A client submitted the following issues :
- Their database hosts multiple tables, including one table of approximately 1 TB, consisting of several billion rows. This table is continuously fed by various data sources. Additionally, it is also used to generate reports and charts based on the stored data.
- The client wanted to archive certain data to be able to delete it (selectively) without affecting the applications that use the table.
- They also wanted to reduce the duration of maintenance jobs for indexes, statistics, and those responsible for verifying data integrity.
During an audit of their environment, we also noticed that the database data files were hosted on a volume using an MBR partition type (which is limited to 2 TB).
2 tables were involved (but only one needed to be partitioned, the “Data” table) because we had a foreign key constraint between the tables. Here’s what the tables looked like :
| Table name | Columns name |
|---|---|
| Mode | ID |
| Data | Date, Value, Mode ID |
Possible solution : table partitioning
Partitioning in SQL Server is a technique used to divide large tables or indexes into smaller, more manageable pieces called partitions, while still being treated as a single logical entity. This improves performance, manageability, and scalability, especially for large datasets. In SQL Server, partitioning is done using a partition function which defines how data is distributed based on a column (e.g., date, ID) and a partition scheme which is a mapping mechanism that determines where partitions of a partitioned table or index will be physically stored. Queries benefit from partition elimination, meaning SQL Server scans only relevant partitions instead of the entire table, optimizing execution. This is widely used in data warehousing, archiving, and high-transaction databases to enhance query performance and simplify maintenance.
Production implementation ?
How can we implement this with minimal downtime since we cannot modify the main table, which is used continuously ?
In our case, we decided to create a new table that is an exact copy of the source table however this new table will be partitioned. Here’s how we proceeded :
Creating the corresponding filegroups
- We have one filegroup per year from 2010 to 2060. We extend up to 2060 to avoid creating a job that dynamically generates filegroups based on certain criteria.
- The files contained in these filegroups will be created in a new volume using the GPT partition type, allowing us to move the table to the new volume.
Creating the partition function
- The partition function will be based on a datetime column, which will determine the partition ID according to the input value.
Creating the partition scheme
This will define where the data is physically stored. The partition scheme maps the partition ID to the filegroups.
From here, we have at least two possibilities :
Create a partitioned (copy) table
- This table will have the same structure as the source table but without indexes.
- The new table will be partitioned using CREATE TABLE() ON partition_scheme().
- Initially, we copy data from the source table to the destination table up to a fixed date. This limit allows us to define a delta.
- We then build the indexes.
- The remaining data to be copied is the delta. The delta can be determined by selecting all rows with a date strictly greater than the copied data. This is easier when using the right indexes.
Using indexes (same process but without the last step)
- We build the corresponding indexes (before copying data), which are an exact copy of those in the source table.
- We copy data from the source table to the destination table up to a fixed date.
- We copy the delta.
- Finally, we switch the tables using the sp_rename stored procedure.
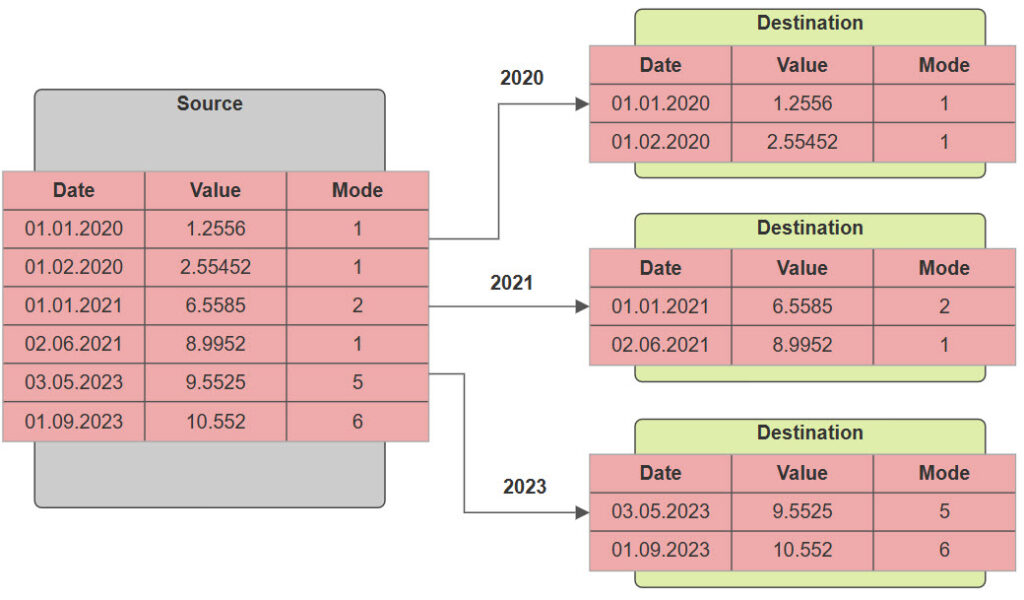
How can we copy the delta?
In our case, we stopped the application for a few minutes and then imported all rows from the fixed date onward (since writes were paused for a specific period, we copied the delta).
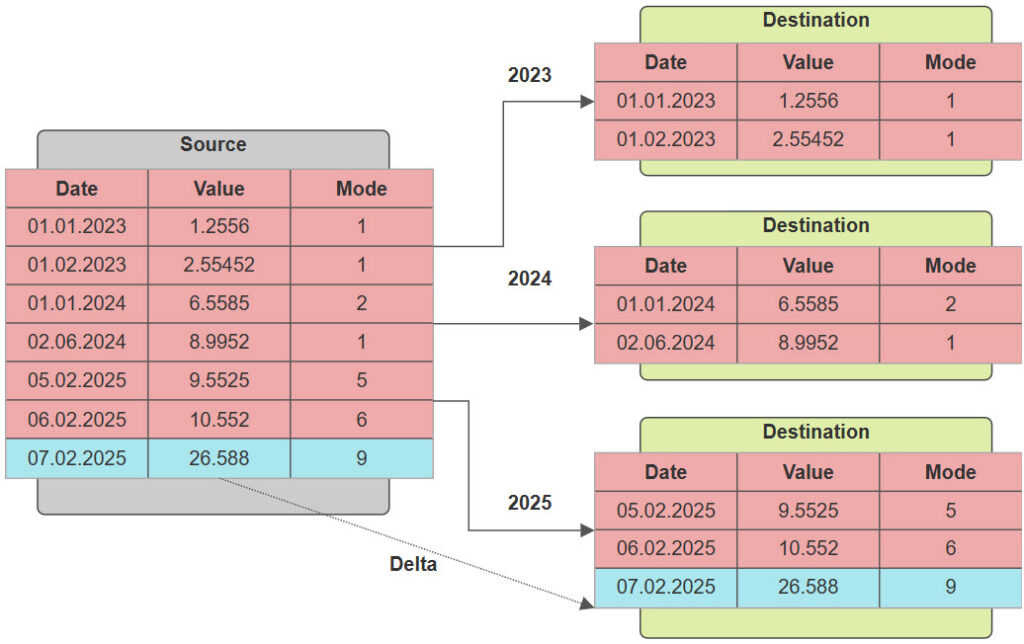
Implementation
In our client’s case, we have dependencies with another table through a foreign key constraint. This is why we have two tables appearing (however, the partitioned table is T_Data).
The code below reproduces the case we worked on.
Database creation :
USE master
GO
IF DB_ID('partitioning_demo') IS NOT NULL
BEGIN
ALTER DATABASE partitioning_demo SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE partitioning_demo
END
CREATE DATABASE partitioning_demo
ON PRIMARY
(
NAME = PARTITIONING_0_Dat,
FILENAME = 'S:\Data\partitioning_demo_0_Dat.mdf',
SIZE = 512MB,
FILEGROWTH = 512MB
)
LOG ON
(
name = PARTITIONING_0_Log,
filename = 'S:\Logs\partitioning_demo_0_Log.ldf',
size = 1024MB,
filegrowth = 512MB
)
GOTables creation :
USE partitioning_demo
GO
CREATE TABLE dbo.T_Mode
(
Mode_ID INT NOT NULL
CONSTRAINT PK_Mode_ID PRIMARY KEY(Mode_ID)
)
GO
CREATE TABLE dbo.T_Data
(
Data_Date DATETIME NOT NULL,
Data_Value DECIMAL(18,3) NOT NULL,
FK_Mode_ID INT NOT NULL
CONSTRAINT PK_T_Data_1 PRIMARY KEY(Data_Date, FK_Mode_ID)
CONSTRAINT FK_T_Data_T_Mode FOREIGN KEY(FK_Mode_ID) REFERENCES dbo.T_Mode(Mode_ID)
)
GO
CREATE NONCLUSTERED INDEX [NCI-1] ON dbo.T_Data(Data_Value)
GO
Generate some data for the T_Mode table :
USE partitioning_demo
GO
SET NOCOUNT ON
DECLARE @i INT = 0, @Min INT = 1, @Max INT = 300
WHILE @i <= @Max
BEGIN
INSERT INTO dbo.T_Mode (Mode_ID) VALUES (@i)
SET @i = @i + 1
END
GOGenerate some data for the T_Data table :
USE partitioning_demo
GO
SET NOCOUNT ON
DECLARE
@i BIGINT,
@NbLinesMax BIGINT,
@StartDateTime DATETIME,
@DataDate DATETIME,
@DataValue DECIMAL(18,3),
@NbLinesFKModeID INT,
@FKModeID INT
SET @i = 0
SET @NbLinesMax = 7884000 --7884000 - nb minutes in 14 years (from 2010 to 2024)
SET @StartDateTime = DATEADD(yy, DATEDIFF(yy, 0, DATEADD(year, -15, GETDATE())), 0) --We start in 2010 : 01.01.2010 00:00:00
SET @NbLinesFKModeID = (SELECT COUNT(*) FROM partitioning_demo.dbo.T_Mode) - 1
WHILE @i <= @NbLinesMax
BEGIN
SET @DataDate = DATEADD(mi, @i, @StartDateTime)
SET @DataValue = ROUND(RAND(CHECKSUM(NEWID())) * (100000000000000), 3) --Generate random values for the Data_Value column
SET @FKModeID = ABS(CHECKSUM(NEWID()) % (@NbLinesFKModeID - 1 + 1)) + 1 --Generate random values for the FK_Mode_ID column
INSERT INTO dbo.T_Data (Data_Date, Data_Value, FK_Mode_ID)
VALUES (@DataDate, @DataValue, @FKModeID)
SET @i = @i + 1
END
GOHere is what our data looks like :
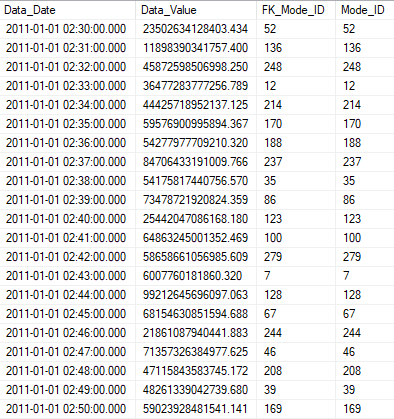
We create the corresponding filegroups. We create more filegroups than necessary to anticipate future insertions:
USE master
GO
DECLARE @Year INT = 2010, @YearLimit INT = 2060, @SQLCmd NVARCHAR(max) = ''
WHILE (@Year <= @YearLimit)
BEGIN
SET @SQLCmd = @SQLCmd+'ALTER DATABASE partitioning_demo ADD FILEGROUP PARTITIONING_FG_'+CAST(@Year AS NVARCHAR(4))+'; '
SET @SQLCmd = @SQLCmd+'ALTER DATABASE partitioning_demo ADD FILE (NAME = PARTITIONING_F_'+CAST(@Year AS NVARCHAR(4))+'_Dat, FILENAME = ''S:\Data\PARTITIONING_F_'+CAST(@Year AS NVARCHAR(4))+'_Dat.mdf'', SIZE = 64MB, FILEGROWTH = 64MB) TO FILEGROUP PARTITIONING_FG_'+CAST(@Year AS NVARCHAR(4))+';'
SET @Year = @Year + 1
END
--PRINT @SQLCMD
EXEC(@SQLCMD)We create our partition function to process data from 2010 to 2060 :
USE partitioning_demo
GO
DECLARE
@i INT = -15,
@PartitionYear DATETIME = 0,
@PartitionFunctionName NVARCHAR(50) = '',
@SQLCMD NVARCHAR(MAX) = ''
SET @PartitionFunctionName = 'PF_T_Data'
SET @SQLCMD = 'CREATE PARTITION FUNCTION ' + @PartitionFunctionName + ' (DATETIME) AS RANGE RIGHT FOR VALUES ('
WHILE (@i <= 35)
BEGIN
SET @PartitionYear = (SELECT DATEADD(yy, DATEDIFF(yy, 0, DATEADD(year, @i, GETDATE())), 0)) -- Start of a year, e.g. 2010-01-01 00:00:00.000
IF (@i <> 35)
BEGIN
SET @SQLCMD = @SQLCMD + '''' + CAST(@PartitionYear AS NVARCHAR(150)) + ''', '
END
ELSE
BEGIN
SET @SQLCMD = @SQLCMD + '''' + CAST(@PartitionYear AS NVARCHAR(150)) + ''')'
END
SET @i = @i + 1
END
--PRINT @SQLCMD
EXEC(@SQLCMD)We create our partition scheme:
USE partitioning_demo
GO
DECLARE
@PartitionFunctionName NVARCHAR(50) = '',
@PartitionSchemeName NVARCHAR(50) = '',
@SQLCMD NVARCHAR(MAX) = '',
@FGName NVARCHAR(100) = '',
@FGNames NVARCHAR(MAX) = ''
SET @PartitionFunctionName = 'PF_T_Data'
SET @PartitionSchemeName = 'PSCH_T_Data'
SET @SQLCMD = 'CREATE PARTITION SCHEME ' + @PartitionSchemeName + ' AS PARTITION ' + @PartitionFunctionName + ' TO ('
DECLARE filegroup_cursor CURSOR FOR
SELECT [name] FROM partitioning_demo.sys.filegroups ORDER BY data_space_id ASC
OPEN filegroup_cursor
FETCH filegroup_cursor INTO @FGName
WHILE @@FETCH_STATUS = 0
BEGIN
SET @FGNames = @FGNames + '[' + @FGName + '],'
FETCH filegroup_cursor INTO @FGName
END
CLOSE filegroup_cursor
DEALLOCATE filegroup_cursor
SET @FGNames = LEFT(@FGNames, LEN(@FGNames) - 1) --Remove the ',' character at the end
SET @SQLCMD = @SQLCMD + @FGNames + ')'
--PRINT @SQLCMD
EXEC(@SQLCMD)We will now create the new table. This is the one that will be partitioned and to which we will switch later :
USE partitioning_demo
GO
CREATE TABLE dbo.T_Data_Staging
(
Data_Date DATETIME NOT NULL,
Data_Value DECIMAL(18,3) NOT NULL,
FK_Mode_ID INT NOT NULL
) ON PSCH_T_Data(Data_Date)
GOWe now copy the data from the source table to the destination table. Since our table is a heap, we can use the query hint (TABLOCK). This enables minimal logging, optimal locking and parallel inserts (however, the recovery model must be bulk-logged or simple). In the case below, we only copy the year 2010 (for example) :
USE partitioning_demo
GO
DECLARE @YearToProcess INT, @BeginDataDate DATETIME, @EndDataDate DATETIME;
SET @YearToProcess = 2010
SET @BeginDataDate = DATEADD(yy, DATEDIFF(yy, 0, CAST(@YearToProcess AS NVARCHAR)), 0)
SET @EndDataDate = DATEADD(ms, -3, DATEADD(yy, DATEDIFF(yy, 0, CAST(@YearToProcess AS NVARCHAR)) + 1, 0))
INSERT INTO dbo.T_Data_Staging WITH (TABLOCK)
(
Data_Date,
Data_Value,
FK_Mode_ID
)
SELECT * FROM dbo.T_Data WHERE Data_Date BETWEEN @BeginDataDate AND @EndDataDate
GOHowever, it is possible to adjust the value of the @EndDataDate variable to copy the data up to the desired point.
We now create the corresponding indexes. These are indeed present in the source table. Additionally, these indexes are partitioned.
USE partitioning_demo
GO
ALTER TABLE dbo.T_Data_Staging ADD CONSTRAINT PK_T_Data_2 PRIMARY KEY(Data_Date, FK_Mode_ID)
GO
ALTER TABLE dbo.T_Data_Staging ADD CONSTRAINT FK_T_Data_T_Mode_2 FOREIGN KEY(FK_Mode_ID) REFERENCES dbo.T_Mode(Channel_ID)
GO
CREATE NONCLUSTERED INDEX [NCI-1-2] ON dbo.T_Data_Staging(Data_Value) ON PSCH_T_Data(Data_Date)
GOAnother possible strategy
From this point, another strategy is possible, which is as follows :
- We create the partitioned table.
- We create the corresponding indexes.
- We copy the data.
However, with this strategy, it is possible that the TempDB database may grow significantly. In this case, it is possible to use the following query hints :
- min_grant_percent
- max_grant_percent
We can also temporarily update statistics asynchronously. Once the vast majority of the data has been copied, we simply need to retrieve the delta and switch the tables. In our case, we had to stop the application for a few minutes before performing the switch as follows :
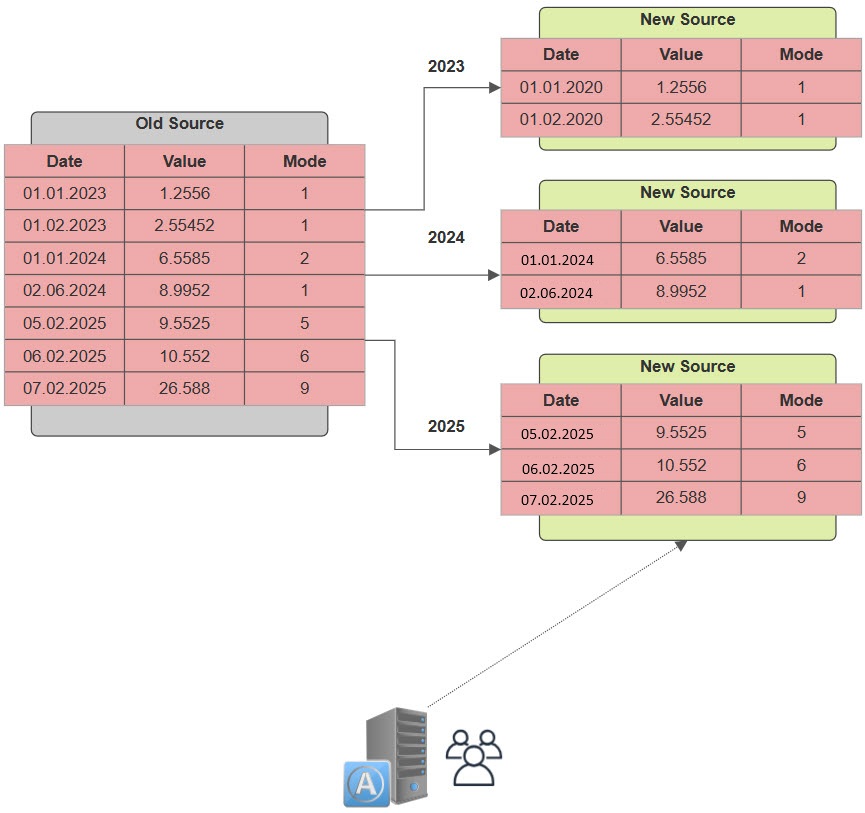
USE partitioning_demo
GO
BEGIN TRANSACTION Table_Switch
EXEC sp_rename 'dbo.T_Data', 'T_Data_Old'
EXEC sp_rename 'dbo.T_Data_Staging', 'T_Data'
COMMIT TRANSACTION Table_SwitchWe can then verify that our data has been properly distributed among the different filegroups:
SELECT
OBJECT_NAME(p.object_id) as obj_name,
f.name,
p.partition_number,
p.rows,
p.index_id,
CASE
WHEN p.index_id = 1 THEN 'CLUSTERED INDEX'
WHEN p.index_id >= 2 THEN 'NONCLUSTERED INDEX'
END AS index_info
FROM sys.system_internals_allocation_units a
JOIN sys.partitions p
ON p.partition_id = a.container_id
JOIN sys.filegroups f
on a.filegroup_id = f.data_space_id
WHERE p.object_id = OBJECT_ID (N'dbo.T_Data_Staging')
ORDER BY f.name ASC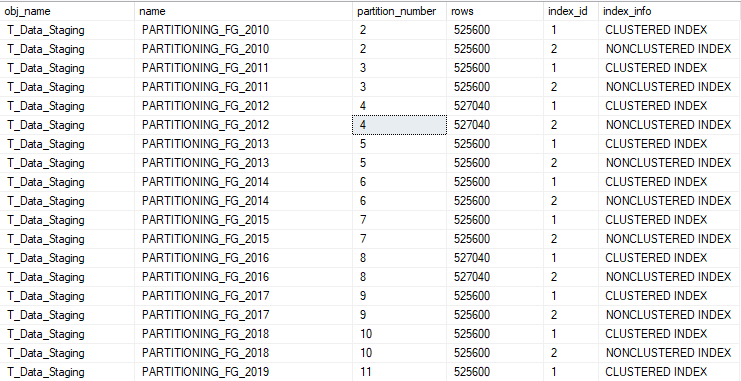
Database maintenance
For database maintenance, we can use Ola Hallengren’s solution (https://ola.hallengren.com).
Database integrity check
This solution allows us to verify data integrity and filter by filegroup. In our case, we have defined one filegroup per year, and the filegroup on which we write regularly is the one for the current year.
Thus, we could implement the following strategy to reduce the time needed for data integrity verification:
- Create a job that checks the integrity of the current filegroup once per day.
- Create a job that checks the integrity of other filegroups once per week.
USE partitioning_demo
GO
DECLARE @Databases NVARCHAR(100), @FilegroupsToCheck NVARCHAR(max)
SET @Databases = 'partitioning_demo'
SET @FilegroupsToCheck = @Databases + '.PARTITIONING_FG_' + CAST(YEAR(GETDATE()) AS NVARCHAR)
EXECUTE [dba_tools].[dbo].[DatabaseIntegrityCheck]
@Databases = @Databases,
@CheckCommands = 'CHECKFILEGROUP',
@FileGroups = @FilegroupsToCheck,
@LogToTable = 'Y'
GOThe verification of the other filegroups can be done as follows :
DECLARE @Database NVARCHAR(250), @FilegroupsToCheck NVARCHAR(MAX)
SET @Database = 'partitioning_demo'
SET @FilegroupsToCheck = 'ALL_FILEGROUPS, -' + @Database + '.PARTITIONING_FG_' + CAST(YEAR(GETDATE()) AS NVARCHAR)
EXECUTE [dba_tools].[dbo].[DatabaseIntegrityCheck]
@Databases = 'partitioning_demo',
@CheckCommands = 'CHECKFILEGROUP',
@FileGroups = @FilegroupsToCheck,
@LogToTable = 'Y'
GOIndex maintenance :
Index maintenance can be a long and resource-intensive operation in terms of CPU and I/O. Based on our research, there is no way to rebuild or reorganize a specific partition using Ola Hallengren’s solution.
Indeed, it may be beneficial to maintain only the current partition (the one where data is updated) and exclude the other partitions. To achieve this, the following example can be used:
USE partitioning_demo
GO
DECLARE
@IndexName NVARCHAR(250),
@IndexId INT,
@ObjectId INT,
@PartitionNumber INT,
@SchemaName NVARCHAR(50),
@TableName NVARCHAR(100),
@IndexFragmentationValue INT,
@IndexFragmentationLowThreshold INT,
@IndexFragmentationHighThreshold INT,
@FilegroupToCheck NVARCHAR(250),
@PartitionToCheck INT,
@SQLCMD NVARCHAR(MAX) = ''
SET @FilegroupToCheck = 'PARTITIONING_FG_' + CAST(YEAR(GETDATE()) AS NVARCHAR)
SET @PartitionNumber = (
SELECT
DISTINCT
p.partition_number
FROM sys.system_internals_allocation_units a
JOIN sys.partitions p
ON p.partition_id = a.container_id
JOIN sys.filegroups f on a.filegroup_id = f.data_space_id
WHERE f.[name] = @FilegroupToCheck)
DECLARE index_cursor CURSOR FOR
SELECT DISTINCT idx.[name], idx.index_id, idx.[object_id], pts.partition_number, scs.[name], obj.[name]
FROM sys.indexes idx
INNER JOIN sys.partitions pts
ON idx.object_id = pts.object_id
INNER JOIN sys.objects obj
ON idx.object_id = obj.object_id
INNER JOIN sys.schemas scs
ON obj.schema_id = scs.schema_id
WHERE pts.partition_number = @PartitionNumber
OPEN index_cursor
FETCH index_cursor INTO @IndexName, @IndexId, @ObjectId, @PartitionNumber, @SchemaName, @TableName
WHILE @@FETCH_STATUS = 0
BEGIN
SELECT @IndexFragmentationValue = MAX(avg_fragmentation_in_percent)
FROM sys.dm_db_index_physical_stats(DB_ID('partitioning_demo'), @ObjectId, @IndexId, @PartitionNumber, 'LIMITED')
WHERE alloc_unit_type_desc = 'IN_ROW_DATA' AND index_level = 0
IF (@IndexFragmentationValue < 5)
BEGIN
PRINT 'No action to perform for the index : [' + @IndexName + '] ON [' + @SchemaName + '].[' + @TableName + ']'
END
ELSE IF (@IndexFragmentationValue BETWEEN 5 AND 20)
BEGIN
SET @SQLCMD = @SQLCMD + 'ALTER INDEX [' + @IndexName + '] ON [' + @SchemaName + '].[' + @TableName + '] REORGANIZE PARTITION = ' + CAST(@PartitionNumber AS NVARCHAR) + ';' + CHAR(13)
END
ELSE IF (@IndexFragmentationValue > 20)
BEGIN
SET @SQLCMD = @SQLCMD + 'ALTER INDEX [' + @IndexName + '] ON [' + @SchemaName + '].[' + @TableName + '] REBUILD PARTITION = ' + CAST(@PartitionNumber AS NVARCHAR) + ';' + CHAR(13)
END
FETCH index_cursor INTO @IndexName, @IndexId, @ObjectId, @PartitionNumber, @SchemaName, @TableName
END
CLOSE index_cursor
DEALLOCATE index_cursor
--PRINT @SQLCMD
EXEC(@SQLCMD)Once the partition maintenance is completed, we can then maintain all other indexes (such as those of other tables) in the following way:
EXECUTE [dba_tools].[dbo].[IndexOptimize]
@Databases = 'USER_DATABASES',
@UpdateStatistics = 'ALL',
@Indexes = 'ALL_INDEXES,-[partitioning_demo].[dbo].[PK_T_Data_2],-[partitioning_demo].[dbo].[NCI-1-2]',
@LogToTable = 'Y'Thank you, Amine Haloui.
![Thumbnail [60x60]](https://www.dbi-services.com/blog/wp-content/uploads/2024/03/AHI_web.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2025/11/LTO_WEB.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/08/STH_web-min-scaled.jpg)
![Thumbnail [90x90]](https://www.dbi-services.com/blog/wp-content/uploads/2022/11/TBR-web-min-scaled.jpg)