This article is part of a series that includes SQLite, Postgresql, Firebird, Oracle RDBMS, Microsoft SQL Server, HSQLDB, MongoDB, and MariaDB. The goal is to set up a self-standing environment for testing an ODBC extension for gawk presented here to be completed. Refer to SQLite for installing the required ODBC Driver Manager.
The test system is a debian v11 (bullseye).
Like MongoDB, Excel is not a relational data source, but the ODBC API will allow to access its data using SQL statements. The idea is to access spreadsheet files as if they were relational databases, each sheet being a table, each line a table’s row and each column a table’s column. The first row of a sheet contains the column headers. This is quite self-evident; see the screen copy down below.
As the Excel sheet is the database, there is no server software to install but only the ODBC drivers.
Let’s create a spreadsheet with the data sample from the site. We will just query an existing database, e.g. the PostgreSQL one if the instructions here were applied, and extract the content of the tables, as shown below:
$ psql sampledb \a Output format is unaligned. sampledb=> select * from regions; region_id|region_name 1|Europe 2|Americas 3|Asia 4|Middle East and Africa (4 rows) sampledb=> select * from countries; country_id|country_name|region_id AR|Argentina|2 AU|Australia|3 BE|Belgium|1 BR|Brazil|2 ... (29 rows)
and so on with the other tables locations, departments, jobs, employees and dependents.
We will simply create one spreadsheet using LibreOffice Calc or Excel, create one tab per table with the table name as its name, paste the data from the above output with the column headers as the first line. Be sure to select the ‘|’ character as the column separator and remove spurious lines and columns. This step is manual and a bit tedious, but it’ll only take a few minutes.
The image below shows how the spreadsheet may look like with some data in it:
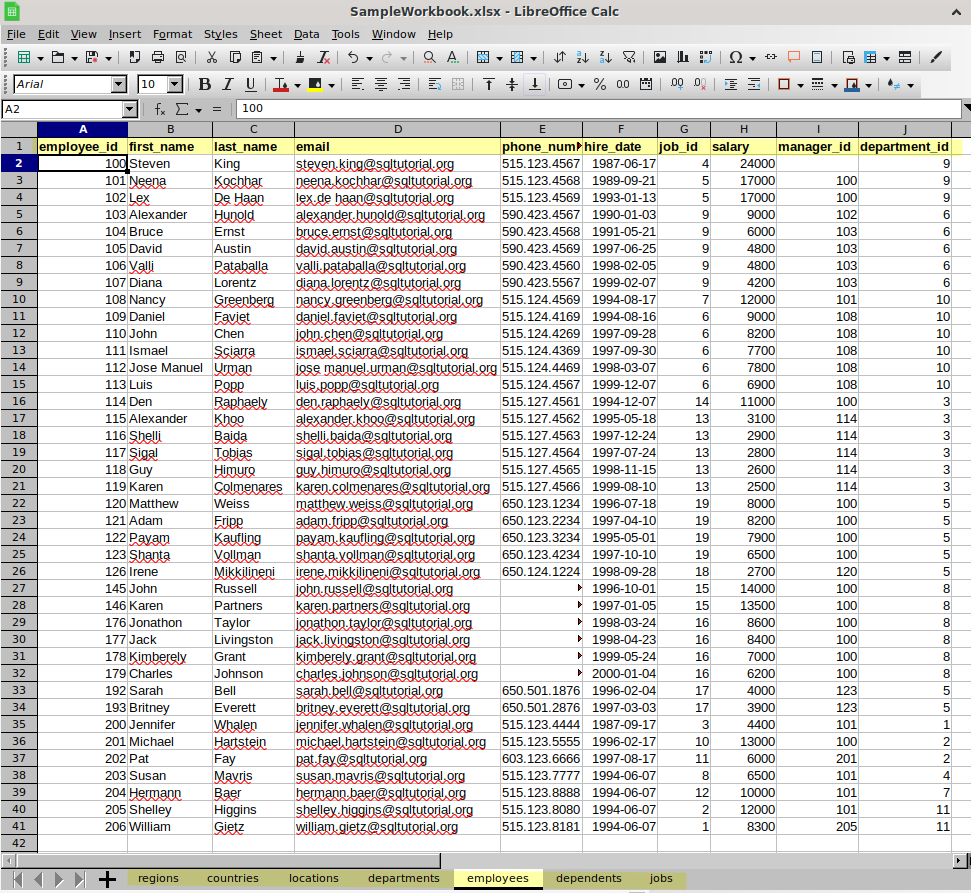
If using isql to extract the data into a tabular format, spurious blanks are added, e.g.:
$ isql -v mysqldb -v debian debian SQL> select * from regions; +------------+--------------------------+ | region_id | region_name | +------------+--------------------------+ | 1 | Europe | | 2 | Americas | | 3 | Asia | | 4 | Middle East and Africa | +------------+--------------------------+ SQLRowCount returns 4 SQL> select * from countries; +-----------+-----------------------------------------+------------+ | country_id| country_name | region_id | +-----------+-----------------------------------------+------------+ | AR | Argentina | 2 | | AU | Australia | 3 | | BE | Belgium | 1 | ... | ZM | Zambia | 4 | | ZW | Zimbabwe | 4 | +-----------+-----------------------------------------+------------+ SQLRowCount returns 29 29 rows fetched
This leading and trailing blanks must be removed as they don’t belong to the data but were added by isql to format the table so that it displays nicely. The following gawk script can be used to this effect:
for t in {regions,countries,locations,departments,jobs,employees,dependents}; do echo "select * from $t;" | isql -v mysqldb debian debian | gawk -v table_name=$t 'BEGIN {
print "table", table_name
do {
getline
} while (0 == index($0, "SQL>"))
n = split ($0, t, "+")
delete t[1]
FIELDWIDTHS = "1"
for (i = 2; i < n; i++)
FIELDWIDTHS = FIELDWIDTHS sprintf(" %d 1", length(t[i]))
FIELDWIDTHS = FIELDWIDTHS " 1"
bHeader = 0
}
{
bHeader++
if (index($0, "+-"))
if (2 == bHeader)
next
else
exit
for (i = 2; i < NF; i += 2) {gsub(/(^ +)|( +$)/, "", $i); printf("%s|", $i)}
printf "\n"
}
END {
printf "\n"
}';
done
Output:
table regions
region_id|region_name|
1|Europe|
2|Americas|
3|Asia|
4|Middle East and Africa|
table countries
country_id|country_name|region_id|
AR|Argentina|2|
...
etc...
If no prior database with the sample data is available, just save the data from here into a text file, say populate-tables.sql, save the following gawk script sql2flat.awk:
# convert sql statements into csv;
# INSERT INTO regions(region_id,region_name) VALUES (1,'Europe');
# becomes
# 1|Europe
# INSERT INTO locations(location_id,street_address,postal_code,city,state_province,country_id) VALUES (1400,'2014 Jabberwocky Rd','26192','Southlake','Texas','US');
# becomes
# 1400|2014 Jabberwocky Rd|26192|Southlake|Texas|US
# sql comes from here for example: https://www.sqltutorial.org/wp-content/uploads/2020/04/postgresql-data.txt;
# Usage:
# gawk -v sep=separator -f sql2csv.awk data.sql
# Example:
# gawk -v sep="|" -f sql2csv.awk populate-tables.sql | tee populate-tables.csv
{
if (match($0, /INSERT INTO ([^)]+)\(.+\) VALUES \((.+)\)/, m)) {
if (m[1] != ex_table) {
ex_table = m[1]
print "# tab", m[1] ":"
}
gsub(/'|"/, "", m[2])
n = split(m[2], data, ",")
for (i = 1; i 1 ≤ n; i++)
printf("%s%s", i > 1 ? sep : "", data[i])
printf "\n"
}
}
and run it on the data file:
gawk -v sep="|" -f sql2flat.awk populate-tables.sql
Snippet of output:
# tab regions: 1|Europe 2|Americas 3|Asia 4|Middle East and Africa # tab countries: AR|Argentina|2 AU|Australia|3 BE|Belgium|1 BR|Brazil|2 ... # tab locations: 1400|2014 Jabberwocky Rd|26192|Southlake|Texas|US 1500|2011 Interiors Blvd|99236|South San Francisco|California|US ... # tab jobs: 1|Public Accountant|4200.00|9000.00 2|Accounting Manager|8200.00|16000.00 3|Administration Assistant|3000.00|6000.00 ... # tab departments: 1|Administration|1700 2|Marketing|1800 ... # tab employees: 100|Steven|King|[email protected]|515.123.4567|1987-06-17|4|24000.00|NULL|9 101|Neena|Kochhar|[email protected]|515.123.4568|1989-09-21|5|17000.00|100|9 102|Lex|De Haan|lex.de [email protected]|515.123.4569|1993-01-13|5|17000.00|100|9 ... # tab dependents: 1|Penelope|Gietz|Child|206 2|Nick|Higgins|Child|205 3|Ed|Whalen|Child|200 ...
Next, copy and paste the above output into the respective sheet’s tabs.
After the edition is completed, save the file as SampleWorkbook.xlsx (for compatibility, select the output format as Excel file if using LibreOffice Calc) and keep a copy of it somewhere in case it becomes corrupted during the tests.
We will use the commercial ODBC drivers provided by cdata (https://www.cdata.com/odbc/); other vendors are e.g. Easysoft (https://www.easysoft.com/developer/interfaces/odbc/index.html) and Devart (https://www.devart.com/odbc/).
Download the drivers from https://www.cdata.com/drivers/excel/odbc/ by following the instructions on the screen, and install them as root:
# dpkg -i ExcelODBCDriverforUnix.deb
Run the licensing script and follow the on-screen instructions:
# cd /opt/cdata/cdata-odbc-driver-for-excel/bin/ # ./install-license.x64 ************************************************************************* Please provide your name and email to install a trial license. To install a full version license pass your product key as a parameter. For instance: ./install-license MY_PRODUCT_KEY Please refer to the documentation for additional details. ************************************************************************* Name: debian Email: ... Installing TRIAL license... Downloading license data... Verifying license data... License installation succeeded.
Check the system-wide installed drivers:
# odbcinst -q -d ... [CData ODBC Driver for Excel] # odbcinst -q -d -n "CData ODBC Driver for Excel" [CData ODBC Driver for Excel] Description=CData ODBC Driver for Excel 2021 Driver=/opt/cdata/cdata-odbc-driver-for-excel/lib/libexcelodbc.x64.so UsageCount=1 Driver64=/opt/cdata/cdata-odbc-driver-for-excel/lib/libexcelodbc.x64.so
Check the system-wide DSN in /etc/odbc.ini:
# odbcinst -q -s ... [CData-Excel-Source] # odbcinst -q -s -n "CData-Excel-Source" [CData Excel Source] Driver=CData ODBC Driver for Excel AWS Access Key= AWS Region=NORTHERNVIRGINIA AWS Role ARN= AWS Secret Key= Azure Access Key= Azure Shared Access Signature= Azure Storage Account= Azure Tenant= MFA Serial Number= MFA Token= Password= Share Point Edition=SharePointOnline SSL Mode=AUTOMATIC User=
Copy the newly inserted DSN into debian’s own ~/.odbc.ini file and append the URI setting as follows:
$ vi ~/.odbc.ini ... [CData-Excel-Source] Driver=CData ODBC Driver for Excel AWS Access Key= AWS Region=NORTHERNVIRGINIA AWS Role ARN= AWS Secret Key= Azure Access Key= Azure Shared Access Signature= Azure Storage Account= Azure Tenant= MFA Serial Number= MFA Token= Password= Share Point Edition=SharePointOnline SSL Mode=AUTOMATIC User= URI=/home/debian/odbc4gawk/SampleWorkbook.xlsx
As debian, check its DSN so far:
$ odbcinst -q -s [mysqlitedb] [mysqldb] [myfbdb] [myfbdb_Devart] [mypostgresqldb] [OracleODBC-21] [mymssqlserverdb] [myhsqldb] [mymongodb] [DEVART_MONGODB] [DEVART_FIREBIRD] [CData-Excel-Source] $ odbcinst -q -s -n [CData-Excel-Source] [CData-Excel-Source] Driver=CData ODBC Driver for Excel AWS Access Key= AWS Region=NORTHERNVIRGINIA AWS Role ARN= AWS Secret Key= Azure Access Key= Azure Shared Access Signature= Azure Storage Account= Azure Tenant= MFA Serial Number= MFA Token= Password= Share Point Edition=SharePointOnline SSL Mode=AUTOMATIC User= URI=/media/sf_customers/dbi/odbc4gawk/SampleWorkbook.xlsx
Try a connection to the spreadsheet via the ODBC Driver Manager’s isql tool:
# isql -v "CData Excel Source" +---------------------------------------+ | Connected! | | | | sql-statement | | help [tablename] | | quit | | | +---------------------------------------+ SQL> help +-----------+-------------+-------------------------------------------------------------------------+ | TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | +-----------+-------------+---------------+------------+--------------------------------------------+ | CData | Excel | regions | TABLE | Retrieve data from the "regions" sheet. | | CData | Excel | countries | TABLE | Retrieve data from the "countries" sheet. | | CData | Excel | locations | TABLE | Retrieve data from the "locations" sheet. | | CData | Excel | department | TABLE | Retrieve data from the "department" sheet. | | CData | Excel | employees | TABLE | Retrieve data from the "employees" sheet. | | CData | Excel | dependent | TABLE | Retrieve data from the "dependent" sheet. | | CData | Excel | jobs | TABLE | Retrieve data from the "jobs" sheet. | +-----------+-------------+---------------+------------+--------------------------------------------+ SQLRowCount returns -1 7 rows fetched
Interesting how the driver presents the data dictionary.
Run the test query:
SQL> SELECT c.country_name, c.country_id, l.country_id, l.street_address, l.city FROM countries c LEFT JOIN locations l ON l.country_id = c.country_id WHERE c.country_id IN ('US', 'UK', 'CN');
Output:
+----------------------------+-------------+------------+-------------------------------------------+----------------------+
| country_name | country_id | country_id | street_address | city |
+----------------------------+-------------+------------+-------------------------------------------+----------------------+
| United Kingdom | UK | UK | 8204 Arthur St | London |
| United Kingdom | UK | UK | Magdalen Centre, The Oxford Science Park | Oxford |
| United States of America | US | US | 2014 Jabberwocky Rd | Southlake |
| United States of America | US | US | 2011 Interiors Blvd | South San Francisco |
| United States of America | US | US | 2004 Charade Rd | Seattle |
| China | CN | | | |
+----------------------------+-------------+------------+-------------------------------------------+----------------------+
SQLRowCount returns -1
6 rows fetched
The join was performed as expected.
Let’s now see how the driver behaves when used with python the module pyodbc:
$ python3
import pyodbc Python 3.9.2 (default, Feb 28 2021, 17:03:44)
[GCC 10.2.1 20210110] on linux
Type "help", "copyright", "credits" or "license" for more information.
import pyodbc
# connect using the DSN;
cnxn = pyodbc.connect(DSN='Cdata-Excel-Source')
# or:
# connect directly using the DRIVER definition, no DSN;
cnxn = pyodbc.connect('DRIVER={CData ODBC Driver for Excel};URI=/media/sf_customers/dbi/odbc4gawk/SampleWorkbook.xlsx')
cursor = cnxn.cursor()
cursor.execute("""SELECT
c.country_name,
c.country_id,
l.country_id,
l.street_address,
l.city
FROM
countries c
LEFT JOIN locations l ON l.country_id = c.country_id
WHERE
c.country_id IN ('US', 'UK', 'CN')""")
row = cursor.fetchone()
while row:
print (row)
row = cursor.fetchone()
Output:
('United Kingdom', 'UK', 'UK', '8204 Arthur St', 'London')
('United Kingdom', 'UK', 'UK', 'Magdalen Centre - The Oxford Science Park', 'Oxford')
('United States of America', 'US', 'US', '2014 Jabberwocky Rd', 'Southlake')
('United States of America', 'US', 'US', '2011 Interiors Blvd', 'South San Francisco')
('United States of America', 'US', 'US', '2004 Charade Rd', 'Seattle')
('China', 'CN', None, None, None)
Excel spreadsheets are now accessible via ODBC under the debian account.
Admittedly, Excel sheets are no natural and reliable data sources for too many reasons to mention here (but they have other advantages) but it is quite impressive and almost magical to query them using SQL vs. some low-level cell-oriented API !
Instructions for the other data sources can be accessed through the following links:
SQLite
Firebird
HSQLDB
MariaDB
PostgreSQL
Oracle
Microsoft SQLServer for Linux
MongoDB
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/11/LTO_WEB.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2023/01/APY_web-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/FRJ_web-min-scaled.jpg)