ss') from v$database;
1 row created.
and commit 5 seconds later:
21:43:18 SQL> commit;
Commit complete.
Here is my source table:
21:43:48 SQL> select * from DEMO order by id;
ID TEXT
---------- ----------
1 21:42:33
Note that the ID column is a 12c ‘generated by default as identity’.
And now let’s see what has been replicated.
21:43:48 SQL> select * from DEMO$AUDIT order by 1,2;
OLD$ID NEW$ID OLD$TEXT NEW$TEXT O XID CHANGE COMMIT SCN
------ ------ -------- ---------- - ----------------- -------- -------- ----------
1 21:42:33 I 0004.003.0000070f 21:42:34 21:43:18 3599970
It’s an insert (I) done at 21:42:34 by the transaction 0004.003.0000070f. This is what has been replicated when the MINE/APPLY has processed the redo record for the insert. Then when the redo record for the commit has been processed, the APPLY came back to the row and update where xid=’0004.003.0000070f’ to set the commit timestamp.
We can check that the SCN is the SCN at the time of update – not the commit SCN.
SCN_TO_TIMESTAMP(3599970)
-------------------------------
02-AUG-15 09.42.32.000000000 PM
So it’s the COMMIT timestamp that must be used to propagate the change to the datawarehouse tables. The important thing here is that we have in the staging tables all information from the source database.
Conclusion
With Change Data Capture you have all change history stored into staging tables. And you have all information to maintain the destination tables with block operations. You don’t have anything to change to the source database except supplemental logging. You don’t have anything to change to the destination tables that are optimized for queries.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/oracle-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/05/JDE_Web-1-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/MAW_web-min-scaled.jpg)