One more blog in the Elasticsearch series (blogs list at the bottom), this time we will try to learn more together about indexing and search, more specifically answer the question: is Elasticsearch case-sensitive or case-insensitive?
To be honest, I had this question as a beginner and rapidly noticed that there are two sides to answer it. First the indexing, is it case-sensitive? How Elasticsearch behave to index a new document?
Then, the search, is it case-sensitive? How Elasticsearch behave to find and select document(s)?
Use case
Let’s first understand the default behavior, then we will see together how to adapt it to our need.
I will take the same example as my previous blog, I created the below document:
{
"title": "Index data with Elastic",
"category": "User Stories",
"author": {
"first_name": "David",
"last_name": "Diab"
}
}
Then, I searched for “Index” in the title field:
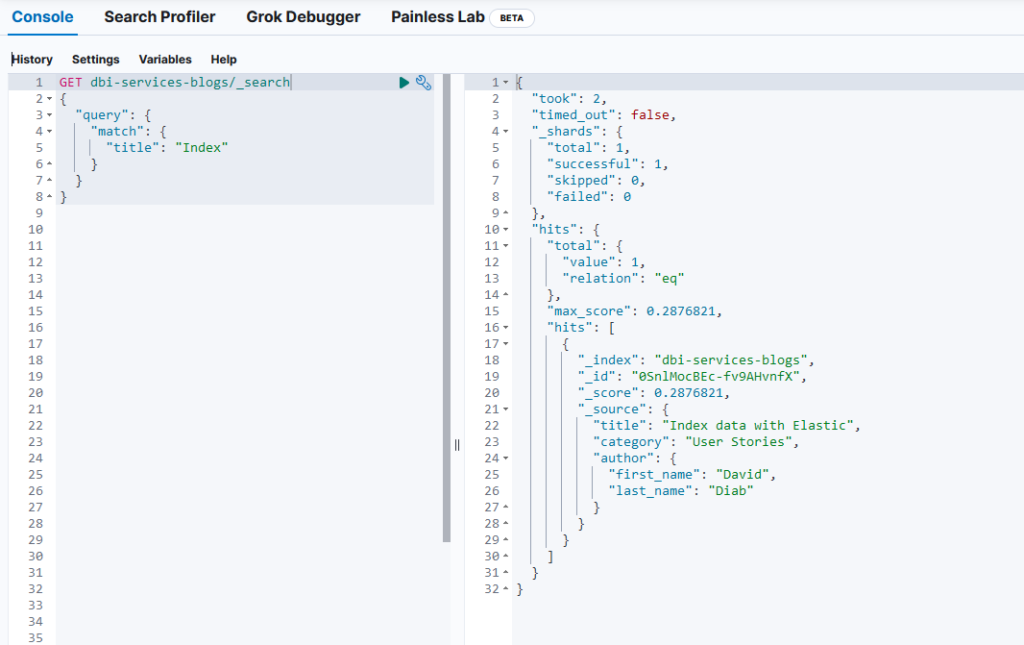
Let’s redo the same search but with “index” in lowercase, we get the same result:
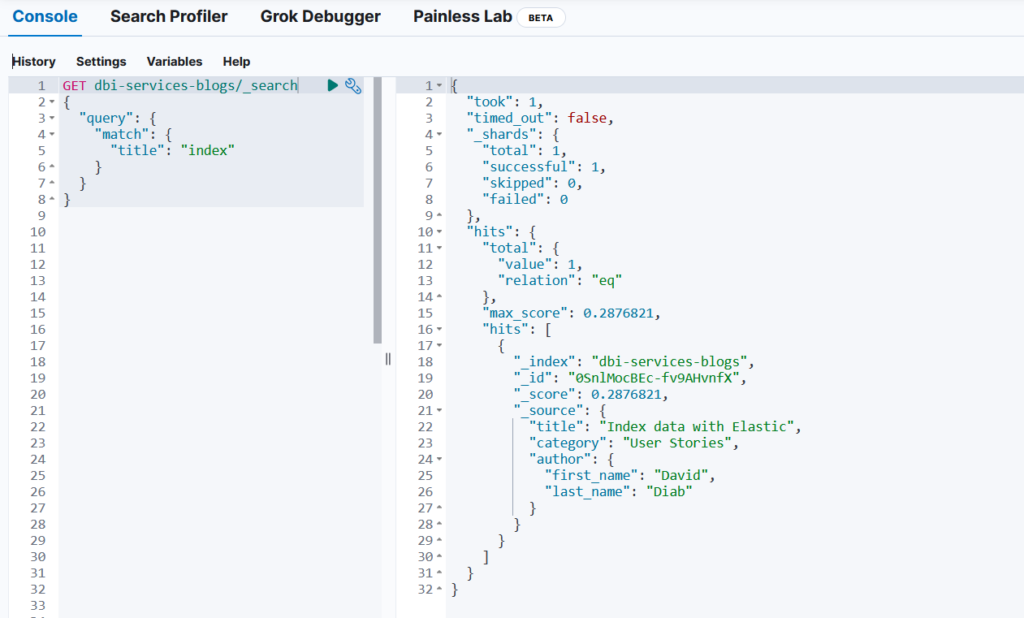
Why?
Indexing default behavior
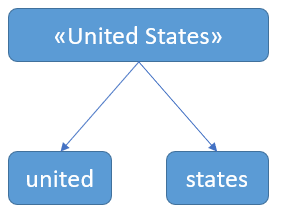
Based on above example, indexing and searches seem to be case-insensitive! In fact, this is due to a process called text analysis which occurs when your string fields are indexed. At index time, text strings are analyzed, by default, text analysis breaks up a text string into individual words (tokens) and lowercase those words, e.g.:
Search default behavior
Your query string is analyzed too, it makes search case-insensitive by default. An example is more than welcome to better understand:
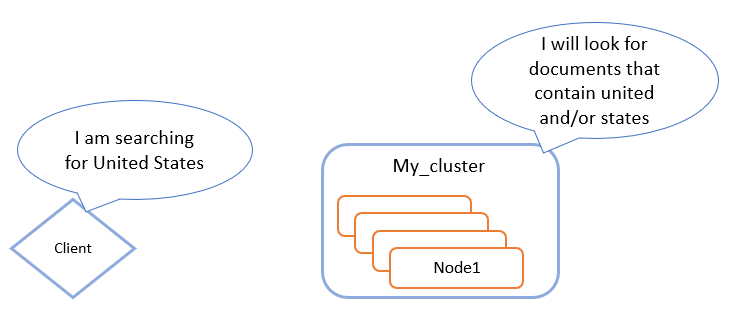
Please note that Elasticsearch calculates a score for each document found, which represent how relevant a document is in regards to the specific query. Elasticsearch uses BM25 as default scoring algorithm. We will discuss more about that in a next blog 😉
How to change the default behavior?
Analyzers
Text analysis is done by an analyzer, by default, Elasticsearch applies the standard analyzer. But, there are many other analyzers: whitespace, stop, pattern, language-specific analyzers, and much more.
In reality, the built-in analyzers work great for many use cases, but you may need to define your own custom analyzers which is possible with Elasticsearch.
Text and Keyword
Text analysis is great for full text search, which enables you to search for individual words in a case-insensitive manner. But, we understood from the example that some strings do not need to be analyzed, instead of “united” and “states” as separate values, we probably want to search “United States” as it is…
That is why Elasticsearch has two kinds of string data types:
- text (for full-text search): which is analyzed
- keyword (for exact searches): which is not analyzed
You can configure mapping depending on your need, but you have to know that Elasticsearch will give you both (text and keyword) by default. Let’s come back to our example and search for “index” in title.keyword:
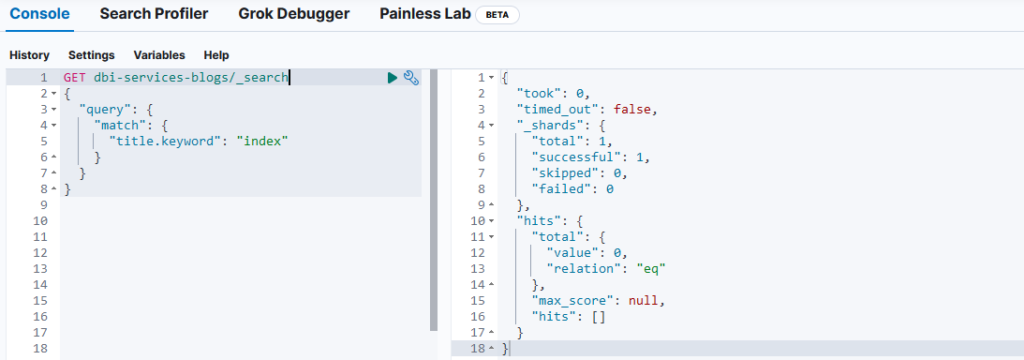
No document has been found, know let’s search for the exact content of title field:
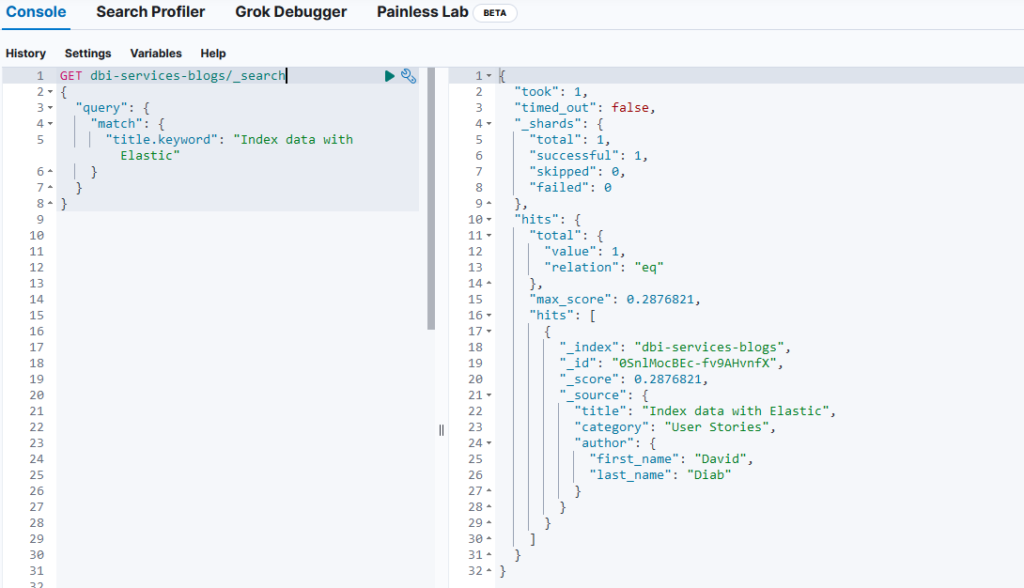
Our document has been found now as it match exactly the title field value!
Conclusion
We can now answer the question, saying that Elasticsearch is case-insensitive by default. There are many ways to change this behavior if it doesn’t match your need.
In next blogs, we will see together more about mappings and analyzers. In the meantime, don’t hesitate please ask questions and give your feedback if you are already using Elasticsearch.
Related topics:
Elasticsearch – Index, document, and search
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2022/09/DDI_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/GRE_web-min-scaled.jpg)
RuyLopez
24.07.2023I don't get the same results for the search query ='A' and 'a'. I don't understand why my result if different from yours.
PS. I use the lowercase token filter