By William Sescu
Oracle incrementally updating backups are used quite often because they are easy to setup and restoring a datafile is very fast. It is very fast because you are not really restoring a datafile, you are switching to the copy, in case something happens. But how do I switch back to the original destination with minimal downtime and with minimal impact on the system?
A quite common scenario is that we have 3 diskgroups, +DATA, +FRA and +REDO with different performance characteristics, like the following:
- +DATA Diskgoup is on fast storage (10k rpm)
- +FRA Diskgroup is on medium storage (7200 rpm)
- +REDO Diskgroup is on very fast storage (15k rpm)
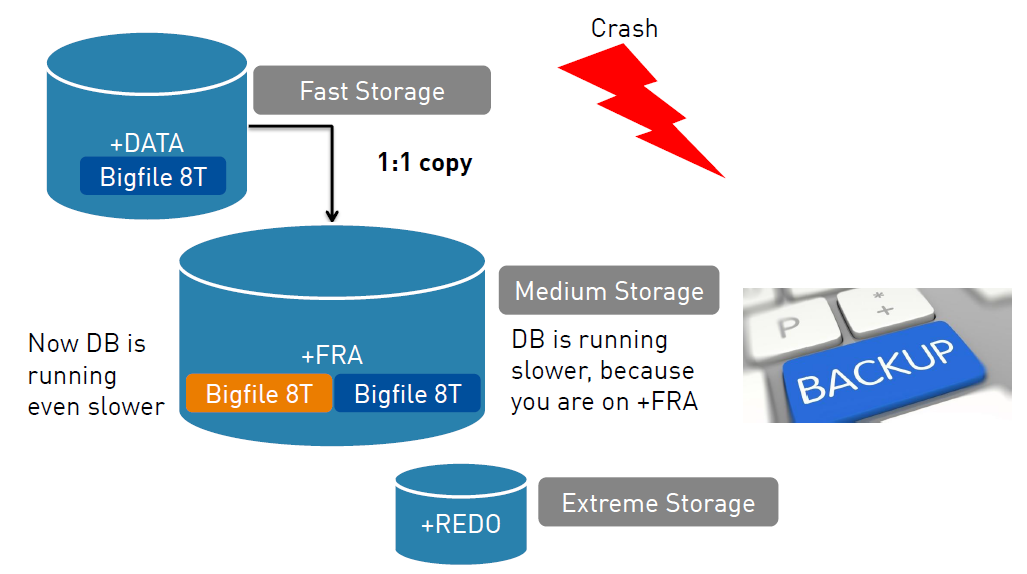
In case we loose now a bigfile with 8TB on the +DATA diskgroup, what options do we have to restore it. Ok. Lets ask the Oracle Data Recovery Advisor first. Oracle came up with the following script.
oracle@oel001:/home/oracle/rman/ [OCM121] cat /u00/app/oracle/diag/rdbms/ocm121/OCM121/hm/reco_3905236091.hm # restore and recover datafile restore ( datafile 9 ); recover datafile 9; sql 'alter database datafile 9 online';
The script does his job, no question about it, but it means, that Oracle would copy 8TB from the +FRA to +DATA and afterwards maybe applying an inc1 and some archivelogs. If we do run this script, we wait for 4h. (suppose that we are copying with 600MB per second, which is very good)
In case your Database has a Standby in a DataGuard configuration, Oracle comes up with the following suggestion.
oracle@oel001:/home/oracle/rman/ [OCM121] cat /u00/app/oracle/diag/rdbms/ocm121/OCM121/hm/reco_4177443733.hm # restore from standby and recover datafile restore ( datafile 9 from service "sty121" ); recover datafile 9; sql 'alter database datafile 9 online';
Again, it will work, but now Oracle tries to get the 8TB datafile over the network from the standby, which makes it even slower. Unfortunately, the “switch datafile to copy” was not build in, into the Recovery Advisor.
Ok. Lets do it manually and switch to the datafile copy. That takes only a few minutes, and this is the reason why we have incrementally updating backups. To make it as fast as possible.
RMAN> switch datafile 9 to copy; datafile 9 switched to datafile copy "+FRA/OCM121/DATAFILE/monster.346.919594959" RMAN> recover datafile 9; RMAN> sql 'alter database datafile 9 online';
Now we restored and recoverd the 8TB datafile, and users can start working again on that bigfile tablespace. But due to the fact that the +FRA has only medium storage, your application might run slower than before.
Be careful, another issue might pop up after you are already on your datafile copy in the +FRA. If now a backup kicks it (scheduled by cron or something else), then Oracle has to create another 8TB in the +FRA as a new base for his incrementally updating backups, which makes your application even slower and even worse, you might run out of space.
An easy restore might end up now in a quite complex scenario. So what do we do now. First of all, we have to make sure that backups are not scheduled during our restore/recovery, and then we can manually create a new datafile copy in +DATA (of course, after the situation was corrected which lead to the datafile loss). In case you are running 12c, you can use the new feature “Multisection Backup for Datafile Copies”.
RMAN> backup section size 1T as copy datafile 9 format ='+DATA' tag clonefile9;
Now, a small downtime kicks in, when we have to take the datafile offline, switch to our new one in +DATA, recover it, and take it online again.
RMAN> sql 'alter database datafile 9 offline'; RMAN> switch datafile 9 to copy; RMAN> recover datafile 9; RMAN> sql 'alter database datafile 9 online';
Uffff … we are ready now, and users can work with the application again which is on the fast storage in +DATA. But wait a second, if we start our RMAN backup again, then Oracle does not regognize the datafile copy in +FRA anymore as a valid copy for incrementally updataing backups. So, Oracle has to create another 8TB in the +FRA.
Now comes the 1Million $ question. How can we avoid this? We need to tag the datafile copy in +FRA as a valid starting point for incrementally updating backups.
RMAN> catalog datafilecopy '+fra/ocm121/datafile/MONSTER.346.919594959' level 0 TAG 'incr_update'; cataloged datafile copy datafile copy file name=+FRA/ocm121/datafile/monster.346.919594959 RECID=33 STAMP=919603336
Oracle has the very useful command “catalog” for situations like this. Take care, that you specify “level 0” and the correct “tag”, otherwise the datafile copy will not be regognized.
Now we are really ready, and we can start the RMAN incremetally backups again, like we did beforehand.
To summarize it:
- Take care of your backups during the restore, it might makes the situation even worse.
- Make use of the new feature “Multisection Backup for Datafile Copies”. It can speed up the creation of your datafile copies quite heavily.
- Use the “catalog” command to tag your datafile copy correctly. It avoids the creation of another 8TB.
Cheers,
William
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/12/oracle-square.png)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/03/AHI_web.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/11/LTO_WEB.jpg)