By Franck Pachot
.
I have posted, a long time ago, about Google Spanner (inserting data and no decimal numeric data types) but many things have changed in this area. There is now a NUMERIC data type and many things have improved in this distributed SQL database, improving a bit the SQL compatibility.
gcloud
I can use the Cloud Shell, which is very easy – one click fron the console – but here I’m showing how to install the gcloud CLI temporarily in a OEL environement (I’ve explained in a previous post how the OCI free tier is my preferred home)
curl https://dl.google.com/dl/cloudsdk/channels/rapid/downloads/google-cloud-sdk-321.0.0-linux-x86_64.tar.gz | tar -C /var/tmp -zxf -
/var/tmp/google-cloud-sdk/install.sh --usage-reporting true --screen-reader false --rc-path /tmp/gcloud.tmp --command-completion true --path-update true --override-components
This downloads and unzips the Google Cloud SDK for Linux (there are other options like a YUM repo). I put it in a temporary directory here under /var/tmp. install.sh is interactive or you can supply all information on command line. I don’t want it to update my .bash_profile or .bashrc but want to see what it puts there, so just providing a temporary /tmp/gcloud.sh to have a lookt at it
[opc@a ~]$ /var/tmp/google-cloud-sdk/install.sh --usage-reporting true --screen-reader false --rc-path /tmp/gcloud.sh --command-completion true --path-update true --override-components
Welcome to the Google Cloud SDK!
Your current Cloud SDK version is: 321.0.0
The latest available version is: 321.0.0
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ Components │
├───────────────┬──────────────────────────────────────────────────────┬──────────────────────────┬──────────┤
│ Status │ Name │ ID │ Size │
├───────────────┼──────────────────────────────────────────────────────┼──────────────────────────┼──────────┤
...
│ Installed │ BigQuery Command Line Tool │ bq │ < 1 MiB │
│ Installed │ Cloud SDK Core Libraries │ core │ 15.9 MiB │
│ Installed │ Cloud Storage Command Line Tool │ gsutil │ 3.5 MiB │
└───────────────┴──────────────────────────────────────────────────────┴──────────────────────────┴──────────┘
[opc@a ~]$ cat /tmp/gcloud.tmp
# The next line updates PATH for the Google Cloud SDK.
if [ -f '/var/tmp/google-cloud-sdk/path.bash.inc' ]; then . '/var/tmp/google-cloud-sdk/path.bash.inc'; fi
# The next line enables shell command completion for gcloud.
if [ -f '/var/tmp/google-cloud-sdk/completion.bash.inc' ]; then . '/var/tmp/google-cloud-sdk/completion.bash.inc'; fi
As you can see, I mentioned nothing for –override-components and the default is gsutil, core and bq
This is the most simple cloud CLI I ever seen. Just type: gcloud init
(/var/tmp/google-cloud-sdk/bin/gcloud in my temporary installation) and it gives you an URL where you can get the verification code, using the web console authentication. Then you pick the cloud project and, optionally, a default region and zone. Those default informations are stored in: ~/.config/gcloud/configurations/config_default
and the credentials are in a sqllite database in ~/.config/gcloud/credentials.db
Sample SQL data
Gerald Venzl has recently published some free to use data about the world’s countries, capitals, and currencies. What I like with this data set is that, in addition to providing the CSV, Gerald have managed to provide a unique DDL + DML to create this data in SQL databases. And this works in the most common databases despite the fact that, beyond the SQL standard, data types and syntax is different in each engine.
Christmas comes early for #data geeks! Thanks to the help of my lovely wife, I present you with #free to use, @creativecommons licensed data about our world's countries, capitals, and currencies! We hope you enjoy and wish you Happy Holidays!https://t.co/zsRpZ4PXP2 pic.twitter.com/yQDTmB6BMv
— Gerald Venzl 🚀 (@GeraldVenzl) December 14, 2020
Google Spanner has a SQL-like API but I cannot run this without a few changes. But just a few, thanks to many recent improvements. And loading this data set will be the occasion to show those new features.
Primary key
Here is the DDL to create the first table, REGIONS:
/*********************************************/
/***************** REGIONS *******************/
/*********************************************/
CREATE TABLE regions
(
region_id VARCHAR(2) NOT NULL,
name VARCHAR(13) NOT NULL,
CONSTRAINT regions_pk
PRIMARY KEY (region_id)
);
In order to run this in Google Spanner, I change VARCHAR to STRING and I move the PRIMARY KEY declaration out of the relational properties:
CREATE TABLE regions
(
region_id STRING(2) NOT NULL,
name STRING(13) NOT NULL
)
PRIMARY KEY (region_id)
;
It may be surprising to have the PRIMARY KEY declaration at this place but, because Google Spanner is a distributed database, the primary key is also a storage attribute. And it is mandatory as sharding is done by range partitioning on the primary key. Well, I would prefer to stay compatible with SQL and have, if needed, an additional organization clause. But Spanner is one of the first database trying to bring SQL to NoSQL and was originally designed to be used internally (like Google object storage matadata), providing SQL database benefits (SQL, ACID, joins,…) with the same scalability as distributed NoSQL databases. So compatibility with other SQL databases was probably not a priority.
Note that the NOT NULL constraint is allowed and we will see more about columns constraints later.
I have removed the comments because this is not allowed in Google Spanner. I don’t understand that, but remember that it takes its roots in NoSQL where the API calls are embedded in the code, and not in scripts, and the code has its own comments.
Foreign key
The second table is COUNTRIES and a country belongs to a region from the REGION table.
/*********************************************/
/**************** COUNTRIES ******************/
/*********************************************/
CREATE TABLE countries
(
country_id VARCHAR(3) NOT NULL,
country_code VARCHAR(2) NOT NULL,
name VARCHAR(100) NOT NULL,
official_name VARCHAR(200),
population NUMERIC(10),
area_sq_km NUMERIC(10,2),
latitude NUMERIC(8,5),
longitude NUMERIC(8,5),
timezone VARCHAR(40),
region_id VARCHAR(2) NOT NULL,
CONSTRAINT countries_pk
PRIMARY KEY (country_id),
CONSTRAINT countries_regions_fk001
FOREIGN KEY (region_id) REFERENCES regions (region_id)
);
CREATE INDEX countries_regions_fk001 ON countries (region_id);
On the datatypes, I’ll change VARCHAR to STRING and now we have a NUMERIC datatype in Spanner (was only IEEE 754 float) but NUMERIC has a fixed scale and precision (38,9) I’ll probably come back to it in another post. But there are still many limitations with NUMERIC (cannot create index on it, not easy to map when importing,…). It is definitely not a good choice here for areas, latitude and longitude. But I keep it just for DDL compatibility.
I move the PRIMARY KEY definition. But the most important here is actually about not changing the referential constraint at all:
CREATE TABLE countries
(
country_id STRING(3) NOT NULL,
country_code STRING(2) NOT NULL,
name STRING(100) NOT NULL,
official_name STRING(200),
population NUMERIC,
area_sq_km NUMERIC,
latitude NUMERIC,
longitude NUMERIC,
timezone STRING(40),
region_id STRING(2) NOT NULL,
CONSTRAINT countries_regions_fk001
FOREIGN KEY (region_id) REFERENCES regions (region_id)
)
PRIMARY KEY (country_id)
;
Before March 2020 The only possible referential integrity way actually a storage clause (at the same place as the PRIMARY KEY declaration) because referential integrity is not something easy in a distributed database. Because you distribute to scale and that works well only when your transaction is single-shard. This is why, initially, referential integrity was not a FOREIGN KEY but a compound PRIMARY KEY interleaved with the parent PRIMARY KEY. But we will see INTERLEAVE IN PARENT later. Here, COUTRIES has its own primary key, and then its own sharding scheme. That’ also mean that inserting a new country may have to check the parent key (region) in another shard. We will look at performance in another post.
When we declare a foreign key in Google Spanner, an index on it is created, then I didn’t copy the CREATE INDEX statement.
Check constraints
/*********************************************/
/***************** CITIES ********************/
/*********************************************/
CREATE TABLE cities
(
city_id VARCHAR(7) NOT NULL,
name VARCHAR(100) NOT NULL,
official_name VARCHAR(200),
population NUMERIC(8),
is_capital CHAR(1) DEFAULT 'N' NOT NULL,
latitude NUMERIC(8,5),
longitude NUMERIC(8,5),
timezone VARCHAR(40),
country_id VARCHAR(3) NOT NULL,
CONSTRAINT cities_pk
PRIMARY KEY (city_id),
CONSTRAINT cities_countries_fk001
FOREIGN KEY (country_id) REFERENCES countries (country_id),
CONSTRAINT cities_is_capital_Y_N_check001
CHECK (is_capital IN ('Y','N'))
);
CREATE INDEX cities_countries_fk001 ON cities (country_id);
In addition to the datatypes we have seen earlier I’ll transform CHAR to STRING, but I have to remove the DEFAULT declaration. Spanner recently introduced generated columns but those are always calculated, they cannot substitute to DEFAULT.
We declare check constraints since Oct. 2020 and I keep the same declaration. As far as I know they are not used by the optimizer but only to validate the data ingested.
I have a foreign key to COUNTRIES which I keep as non-interleaved. Because the COUNTRY_ID is not part of the CITIES primary key, and maybe because my data model may have to cope with cities changing to another country (geopolitical immutability).
CREATE TABLE cities
(
city_id STRING(7) NOT NULL,
name STRING(100) NOT NULL,
official_name STRING(200),
population NUMERIC,
is_capital STRING(1) NOT NULL,
latitude NUMERIC,
longitude NUMERIC,
timezone STRING(40),
country_id STRING(3) NOT NULL,
CONSTRAINT cities_countries_fk001
FOREIGN KEY (country_id) REFERENCES countries (country_id),
CONSTRAINT cities_is_capital_Y_N_check001
CHECK (is_capital IN ('Y','N'))
)
PRIMARY KEY (city_id)
;
Again, the index on COUNTRY_ID is created implicitely.
Interleaved
/*********************************************/
/***************** CURRENCIES ****************/
/*********************************************/
CREATE TABLE currencies
(
currency_id VARCHAR(3) NOT NULL,
name VARCHAR(50) NOT NULL,
official_name VARCHAR(200),
symbol VARCHAR(18) NOT NULL,
CONSTRAINT currencies_pk
PRIMARY KEY (currency_id)
);
/*********************************************/
/*********** CURRENCIES_COUNTRIES ************/
/*********************************************/
CREATE TABLE currencies_countries
(
currency_id VARCHAR(3) NOT NULL,
country_id VARCHAR(3) NOT NULL,
CONSTRAINT currencies_countries_pk
PRIMARY KEY (currency_id, country_id),
CONSTRAINT currencies_countries_currencies_fk001
FOREIGN KEY (currency_id) REFERENCES currencies (currency_id),
CONSTRAINT currencies_countries_countries_fk002
FOREIGN KEY (country_id) REFERENCES countries(country_id)
);
The CURRENCIES_COUNTRIES is the implementation of many-to-many relationship as a country may have multiple currencies and a currency can be used in multiple country. The primary key is a concatenation of the foreign keys. Here I’ll decide that referential integrity is a bit stronger and the list of currencies will be stored in each country, like storing it pre-joined for performance reason. If you come from Oracle, you may see this INTERLEAVE IN PARENT as a table CLUSTER but on a partitioned table. If you come from DynamoDB you may see the of it as the Adjacency lists modeling in the single-table design.
CREATE TABLE currencies
(
currency_id STRING(3) NOT NULL,
name STRING(50) NOT NULL,
official_name STRING(200),
symbol STRING(18) NOT NULL,
)
PRIMARY KEY (currency_id)
;
CREATE TABLE currencies_countries
(
currency_id STRING(3) NOT NULL,
country_id STRING(3) NOT NULL,
CONSTRAINT currencies_countries_countries_fk002
FOREIGN KEY (country_id) REFERENCES countries(country_id)
)
PRIMARY KEY (currency_id, country_id)
, INTERLEAVE IN PARENT currencies ON DELETE CASCADE;
Here, the many-to-many association between CURRENCIES and COUNTRIES is materialized as a composition with CURRENCIES, stored with it (INTERLEAVE), and removed with it (ON DELETE CASCADE). Note that I did that for the demo because CURRENCY_ID was first in the primary key declaration, but you may think more about data distribution and lifecycle when deciding on interleaving. Google Spanner partitions by range, and this means that all CURRENCIES_COUNTRIES associations will be stored together, in the same shard (called “split” in Spanner) for the same CURRENCY_ID.
Multi-region instance
There are many new multi-region configurations, within the same continent or distributed over multiple ones:
gcloud spanner instance-configs list
NAME DISPLAY_NAME
asia1 Asia (Tokyo/Osaka/Seoul)
eur3 Europe (Belgium/Netherlands)
eur5 Europe (London/Belgium/Netherlands)
eur6 Europe (Netherlands, Frankfurt)
nam-eur-asia1 United States, Europe, and Asia (Iowa/Oklahoma/Belgium/Taiwan)
nam10 United States (Iowa/Salt Lake/Oklahoma)
nam11 United States (Iowa, South Carolina, Oklahoma)
nam3 United States (Northern Virginia/South Carolina)
nam6 United States (Iowa/South Carolina/Oregon/Los Angeles)
nam7 United States (Iowa, Northern Virginia, Oklahoma)
nam8 United States (Los Angeles, Oregon, Salt Lake City)
nam9 United States (Northern Virginia, Iowa, South Carolina, Oregon)
regional-asia-east1 asia-east1
regional-asia-east2 asia-east2
regional-asia-northeast1 asia-northeast1
regional-asia-northeast2 asia-northeast2
regional-asia-northeast3 asia-northeast3
regional-asia-south1 asia-south1
regional-asia-southeast1 asia-southeast1
regional-asia-southeast2 asia-southeast2
regional-australia-southeast1 australia-southeast1
regional-europe-north1 europe-north1
regional-europe-west1 europe-west1
regional-europe-west2 europe-west2
regional-europe-west3 europe-west3
regional-europe-west4 europe-west4
regional-europe-west6 europe-west6
regional-northamerica-northeast1 northamerica-northeast1
regional-southamerica-east1 southamerica-east1
regional-us-central1 us-central1
regional-us-east1 us-east1
regional-us-east4 us-east4
regional-us-west1 us-west1
regional-us-west2 us-west2
regional-us-west3 us-west3
regional-us-west4 us-west4
I’ll use the latest dual-region in my continent, eur6, added on Dec. 2020 which has two read-write regions (Netherlands, Frankfurt) and the witness region in Zurich. Yes, this neutral position of Switzerland is a perfect fit in the distributed quorum, isn’t it? 😉
time gcloud spanner instances create franck --config eur6 --nodes=3 --description Franck
Creating instance...done.
real 0m5.128s
user 0m0.646s
sys 0m0.079s
The instance is created, and we can create multiple database in it (there is no schemas, so database is the right logical isolation between database objects)
time gcloud spanner databases create test --instance=franck --ddl "
CREATE TABLE regions
(
region_id STRING(2) NOT NULL,
name STRING(13) NOT NULL
)
PRIMARY KEY (region_id)
;
CREATE TABLE countries
(
country_id STRING(3) NOT NULL,
country_code STRING(2) NOT NULL,
name STRING(100) NOT NULL,
official_name STRING(200),
population NUMERIC,
area_sq_km NUMERIC,
latitude NUMERIC,
longitude NUMERIC,
timezone STRING(40),
region_id STRING(2) NOT NULL,
CONSTRAINT countries_regions_fk001
FOREIGN KEY (region_id) REFERENCES regions (region_id)
)
PRIMARY KEY (country_id)
;
CREATE TABLE cities
(
city_id STRING(7) NOT NULL,
name STRING(100) NOT NULL,
official_name STRING(200),
population NUMERIC,
is_capital STRING(1) NOT NULL,
latitude NUMERIC,
longitude NUMERIC,
timezone STRING(40),
country_id STRING(3) NOT NULL,
CONSTRAINT cities_countries_fk001
FOREIGN KEY (country_id) REFERENCES countries (country_id),
CONSTRAINT cities_is_capital_Y_N_check001
CHECK (is_capital IN ('Y','N'))
)
PRIMARY KEY (city_id)
;
CREATE TABLE currencies
(
currency_id STRING(3) NOT NULL,
name STRING(50) NOT NULL,
official_name STRING(200),
symbol STRING(18) NOT NULL,
)
PRIMARY KEY (currency_id)
;
CREATE TABLE currencies_countries
(
currency_id STRING(3) NOT NULL,
country_id STRING(3) NOT NULL,
CONSTRAINT currencies_countries_countries_fk002
FOREIGN KEY (country_id) REFERENCES countries(country_id)
)
PRIMARY KEY (currency_id, country_id)
, INTERLEAVE IN PARENT currencies ON DELETE CASCADE;
"
ERROR: (gcloud.spanner.databases.create) INVALID_ARGUMENT: Error parsing Spanner DDL statement: \n : Syntax error on line 1, column 1: Encountered \'EOF\' while parsing: ddl_statement
- '@type': type.googleapis.com/google.rpc.LocalizedMessage
locale: en-US
message: |-
Error parsing Spanner DDL statement:
: Syntax error on line 1, column 1: Encountered 'EOF' while parsing: ddl_statement
No idea why it didn’t parse my DDL. The same in the console works, so this is how I’ve created those tables. Now re-reading this and the problem may be only that I start with an newline here before the first CREATE.
My database is ready for DDL and DML, provisioned in a few seconds.
Foreign Key indexes
You mave seen that I removed the CREATE INDEX that was in the original DDL. This is because an index is created automatically on the foreign key (which makes sense, we want to avoid full table scans at all prize in a distributed database).
gcloud spanner databases ddl update test --instance=franck --ddl="CREATE INDEX countries_regions_fk001 ON countries (region_id)"
Schema updating...failed.
ERROR: (gcloud.spanner.databases.ddl.update) Duplicate name in schema: countries_regions_fk001.
Trying to create an index with the same name as the foreign key is rejected as “duplicate name”. However, when looking at the ddl:
gcloud spanner databases ddl describe test --instance=franck | grep -i "CREATE INDEX"
Shows no index. And trying to query explicitly through this index with this name is rejected:
gcloud spanner databases execute-sql test --instance=franck --query-mode=PLAN \
--sql "select count(region_id) from countries@{FORCE_INDEX=countries_regions_fk001}"
ERROR: (gcloud.spanner.databases.execute-sql) INVALID_ARGUMENT: The table countries does not have a secondary index called countries_regions_f
k001
However this index exists, with another name. Let’s do an explain plan when querying this column only:
gcloud spanner databases execute-sql test --instance=franck --query-mode=PLAN \
--sql "select count(region_id) from countries"
RELATIONAL Serialize Result
|
+- RELATIONAL Aggregate
| call_type: Global, iterator_type: Stream, scalar_aggregate: true
| |
| +- RELATIONAL Distributed Union
| | subquery_cluster_node: 3
| | |
| | +- RELATIONAL Aggregate
| | | call_type: Local, iterator_type: Stream, scalar_aggregate: true
| | | |
| | | +- RELATIONAL Distributed Union
| | | | call_type: Local, subquery_cluster_node: 5
| | | | |
| | | | \- RELATIONAL Scan
| | | | Full scan: true, scan_target: IDX_countries_region_id_1D2B1A686087F93F, scan_type: IndexScan
| | | |
| | | \- SCALAR Function
| | | COUNT(1)
| | | |
| | | \- SCALAR Constant
| | | 1
| | |
| | \- SCALAR Constant
| | true
| |
| \- SCALAR Function
| COUNT_FINAL($v1)
| |
| \- SCALAR Reference
| $v1
|
\- SCALAR Reference
$agg1
The foreign key index name is: IDX_countries_region_id_1D2B1A686087F93F
gcloud spanner databases execute-sql test --instance=franck --query-mode=PLAN \
--sql "select count(region_id) from countries@{FORCE_INDEX=IDX_countries_region_id_1D2B1A686087F93F}" \
| grep scan
| | | | Full scan: true, scan_target: IDX_countries_region_id_1D2B1A686087F93F, scan_type: IndexScan
I can use this index name here. Apparently, the index that is implicitly created with the foreign key has an internal name, but also reserves the constraint name in the index namespace. Let’s validate that the initial error was about the name of the index and not the same columns:
gcloud spanner databases ddl update test --instance=franck \
--ddl="CREATE INDEX a_silly_redundant_index ON countries (region_id)"
Schema updating...done.
This works, I can create a secondary index on the foreign key columns
gcloud spanner databases execute-sql test --instance=franck --query-mode=PLAN \
--sql "select count(region_id) from countries"\
| grep scan
| | | | Full scan: true, scan_target: a_silly_redundant_index, scan_type: IndexScan
Querying without mentioning the index shows that it can be used instead of the implicit one. Yes, Google Spanner has now an optimizer that can decide to use a secondary index. But I’ll come back to that in a future blog post. Why using this new index rather than the one created implicitly, as they have the same cost? I don’t know but I’ve started it with an “a” in case alphabetical order wins…
gcloud spanner databases ddl describe test --instance=franck | grep -i "CREATE INDEX"
CREATE INDEX a_silly_redundant_index ON countries(region_id);
gcloud spanner databases ddl update test --instance=franck \
--ddl="DROP INDEX a_silly_redundant_index"
Schema updating...done.
I remove this index which has no reason to be there.
insert
Executing multiple DML statements at once is not possible. It is possible to insert multiple rows into one table like this:
INSERT INTO regions (region_id, name) VALUES
('AF', 'Africa')
, ('AN', 'Antarctica')
, ('AS', 'Asia')
, ('EU', 'Europe')
, ('NA', 'North America')
, ('OC', 'Oceania')
, ('SA', 'South America')
;
However, the initial SQL file doesn’t insert into the same number of columns, like:
INSERT INTO cities (city_id, name, population, is_capital, latitude, longitude, country_id) VALUES ('AFG0001', 'Kabul', 4012000, 'Y', 34.52813, 69.17233, 'AFG');
INSERT INTO cities (city_id, name, official_name, population, is_capital, latitude, longitude, country_id) VALUES ('ATG0001', 'Saint John''s', 'Saint John’s', 21000, 'Y', 17.12096, -61.84329, 'ATG');
INSERT INTO cities (city_id, name, population, is_capital, latitude, longitude, country_id) VALUES ('ALB0001', 'Tirana', 476000, 'Y', 41.3275, 19.81889, 'ALB');
and then a quick replace is not easy. On this example you see something else. There are double quotes, the SQL way to escape quotes, but Spanner doesn’t like it.
Then, without writing a program to insert in bulk, here is what I did to keep the SQL statements from the source:
curl -s https://raw.githubusercontent.com/gvenzl/sample-data/master/countries-cities-currencies/install.sql \
| awk "/^INSERT INTO /{gsub(/''/,quote);print}" quote="\\\\\\\'" \
| while read sql ; do echo "$sql" ; gcloud spanner databases execute-sql test --instance=franck --sql="$sql" ; done \
| ts | tee insert.log
I just replaced the quote escaping ” by //. It is slow row-by-row but all rows are inserted with the original SQL.
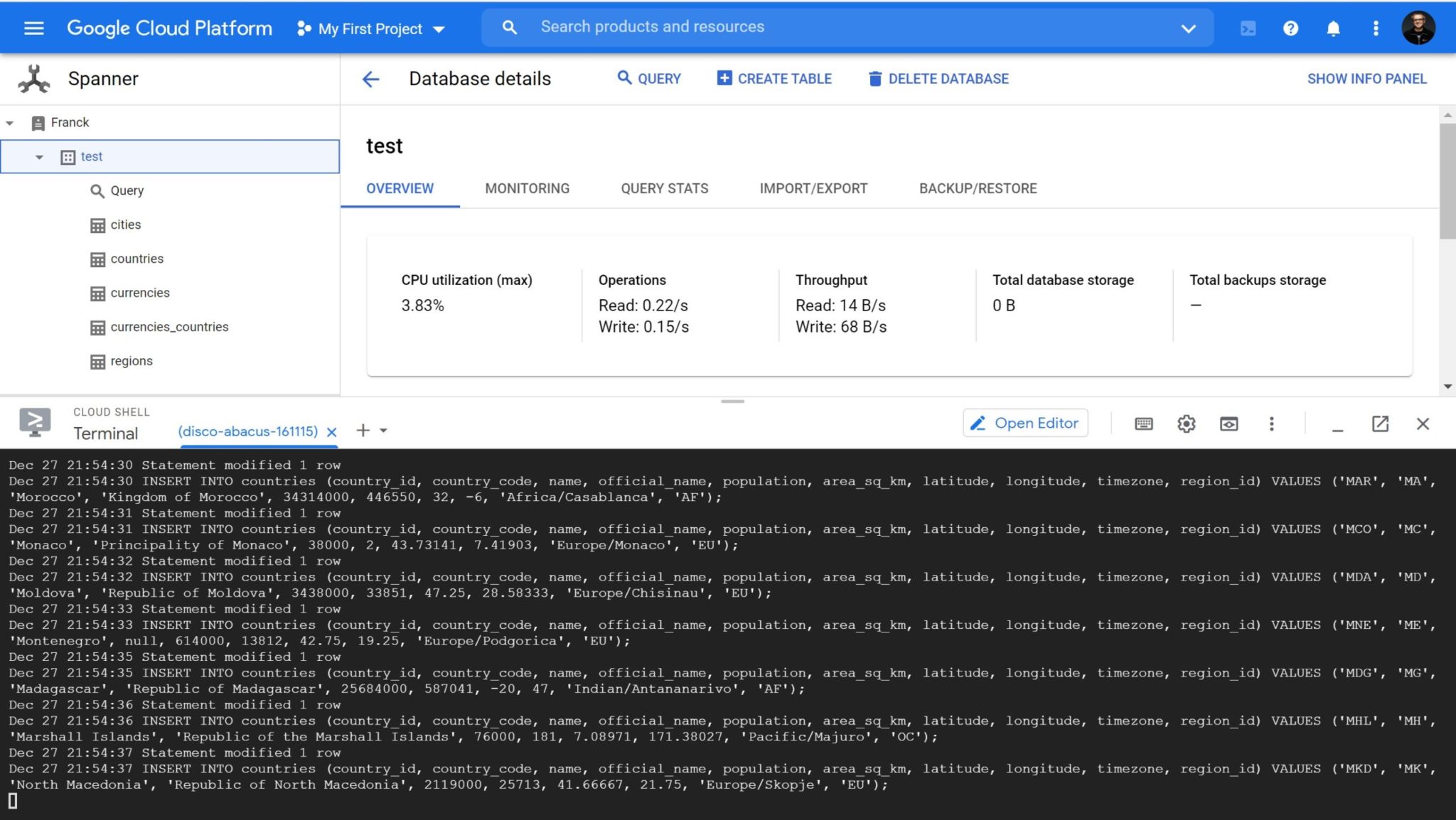
I have 3 nodes running, two in read-write in two regions (europe-west3 is “Frankfurt”, europe-west4 is “Netherlands”) and one acting as witness for the quorum (europe-west6 in Zürich).
select
With the sample data provided by Gerald, there’s a query to check the number of rows:
gcloud spanner databases execute-sql test --instance=franck --query-mode=NORMAL --sql "SELECT 'regions' AS Table, 7 AS provided,
COUNT(1) AS actual FROM regions
UNION ALL
SELECT 'countries' AS Table, 196 AS provided, COUNT(1) AS actual FROM countries
UNION ALL
SELECT 'cities' AS Table, 204 AS provided, COUNT(1) AS actual FROM cities
UNION ALL
SELECT 'currencies' AS Table, 146 AS provided, COUNT(1) AS actual FROM currencies
UNION ALL
SELECT 'currencies_countries' AS Table, 203 AS provided, COUNT(1) AS actual FROM currencies_countries;
"
Table provided actual
regions 7 7
countries 196 196
cities 204 204
currencies 146 146
currencies_countries 203 203
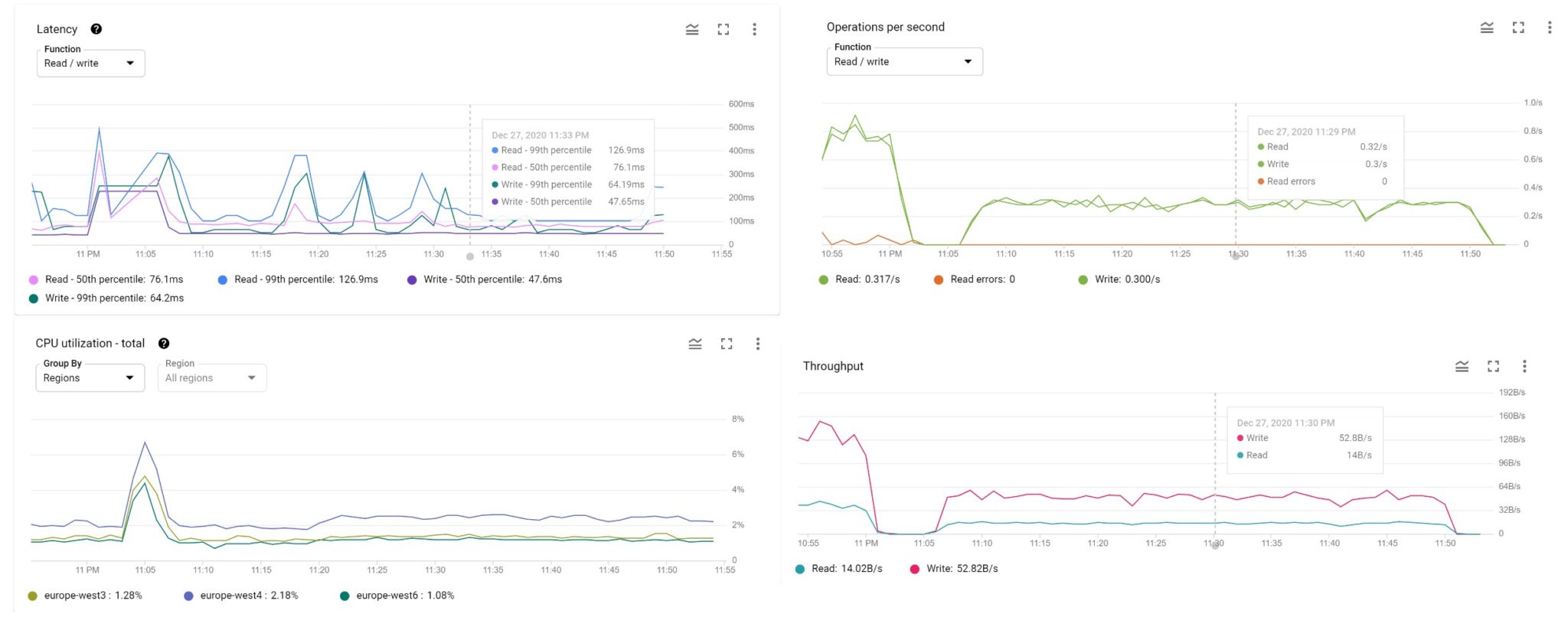
The result is correct. By curiosity, I’m running it with execution plan and statistics (query mode “PROFILE”):
gcloud spanner databases execute-sql test --instance=franck --query-mode=PROFILE --sql "SELECT 'regions' AS Table, 7 AS provided,
COUNT(1) AS actual FROM regions
UNION ALL
SELECT 'countries' AS Table, 196 AS provided, COUNT(1) AS actual FROM countries
UNION ALL
SELECT 'cities' AS Table, 204 AS provided, COUNT(1) AS actual FROM cities
UNION ALL
SELECT 'currencies' AS Table, 146 AS provided, COUNT(1) AS actual FROM currencies
UNION ALL
SELECT 'currencies_countries' AS Table, 203 AS provided, COUNT(1) AS actual FROM currencies_countries;
"
┌────────────────────┬────────────┬───────────────┬──────────────┬───────────────────┐
│ TOTAL_ELAPSED_TIME │ CPU_TIME │ ROWS_RETURNED │ ROWS_SCANNED │ OPTIMIZER_VERSION │
├────────────────────┼────────────┼───────────────┼──────────────┼───────────────────┤
│ 14.7 msecs │ 4.92 msecs │ 5 │ 756 │ 2 │
└────────────────────┴────────────┴───────────────┴──────────────┴───────────────────┘
RELATIONAL Serialize Result
(1 execution, 0.45 msecs total latency)
|
+- RELATIONAL Union All
| (1 execution, 0.44 msecs total latency)
| |
| +- RELATIONAL Union Input
| | |
| | +- RELATIONAL Compute
| | | |
| | | +- RELATIONAL Aggregate
| | | | (1 execution, 0.06 msecs total latency)
| | | | call_type: Global, iterator_type: Stream, scalar_aggregate: true
| | | | |
| | | | +- RELATIONAL Distributed Union
| | | | | (1 execution, 0.06 msecs total latency)
| | | | | subquery_cluster_node: 6
| | | | | |
| | | | | +- RELATIONAL Aggregate
| | | | | | (1 execution, 0.04 msecs total latency)
| | | | | | call_type: Local, iterator_type: Stream, scalar_aggregate: true
| | | | | | |
| | | | | | +- RELATIONAL Distributed Union
| | | | | | | (1 execution, 0.04 msecs total latency)
| | | | | | | call_type: Local, subquery_cluster_node: 8
| | | | | | | |
| | | | | | | \- RELATIONAL Scan
| | | | | | | (1 execution, 0.03 msecs total latency)
| | | | | | | Full scan: true, scan_target: regions, scan_type: TableScan
| | | | | | |
| | | | | | \- SCALAR Function
| | | | | | COUNT(1)
| | | | | | |
| | | | | | \- SCALAR Constant
| | | | | | 1
| | | | | |
| | | | | \- SCALAR Constant
| | | | | true
| | | | |
| | | | \- SCALAR Function
| | | | COUNT_FINAL($v1)
| | | | |
| | | | \- SCALAR Reference
| | | | $v1
| | | |
| | | +- SCALAR Constant
| | | | 'regions'
| | | |
| | | \- SCALAR Constant
| | | 7
| | |
| | +- SCALAR Reference
| | | $Table
| | |
| | +- SCALAR Reference
| | | $provided
| | |
| | \- SCALAR Reference
| | $actual
| |
| +- RELATIONAL Union Input
| | |
| | +- RELATIONAL Compute
| | | |
| | | +- RELATIONAL Aggregate
| | | | (1 execution, 0.1 msecs total latency)
| | | | call_type: Global, iterator_type: Stream, scalar_aggregate: true
| | | | |
| | | | +- RELATIONAL Distributed Union
| | | | | (1 execution, 0.1 msecs total latency)
| | | | | subquery_cluster_node: 23
| | | | | |
| | | | | +- RELATIONAL Aggregate
| | | | | | (1 execution, 0.09 msecs total latency)
| | | | | | call_type: Local, iterator_type: Stream, scalar_aggregate: true
| | | | | | |
| | | | | | +- RELATIONAL Distributed Union
| | | | | | | (1 execution, 0.09 msecs total latency)
| | | | | | | call_type: Local, subquery_cluster_node: 25
| | | | | | | |
| | | | | | | \- RELATIONAL Scan
| | | | | | | (1 execution, 0.08 msecs total latency)
| | | | | | | Full scan: true, scan_target: IDX_countries_region_id_1D2B1A686087F93F, scan_type: IndexScan
| | | | | | |
| | | | | | \- SCALAR Function
| | | | | | COUNT(1)
| | | | | | |
| | | | | | \- SCALAR Constant
| | | | | | 1
| | | | | |
| | | | | \- SCALAR Constant
| | | | | true
| | | | |
| | | | \- SCALAR Function
| | | | COUNT_FINAL($v2)
| | | | |
| | | | \- SCALAR Reference
| | | | $v2
| | | |
| | | +- SCALAR Constant
| | | | 'countries'
| | | |
| | | \- SCALAR Constant
| | | 196
| | |
| | +- SCALAR Reference
| | | $Table_1
| | |
| | +- SCALAR Reference
| | | $provided_1
| | |
| | \- SCALAR Reference
| | $actual_1
| |
| +- RELATIONAL Union Input
| | |
| | +- RELATIONAL Compute
| | | |
| | | +- RELATIONAL Aggregate
| | | | (1 execution, 0.12 msecs total latency)
| | | | call_type: Global, iterator_type: Stream, scalar_aggregate: true
| | | | |
| | | | +- RELATIONAL Distributed Union
| | | | | (1 execution, 0.11 msecs total latency)
| | | | | subquery_cluster_node: 40
| | | | | |
| | | | | +- RELATIONAL Aggregate
| | | | | | (1 execution, 0.11 msecs total latency)
| | | | | | call_type: Local, iterator_type: Stream, scalar_aggregate: true
| | | | | | |
| | | | | | +- RELATIONAL Distributed Union
| | | | | | | (1 execution, 0.1 msecs total latency)
| | | | | | | call_type: Local, subquery_cluster_node: 42
| | | | | | | |
| | | | | | | \- RELATIONAL Scan
| | | | | | | (1 execution, 0.09 msecs total latency)
| | | | | | | Full scan: true, scan_target: IDX_cities_country_id_35A7C9365B4BF943, scan_type: IndexScan
| | | | | | |
| | | | | | \- SCALAR Function
| | | | | | COUNT(1)
| | | | | | |
| | | | | | \- SCALAR Constant
| | | | | | 1
| | | | | |
| | | | | \- SCALAR Constant
| | | | | true
| | | | |
| | | | \- SCALAR Function
| | | | COUNT_FINAL($v3)
| | | | |
| | | | \- SCALAR Reference
| | | | $v3
| | | |
| | | +- SCALAR Constant
| | | | 'cities'
| | | |
| | | \- SCALAR Constant
| | | 204
| | |
| | +- SCALAR Reference
| | | $Table_2
| | |
| | +- SCALAR Reference
| | | $provided_2
| | |
| | \- SCALAR Reference
| | |
| | \- SCALAR Reference
| | $actual_2
| |
| +- RELATIONAL Union Input
| | |
| | +- RELATIONAL Compute
| | | |
| | | +- RELATIONAL Aggregate
| | | | (1 execution, 0.08 msecs total latency)
| | | | call_type: Global, iterator_type: Stream, scalar_aggregate: true
| | | | |
| | | | +- RELATIONAL Distributed Union
| | | | | (1 execution, 0.08 msecs total latency)
| | | | | subquery_cluster_node: 57
| | | | | |
| | | | | +- RELATIONAL Aggregate
| | | | | | (1 execution, 0.07 msecs total latency)
| | | | | | call_type: Local, iterator_type: Stream, scalar_aggregate: true
| | | | | | |
| | | | | | +- RELATIONAL Distributed Union
| | | | | | | (1 execution, 0.07 msecs total latency)
| | | | | | | call_type: Local, subquery_cluster_node: 59
| | | | | | | |
| | | | | | | \- RELATIONAL Scan
| | | | | | | (1 execution, 0.06 msecs total latency)
| | | | | | | Full scan: true, scan_target: currencies, scan_type: TableScan
| | | | | | |
| | | | | | \- SCALAR Function
| | | | | | COUNT(1)
| | | | | | |
| | | | | | \- SCALAR Constant
| | | | | | 1
| | | | | |
| | | | | \- SCALAR Constant
| | | | | true
| | | | |
| | | | \- SCALAR Function
| | | | COUNT_FINAL($v4)
| | | | |
| | | | \- SCALAR Reference
| | | | $v4
| | | | $v4 [49/9050]
| | | |
| | | +- SCALAR Constant
| | | | 'currencies'
| | | |
| | | \- SCALAR Constant
| | | 146
| | |
| | +- SCALAR Reference
| | | $Table_3
| | |
| | +- SCALAR Reference
| | | $provided_3
| | |
| | \- SCALAR Reference
| | $actual_3
| |
| +- RELATIONAL Union Input
| | |
| | +- RELATIONAL Compute
| | | |
| | | +- RELATIONAL Aggregate
| | | | (1 execution, 0.08 msecs total latency)
| | | | call_type: Global, iterator_type: Stream, scalar_aggregate: true
| | | | |
| | | | +- RELATIONAL Distributed Union
| | | | | (1 execution, 0.08 msecs total latency)
| | | | | subquery_cluster_node: 74
| | | | | |
| | | | | +- RELATIONAL Aggregate
| | | | | | (1 execution, 0.08 msecs total latency)
| | | | | | call_type: Local, iterator_type: Stream, scalar_aggregate: true
| | | | | | |
| | | | | | +- RELATIONAL Distributed Union
| | | | | | | (1 execution, 0.07 msecs total latency)
| | | | | | | call_type: Local, subquery_cluster_node: 76
| | | | | | | |
| | | | | | | \- RELATIONAL Scan
| | | | | | | (1 execution, 0.07 msecs total latency)
| | | | | | | Full scan: true, scan_target: IDX_currencies_countries_country_id_89DC8690B5CAF5C1, scan_type: IndexScan
| | | | | | |
| | | | | | \- SCALAR Function
| | | | | | COUNT(1)
| | | | | | |
| | | | | | \- SCALAR Constant
| | | | | | 1
| | | | | |
| | | | | \- SCALAR Constant
| | | | | \- SCALAR Constant [2/9050]
| | | | | true
| | | | |
| | | | \- SCALAR Function
| | | | COUNT_FINAL($v5)
| | | | |
| | | | \- SCALAR Reference
| | | | $v5
| | | |
| | | +- SCALAR Constant
| | | | 'currencies_countries'
| | | |
| | | \- SCALAR Constant
| | | 203
| | |
| | +- SCALAR Reference
| | | $Table_4
| | |
| | +- SCALAR Reference
| | | $provided_4
| | |
| | \- SCALAR Reference
| | $actual_4
| |
| +- SCALAR Reference
| | input_0
| |
| +- SCALAR Reference
| | input_1
| |
| \- SCALAR Reference
| input_2
|
+- SCALAR Reference
| $Table_5
|
+- SCALAR Reference
| $provided_5
|
\- SCALAR Reference
$actual_5
Table provided actual
regions 7 7
countries 196 196
cities 204 204
currencies 146 146
currencies_countries 203 203
That’s a long one: scans, joins, concatenation, with some operations run in parallel, projection, aggregation. But basically, it scans each table, or the index when available as we can count the rows from the index which is smaller.
delete instance
This Google Spanner instance costs me $9 per hour (the pricing https://cloud.google.com/spanner/pricing for this eur6 configuration is $3 per node per hour and $50 per 100GB per month). As the provisioning takes 1 minute, and I can copy-paste everything from this blog post, I terminate the instance when I’ve finished my tests.
However, in order to avoid to re-insert those rows, I would be nice to have a backup. Let’s try:
time gcloud spanner backups create sample-data --retention-period=30d --database test --instance=franck
Create request issued for: [sample-data]
Waiting for operation [projects/disco-abacus-161115/instances/franck/backups/sample-data/operations/_auto_op_05f73852e07ae49f] to complete...
⠛
done.
Created backup [sample-data].
real 2m37.593s
user 0m0.908s
sys 0m0.175s
gcloud spanner instances delete franck
Delete instance [franck]. Are you sure?
Do you want to continue (Y/n)? Y
ERROR: (gcloud.spanner.instances.delete) FAILED_PRECONDITION: Cannot delete instance projects/disco-abacus-161115/instances/franck because it contains backups. Please delete the backups before deleting the instance.
Yes, be careful, a backup is not a database backup here. Just a copy of the tables within the same instance, to be restored to the same region. This is documented of course: Backups reside in the same instance as their source database and cannot be moved. But you know how I find misleading to call that “backup” (a database is living and all the transactions must be backed-up, see What is a database backup). Anyway, this copy cannot help to save money by deleting the instance. The database is gone if I delete the instance and I cannot stop it. The solution is probably to export to the object storage, like a dump, but this will be for a future blog post, maybe.
gcloud spanner backups delete sample-data --instance=franck
You are about to delete backup [sample-data]
Do you want to continue (Y/n)? Y
Deleted backup [sample-data].
real 0m7.744s
user 0m0.722s
sys 0m0.056s
[opc@a tmp]$ gcloud spanner instances delete franck --quiet
The –quiet argument bypasses the interactive confirmation.
This test was with small volume, simple schema, from a SQL script that works as-is on the most common SQL databases. Here I had to adapt a few things, but the compatibility with RDBMS has improved a lot in the past year as we can have full referential integrity (foreign key not limited to hierarchical interleave) and logical independence where a secondary index can be used without explicitly mentioning it. Google Spanner is probably the most efficient distributed database when you develop with a NoSQL approach but want to benefit from some SQL features to get a more agile data model and easier integrity and transaction management. However, I don’t think you can port any existing SQL application easily, or even consider it as a general purpose SQL database. For this, you may look at YugaByteDB which uses the PostgreSQL upper layer on distributed database similar to Spanner. However, Spanner has probably the lowest latency for multi-shard operations as it has some cloud-vendor specific optimizations like TrueTime, for software and hardware synchronization.
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2024/03/AHI_web.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/07/ALK_MIN.jpeg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/05/JDE_Web-1-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/ADE_WEB-min-scaled.jpg)